
Python 基础爬虫架构
基础爬虫框架主要包括五大模块,分别为爬虫调度器、url管理器、HTML下载器、HTML解析器、数据存储器。
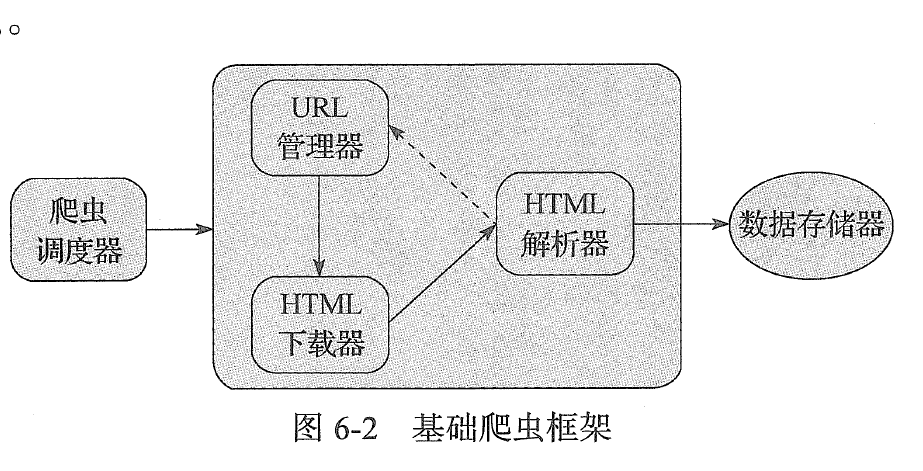
1:爬虫调度器主要负责统筹其他四个模块的协调工作
2: URL管理器负责管理URL连接,维护已经爬取的URL集合和未爬取的URL集合,提供获取新URL链接的接口
3: HTML下载器用于从URL管理器中获取未爬取的URL链接并下载HTML网页
4:HTML解析器用于从HTML下载器中获取已经下载的HTML网页,并从中解析出新的URL连接交给URL管理器,解析出有效数据交给数据存储器
URL管理器主要包括两个变量,一个是已爬取URL的集合,另一个是未爬取URL的集合。采用Python中的set类型,主要是使用set的去重复功能,防止链接重复爬取,重复爬取容易造成死循环。链接去重复在Python爬虫开发中是必备的功能,解决方案主要有三种:1:内存去重2:
关系数据库去重3:缓存数据库去重。大型成熟的爬虫基本上采用缓存数据库的去重方案
URL管理器除了具有两个URL集合,还需要以下接口
1:判断是否有待取的URL,方法定义为has_new_url()
2:添加新的URL到未爬取集合中,方法定义为add_new_url(url),add_new_urls(urls)
3:获取一个未爬取的URL,方法定义为get_new_url()
4:获取未爬取URL集合的大小,方法定义为new_url_size()
5:获取已经爬取的URL集合的大小,方法定义为old_url_size()
URL管理器
#coding:utf-8
class UrlManager(object):
def __init__(self):
self.new_urls = set() # 未爬取URL集合
self.old_urls = set() # 已爬取URL集合
def has_new_url(self):
# 判断是否有未爬取的URL
return self.new_url_size() != 0
def get_new_url(self):
# 获取一个未爬取的URL
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
def add_new_url(self, url):
# 将新的URL添加到未爬取的URL结合中
if url is None:
return
if url not in self.old_urls and url not in self.new_urls:
self.new_urls.add(url) # 将新的url添加到列表中
# 批量添加url
def add_new_urls(self, urls):
# 将新的URL添加到未爬取的URL集合中
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
# 获取未爬取url集合的大小
def new_url_size(self):
return len(self.new_urls)
# 获取已经爬取URL集合的大小
def old_url_size(self):
return len(self.old_urls)
HTML下载器
# coding:utf-8
import requests
import urllib2
import sys
type = sys.getfilesystemencoding()
class HtmlDownloader(object):
def download(slef, url):
if url is None:
return None
user_agent = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
headers = {'User-Agent': user_agent}
req = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(req)
if response.getcode() == 200:
html = response.read().decode("UTF-8").encode(type)
return html
return None
HTML解析器
#coding:utf-8
import re
import urlparse
from bs4 import BeautifulSoup
class HtmlParser(object):
# page_url下载页面的URL
# html_cont 下载的网页内容
# 返回URL和数据
def parser(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont, 'html.parser')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
# page_url下载页面的url
# soup:soup
# 返回新的URL集合
def _get_new_urls(self, page_url, soup):
new_urls = set()
# 抽取符合要求的a标记
links = soup.find_all('a', href=re.compile(r'/item/.*'))
for link in links:
# 提取href属性
new_url = link['href']
# 拼接成完整网址
new_full_url = urlparse.urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
# 下载页面的url
def _get_new_data(self, page_url, soup):
data = {}
data['url'] = page_url
title = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1')
data['title'] = title.get_text()
summary = soup.find('div', class_='lemma-summary')
# 获取tag中包含的所有文本内容,包括子孙tag中的内容,并将结果作为Unicode字符串返回
data['summary'] = summary.get_text()
return data
数据存储器:
# coding:utf-8
import codecs
import sys
from urllib import unquote
class DataOutput(object):
def __init__(self):
self.datas = []
def store_data(self, data):
if data is None:
return
self.datas.append(data)
def output_html(self):
fout = codecs.open('baike.html', 'w','utf-8')
fout.write("<html>")
fout.write("<body>")
fout.write("<table>")
for data in self.datas:
fout.write("<tr>")
fout.write("<td>%s</td>" % data['url'])
fout.write("<td>%s</td>" % data['title'])
fout.write("<td>%s</td>" % data['summary'])
fout.write("</tr>")
self.datas.remove(data)
fout.write("</table>")
fout.write("</body>")
fout.write("</html>")
fout.close()
爬虫调度器
# coding:utf-8
from DataOutput import DataOutput
from HtmlDownloader import HtmlDownloader
from HtmlParser import HtmlParser
from UrlManager import UrlManager
class SpiderMan(object):
def __init__(self):
self.manager = UrlManager()
self.downloader = HtmlDownloader()
self.parser = HtmlParser()
self.output = DataOutput()
def crawl(self, root_url):
# 添加入口URL
self.manager.add_new_url(root_url)
# 判断url管理器中是否有新的url,同时判断抓取了多少个url
while (self.manager.has_new_url() and self.manager.old_url_size() < 100):
try:
# 从URL管理器获取新的url
new_url = self.manager.get_new_url()
# html下载器下载网页
html = self.downloader.download(new_url)
# HTML解析器抽取网页数据
new_urls, data = self.parser.parser(new_url, html)
# 将抽取的url添加到URL管理器中
self.manager.add_new_urls(new_urls)
# 数据存储器存储文件
self.output.store_data(data)
print u"已经抓取%s个链接" % self.manager.old_url_size()
except Exception, e:
print "crawl failed"
self.output.output_html()
if __name__ == "__main__":
spider_man = SpiderMan()
spider_man.crawl("https://baike.baidu.com/item/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号