

机器学习工程师 - Udacity 强化学习 Part Two
三、强化学习框架:解决方案
1.状态值函数

2.贝尔曼方程
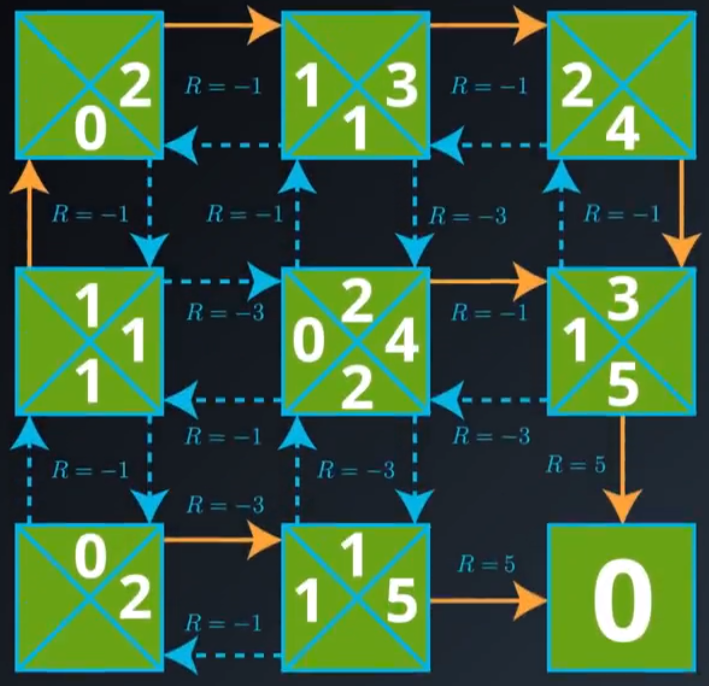
在这个网格世界示例中,一旦智能体选择一个动作,
1)它始终沿着所选方向移动(而一般 MDP 则不同,智能体并非始终能够完全控制下个状态将是什么)
2)可以确切地预测奖励(而一般 MDP 则不同,奖励是从概率分布中随机抽取的)。
在这个简单示例中,我们发现任何状态的值可以计算为即时奖励和下个状态(折扣)值的和。
对于一般 MDP,我们需要使用期望值,因为通常即时奖励和下个状态无法准确地预测,奖励和下个状态是根据 MDP 的一步动态特性选择的。在这种情况下,奖励 r 和下个状态 s' 是从(条件性)概率分布 p(s',r|s,a) 中抽取的,贝尔曼预期方程(对于 vπ)表示了任何状态 s 对于预期即时奖励和下个状态的预期值的值:
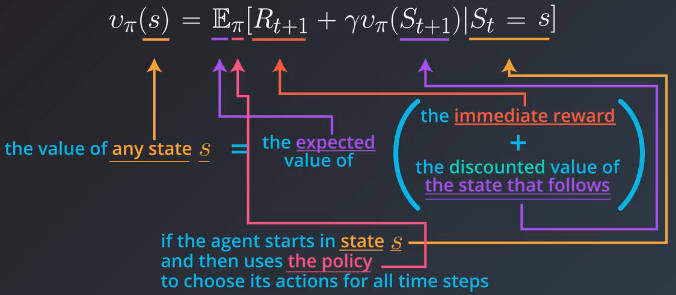
vπ(s)=Eπ[Rt+1+γvπ(St+1)∣St=s].
计算预期值
如果智能体的策略 π 是确定性策略,智能体在状态 s 选择动作 π(s),贝尔曼预期方程可以重写为两个变量 (s 和 r) 的和:
vπ(s)=∑s′∈S+,r∈Rp(s′,r∣s,π(s))(r+γvπ(s′))
在这种情况下,我们将奖励和下个状态的折扣值之和 (r+γvπ(s′)) 与相应的概率 p(s′,r∣s,π(s)) 相乘,并将所有概率相加得出预期值。
如果智能体的策略 π 是随机性策略,智能体在状态 s 选择动作 a 的概率是 π(a∣s),贝尔曼预期方程可以重写为三个变量(s' 、r 和 a)的和:
vπ(s)=∑s′∈S+,r∈R,a∈A(s)π(a∣s)p(s′,r∣s,a)(r+γvπ(s′))
在这种情况下,我们将奖励和下个状态的折扣值之和 (r+γvπ(s′)) 与相应的概率 π(a∣s)p(s′,r∣s,a) 相乘,并将所有概率相加得出预期值。
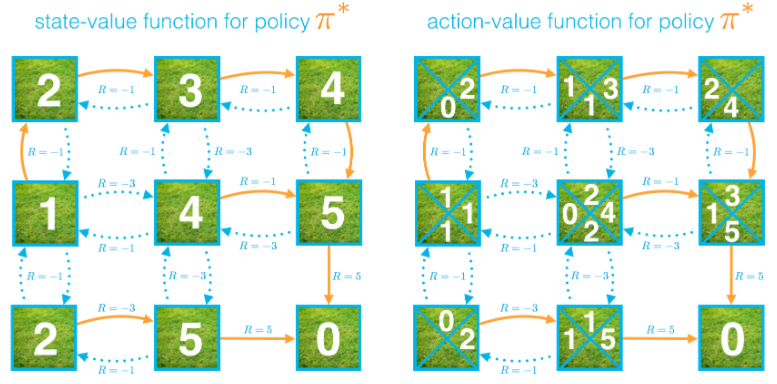
3.动作值函数
4.最优性

5.对于确定性策略 π,vπ(s)=qπ(s,π(s))适用于所有 s∈S:
6.最优策略
智能体与环境互动,通过该互动,估算出最优动作值函数,然后智能体使用该值函数得出最优策略。
如果状态空间 S 和动作空间 A 是有限的,我们可以用表格表示最优动作值函数 q∗,每个可能的环境状态 s∈S 和动作 a∈A 对应一个策略。
特定状态动作对 s,a 的值是智能体从状态 s 开始并采取动作 a,然后遵守最优策略 π∗所获得的预期回报。
我们在下方为虚拟马尔可夫决策流程 (MDP) (where S={s1,s2,s3} 和 A={a1,a2,a3}) 填充了一些值。
智能体确定最优动作值函数 q∗后,它可以为所有 s∈S 设置 π∗(s)=argmaxa∈A(s)q∗(s,a) 快速获得最优策略 π∗。
要了解为何是这种情况,注意,必须确保 v∗(s)=maxa∈A(s)q∗(s,a)。
如果在某个状态 s∈S 中,a∈A(s) 可以最大化最优动作值函数,你可以通过向任何(最大化)状态分配任意大小的概率构建一个最优策略。只需确保根据该策略给不会最大化动作值函数的动作(对于特定状态)分配的概率是 0% 即可。
为了构建最优策略,我们可以先在每行(或每个状态)中选择最大化动作值函数的项。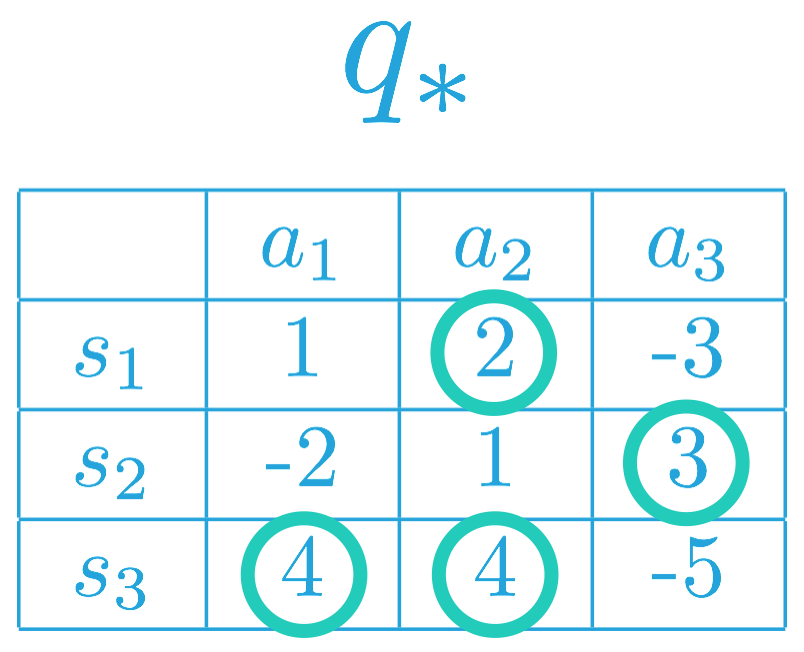
因此,相应 MDP 的最优策略 π∗ 必须满足:
π∗(s1) = a2(or, equivalently, π∗(a2∣s1)=1),以及
π∗(s2)=a3(or, equivalently, π∗(a3∣s2)=1)。
这是因为 a2=argmaxa∈A(s1)q∗(s,a),以及 a3=argmaxa∈A(s2)q∗(s,a)。
换句话说,在最优策略下,智能体在状态 s1下必须选择动作 a2,在状态 s2下将选择动作 a3。
对于状态 s3,注意 a1,a2∈argmaxa∈A(s3)q∗(s,a)。因此,智能体可以根据最优策略选择动作 a1或 a2,但是始终不能选择动作 a3。即最优策略 π∗ 必须满足:
π∗(a1∣s3)=p,
π∗(a2∣s3)=q,以及
π∗(a3∣s3)=0,
其中 p,q≥0 以及 p+q=1。
7.贝尔曼方程(第 2 部分)
有两组贝尔曼方程:(1) 贝尔曼预期方程 和 (2) 贝尔曼最优性方程。每组方程包含两个方程,对应于状态值或动作值。
所有贝尔曼方程对有限马尔可夫决策流程 (MDP) 来说都非常有用。
贝尔曼预期方程
我们已经介绍了 vπ 的贝尔曼预期方程
vπ(s)=Eπ[Rt+1+γvπ(St+1)∣St=s]。
对于任意随机性策略 π,该方程可以表示为
vπ(s)=∑s′∈S+,r∈R,a∈A(s)π(a∣s)p(s′,r∣s,a)(r+γvπ(s′))。
该方程表示了任何状态(根据任意策略)相对于后续状态(根据同一策略)的值。
qπ的贝尔曼预期方程是:
qπ(s,a)=Eπ[Rt+1+γqπ(St+1,At+1)∣St=s,At=a]=∑s′∈S+,r∈Rp(s′,r∣s,a)(r+γ∑a′∈A(s)π(a′∣s′)qπ(s′,a′))
其中最后一个形式详细介绍了如何计算任意随机策略 π 的预期值。该方程表示任何状态动作对(根据任意策略)相对于后续状态的值(根据同一策略)的值。
贝尔曼最优性方程
和贝尔曼预期方程相似,贝尔曼最优性方程可以证明:状态值(以及动作值函数)满足递归关系,可以将状态值(或状态动作对的值)与所有后续状态(或状态动作对)的值联系起来。
虽然贝尔曼最优性方程关心的是任意策略,但是贝尔曼最优性方程完全侧重于最优策略对应的值满足的关系。
v∗的贝尔曼最优性方程是:
v∗(s)=maxa∈A(s)E[Rt+1+γv∗(St+1)∣St=s]=maxa∈A(s)∑s′∈S+,r∈Rp(s′,r∣s,a)(r+γv∗(s′))
它表示任何状态根据最优策略相对于后续状态的值(根据最优策略)的值。
q∗的贝尔曼最优性方程是:
q∗(s,a)=E[Rt+1+γmaxa′∈A(St+1)q∗(St+1,a′)∣St=s,At=a]=∑s′∈S+,r∈Rp(s′,r∣s,a)(r+γmaxa′∈A(s′)q∗(s′,a′))
它表示任何状态动作对根据最优策略相对于后续状态动作对(根据最优策略)的值的值。
实用公式
为了推导出所有四个贝尔曼方程,有必要先推导出紧密相关的公式。
qπ(s,a)=∑s′∈S+,r∈Rp(s′,r∣s,a)(r+γvπ(s′)) (方程 1)
该方程表示相对于状态值函数和 MDP 一步动态特性的策略动作值函数。
我们将提供两个论证来证明该方程,一个是对话论证,另一个是代数论证。
求导 1
我们将先从会话参数开始。当智能体位于状态 s 并采取动作 a 时,可以产生任何数量的潜在下个状态 s′ 和奖励 r。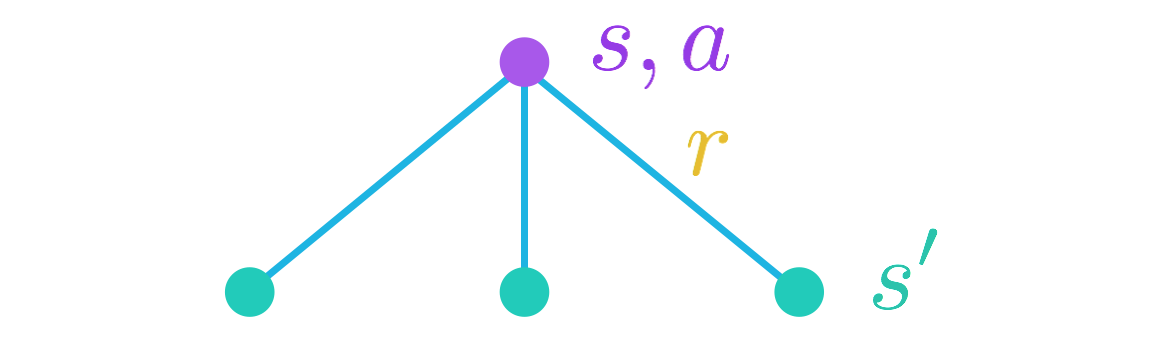
如果下个状态 s′ 和奖励 r 可以确切地预测,那么回报可以计算为 r+γvπ(s′)。
知道这一点后,为了获得动作值 qπ(s,a),我们只需计算和 r+γvπ(s′) 的预期值。可以通过以下方程获得
qπ(s,a)=∑s′∈S+,r∈Rp(s′,r∣s,a)(r+γvπ(s′)),
其中每个 s',r 对的概率由 MDP 的一步动态特性 p(s′,r∣s,a) 确定。
求导 2
请算出以下方程 1 的替代导数。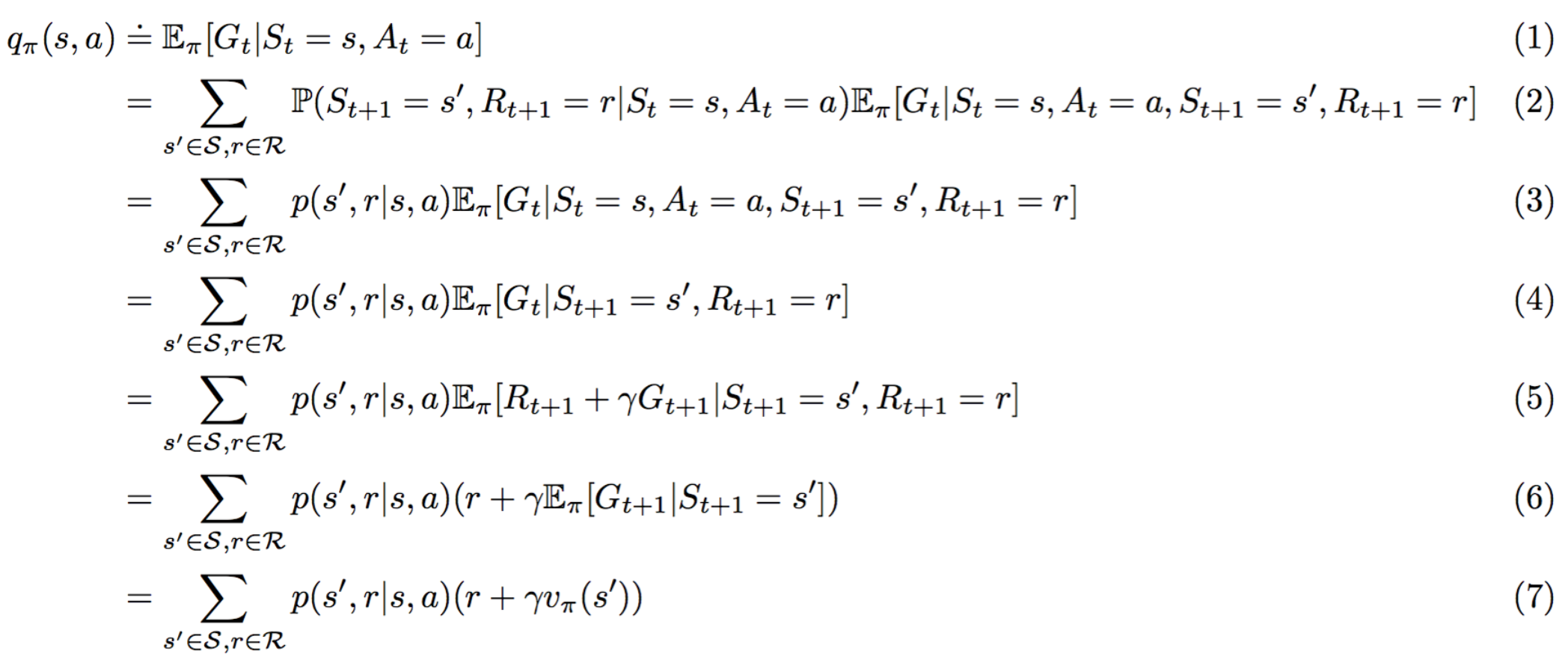
理由如下:
(1) 满足 qπ(s,a)=Eπ[Gt∣St=s,At=a] 的定义。
(2) 遵守全期望公式。
(3) 根据定义 p(s′,r∣s,a)=P(St+1=s′,Rt+1=r∣St=s,At=a) 是正确的
(4) 满足,因为 Eπ[Gt∣St=s,At=a,St+1=s′,Rt+1=r]=Eπ[Gt∣St+1=s′,Rt+1=r]。
(5) 遵守,因为 Gt=Rt+1+γGt+1。
(6) 根据线性期望是正确的。
(7) 根据定义 vπ(s′):=Eπ[Gt∣St=s′]=Eπ[Gt+1∣St+1=s′] 是正确的。
得出贝尔曼预期方程
为了得出贝尔曼预期方程,我们需要使用另一个公式。
vπ(s)=∑a∈A(s)π(a∣s)qπ(s,a)(方程 2)
该方程使我们能够根据(潜在随机性)策略对应的动作值函数获得状态值函数。
vπ 的贝尔曼预期方程可以通过先从方程 2 开始并用方程 1 替换 qπ(s,a) 的值获得。
同样,qπ 的贝尔曼预期方程可以通过先从方程 1 开始并用方程 2 替换 vπ(s) 的值获得。
获得贝尔曼最优性方程
为了推出贝尔曼最优性方程,我们需要另外两个方程。
q∗(s,a)=∑s′∈S+,r∈Rp(s′,r∣s,a)(r+γv∗(s′)) (方程 3)
方程 3 表示相对于最优状态值函数和 MDP 一步动态特性的最优动作值函数。
v∗(s)=maxa∈A(s)q∗(s,a) (方程 4)
方程 4 表示相对于最优动作值函数的最优状态值函数。
v∗ 的贝尔曼最优性方程可以通过先从方程 4 开始并用方程 3 替换 q∗(s,a) 的值获得。
q∗ 的贝尔曼最优性方程可以通过先从方程 3 开始并用方程 4 替换 v∗(s) 的值获得。
posted on 2018-12-10 20:36 paulonetwo 阅读(328) 评论(0) 编辑 收藏 举报


