

机器学习工程师 - Udacity 强化学习 Part One
一、简介
1.强化学习简称RL,即Reinforcement Learning。
2.应用
-
了解 AlphaGo Zero,一款先进的计算机程序,打败了专业人类围棋手。
-
了解如何使用强化学习 (RL) 玩Atari 游戏。
-
了解打败全世界的顶级 Dota 2 玩家的 OpenAI 机器人。
-
了解指导仿真机器人如何行走的研究。
-
了解无人驾驶车强化学习。
-
要了解应用于金融领域的强化学习示例,请参阅这个最终项目,该项目的作者是一位毕业于机器学习工程师纳米学位的学员。
-
了解电信强化学习。
-
阅读这篇介绍库存管理强化学习的论文。
3.智能体需要在以下两种情形之间找到平衡点:
1)exploration,探索如何选择动作的潜在假设;
2)exploitation,利用已有的可行有限知识。
同时,智能体不仅关心现在可以获得的奖励,而且要最大化长期可以获得的奖励数量。
4.OpenAI Gym
你可以通过查看该 GitHub 代码库详细了解 OpenAI Gym。
建议你花时间查看 leaderboard,其中包含每个任务的最佳解决方案。
请参阅此博客帖子,详细了解如何使用 OpenAI Gym 加速强化学习研究。
5.资源
关于强化学习的经典教科书:Reinforcement Learning: An Introduction。
参阅此 GitHub 代码库以查看该教科书中的大多数图表的 Python 实现。
二、强化学习框架:问题
1.阶段性任务与连续性任务
具有清晰结束点的任务称之为阶段性任务。当某个阶段结束后,智能体会查看奖励总量,并判断自己的表现如何,然后带着之前的经验从头开始。
一直持续下去的任务称之为连续性任务,例如,根据金融市场买入和卖出股票的算法。
2.目标和奖励
如果想详细了解 DeepMind 的研究成果,请参阅此链接。研究论文位于此处。此外,观看这个非常酷的视频(链接来自Youtube)。
3.累计奖励
智能体如何通过与环境互动实现目标这种框架适合很多现实应用,框架将互动简化为在智能体和环境之间传递的三种信号,状态信号是环境向智能体呈现情形的方式,智能体做出动作响应并影响到环境,环境做出奖励响应,表示智能体是否对环境做出了正确响应。该框架还包括智能体目标,即最大化累计奖励。
4.折扣回报
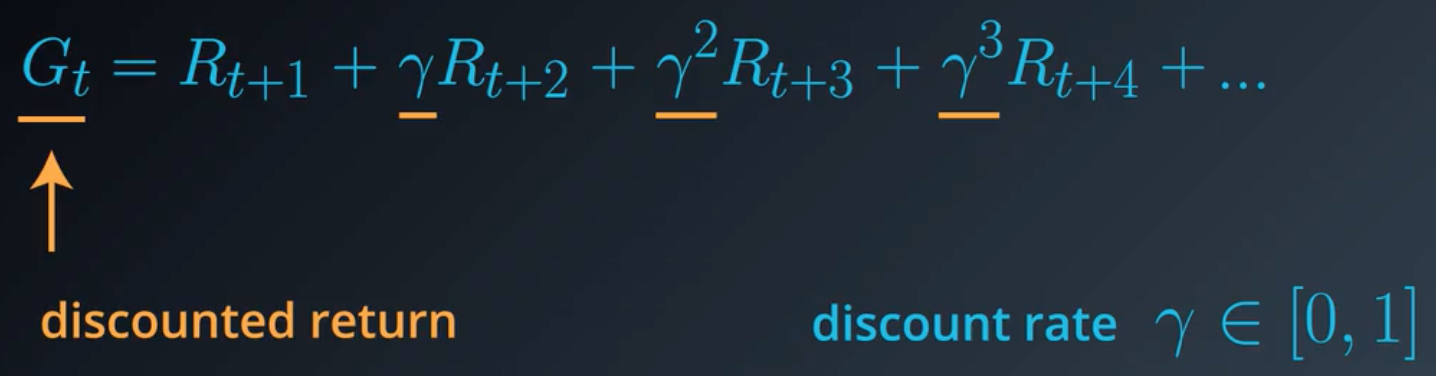
5.杆平衡
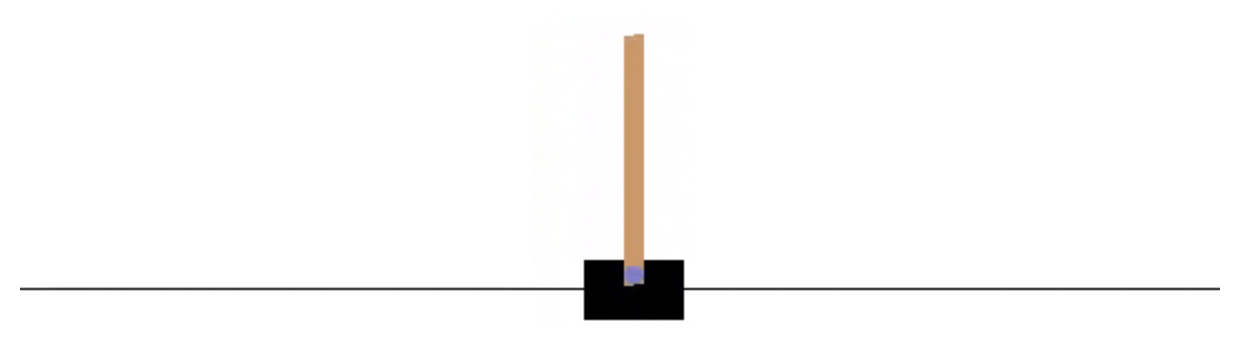
在这个经典的强化学习任务中,在光滑的道路上有一辆购物车,购物车的顶部插着一根杆子。目标是通过使购物车向左或向右移动,防止杆子掉下来,并且购物车不会脱离轨道。
在 OpenAI Gym 实现中,智能体在每个时间步都向购物车应用 +1 或 -1 的力。它是一个阶段性任务,在以下情况下这一阶段会结束:(1) 杆子与垂直方向的夹角超过 20.9 度,(2) 购物车离道路中心的距离超过 2.4 个单位,或者 (3) 时间步超过了 200 步。对于每个时间步,购物车都获得奖励 +1,包括最终时间步。你可以在 OpenAI 的 github 中详细了解该环境。该任务还出现在了教科书的第 3.4 个示例中。
习题 1/3
智能体在每个时间步都获得奖励 +1,包括最终时间步。哪些折扣率会鼓励智能体尽量使杆子保持平衡?(请选中所有适用项。)
A.折扣率为 1。
B.折扣率为 0.9。
C.折扣率为 0.5。
习题 2/3
假设我们对奖励信号进行了修改,仅在阶段结束时向智能体提供奖励。因此在每个时间步,奖励都是 0,但是最终时间步除外。当阶段结束时,智能体获得奖励 -1。哪些折扣率会鼓励智能体尽量使杆子保持平衡?(请选中所有适用项。)
A.折扣率是 1。
B.折扣率是 0.9。
C.折扣率是 0.5。
D.所有这些折扣率都无法帮助智能体,因为没有奖励信号。
答案:BC。
解析:没有折扣的话,智能体将始终获得奖励 -1(无论在阶段过程中选择哪个动作),因此奖励信号将不会向智能体提供任何实用的反馈。有了折扣后,智能体将尽量使杆子保持平衡,因为这样会形成相对来说不是太负面的回报。
习题 3/3
假设我们对奖励信号进行了修改,仅在阶段结束时向智能体提供奖励。因此在每个时间步,奖励都是 0,但是最终时间步除外。当阶段结束时,智能体获得奖励 +1。哪些折扣率会鼓励智能体尽量使杆子保持平衡?(请选中所有适用项。)
A.折扣率是 1。
B.折扣率是 0.9。
C.折扣率是 0.5。
D.所有这些折扣率都无法帮助智能体,因为没有奖励信号。
答案:D。
解析:如果折扣率是 1,智能体将始终获得奖励 +1(无论它在这一阶段中选择哪些动作),因此奖励信号将不会向智能体提供任何实用反馈。如果折扣率是 0.5 或 0.9,智能体将尝试尽快结束这一阶段(通过快速扔下杆子或离开轨道边缘)。因此,我们必须重新设计奖励信号!
6.通常,状态空间 S 是指所有非终止状态集合。在连续性任务中,就相当于所有状态集合。在阶段性任务中,我们使用 S+ 表示所有状态(包括终止状态)集合。
动作空间 A 是指智能体可以采取的动作集合。如果在某些状态下,只能采取部分动作,我们还可以使用 A(s) 表示在状态 s∈S 下可以采取的动作集合。
7.一步动态特性:可以在任何时间步确定状态和奖励的一种方法。
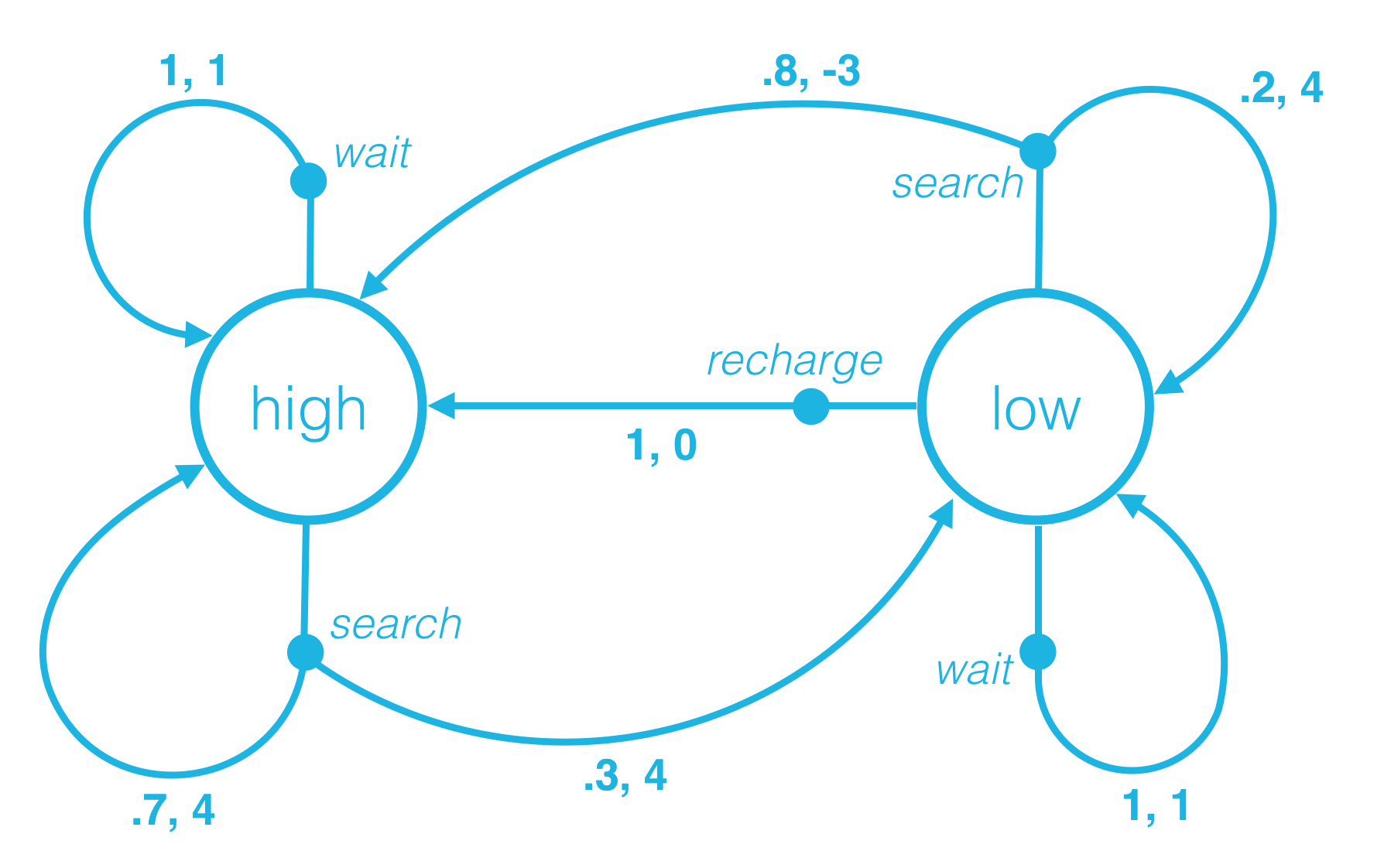
在随机时间步 t,智能体环境互动变成一系列的状态、动作和奖励。
(S0,A0,R1,S1,A1,…,Rt−1,St−1,At−1,Rt,St,At)
当环境在时间步 t+1 对智能体做出响应时,它只考虑上一个时间步 (St,At) 的状态和动作。
尤其是,它不关心再上一个时间步呈现给智能体的状态。(换句话说,环境不考虑任何 {S0,…,St−1}。)
并且,它不考虑智能体在上个时间步之前采取的动作。(换句话说,环境不考虑任何 {A0,…,At−1}。)
此外,智能体的表现如何,或收集了多少奖励,对环境选择如何对智能体做出响应没有影响。(换句话说,环境不考虑任何 {R0,…,Rt}。)
因此,我们可以通过指定以下设置完全定义环境如何决定状态和奖励
p(s′,r∣s,a)≐P(St+1=s′,Rt+1=r∣St=s,At=a)
对于每个可能的 s′,r,s,and a。这些条件概率用于指定环境的一步动态特性。
例如,考虑St=high、At=search 的情况。
当环境在下个时间步对智能体做出响应时
-
下个时间步是电量很高的概率为 70%,奖励为 4。换句话说,p(high,4∣high,search)=P(St+1=high,Rt+1=4∣St=high,At=search)=0.7。
-
下个时间步是电量很低的概率为 30%,奖励为 4。换句话说,p(low,4∣high,search)=P(St+1=low,Rt+1=4∣St=high,At=search)=0.3
8.MDP(马尔可夫决策流程)

连续性任务需要将折扣率设为小于1,否则,智能体需要查看无限的未来。通常,将折扣率设为0.9比较合适。折扣率需设置为非常接近1而不是0的某个值,否则,智能体将出现看不清故障的情况。
9.有限 MDP
使用此链接获取 OpenAI Gym 中的可用环境。

环境索引为环境 ID,每个环境都有对应的观察空间、动作空间、奖励范围、tStepL、Trials 和 rThresh。
CartPole-v0:
在表格中查找对应于 CartPole-v0 环境的行。请记下相应的观察空间 (Box(4,)) 和动作空间 (Discrete(2))。

正如在 OpenAI Gym 文档中所描述的情况:
每个环境都有第一类
Space对象,描述了有效的动作和观察结果。
Discrete空间允许存在固定范围的非负数。Box空间表示 n 维方框,因此有效动作或观察结果将是一个有 n 个数字的数组。
观察空间:
CartPole-v0 环境的观察空间有一个笔误:Box(4,)。因此,在每个时间点的观察结果(或状态)是有 4 个数字的数组。你可以在此文档中查看每个数字表示的含义。打开该页面后,向下滚动到观察空间的说明部分。

注意购物车速度和杆子顶端速度的最小值 (-Inf) 和最大值 (Inf)。
因为数组中的条目对应的每个索引可以是任何实数,所以状态空间 S+ 是无限的!
动作空间:
CartPole-v0 环境的动作空间类型为 Discrete(2)。因此,在任何时间点,智能体只能采取两个动作。你可以在此文档(和查找观察空间使用的文档一样!)中查看每个数字表示的含义。打开该页面后,向下滚动到动作空间的说明部分。

在这种情况下,动作空间 A 是一组有限的集合,仅包含两个元素。
有限 MDP:
在有限的 MDP 中,状态空间 S(或在阶段性任务中为 S+)和动作空间 A 必须都是有限的。
posted on 2018-12-08 13:05 paulonetwo 阅读(433) 评论(0) 编辑 收藏 举报


