

机器学习工程师 - Udacity 深度学习
一、神经网络
1.为了进行梯度下降,误差函数不能是离散的,而必须是连续的。误差函数必须是可微分的。同时,要将离散预测变成连续预测,方法是将激活函数从阶跃函数变成S函数。
2.最大似然法:选出实际发生的情况所对应的概率更大的模型。
3.交叉熵(损失函数):将得到的概率取对数,对它们的相反数进行求和。准确的模型得到较低的交叉熵。
交叉熵可以告诉我们两个向量是相似还是不同。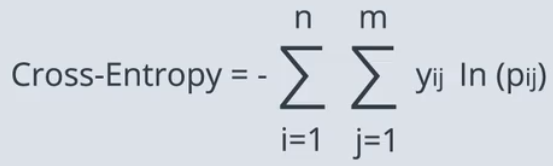
4.Logistic回归(对数几率回归)
机器学习中最热门和最有用的算法之一,也是所有机器学习的基石。基本上是这样的:
1)获得数据;
2)选择一个随机模型;
3)计算误差;
4)最小化误差,获得更好的模型;
5)完成!
计算误差函数: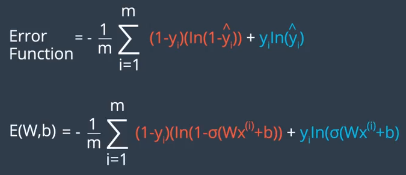
5.感知器算法和对数概率很相似,分类错误的点都会告诉直线靠近点,不同的是对于分类正确的点,感知器算法会说什么也不要做,而对数概率会说远离它。
二、深度神经网络
1.使用L1和L2的通用规则:
L1:希望得到稀疏向量,即较小权重趋向于0;有利于特征选择,我们有时会遇到几百个特征,L1可以帮助选择哪一些更重要,然后将其余的变为0。
L2:不支持稀疏向量,因为它确保所有权重一致较小;一般可以用于训练模型得出更好的结果,所以是最常用的。
例如向量(1,0),权重绝对值的和是1,权重平方的和也是1,向量(0.5,0.5),权重绝对值的和还是1,权重平方的和是0.5,那么L2更倾向于向量(0.5,0.5),因为它可以得出更小的平方和,即更小的误差函数。
2.Dropout:随机关闭某些节点,以使得其他节点得到更好的训练。
3.s函数两端的梯度很小,可能导致梯度消失。我们可以考虑别的激活函数:
1)双曲正切
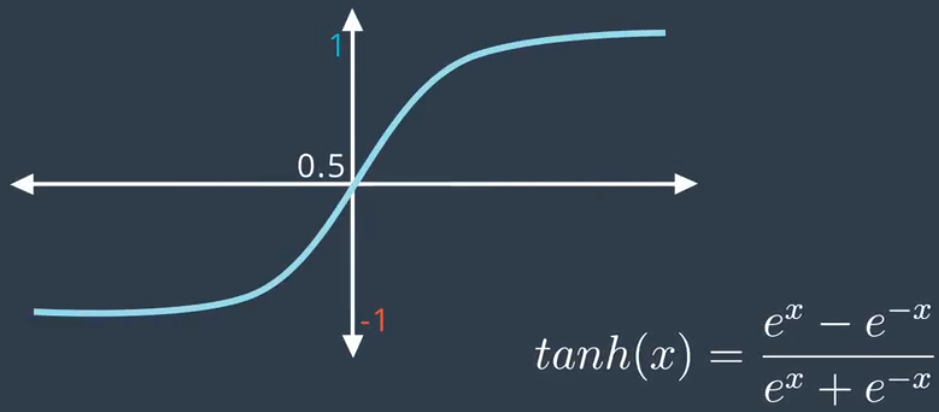
由于函数值范围在-1到1之间,导数更大,这使得神经网络效果更好。
2)修正线性单元
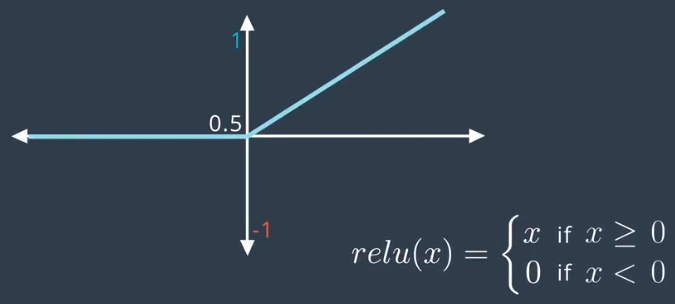
除了sigmoid之外最常用的函数,可以在不牺牲精确度的前提下极大提高训练效果。因为如果值为正,则导数等于1,所以这个函数很少会打破线性得出复杂的非线性解。
4.学习速率:如果学习速率太大,那么采取的就是很大的步长,一开始可能训练速度很快,但是会错过最低值,并继续前进,这样将使模型很混乱;如果学习速率很小,模型速度会很慢,更有可能到达局部最低值。好的经验是,如果模型不可行,则降低学习速率;最佳学习速率是,在模型越来越接近解决方案时会越来越小。
5.解决局部最优,一种方法是随机重新开始,从几个随机的不同地点开始,从所有这些地点进行梯度下降;
一种是动量:

使用动量的算法在实际中运作得很好。
6.Keras 优化程序
Keras 中有很多优化程序,这些优化程序结合使用了上述技巧,以及其他一些技巧。最常见的包括:
1)SGD,随机梯度下降。它使用了以下参数:
a.学习速率。
b.动量(获取前几步的加权平均值,以便获得动量而不至于陷在局部最低点)。
c.Nesterov 动量(当最接近解决方案时,它会减缓梯度)。
2)Adam,Adam (Adaptive Moment Estimation) 使用更复杂的指数衰减,不仅仅会考虑平均值(第一个动量),并且会考虑前几步的方差(第二个动量)。
RMSProp,RMSProp (RMS 表示均方根误差)通过除以按指数衰减的平方梯度均值来减小学习速率。
三、卷积神经网络
1.CNN的应用
1)了解 WaveNet 模型。
如果你能训练人工智能机器人唱歌,干嘛还训练它聊天?在 2017 年 4 月,研究人员使用 WaveNet 模型的变体生成了歌曲。原始论文和演示可以在此处找到。
2)了解文本分类 CNN。
3)了解 Facebook 的创新 CNN 方法(Facebook),该方法专门用于解决语言翻译任务,准确率达到了前沿性水平,并且速度是 RNN 模型的 9 倍。
4)利用 CNN 和强化学习玩 Atari 游戏。你可以下载此论文附带的代码。
如果你想研究一些(深度强化学习)初学者代码,建议你参阅 Andrej Karpathy 的帖子。
5)利用 CNN 玩看图说词游戏!
此外,还可以参阅 A.I. Experiments 网站上的所有其他很酷的实现。别忘了 AutoDraw!
6)详细了解 AlphaGo。
阅读这篇文章,其中提出了一个问题:如果掌控 Go“需要人类直觉”,那么人性受到挑战是什么感觉?
7)观看这些非常酷的视频,其中的无人机都受到 CNN 的支持。
这是初创企业 Intelligent Flying Machines (IFM) (Youtube)的访谈。
户外自主导航通常都要借助全球定位系统 (GPS),但是下面的演示展示的是由 CNN 提供技术支持的自主无人机(Youtube)。
8)如果你对无人驾驶汽车使用的 CNN 感兴趣,请参阅:
这些系列博客,其中详细讲述了如何训练用 Python 编写的 CNN,以便生成能够玩“侠盗猎车手”的无人驾驶 AI。
9)其他应用情形。
一些全球最著名的画作被转换成了三维形式,以便视力受损人士也能欣赏。虽然这篇文章没有提到是怎么做到的,我们注意到可以使用 CNN 预测单个图片的深度。
参阅这篇关于使用 CNN 确定乳腺癌位置的研究论文。
CNN 被用来拯救濒危物种!
一款叫做 FaceApp 的应用使用 CNN 让你在照片中是微笑状态或改变性别。
2.Dropout:建议从小值开始,看看网络有何响应,有必要增大的话再增大。
参阅首篇建议将 dropout 用作避免过拟合技巧的研究论文。
想详细了解激活函数,访问此网站。
3.多分类任务使用分类交叉熵作为损失函数。
损失函数是用来估量模型中预测值y与真实值Y之间的差异,即不一致程度。
在 Keras 中,你可以通过为 kernel_initializer 和 bias_initializer 参数提供值更改权重的初始化方法。注意默认值分别为 'glorot_uniform' 和 'zeros'。
Keras 中有很多不同的损失函数:
'sgd' : SGD
'rmsprop' : RMSprop
'adagrad' : Adagrad
'adadelta' : Adadelta
'adam' : Adam
'adamax' : Adamax
'nadam' : Nadam
'tfoptimizer' : TFOptimizer
4.在训练过程中,你可以使用很多回调(例如 ModelCheckpoint)来监控你的模型。建议先详细了解 EarlyStopping 回调。如果想查看另一个 ModelCheckpoint 代码示例,请参阅这篇博文。
5.密集层:完全连接;卷积层:局部连接,具有参数共享特性(过滤器参数)。对于CNN,我们不会指定过滤器值,或者告诉CNN它需要检测什么样的规律,而是从数据中学习。
6.池化层:论文network in network。
7.图片分类CNN
CNN中,我们经常会重新调整图片的大小,变成正方形,并使空间维度(宽和高)等于2的幂次方,或者可以被2的幂次方整除的数。
无论彩色图片还是灰度图片,输入数组的宽和高始终会大于深度。CNN架构的设计目标是获取该输入,然后逐渐使其深度大于宽和高。
卷积层用于使穿过卷积层的数组更深,最大池化层将用于减小空间维度。
过滤器经常是正方形,大小范围从2*2到5*5。
stride通常设为1。在keras中1是默认值。
对于填充,如果将其设为'same',将获得更好的结果。在keras中这不是默认值。
filters,过滤器数量,控制的是卷积层的深度。通常,我们会让过滤器数量逐渐递增。
最大池化层通常紧跟在序列中的一个或两个卷积层后面。最常见的设置是使用大小为2,stride为2的过滤器。这样可以使空间维度变成上一层级的一半。
CNN发现了图片中包含的空间规律,它逐渐获取空间数据,并将图片内容用数组表示。所有空间信息最终会丢失。在原始图片中,很容易知道各个像素与其他哪些像素相邻,但在最终的数组中,条目与谁相邻不重要,相反,数组可以回答以下问题:图片中有轮子吗?有眼睛吗?有毛茸茸的腿或尾巴吗?
一旦我们获得的表示不再具有图片中的空间信息,我们就可以扁平化该数组,并将其提供给一个或多个全连接层,判断图片中包含什么对象。
注意事项:
始终向 CNN 中的 Conv2D 层添加 ReLU 激活函数。但是网络的最后层级除外,密集层也应该具有 ReLU 激活函数。
在构建分类网络时,网络中的最后层级应该是具有 softmax 激活函数的 密集层。最后层级的节点数量应该等于数据集中的类别总数。
参阅 CIFAR-10 竞赛的获胜架构!
8.Keras中的图片增强功能:ImageDataGenerator
只要拟合通过ImageDataGenerator类生成的CNN增强图片,就始终需要将fit命令改成fit_generator。
现实中经常会使用增强处理来改善CNN模型的效果。
阅读这篇对 MNIST 数据集进行可视化的精彩博文。
参阅此详细实现,了解如何使用增强功能提高 Kaggle 数据集的效果。
9.突破性的CNN架构
ImageNet是一个拥有超过1千万张手动标记图片的数据库,这些图片来自1000个不同的图片类别。
2012年,多伦多大学开发出AlexNet。AlexNet在使用ReLU激活函数和dropout来避免过拟合这一方面走在了前沿。
2014年,牛津大学开发出VGG(包括VGG16和VGG19)。VGG是一个很长的3*3卷积序列,并穿插着2*2的池化层,最后是三个完全连接层。VGG以独特方式使用很小的3*3卷积窗口与AlexNet的大型11*11窗口形成鲜明对比
2015年,微软开发出ResNet。ResNet和VGG很相似,不同的结构不断重复,一层又一层,同时也具有不同的版本,区别在于层级的数量,最大的网络具有破纪录的152个层级。之前的研究人员也尝试过构建这么深的CNN,但当他们不断添加层级时,效果增强到一定的程度之后就快速下降了,一部分原因是梯度消失问题,当我们通过反向传播训练网络时就会出现该问题,主要原理是梯度信号需要传递到整个网络中,网络越深,很有可能信号在抵达目的地之前就削弱了。ResNet团队在他们的深度CNN中增加了跳过层级的连接,因此梯度信号的传播路径更短。ResNet在ImageNet数据库的图片分类方面取得了惊人的效果。
在Keras中导入ResNet50、VGG16、VGG19等等很简单。
参阅 AlexNet 论文!
在此处详细了解 VGGNet。
此处是 ResNet 论文。
这是用于访问一些著名 CNN 架构的 Keras 文档。
阅读这一关于梯度消失问题的详细处理方案。
这是包含不同 CNN 架构的基准的 GitHub 资源库。
访问 ImageNet Large Scale Visual Recognition Competition (ILSVRC) 网站。
10.可视化CNN
这是摘自斯坦福大学的 CS231n 课程中的一个章节,其中对 CNN 学习的内容进行了可视化。
参阅这个关于很酷的 OpenFrameworks 应用的演示,该应用可以根据用户提供的视频实时可视化 CNN!
这是另一个 CNN 可视化工具的演示。如果你想详细了解这些可视化图表是如何制作的,请观看此视频。
这是另一个可与 Keras 和 Tensorflow 中的 CNN 无缝合作的可视化工具。
阅读这篇可视化 CNN 如何看待这个世界的 Keras 博文。在此博文中,你会找到 Deep Dreams 的简单介绍,以及在 Keras 中自己编写 Deep Dreams 的代码。阅读了这篇博文后:
再观看这个利用 Deep Dreams 的音乐视频(注意 3:15-3:40 部分)!
使用这个网站创建自己的 Deep Dreams(不用编写任何代码!)。
这篇文章详细讲解了在现实生活中使用深度学习模型(暂时无法解释)的一些危险性。
这一领域有很多热点研究。这些作者最近朝着正确的方向迈出了一步。
11.全局平均池化层又称GAP层,MIT的研究人员演示指出,经过分类任务训练并且具有GAP层级的CNN还可以用来进行对象定位,换句话说,这些CNN不仅能告诉我们图片中包含什么对象,而且可以告诉我们对象位于图片的哪个位置。
这是提议将 GAP 层级用于对象定位的首篇研究论文。
参阅这个使用 CNN 进行对象定位的资源库。
观看这个关于使用 CNN 进行对象定位的视频演示(Youtube链接,国内网络可能打不开)。
参阅这个使用可视化机器更好地理解瓶颈特征的资源库。
12.如果在训练一个神经网络时,你留意到一些节点的权重很低,并且对模型没有多大贡献,你可以采取什么方法来解决这个问题?
A.L1正则化
B.L2正则化
C.Dropout
D.集成学习
答案:C
13.你已为分类任务设计了CNN架构,并且你注意到你的模型过拟合。 以下哪一个选项最有可能减少过拟合?
A.增加卷积层的数量
B.降低每个卷积层中的过滤器大小
C.减少每个卷积层中的过滤器数量
D.降低每个最大池化层中的内核大小
答案:C
14.确保CNN分类器能检测在图像数据中各种大小和不同位置的对象的最佳方案是什么?
A.添加更多最大池化层
B.添加dropout,并从所有卷积图层中删除'relu'激活函数
C.通过添加包含来自更多类别的对象的图像来扩展训练和验证数据
D.通过增强来扩展现有的训练和验证数据。
答案:D
posted on 2018-11-26 20:54 paulonetwo 阅读(242) 评论(0) 编辑 收藏 举报


