

机器学习工程师 - Udacity 机器学习毕业项目 算式识别
import pandas as pd
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
# 统计字符长度
def draw_hist(data, title):
plt.style.use(u'ggplot')
fig = pd.DataFrame(data, index=[0]).transpose()[0].plot(kind='barh')
fig = fig.get_figure()
fig.tight_layout()
plt.title(title)
plt.show()
data_csv = pd.read_csv('F:/train.csv')
img_dirpath = data_csv['filename'].tolist()
label = data_csv['label'].tolist()
X_data, X_valid, y_data, y_valid = train_test_split(img_dirpath, label, test_size=10000, random_state=17)
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=10000, random_state=17)
list_length_train = list()
for str in y_train:
list_length_train.append(len(str))
list_length_train = pd.Series(list_length_train).value_counts().to_dict()
draw_hist(list_length_train, 'train data length')
list_length_valid = list()
for str in y_valid:
list_length_valid.append(len(str))
list_length_valid = pd.Series(list_length_valid).value_counts().to_dict()
draw_hist(list_length_valid,'valid data length')
list_length_test = list()
for str in y_test:
list_length_test.append(len(str))
list_length_test = pd.Series(list_length_test).value_counts().to_dict()
draw_hist(list_length_test,'test data length')
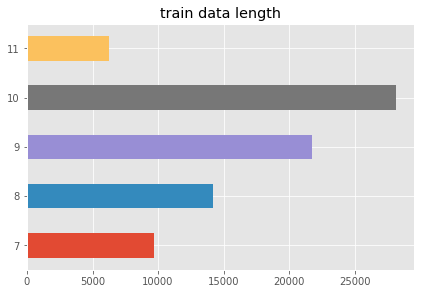
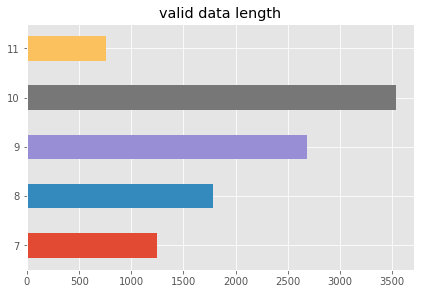
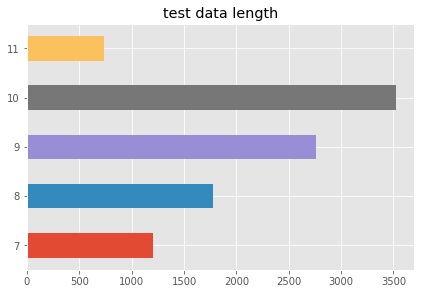
# 统计字符分布
from collections import defaultdict
sum_character_train = defaultdict(int)
for str in y_train:
for character in str:
sum_character_train[character] += 1
sum_character_train = dict(sum_character_train)
draw_hist(sum_character_train,'train data character distribution')
sum_character_valid = defaultdict(int)
for str in y_valid:
for character in str:
sum_character_valid[character] += 1
sum_character_valid = dict(sum_character_valid)
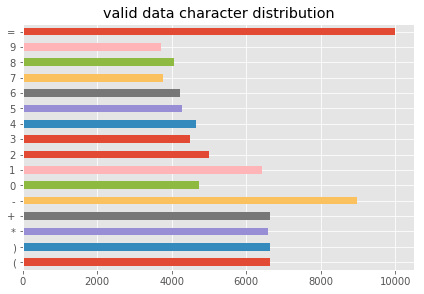
draw_hist(sum_character_valid,'valid data character distribution')
sum_character_test = defaultdict(int)
for str in y_test:
for character in str:
sum_character_test[character] += 1
sum_character_test = dict(sum_character_test)
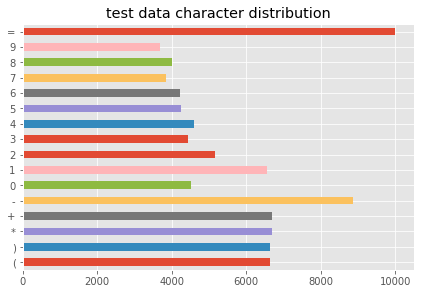
draw_hist(sum_character_test,'test data character distribution')
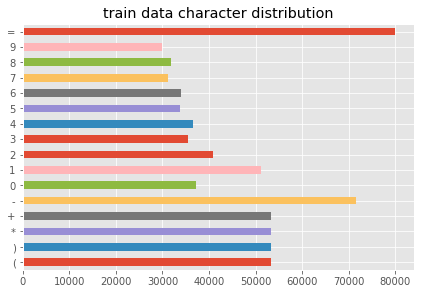
# 所有待识别字符
CHAR_VECTOR = "0123456789+-*()=a"
letters = [letter for letter in CHAR_VECTOR]
# 将索引转换为字符
def labels_to_text(labels):
return ''.join(list(map(lambda x: letters[int(x)], labels)))
# 将字符转换为索引
def text_to_labels(text):
return list(map(lambda x: letters.index(x), text))
import cv2
import random
from tqdm import tqdm
class TextImageGenerator:
def __init__(self, rootpath, img_dirpath, label, img_w, img_h, batch_size, downsample_factor, max_text_len):
self.rootpath = rootpath # 文件根目录
self.img_dirpath = img_dirpath
self.label = label
self.img_w = img_w
self.img_h = img_h
self.batch_size = batch_size
self.downsample_factor = downsample_factor
self.max_text_len = max_text_len
self.n = len(self.img_dirpath) # 图片数量
self.indexes = list(range(self.n))
self.cur_index = 0
self.imgs = np.zeros((self.n, self.img_h, self.img_w))
self.texts = []
def build_data(self):
for i, img_file in enumerate(tqdm(self.img_dirpath)):
img = cv2.imread(self.rootpath + img_file, cv2.IMREAD_GRAYSCALE)
img = cv2.resize(img, (self.img_w, self.img_h))
img = img.astype(np.float32)
img = (img / 255.0) * 2.0 - 1.0
self.imgs[i, :, :] = img
self.texts.append(self.label[i])
print(self.n, " Image Loading finish...")
def next_sample(self):
self.cur_index += 1
if self.cur_index >= self.n:
self.cur_index = 0
random.shuffle(self.indexes)
return self.imgs[self.indexes[self.cur_index]], self.texts[self.indexes[self.cur_index]]
def next_batch(self):
while True:
X_data = np.ones([self.batch_size, self.img_w, self.img_h, 1])
Y_data = np.empty([self.batch_size, self.max_text_len])
input_length = np.ones((self.batch_size, 1)) * (self.img_w // self.downsample_factor - 2)
label_length = np.zeros((self.batch_size, 1))
for i in range(self.batch_size):
img, text = self.next_sample()
img = img.T
img = np.expand_dims(img, -1)
X_data[i] = img
labels = text_to_labels(text)
Y_data[i, 0:len(labels)] = labels
Y_data[i, len(labels):13] = 16
label_length[i] = len(text)
inputs = {
'the_input': X_data,
'the_labels': Y_data,
'input_length': input_length,
'label_length': label_length
}
outputs = {'ctc': np.zeros([self.batch_size])}
yield (inputs, outputs)
from keras import backend as K
def ctc_lambda_func(args):
y_pred, labels, input_length, label_length = args
# the 2 is critical here since the first couple outputs of the RNN tend to be garbage:
y_pred = y_pred[:, 2:, :]
return K.ctc_batch_cost(labels, y_pred, input_length, label_length)
from keras.layers import *
from keras.models import *
def get_model(img_w, img_h, num_classes, training):
input_shape = (img_w, img_h, 1) # (128, 64, 1)
# Make Networkw
inputs = Input(name='the_input', shape=input_shape, dtype='float32') # (None, 128, 64, 1)
# Convolution layer (VGG)
inner = Conv2D(64, (3, 3), padding='same', name='conv1', kernel_initializer='he_normal')(inputs) # (None, 128, 64, 64)
inner = BatchNormalization()(inner)
inner = Activation('relu')(inner)
inner = MaxPooling2D(pool_size=(2, 2), name='max1')(inner) # (None,64, 32, 64)
inner = Dropout(0.2)(inner)
inner = Conv2D(128, (3, 3), padding='same', name='conv2', kernel_initializer='he_normal')(inner) # (None, 64, 32, 128)
inner = BatchNormalization()(inner)
inner = Activation('relu')(inner)
inner = MaxPooling2D(pool_size=(2, 2), name='max2')(inner) # (None, 32, 16, 128)
inner = Dropout(0.2)(inner)
inner = Conv2D(256, (3, 3), padding='same', name='conv3', kernel_initializer='he_normal')(inner) # (None, 32, 16, 256)
inner = BatchNormalization()(inner)
inner = Activation('relu')(inner)
inner = Conv2D(256, (3, 3), padding='same', name='conv4', kernel_initializer='he_normal')(inner) # (None, 32, 16, 256)
inner = BatchNormalization()(inner)
inner = Activation('relu')(inner)
inner = MaxPooling2D(pool_size=(1, 2), name='max3')(inner) # (None, 32, 8, 256)
inner = Dropout(0.2)(inner)
# inner = Conv2D(512, (3, 3), padding='same', name='conv5', kernel_initializer='he_normal')(inner) # (None, 32, 8, 512)
# inner = BatchNormalization()(inner)
# inner = Activation('relu')(inner)
# inner = Conv2D(512, (3, 3), padding='same', name='conv6')(inner) # (None, 32, 8, 512)
# inner = BatchNormalization()(inner)
# inner = Activation('relu')(inner)
# inner = MaxPooling2D(pool_size=(1, 2), name='max4')(inner) # (None, 32, 4, 512)
# inner = Dropout(0.2)(inner)
inner = Conv2D(256, (2, 2), padding='same', kernel_initializer='he_normal', name='con7')(inner) # (None, 32, 4, 256)
inner = BatchNormalization()(inner)
inner = Activation('relu')(inner)
# CNN to RNN
inner = Reshape(target_shape=((32, 2048)), name='reshape')(inner) # (None, 32, 2048)
inner = Dense(64, activation='relu', kernel_initializer='he_normal', name='dense1')(inner) # (None, 32, 64)
# RNN layer
lstm_1 = GRU(256, return_sequences=True, kernel_initializer='he_normal', name='lstm1')(inner) # (None, 32, 512)
lstm_1b = GRU(256, return_sequences=True, go_backwards=True, kernel_initializer='he_normal', name='lstm1_b')(inner)
lstm1_merged = add([lstm_1, lstm_1b]) # (None, 32, 512)
lstm1_merged = BatchNormalization()(lstm1_merged)
lstm_2 = GRU(256, return_sequences=True, kernel_initializer='he_normal', name='lstm2')(lstm1_merged)
lstm_2b = GRU(256, return_sequences=True, go_backwards=True, kernel_initializer='he_normal', name='lstm2_b')(lstm1_merged)
lstm2_merged = concatenate([lstm_2, lstm_2b]) # (None, 32, 1024)
lstm2_merged = Dropout(0.2)(lstm2_merged)
# lstm_merged = BatchNormalization()(lstm2_merged)
# transforms RNN output to character activations:
inner = Dense(num_classes, kernel_initializer='he_normal', name='dense2')(lstm2_merged) #(None, 32, 63)
y_pred = Activation('softmax', name='softmax')(inner)
labels = Input(name='the_labels', shape=[max_text_len], dtype='float32') # (None ,8)
input_length = Input(name='input_length', shape=[1], dtype='int64') # (None, 1)
label_length = Input(name='label_length', shape=[1], dtype='int64') # (None, 1)
# Keras doesn't currently support loss funcs with extra parameters so CTC loss is implemented in a lambda layer
loss_out = Lambda(ctc_lambda_func, output_shape=(1,), name='ctc')([y_pred, labels, input_length, label_length]) #(None, 1)
if training:
return Model(inputs=[inputs, labels, input_length, label_length], outputs=loss_out)
else:
return Model(inputs=[inputs], outputs=y_pred)
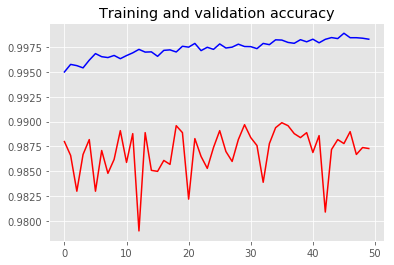
# 绘制准确率
def plot_training(history):
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'b-')
plt.plot(epochs, val_acc, 'r')
plt.title('Training and validation accuracy')
plt.savefig("Training and validation accuracy.png")
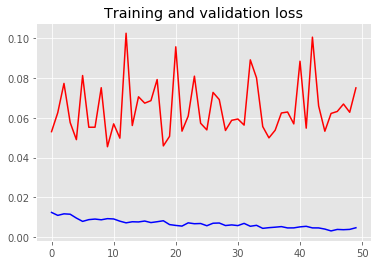
plt.figure()
plt.plot(epochs, loss, 'b-')
plt.plot(epochs, val_loss, 'r-')
plt.title('Training and validation loss')
plt.savefig("Training and validation loss.png")
plt.show()
from keras.optimizers import Adadelta
from keras.callbacks import ModelCheckpoint
from keras.utils.vis_utils import plot_model
rootpath = 'F:/'
img_w, img_h = 128, 64
batch_size = 256
downsample_factor = 4
max_text_len = 12
num_classes = len(letters) + 1
model = get_model(img_w, img_h, num_classes, True)
plot_model(model, to_file='model.png', show_shapes=True)
try:
model.load_weights('best_weight.hdf5')
print("...Previous weight data...")
except:
print("...New weight data...")
pass
data_train = TextImageGenerator(rootpath, X_train, y_train, img_w, img_h, batch_size, downsample_factor, max_text_len)
data_train.build_data()
data_valid = TextImageGenerator(rootpath, X_valid, y_valid, img_w, img_h, batch_size, downsample_factor, max_text_len)
data_valid.build_data()
data_test = TextImageGenerator(rootpath, X_test, y_test, img_w, img_h, batch_size, downsample_factor, max_text_len)
data_test.build_data()
checkpoint = ModelCheckpoint(filepath='best_weight.hdf5', monitor='val_acc', verbose=0, save_best_only=True, period=1)
# the loss calc occurs elsewhere, so use a dummy lambda func for the loss
model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer=Adadelta(), metrics=['accuracy'])
history_ft = model.fit_generator(generator=data_train.next_batch(),
steps_per_epoch=int(data_train.n / batch_size),
epochs=50,
verbose = 2,
callbacks=[checkpoint],
validation_data=data_valid.next_batch(),
validation_steps=int(data_valid.n / batch_size))
plot_training(history_ft)
10000 Image Loading finish...
Epoch 1/50
- 141s - loss: 0.0125 - acc: 0.9950 - val_loss: 0.0530 - val_acc: 0.9880
Epoch 2/50
- 134s - loss: 0.0110 - acc: 0.9958 - val_loss: 0.0625 - val_acc: 0.9866
Epoch 3/50
- 132s - loss: 0.0118 - acc: 0.9956 - val_loss: 0.0773 - val_acc: 0.9830
Epoch 4/50
- 130s - loss: 0.0116 - acc: 0.9954 - val_loss: 0.0576 - val_acc: 0.9867
Epoch 5/50
- 130s - loss: 0.0096 - acc: 0.9962 - val_loss: 0.0490 - val_acc: 0.9882
Epoch 6/50
- 130s - loss: 0.0080 - acc: 0.9969 - val_loss: 0.0812 - val_acc: 0.9830
Epoch 7/50
- 131s - loss: 0.0088 - acc: 0.9965 - val_loss: 0.0552 - val_acc: 0.9871
Epoch 8/50
- 132s - loss: 0.0091 - acc: 0.9965 - val_loss: 0.0553 - val_acc: 0.9848
Epoch 9/50
- 132s - loss: 0.0088 - acc: 0.9967 - val_loss: 0.0751 - val_acc: 0.9862
Epoch 10/50
- 133s - loss: 0.0093 - acc: 0.9963 - val_loss: 0.0454 - val_acc: 0.9891
Epoch 11/50
- 132s - loss: 0.0092 - acc: 0.9967 - val_loss: 0.0569 - val_acc: 0.9859
Epoch 12/50
- 131s - loss: 0.0081 - acc: 0.9969 - val_loss: 0.0498 - val_acc: 0.9888
Epoch 13/50
- 131s - loss: 0.0072 - acc: 0.9973 - val_loss: 0.1024 - val_acc: 0.9790
Epoch 14/50
- 131s - loss: 0.0078 - acc: 0.9970 - val_loss: 0.0561 - val_acc: 0.9889
Epoch 15/50
- 131s - loss: 0.0077 - acc: 0.9970 - val_loss: 0.0705 - val_acc: 0.9851
Epoch 16/50
- 133s - loss: 0.0081 - acc: 0.9966 - val_loss: 0.0673 - val_acc: 0.9850
Epoch 17/50
- 136s - loss: 0.0074 - acc: 0.9972 - val_loss: 0.0686 - val_acc: 0.9861
Epoch 18/50
- 135s - loss: 0.0078 - acc: 0.9972 - val_loss: 0.0792 - val_acc: 0.9857
Epoch 19/50
- 133s - loss: 0.0083 - acc: 0.9970 - val_loss: 0.0459 - val_acc: 0.9896
Epoch 20/50
- 131s - loss: 0.0064 - acc: 0.9976 - val_loss: 0.0507 - val_acc: 0.9889
Epoch 21/50
- 133s - loss: 0.0059 - acc: 0.9975 - val_loss: 0.0956 - val_acc: 0.9822
Epoch 22/50
- 133s - loss: 0.0056 - acc: 0.9979 - val_loss: 0.0533 - val_acc: 0.9883
Epoch 23/50
- 132s - loss: 0.0072 - acc: 0.9972 - val_loss: 0.0608 - val_acc: 0.9865
Epoch 24/50
- 131s - loss: 0.0068 - acc: 0.9975 - val_loss: 0.0809 - val_acc: 0.9853
Epoch 25/50
- 131s - loss: 0.0069 - acc: 0.9973 - val_loss: 0.0572 - val_acc: 0.9874
Epoch 26/50
- 131s - loss: 0.0058 - acc: 0.9978 - val_loss: 0.0539 - val_acc: 0.9891
Epoch 27/50
- 131s - loss: 0.0070 - acc: 0.9974 - val_loss: 0.0727 - val_acc: 0.9870
Epoch 28/50
- 132s - loss: 0.0071 - acc: 0.9975 - val_loss: 0.0691 - val_acc: 0.9860
Epoch 29/50
- 131s - loss: 0.0059 - acc: 0.9978 - val_loss: 0.0536 - val_acc: 0.9882
Epoch 30/50
- 131s - loss: 0.0062 - acc: 0.9976 - val_loss: 0.0587 - val_acc: 0.9897
Epoch 31/50
- 132s - loss: 0.0059 - acc: 0.9976 - val_loss: 0.0594 - val_acc: 0.9884
Epoch 32/50
- 131s - loss: 0.0070 - acc: 0.9974 - val_loss: 0.0563 - val_acc: 0.9876
Epoch 33/50
- 132s - loss: 0.0055 - acc: 0.9979 - val_loss: 0.0891 - val_acc: 0.9839
Epoch 34/50
- 132s - loss: 0.0060 - acc: 0.9978 - val_loss: 0.0800 - val_acc: 0.9878
Epoch 35/50
- 130s - loss: 0.0045 - acc: 0.9982 - val_loss: 0.0556 - val_acc: 0.9894
Epoch 36/50
- 130s - loss: 0.0048 - acc: 0.9982 - val_loss: 0.0499 - val_acc: 0.9899
Epoch 37/50
- 130s - loss: 0.0051 - acc: 0.9980 - val_loss: 0.0537 - val_acc: 0.9896
Epoch 38/50
- 130s - loss: 0.0053 - acc: 0.9979 - val_loss: 0.0624 - val_acc: 0.9888
Epoch 39/50
- 131s - loss: 0.0047 - acc: 0.9983 - val_loss: 0.0629 - val_acc: 0.9884
Epoch 40/50
- 130s - loss: 0.0047 - acc: 0.9980 - val_loss: 0.0569 - val_acc: 0.9889
Epoch 41/50
- 130s - loss: 0.0052 - acc: 0.9983 - val_loss: 0.0884 - val_acc: 0.9869
Epoch 42/50
- 130s - loss: 0.0055 - acc: 0.9979 - val_loss: 0.0548 - val_acc: 0.9886
Epoch 43/50
- 131s - loss: 0.0047 - acc: 0.9983 - val_loss: 0.1005 - val_acc: 0.9809
Epoch 44/50
- 130s - loss: 0.0047 - acc: 0.9985 - val_loss: 0.0659 - val_acc: 0.9872
Epoch 45/50
- 130s - loss: 0.0041 - acc: 0.9984 - val_loss: 0.0532 - val_acc: 0.9882
Epoch 46/50
- 130s - loss: 0.0032 - acc: 0.9989 - val_loss: 0.0622 - val_acc: 0.9878
Epoch 47/50
- 130s - loss: 0.0039 - acc: 0.9985 - val_loss: 0.0632 - val_acc: 0.9890
Epoch 48/50
- 130s - loss: 0.0038 - acc: 0.9985 - val_loss: 0.0669 - val_acc: 0.9867
Epoch 49/50
- 130s - loss: 0.0039 - acc: 0.9984 - val_loss: 0.0628 - val_acc: 0.9874
Epoch 50/50
- 131s - loss: 0.0048 - acc: 0.9983 - val_loss: 0.0750 - val_acc: 0.9873
import itertools
def decode_label(out):
out_best = list(np.argmax(out[0, 2:], axis=1)) # get max index
out_best = [k for k, g in itertools.groupby(out_best)] # remove overlap value
outstr = ''
for i in out_best:
if i < len(letters):
outstr += letters[i]
return outstr
model_best = get_model(img_w, img_h, num_classes, False)
model_best.load_weights("best_weight.hdf5")
total = 0
acc = 0
letter_total = 0
letter_acc = 0
for i, img_file in enumerate(X_test):
img = cv2.imread('F:/' + img_file, cv2.IMREAD_GRAYSCALE)
img_pred = img.astype(np.float32)
img_pred = cv2.resize(img_pred, (128, 64))
img_pred = (img_pred / 255.0) * 2.0 - 1.0
img_pred = img_pred.T
img_pred = np.expand_dims(img_pred, axis=-1)
img_pred = np.expand_dims(img_pred, axis=0)
net_out_value = model_best.predict(img_pred)
pred_texts = decode_label(net_out_value)
for j in range(min(len(pred_texts), len(y_test[i]))):
if pred_texts[j] == y_test[i][j]:
letter_acc += 1
letter_total += max(len(pred_texts), len(label[i]))
if pred_texts == y_test[i]:
acc += 1
total += 1
print("ACC : ", acc / total)
print("letter ACC : ", letter_acc / letter_total)
ACC : 0.9903
letter ACC : 0.9339507953515206
# 结果可视化
fig = plt.figure()
for i in range(9):
ax = fig.add_subplot(330 + 1 + i)
ax.axis('off')
image = cv2.imread('F:/' + X_test[i])
ax.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
img = cv2.imread('F:/' + X_test[i], cv2.IMREAD_GRAYSCALE)
img_pred = img.astype(np.float32)
img_pred = cv2.resize(img_pred, (128, 64))
img_pred = (img_pred / 255.0) * 2.0 - 1.0
img_pred = img_pred.T
img_pred = np.expand_dims(img_pred, axis=-1)
img_pred = np.expand_dims(img_pred, axis=0)
net_out_value = model_best.predict(img_pred)
pred_texts = decode_label(net_out_value)
ax.set_title(pred_texts)

Tips:关于过拟合你可以参考一些网上的资料,例如 https://blog.csdn.net/qq_18254385/article/details/78428887 。对于过拟合问题,需要了解的是最根本的原因是因为模型太大(或者数据太少),导致模型倾向于学习一些训练集的专有特征,那么针对性的也有相关解决方法可以尝试:
1)模型太大:减少模型参数,dropout
2)数据太少:数据增强,fake数据生成
3)学习专有特征:l2正则化等,控制参数不要太放浪。
4)其他方法:模型融合,实际上模型融合可以有效克服过拟合问题,因为不同模型学到的专有特征通常也不一样,但是公共特征比较相似,多模型融合可以很好地弱化专有特征,保留更公有,或者我们说更泛化的特征。
克服过拟合的方法有很多,不过都需要尝试,不同方法的效果在不同数据集上也是不一样的。
此外,train的loss和valid的loss有差距是正常的,毕竟模型只见过train的数据,轻微的过拟合是难以避免的,上述方法也只能缓解过拟合,得到更泛化的模型,而很难完全解决。
参考:
https://github.com/ypwhs/baiduyun_deeplearning_competition
https://github.com/qjadud1994/CRNN-Keras
posted on 2019-03-14 20:38 paulonetwo 阅读(719) 评论(0) 编辑 收藏 举报


