

机器学习工程师 - Udacity 非监督学习 Part Two
四、特征缩放
1.特征缩放的优点:Andrew在他的机器学习课程里强调,在进行学习之前要进行特征缩放,目的是保证这些特征都具有相近的尺度,这将帮助梯度下降算法更快地收敛。
python里常用的是preprocessing.StandardScaler(),公式为:(X-mean)/std,得到的结果是,对于每个属性来说所有数据都聚集在0附近,方差为1。
缺点:如果特征中有异常数值,那么缩放的结果会很不理想。
2.sklearn中的最小值/最大值缩放器
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
y = scaler.fit_transform(x)
3.哪些机器学习算法会受到特征缩放的影响?
□ 决策树
□ 使用 RBF 核函数的 SVM
□ 线性回归
□ K-均值聚类
答案是SVM和K-means。SVM和K-means需要根据不同维度的特征计算距离,而决策树和线性回归只需在不同维度的特征间找到一个切割点。
五、PCA(主成分分析)
1.PCA从旧坐标系统仅通过转化和轮换获得新坐标系统,它将坐标系的中心移至数据的中心,将x轴移至方差最大的位置。
2.最大主成分数量是训练点数量和特征数量这两者中的最小值。
六、随机投影与ICA
1.随机投影是一个很有效的降维方法,在计算上比主成分分析更有效率。它通常应用于当一个数据集里有太多维度,PCA无法直接计算的情境下。PCA选择方差最大的方向,随机投影随机选择一个方向,它在某些情境下没有太大意义。但它其实是有作用的,在更高维度的效果更好,且工作效能更高。
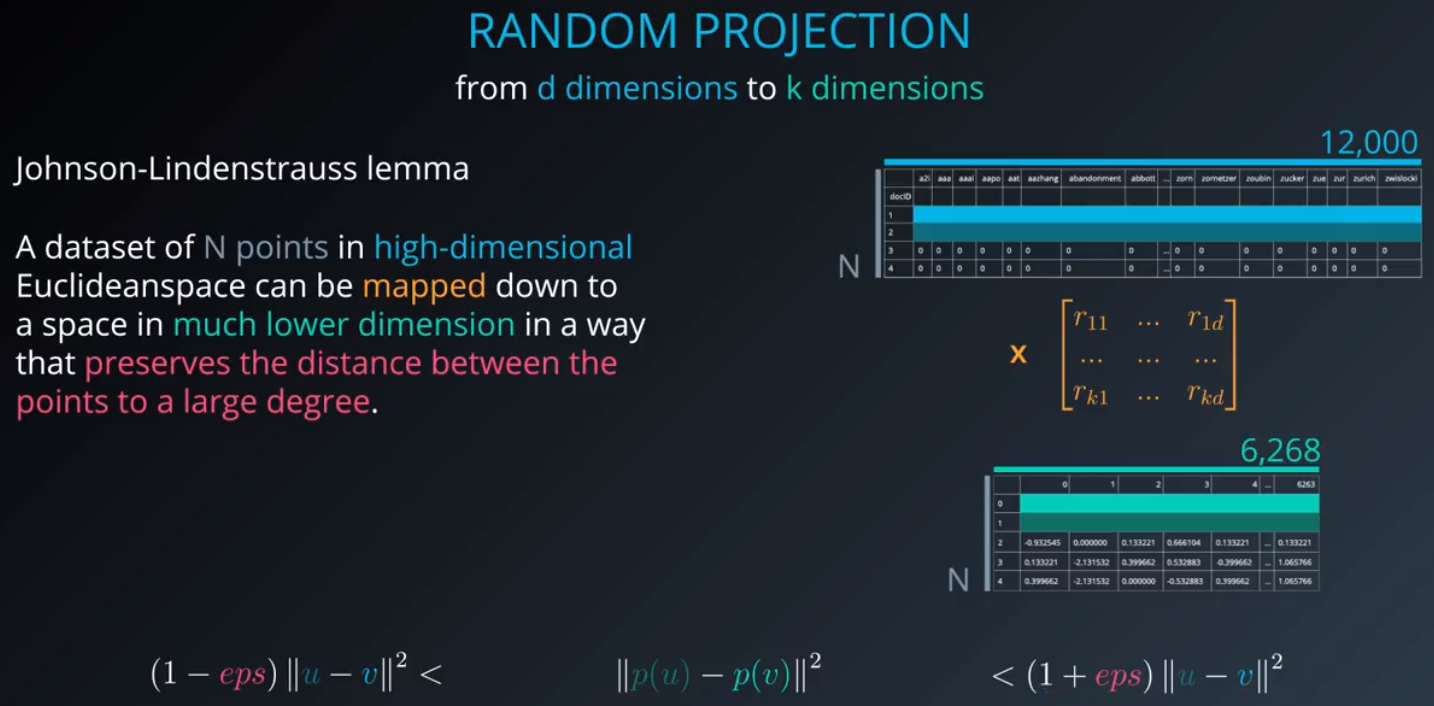
2.sklearn中的随机投影
from sklearn import random_projection
rp = random_projection.SparseRandomProjection()
new_x = rp.fit_transform(x)
稀疏随机投影比高斯随机投影更快速,效果更好。
3.独立成分分析(ICA)
PCA最大化方差,ICA假定这些特征是独力源的混合,并尝试分离这些混合在数据集里的独力源。
盲源分离问题:
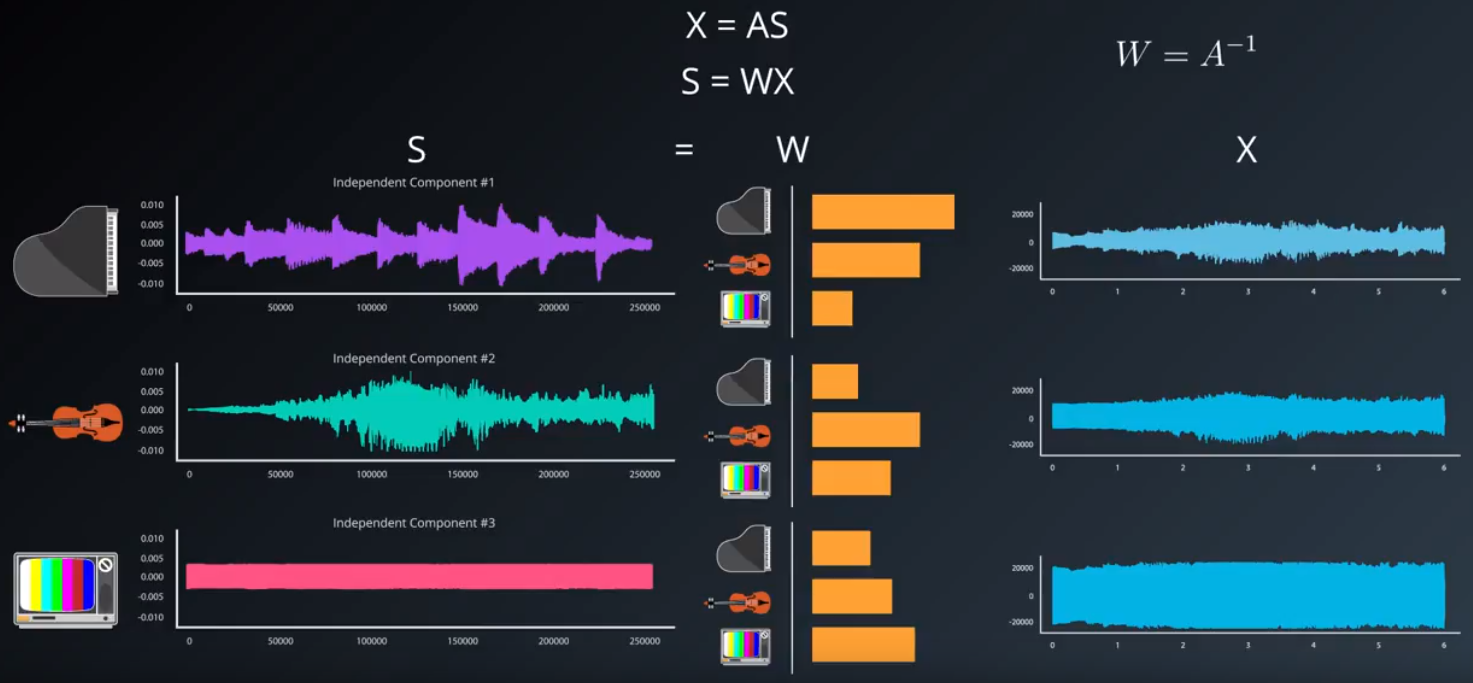
参考文献: "独立成分分析:算法与应用" (pdf)
ICA假设各成分是分别统计的,各成分须为非高斯分布。
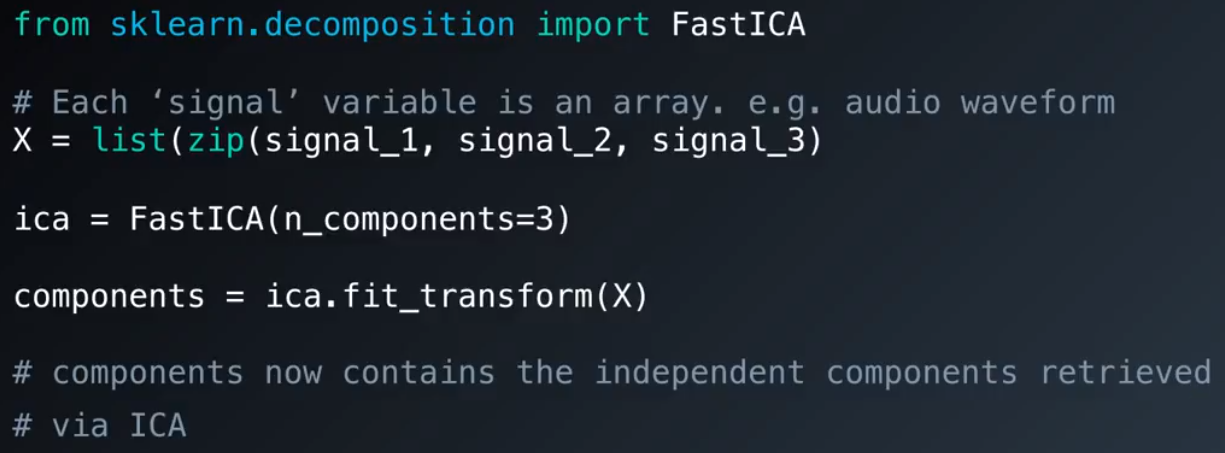
4.sklearn中的Fast ICA算法:
1)居中、白化数据集x;
2)选择一个初始的随机权重矩阵W;
3)预估W,W是包含多个向量的矩阵,每个向量都是权值向量;
4)对W进行去相关操作。即防止W1和W2转化为相同的值;
5)重复第三步,直到找到满意的W值。
5. ICA 需要与我们试图分离的原始信号一样多的观测值。
6.ICA应用
ICA广泛应用于医学扫描仪;有人尝试在财务数据中运用ICA。
7.当你在评估 PCA 中有包含多少组件时,基于你的实际经验,已保留的组件(特征)可以捕获的总变化量是多少比较好?
答案是80%。
posted on 2018-11-22 13:18 paulonetwo 阅读(323) 评论(0) 编辑 收藏 举报


