

机器学习工程师 - Udacity 强化学习 Part Three
四、动态规划
1.在动态规划设置中,智能体完全了解表示环境特性的马尔可夫决策流程 (MDP)。(这比强化学习设置简单多了,在强化学习设置中,智能体一开始不知道环境如何决定状态和奖励,必须完全通过互动学习如何选择动作。)
2.迭代方法求状态值函数
迭代方法先对每个状态的值进行初始猜测。尤其是,我们先假设每个状态的值为 0。然后,循环访问状态空间并通过应用连续的更新方程修改状态值函数的估算结果。

3.动作值
思考下 qπ(s1,right) 这个示例。这个动作值的计算方式如下所示:
qπ(s1,right)=−1+vπ(s2)=−1+2=1,
我们可以将状态动作对的值 s1,right 表示为以下两个量的和:(1)向右移动并进入状态 s2 的即时奖励,以及 (2) 智能体从状态 s2 开始并遵守该策略获得的累积奖励。
4.对于更加复杂的环境
在这个简单的网格世界示例中,环境是确定性环境。换句话说,智能体选择某个动作后,下个状态和奖励可以 100% 确定不是随机的。对于确定性环境,所有的s′,r,s,a 为 p(s′,r∣s,a)∈{0,1}。
在这种情况下,当智能体处在状态 s 并采取动作 a 时,下个状态 s′ 和奖励 r 可以确切地预测,我们必须确保 qπ(s,a)=r+γvπ(s′)。
通常,环境并非必须是确定性环境,可以是随机性的。这是迷你项目中的 FrozenLake 环境的默认行为;在这种情况下,智能体选择动作后,下个状态和奖励无法确切地预测,而是从(条件性)概率分布 p(s′,r∣s,a)中随机抽取的。
在这种情况下,当智能体处在状态 s 并采取动作 a 时,每个潜在下个状态 s′ 的概率和奖励 r 由 p(s′,r∣s,a) 确定。在这种情况下,我们必须确保 qπ(s,a)=∑s′∈S+,r∈Rp(s′,r∣s,a)(r+γvπ(s′)),我们计算和 r+γvπ(s′) 的期望值。

5.策略改进
如果给定策略 π 对应的动作值函数 qπ 的估值 Q,可以构建一个改进(或对等)的策略 π′,其中 π′≥π。
对于每个状态 s∈S,你只需选择最大化动作值函数估值的动作。换句话说,π′(s)=arg maxa∈A(s)Q(s,a),针对所有 s∈S。
如果对于某个状态 s∈S,其 arg maxa∈A(s)Q(s,a) 不是唯一的,则可以灵活地构建改进策略 π′。
实际上,只要策略 π′ 对于每个 s∈S 和 a∈A(s) 都满足:
π′(a∣s)=0 如果 a∉arg maxa′∈A(s)Q(s,a′),
它是改进策略。换句话说,(对于每个状态)任何策略只要为不会最大化动作值函数估值的动作分配概率 0,则对该状态来说就是改进策略。

6.策略迭代
策略迭代肯定会用有限次数的迭代找到任何有限马尔可夫决策流程 (MDP) 的最优策略。

7.截断策略迭代
截断策略迭代是在动态规划设置中用来估算策略 π 对应的状态值函数 vπ 的算法。对于此方法,在对状态空间执行固定次数的遍历后,停止评估步骤。我们将评估步骤中的此方法称为截断策略评估。


8.值迭代
值迭代是在动态规划设置中用来估算策略 π 对应的状态值函数 vπ 的算法。对于此方法,每次对状态空间进行遍历时,都同时进行策略评估和策略改进。
注意,如果后续值函数估值之间的差值很小,则满足了停止条件。尤其是,如果对于每个状态,差值都小于 θ,则循环终止。并且,如果我们希望最终值函数估值与最优值函数越接近,则需要将值 θ 设得越小。
你可以在你的实现中将 θ 设成各种值;注意,对于 FrozenLake 环境,1e-8 左右的值似乎很合适。
如果你想详细了解如何设置 θ 的值,建议阅读这篇论文,并重点看看 Theorem 3.2。他们的主要结果可以总结如下:
用 Vfinal 表示算法计算的最终值函数估值。然后可以发现 Vfinal 与最优值函数 v∗ 之间的差值最大为 2θγ/(1−γ)。换句话说,对于每个 s∈S,
maxs∈S∣Vfinal(s)−v∗(s)∣<2θγ/(1−γ)。

迷你项目:动态规划
相应的 GitHub 文件
第 0 部分:探索 FrozenLakeEnv
请使用以下代码单元格创建 FrozenLake 环境的实例。
from frozenlake import FrozenLakeEnv
env = FrozenLakeEnv()
智能体将会在 4×4 网格世界中移动,状态编号如下所示:
智能体可以执行 4 个潜在动作:
LEFT = 0
DOWN = 1
RIGHT = 2
UP = 3
因此,S+={0,1,…,15} 以及 A={0,1,2,3}。请通过运行以下代码单元格验证这一点。
# print the state space and action space
print(env.observation_space)
print(env.action_space)
# print the total number of states and actions
print(env.nS)
print(env.nA)
Discrete(16)
Discrete(4)
16
4
动态规划假设智能体完全了解 MDP。我们已经修改了 frozenlake.py 文件以使智能体能够访问一步动态特性。
请执行以下代码单元格以返回特定状态和动作对应的一步动态特性。具体而言,当智能体在网格世界中以状态 1 向左移动时,env.P[1][0] 会返回每个潜在奖励的概率和下一个状态。
env.P[1][0]
[(0.3333333333333333, 1, 0.0, False),
(0.3333333333333333, 0, 0.0, False),
(0.3333333333333333, 5, 0.0, True)]
每个条目的格式如下所示
其中:
prob详细说明了相应的 (next_state,reward) 对的条件概率,以及- 如果
next_state是终止状态,则done是True,否则是False。
因此,我们可以按照以下方式解析 env.P[1][0]:
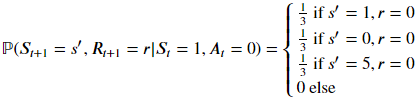
你可以随意更改上述代码单元格,以探索在其他(状态、动作)对下环境的行为是怎样的。
第 1 部分:迭代策略评估
在此部分,你将自己编写迭代策略评估的实现。
你的算法应该有四个输入参数:
env:这是 OpenAI Gym 环境的实例,其中env.P会返回一步动态特性。policy:这是一个二维 numpy 数组,其中policy.shape[0]等于状态数量 (env.nS) ,policy.shape[1]等于动作数量 (env.nA) 。policy[s][a]返回智能体在状态s时根据该策略选择动作a的概率。gamma:这是折扣率。它必须是在 0 到 1(含)之间的值,默认值为:1。theta:这是一个非常小的正数,用于判断估算值是否足够地收敛于真值函数 (默认值为:1e-8)。
该算法会返回以下输出结果:
V:这是一个一维numpy数组,其中V.shape[0]等于状态数量 (env.nS)。V[s]包含状态s在输入策略下的估算值。
请完成以下代码单元格中的函数。
import numpy as np
def policy_evaluation(env, policy, gamma=1, theta=1e-8):
V = np.zeros(env.nS)
while True:
delta = 0
for s in range(env.nS):
Vs = 0
for a, action_prob in enumerate(policy[s]):
for prob, next_state, reward, done in env.P[s][a]:
Vs += action_prob * prob * (reward + gamma * V[next_state])
delta = max(delta, np.abs(V[s]-Vs))
V[s] = Vs
if delta < theta:
break
return V
我们将评估等概率随机策略 π,其中对于所有 s∈S 和 a∈A(s) ,π(a|s)=1/|A(s)|。
请使用以下代码单元格在变量 random_policy中指定该策略。
random_policy = np.ones([env.nS, env.nA]) / env.nA
运行下个代码单元格以评估等概率随机策略并可视化输出结果。状态值函数已调整形状,以匹配网格世界的形状。
from plot_utils import plot_values
%matplotlib inline
# evaluate the policy
V = policy_evaluation(env, random_policy)
plot_values(V)

运行以下代码单元格以测试你的函数。如果代码单元格返回 PASSED,则表明你正确地实现了该函数!
注意:为了确保结果准确,确保你的 policy_evaluation 函数满足上文列出的要求(具有四个输入、一个输出,并且没有更改输入参数的默认值)。
import check_test
check_test.run_check('policy_evaluation_check', policy_evaluation)
PASSED
第 2 部分:通过 vπ 获取 qπ
在此部分,你将编写一个函数,该函数的输入是状态值函数估值以及一些状态 s∈S。它会返回输入状态 s∈S 对应的动作值函数中的行。即你的函数应同时接受输入 vπ 和 s,并针对所有 a∈A(s) 返回 qπ(s,a)。
你的算法应该有四个输入参数:
env:这是 OpenAI Gym 环境的实例,其中env.P会返回一步动态特性。V:这是一个一维 numpy 数组,其中V.shape[0]等于状态数量 (env.nS)。V[s]包含状态s的估值。s:这是环境中的状态对应的整数。它应该是在0到(env.nS)-1(含)之间的值。gamma:这是折扣率。它必须是在 0 到 1(含)之间的值,默认值为:1。
该算法会返回以下输出结果:
q:这是一个一维 numpy 数组,其中q.shape[0]等于动作数量 (env.nA)。q[a]包含状态s和动作a的(估算)值。
请完成以下代码单元格中的函数。
def q_from_v(env, V, s, gamma=1):
q = np.zeros(env.nA)
for a in range(env.nA):
for prob, next_state, reward, done in env.P[s][a]:
q[a] += prob * (reward + gamma * V[next_state])
return q
请运行以下代码单元格以输出上述状态值函数对应的动作值函数。
Q = np.zeros([env.nS, env.nA])
for s in range(env.nS):
Q[s] = q_from_v(env, V, s)
print("Action-Value Function:")
print(Q)
Action-Value Function:
[[ 0.0147094 0.01393978 0.01393978 0.01317015]
[ 0.00852356 0.01163091 0.0108613 0.01550788]
[ 0.02444514 0.02095298 0.02406033 0.01435346]
[ 0.01047649 0.01047649 0.00698432 0.01396865]
[ 0.02166487 0.01701828 0.01624865 0.01006281]
[ 0. 0. 0. 0. ]
[ 0.05433538 0.04735105 0.05433538 0.00698432]
[ 0. 0. 0. 0. ]
[ 0.01701828 0.04099204 0.03480619 0.04640826]
[ 0.07020885 0.11755991 0.10595784 0.05895312]
[ 0.18940421 0.17582037 0.16001424 0.04297382]
[ 0. 0. 0. 0. ]
[ 0. 0. 0. 0. ]
[ 0.08799677 0.20503718 0.23442716 0.17582037]
[ 0.25238823 0.53837051 0.52711478 0.43929118]
[ 0. 0. 0. 0. ]]
运行以下代码单元格以测试你的函数。如果代码单元格返回 PASSED,则表明你正确地实现了该函数!
注意:为了确保结果准确,确保 q_from_v 函数满足上文列出的要求(具有四个输入、一个输出,并且没有更改输入参数的默认值)。
check_test.run_check('q_from_v_check', q_from_v)
PASSED
第 3 部分:策略改进
在此部分,你将自己编写策略改进实现。
你的算法应该有三个输入参数:
env:这是 OpenAI Gym 环境的实例,其中env.P会返回一步动态特性。V:这是一个一维 numpy 数组,其中V.shape[0]等于状态数量 (env.nS)。V[s]包含状态s的估值。gamma:这是折扣率。它必须是在 0 到 1(含)之间的值,默认值为:1。
该算法会返回以下输出结果:
policy:这是一个二维 numpy 数组,其中policy.shape[0]等于状态数量 (env.nS) ,policy.shape[1]等于动作数量 (env.nA) 。policy[s][a]返回智能体在状态s时根据该策略选择动作a的概率。
请完成以下代码单元格中的函数。建议你使用你在上文实现的 q_from_v 函数。
def policy_improvement(env, V, gamma=1):
policy = np.zeros([env.nS, env.nA]) / env.nA
for s in range(env.nS):
q = q_from_v(env, V, s, gamma)
# OPTION 1: construct a deterministic policy
# policy[s][np.argmax(q)] = 1
# OPTION 2: construct a stochastic policy that puts equal probability on maximizing actions
best_a = np.argwhere(q==np.max(q)).flatten()
policy[s] = np.sum([np.eye(env.nA)[i] for i in best_a], axis=0)/len(best_a)
return policy
运行以下代码单元格以测试你的函数。如果代码单元格返回 PASSED,则表明你正确地实现了该函数!
注意:为了确保结果准确,确保 policy_improvement 函数满足上文列出的要求(具有三个输入、一个输出,并且没有更改输入参数的默认值)。
在继续转到该 notebook 的下个部分之前,强烈建议你参阅 Dynamic_Programming_Solution.ipynb 中的解决方案。该函数有很多正确的实现方式!
check_test.run_check('policy_improvement_check', policy_improvement)
PASSED
第 4 部分:策略迭代
在此部分,你将自己编写策略迭代的实现。该算法会返回最优策略,以及相应的状态值函数。
你的算法应该有三个输入参数:
env:这是 OpenAI Gym 环境的实例,其中env.P会返回一步动态特性。gamma:这是折扣率。它必须是在 0 到 1(含)之间的值,默认值为:1。theta:这是一个非常小的正数,用于判断策略评估步骤是否足够地收敛于真值函数 (默认值为:1e-8)。
该算法会返回以下输出结果:
policy:这是一个二维 numpy 数组,其中policy.shape[0]等于状态数量 (env.nS) ,policy.shape[1]等于动作数量 (env.nA) 。policy[s][a]返回智能体在状态s时根据该策略选择动作a的概率。V:这是一个一维 numpy 数组,其中V.shape[0]等于状态数量 (env.nS)。V[s]包含状态s的估值。
请完成以下代码单元格中的函数。强烈建议你使用你在上文实现的 policy_evaluation 和 policy_improvement 函数。
import copy
def policy_iteration(env, gamma=1, theta=1e-8):
policy = np.ones([env.nS, env.nA]) / env.nA
while True:
V = policy_evaluation(env, policy, gamma, theta)
new_policy = policy_improvement(env, V)
# OPTION 1: stop if the policy is unchanged after an improvement step
if (new_policy == policy).all():
break;
# OPTION 2: stop if the value function estimates for successive policies has converged
# if np.max(abs(policy_evaluation(env, policy) - policy_evaluation(env, new_policy))) < theta*1e2:
# break;
policy = copy.copy(new_policy)
return policy, V
运行下个代码单元格以解决该 MDP 并可视化输出结果。最优状态值函数已调整形状,以匹配网格世界的形状。
将该最优状态值函数与此 notebook 第 1 部分的状态值函数进行比较。最优状态值函数一直都大于或等于等概率随机策略的状态值函数吗?
# obtain the optimal policy and optimal state-value function
policy_pi, V_pi = policy_iteration(env)
# print the optimal policy
print("\nOptimal Policy (LEFT = 0, DOWN = 1, RIGHT = 2, UP = 3):")
print(policy_pi,"\n")
plot_values(V_pi)
Optimal Policy (LEFT = 0, DOWN = 1, RIGHT = 2, UP = 3):
[[ 1. 0. 0. 0. ]
[ 0. 0. 0. 1. ]
[ 0. 0. 0. 1. ]
[ 0. 0. 0. 1. ]
[ 1. 0. 0. 0. ]
[ 0.25 0.25 0.25 0.25]
[ 0.5 0. 0.5 0. ]
[ 0.25 0.25 0.25 0.25]
[ 0. 0. 0. 1. ]
[ 0. 1. 0. 0. ]
[ 1. 0. 0. 0. ]
[ 0.25 0.25 0.25 0.25]
[ 0.25 0.25 0.25 0.25]
[ 0. 0. 1. 0. ]
[ 0. 1. 0. 0. ]
[ 0.25 0.25 0.25 0.25]]
运行以下代码单元格以测试你的函数。如果代码单元格返回 PASSED,则表明你正确地实现了该函数!
注意:为了确保结果准确,确保 policy_iteratio 函数满足上文列出的要求(具有三个输入、两个输出,并且没有更改输入参数的默认值)。
check_test.run_check('policy_iteration_check', policy_iteration)
PASSED
第 5 部分:截断策略迭代
在此部分,你将自己编写截断策略迭代的实现。
首先,你将实现截断策略评估。你的算法应该有五个输入参数:
env:这是 OpenAI Gym 环境的实例,其中env.P会返回一步动态特性。policy:这是一个二维 numpy 数组,其中policy.shape[0]等于状态数量 (env.nS) ,policy.shape[1]等于动作数量 (env.nA) 。policy[s][a]返回智能体在状态s时根据该策略选择动作a的概率。V:这是一个一维 numpy 数组,其中V.shape[0]等于状态数量 (env.nS)。V[s]包含状态s的估值。max_it:这是一个正整数,对应的是经历状态空间的次数(默认值为:1)。gamma:这是折扣率。它必须是在 0 到 1(含)之间的值,默认值为:1。
该算法会返回以下输出结果:
V:这是一个一维 numpy 数组,其中V.shape[0]等于状态数量 (env.nS)。V[s]包含状态s的估值。
请完成以下代码单元格中的函数。
def truncated_policy_evaluation(env, policy, V, max_it=1, gamma=1):
num_it=0
while num_it < max_it:
for s in range(env.nS):
v = 0
q = q_from_v(env, V, s, gamma)
for a, action_prob in enumerate(policy[s]):
v += action_prob * q[a]
V[s] = v
num_it += 1
return V
接着,你将实现截断策略迭代。你的算法应该接受五个输入参数:
env:这是 OpenAI Gym 环境的实例,其中env.P会返回一步动态特性。max_it:这是一个正整数,对应的是经历状态空间的次数(默认值为:1)。gamma:这是折扣率。它必须是在 0 到 1(含)之间的值,默认值为:1。theta:这是一个非常小的正整数,用作停止条件(默认值为:1e-8)。
该算法会返回以下输出结果:
policy:这是一个二维 numpy 数组,其中policy.shape[0]等于状态数量 (env.nS) ,policy.shape[1]等于动作数量 (env.nA) 。policy[s][a]返回智能体在状态s时根据该策略选择动作a的概率。V:这是一个一维 numpy 数组,其中V.shape[0]等于状态数量 (env.nS)。V[s]包含状态s的估值。
请完成以下代码单元格中的函数。
def truncated_policy_iteration(env, max_it=1, gamma=1, theta=1e-8):
V = np.zeros(env.nS)
policy = np.zeros([env.nS, env.nA]) / env.nA
while True:
policy = policy_improvement(env, V)
old_V = copy.copy(V)
V = truncated_policy_evaluation(env, policy, V, max_it, gamma)
if max(abs(V-old_V)) < theta:
break;
return policy, V
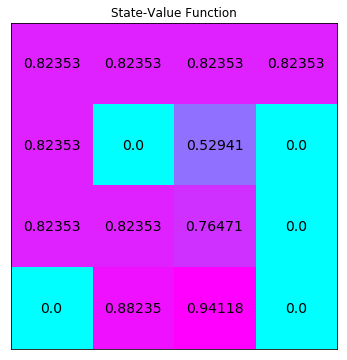
运行下个代码单元格以解决该 MDP 并可视化输出结果。状态值函数已调整形状,以匹配网格世界的形状。
请实验不同的 max_it 参数值。始终都能获得最优状态值函数吗?
policy_tpi, V_tpi = truncated_policy_iteration(env, max_it=2)
# print the optimal policy
print("\nOptimal Policy (LEFT = 0, DOWN = 1, RIGHT = 2, UP = 3):")
print(policy_tpi,"\n")
# plot the optimal state-value function
plot_values(V_tpi)
Optimal Policy (LEFT = 0, DOWN = 1, RIGHT = 2, UP = 3):
[[ 1. 0. 0. 0. ]
[ 0. 0. 0. 1. ]
[ 0. 0. 0. 1. ]
[ 0. 0. 0. 1. ]
[ 1. 0. 0. 0. ]
[ 0.25 0.25 0.25 0.25]
[ 0.5 0. 0.5 0. ]
[ 0.25 0.25 0.25 0.25]
[ 0. 0. 0. 1. ]
[ 0. 1. 0. 0. ]
[ 1. 0. 0. 0. ]
[ 0.25 0.25 0.25 0.25]
[ 0.25 0.25 0.25 0.25]
[ 0. 0. 1. 0. ]
[ 0. 1. 0. 0. ]
[ 0.25 0.25 0.25 0.25]]
运行以下代码单元格以测试你的函数。如果代码单元格返回 PASSED,则表明你正确地实现了该函数!
注意:为了确保结果准确,确保 truncated_policy_iteration 函数满足上文列出的要求(具有四个输入、两个输出,并且没有更改输入参数的默认值)。
check_test.run_check('truncated_policy_iteration_check', truncated_policy_iteration)
PASSED
第 6 部分:值迭代
在此部分,你将自己编写值迭代的实现。
你的算法应该接受三个输入参数:
env:这是 OpenAI Gym 环境的实例,其中env.P会返回一步动态特性。gamma:这是折扣率。它必须是在 0 到 1(含)之间的值,默认值为:1。theta:这是一个非常小的正整数,用作停止条件(默认值为:1e-8)。
该算法会返回以下输出结果:
policy:这是一个二维 numpy 数组,其中policy.shape[0]等于状态数量 (env.nS) ,policy.shape[1]等于动作数量 (env.nA) 。policy[s][a]返回智能体在状态s时根据该策略选择动作a的概率。V:这是一个一维 numpy 数组,其中V.shape[0]等于状态数量 (env.nS)。V[s]包含状态s的估值。
def value_iteration(env, gamma=1, theta=1e-8):
V = np.zeros(env.nS)
while True:
delta = 0
for s in range(env.nS):
v = V[s]
V[s] = max(q_from_v(env, V, s, gamma))
delta = max(delta,abs(V[s]-v))
if delta < theta:
break
policy = policy_improvement(env, V, gamma)
return policy, V
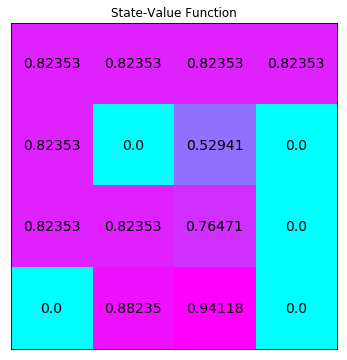
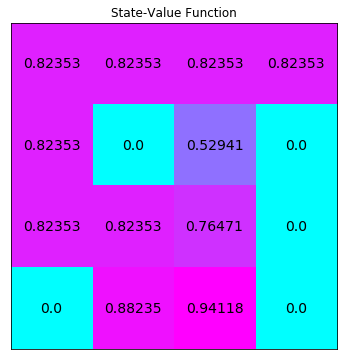
运行下个代码单元格以解决该 MDP 并可视化输出结果。状态值函数已调整形状,以匹配网格世界的形状。
policy_vi, V_vi = value_iteration(env)
# print the optimal policy
print("\nOptimal Policy (LEFT = 0, DOWN = 1, RIGHT = 2, UP = 3):")
print(policy_vi,"\n")
# plot the optimal state-value function
plot_values(V_vi)
Optimal Policy (LEFT = 0, DOWN = 1, RIGHT = 2, UP = 3):
[[ 1. 0. 0. 0. ]
[ 0. 0. 0. 1. ]
[ 0. 0. 0. 1. ]
[ 0. 0. 0. 1. ]
[ 1. 0. 0. 0. ]
[ 0.25 0.25 0.25 0.25]
[ 0.5 0. 0.5 0. ]
[ 0.25 0.25 0.25 0.25]
[ 0. 0. 0. 1. ]
[ 0. 1. 0. 0. ]
[ 1. 0. 0. 0. ]
[ 0.25 0.25 0.25 0.25]
[ 0.25 0.25 0.25 0.25]
[ 0. 0. 1. 0. ]
[ 0. 1. 0. 0. ]
[ 0.25 0.25 0.25 0.25]]
运行以下代码单元格以测试你的函数。如果代码单元格返回 PASSED,则表明你正确地实现了该函数!
注意:为了确保结果准确,确保 truncated_policy_iteration 函数满足上文列出的要求(具有三个输入、两个输出,并且没有更改输入参数的默认值)。
check_test.run_check('value_iteration_check', value_iteration)
PASSED
posted on 2019-02-13 19:09 paulonetwo 阅读(599) 评论(0) 编辑 收藏 举报

