机器学习工程师 - Udacity 机器学习基础
一、评估指标
1.混淆矩阵:

2.准确率(accuracy):正确分类的点占总点数的比例。在sklearn中很容易计算:
from sklearn.metrics import accuracy_score
accuracy_score(y_true, y_pred)
准确率不适用偏斜严重的数据集。
3.精度(precision):所有预测为阳性的点中,真阳性的点的占比;
召回率(recall):所有标记为阳性的点中,正确预测为阳性的占比;
4.F1得分:精度和召回率的调和平均。
调和平均:2xy/(x+y)。调和平均总是比算术平均小,更接近较小的值。
5.F-β得分:(1+β2)·{xy/(β2x+y)},其中,x为精度,y为召回率。
如果β=0,则得出精度;
如果β=∞, 则得出召回率;
如果β=1, 则得出精度和召回率的调和平均数;
对于其他值,如果接近 0,则得出接近精度的值,如果很大,则得出接近召回率的值。
6.ROC曲线:Receiver Operator Characteristic,受试者工作特性曲线。
真阳性比例:在所有阳性的标记的点中,有多少点分类正确;
假阳性比例:在所有阴性的标记的点中,有多少点被分为阳性;
计算所有可能的分类情况下上述两个值组成的坐标,将这些坐标连成曲线,即ROC曲线。
完美数据情况下,ROC曲线下方的面积接近1;
良好数据情况下,ROC曲线下方的面积接近0.8;
随机数据情况下,ROC曲线下方的面积接近0.5;
曲线下的面积可以小于0.5,甚至为0。为0的模型更像是倒退,阳性的区域有更多的阴极点,阴性的区域有更多的阳极点,或许翻转数据会有帮助。
7.回归指标
a.平均绝对误差:将点到直线的距离的绝对值求和。
from sklearn.metrics import mean_absolute_error
from sklearn.linear_model import LinearRegression
classifier = LinearRegression()
classifier.fit(x, y)
guesses = classifier.predict(x)
error = mean_absolute_error(y, guesses)
绝对值函数是不可微分的,不利于使用诸如梯度下降等方法,为此,可以使用均方误差。
b.均方误差:计算的是点到直线距离的平方。
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import LinearRegression
classifier = LinearRegression()
classifier.fit(x, y)
guesses = classifier.predict(x)
error = mean_squared_error(y, guesses)
R2分数:拟合一堆点的最简单的模型是取所有点的平均值,画一条经过该值的水平直线。计算我们模型的均方误差和最简单模型的均方误差的比值,用1减去该值,即得到R2分数。
如果模型效果很差,R2分数接近于0,如果模型很好,R2分数接近于1。
from sklearn.metrics import r2_score
y_true = [1, 2, 4]
y_pred = [1.3, 2.5, 3.7]
r2_score(y_true, y_pred)
二、模型选择
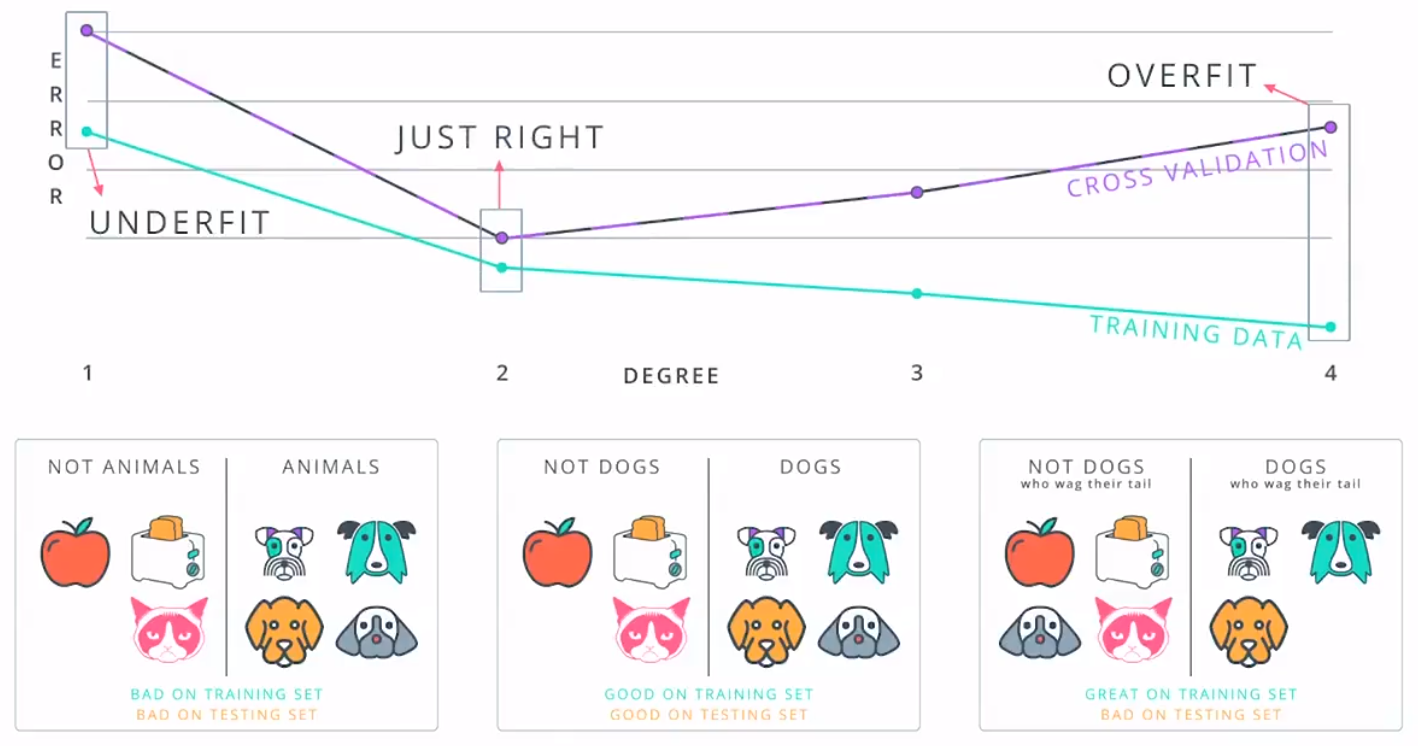
1.错误类型:
欠拟合:模型太简单,高偏差;
过拟合:模型太简单,高方差;
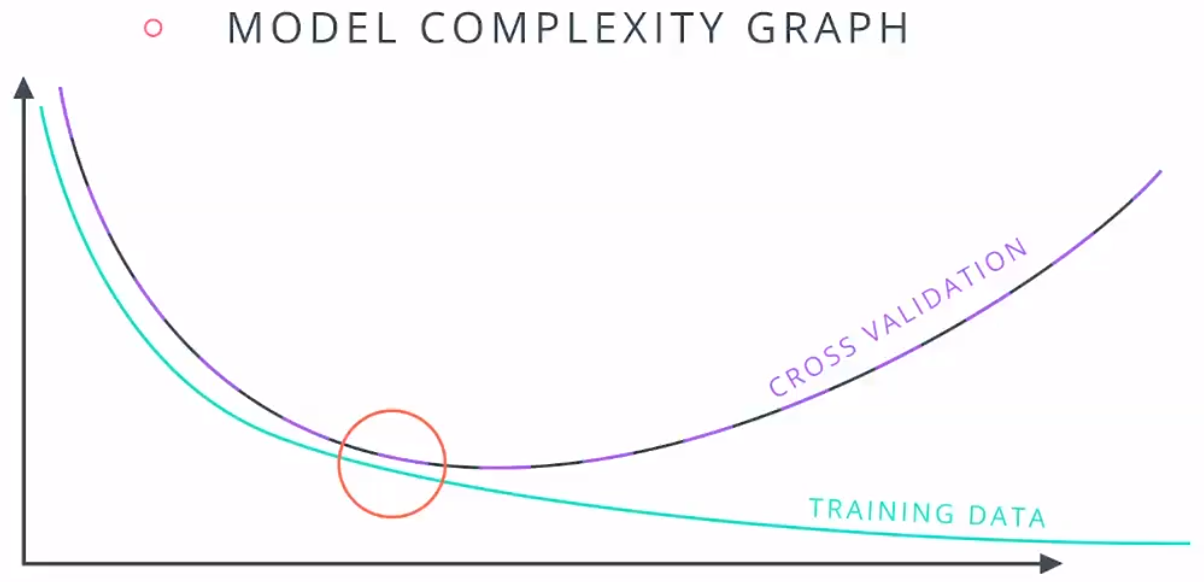
2.交叉验证:训练集用于训练参数,交叉验证集用于对模型做出决定,例如多项式的次数,测试集将用于模型的最终测试。
3.K折线交叉验证:
from sklearn.model_selection import KFord
kf = KFord(12, 3, shuffle = true)
其中参数为数据的大小和测试集的大小,shuffle = true表示随机化数据以消除偏差。
4.学习曲线:
高偏差模型(欠拟合):训练集和交叉验证集的误差曲线相互接近并交于一点;
效果好的模型:训练集和交叉验证集的误差曲线相互接近并交于一个很低的点;
高方差模型(过拟合):训练集保持很低,交叉验证集保持很高,两条曲线并不相交。
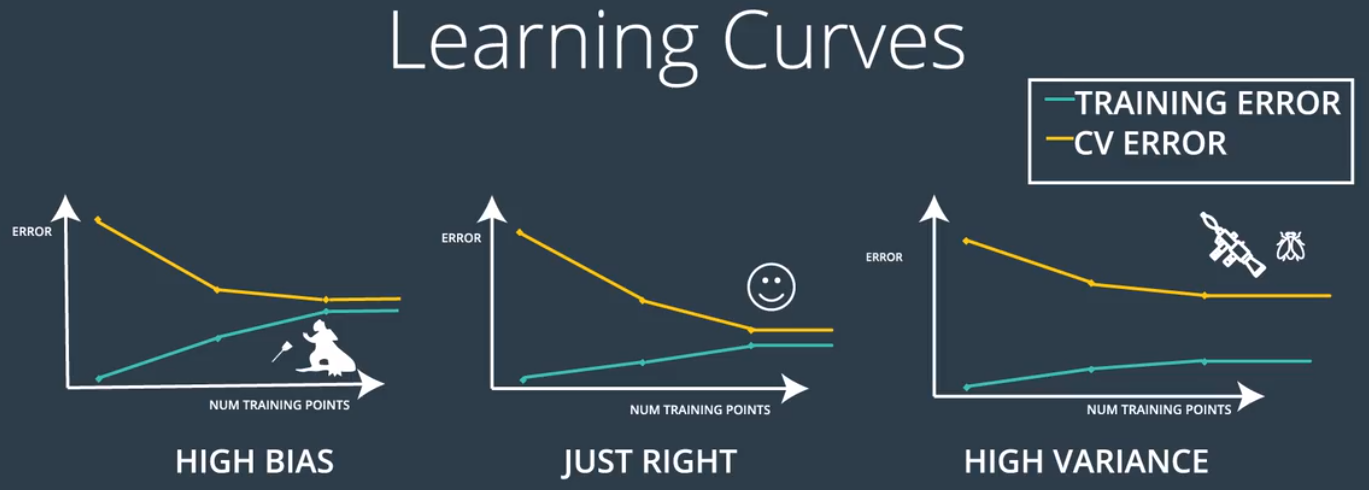
5.通过学习曲线检测过拟合和欠拟合
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=None, n_jobs=1, train_sizes=np.linspace(.1, 1.0, num_trainings))
其中,estimator,是我们针对数据使用的实际分类器,例如 LogisticRegression() 或 GradientBoostingClassifier()。
X 和 y 是我们的数据,分别表示特征和标签。
train_sizes 是用来在曲线上绘制每个点的数据大小。
train_scores 是针对每组数据进行训练后的算法训练得分。
test_scores 是针对每组数据进行训练后的算法测试得分。
注意:
a.训练和测试得分是一个包含 3 个值的列表,这是因为函数使用了 3 折交叉验证。
b.可以看出,我们使用训练和测试误差来定义我们的曲线,而这个函数使用训练和测试得分来定义曲线。二者是相反的,因此误差越高,得分就越低。因此,当你看到曲线时,你需要自己在脑中将它颠倒过来,以便与上面的曲线对比。
6.在 sklearn 中的网格搜索:
假设我们想要训练支持向量机,并且我们想在以下参数之间做出决定:
kernel:poly或rbf。
C:0.1,1 或 10。
具体步骤如下所示:
1)导入 GridSearchCV
from sklearn.model_selection import GridSearchCV
2)选择参数:
现在我们来选择我们想要选择的参数,并形成一个字典。 在这本字典中,键 (keys) 将是参数的名称,值 (values) 将是每个参数可能值的列表。
parameters = {'kernel':['poly', 'rbf'],'C':[0.1, 1, 10]}
3)创建一个评分机制 (scorer)
我们需要确认将使用什么指标来为每个候选模型评分。 这里,我们将使用 F1 分数。
from sklearn.metrics import make_scorer
from sklearn.metrics import f1_score
scorer = make_scorer(f1_score)
4)使用参数 (parameter) 和评分机制 (scorer) 创建一个 GridSearch 对象。 使用此对象与数据保持一致 (fit the data) 。
# Create the object.
grid_obj = GridSearchCV(clf, parameters, scoring=scorer)
# Fit the data
grid_fit = grid_obj.fit(X, y)
5)获得最佳估算器 (estimator)
best_clf = grid_fit.best_estimator_
现在你可以使用这一估算器best_clf来做出预测。
三、Numpy与pandas
1.在二维 NumPy 数组 'X' 中,如何选择最后 100 行?
X[-100:,]
2.基于 Pandas dataframe 'df' 中的列 'gender' 与 'age', 你是如何计算出每一个性别 (gender) 中的平均年龄 (average age) 呢?
df.groupby('gender')['age'].mean()
3.在 Pandas dataframe 'df' 中,你将运用哪一个命令行来可视化 'height' 值的分布情况?
df['height'].plot(kind='box')
四、模型评估与验证
1.一类错误和二类错误之间的区别是什么?
一类错误为假正,二类错误为假负。
tips:混淆矩阵是一种评估一类错误和二类错误的有效方法。
2.什么是k折交叉验证?它能帮助预防什么?
将数据集拆分为 k 个子集,每次将其中一个子集用作测试集,剩下 k-1 个子集将组合起来构成训练集。接着计算所有 k 次测试的平均误差。这能帮助预防过拟合。
posted on 2018-11-07 20:20 paulonetwo 阅读(674) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号