数据采集与融合技术 实验4
作业①:
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
-
关键词:学生可自由选择
-
输出信息:MySQL的输出信息如下
![avatar]()

1)、当当网图书数据爬取
- 在settings.py文件中进行设置
设置请求头:

打开pipeline:

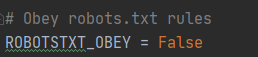
将ROBOTSTXT_OBEY设置为false
- items.py中编写所需字段

- spider.py中编写爬虫部分
parse函数中设置解码信息
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
在网页中查看需爬取数据结点信息

在parse函数中利用xpath进行嵌套爬取
for li in lis:
global countall
title = li.xpath("./a[position()=1]/@title").extract_first()
author = li.xpath("./p[@class='search_book_author']/span/a[position()=1]/@title").extract_first()
publisher = li.xpath("./p[@class='search_book_author']//span/a[@dd_name='单品出版社']/text()").extract_first()
date = li.xpath("./p[@class='search_book_author']//span[2]/text()").extract_first()
price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
将爬取到的数据利用item类传到pipelines,在for循环的最后进行数量限制
global countall
countall += 1
if countall == 413:
break
接下来进行翻页处理
在网页中查看翻页信息:

翻页处理(在处理翻页时同时需要限制爬取数量):
link=selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next']/a/@href").extract_first()
if (link and countall<413) :
url = response.urljoin(link)
yield scrapy.Request(url=url, callback=self.parse,dont_filter=True)
- pipelines.py中对数据进行处理
连接mysql数据库
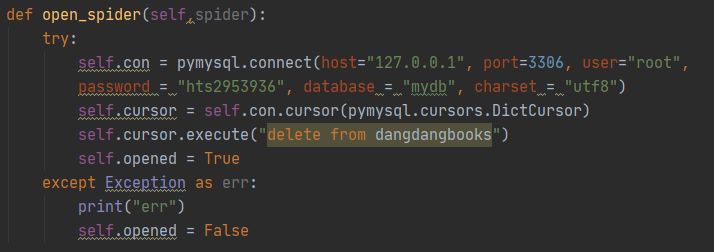
在processitems函数中执行插入数据库语句
其中利用了自增count变量来设置插入的id字段(本来想利用数据库的自增主键,但是数据库没有设置完备插入时出现报错,所以作罢)

- 结果查看
数据库中查看结果如下

爬取数量限制:
2)、心得体会
本次实验加深巩固了scrapy框架的使用方法以及xpath元素定位方法的复习与加强、翻页的处理。爬虫与数据库的结合也得到了巩固。
作业②:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
-
候选网站:招商银行网:http://fx.cmbchina.com/hq/
-
输出信息:MySQL数据库存储和输出格式
Id Currency TSP CSP TBP CBP Time 1 港币 86.60 86.60 86.26 85.65 15:36:30 2......
1)、scrapy爬取招商银行数据
- 在settings.py文件中进行设置
与作业1中配置类似
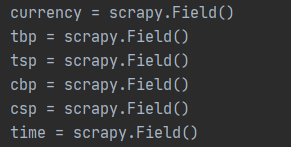
- items.py中编写所需字段
- spider.py中编写爬虫部分
parse函数中设置解码信息
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
在网页中查看需爬取数据结点信息
在parse函数中利用xpath进行嵌套爬取(其中利用了strip函数去除空格)
trs = selector.xpath("//div[@id='realRateInfo']/table[@class='data']/tr")
for tr in trs[1:]:
currency = tr.xpath("./td[@class='fontbold'][1]/text()").extract_first().strip()
tsp = tr.xpath("./td[@class='numberright'][1]/text()").extract_first().strip()
csp = tr.xpath("./td[@class='numberright'][2]/text()").extract_first().strip()
tbp = tr.xpath("./td[@class='numberright'][3]/text()").extract_first().strip()
cbp = tr.xpath("./td[@class='numberright'][4]/text()").extract_first().strip()
time = tr.xpath("./td[8]/text()").extract_first().strip()
- pipelines.py中对数据进行处理
连接mysql数据库
在processitems函数中执行插入数据库语句

- 结果查看
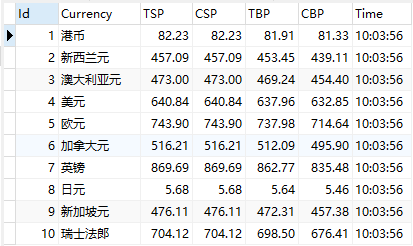
数据库中查看结果如下
2)、心得体会
作业2用scrapy框架,与第一题类似。该页面的结构为table类型,第一次在利用xpath定位元素的时候由于嵌入了tbody标签,导致定位失败,后来得知xpath定位需要忽略tbody,反而selenium的定位方法可以带tbody。其tr结点的第一个结点为空,需要从第二个开始遍历,这一点需要注意。
作业③:
-
要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
-
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
-
输出信息:MySQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 成交额 振幅 最高 最低 今开 昨收 1 688093 N世华 28.47 62.22% 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.2 17.55 2......
1)、利用selenium爬取东方财富网股票信息
- 编写seleniumspider类,首先编写start函数,初始化驱动
boards = ['hs_a_board', 'sh_a_board', 'sz_a_board']
def start(self,url):
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(chrome_options=chrome_options)
self.driver.get(url)
html = self.driver.page_source
print("opened")
其中boards中包含需爬取的版块信息
- 编写open_db函数连接数据库
def open_db(self):
try:
# 连接mysql数据库
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",
password="hts2953936", database="mydb", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor) # 设置cursor
self.opened = True
except Exception as err:
self.opened = False
- close_db函数实现数据的commit和关闭数据库
def close_db(self):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
- 编写processSpider函数,爬取多个页面中单个版块的信息
首先查看网页中需要爬取的数据
需爬取的数据还算整齐,基本上是按顺序。
对页面信息进行提取
lis = self.driver.find_elements_by_xpath("//div[@class='listview full']/table[@id='table_wrapper-table']/tbody/tr")
# print(lis)
for li in lis:
id = li.find_element_by_xpath(".//td[position()=1]").text # 序号
symbol = li.find_element_by_xpath(".//td[position()=2]/a").text # 代码
stockname = li.find_element_by_xpath(".//td[position()=3]/a").text # 名称
lasttrade = li.find_element_by_xpath(".//td[position()=5]/span").text # 最新价
chg = li.find_element_by_xpath(".//td[position()=6]/span").text # 涨跌幅
change = li.find_element_by_xpath(".//td[position()=7]/span").text # 涨跌额
volume = li.find_element_by_xpath(".//td[position()=8]").text # 成交量
turnover = li.find_element_by_xpath(".//td[position()=9]").text # 成交额
amplitude = li.find_element_by_xpath(".//td[position()=10]").text # 振幅
highest = li.find_element_by_xpath(".//td[position()=11]/span").text # 最高
lowest = li.find_element_by_xpath(".//td[position()=12]/span").text # 最低
open = li.find_element_by_xpath(".//td[position()=13]/span").text # 今开
prevclose = li.find_element_by_xpath(".//td[position()=14]").text # 昨收
time.sleep(1)
在爬取完一条后设置了time.sleep(1)
随即将数据插入数据库:
print('-------------------------------')
# 打印出插入语句
print("insert into STOCK2 (Sid,Ssymbol,Sname,Slasttrade,Schg,Schange,Svolume,Sturnover,Samplitude,Shighest,Slowest,Sopen,Sprevclose) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(id, symbol, stockname, lasttrade, chg, change, volume, turnover, amplitude, highest, lowest, open, prevclose))
# 执行插入数据库操作
if self.opened:
self.cursor.execute("insert into STOCK2 (Sid,Ssymbol,Sname,Slasttrade,Schg,Schange,Svolume,Sturnover,Samplitude,Shighest,Slowest,Sopen,Sprevclose) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(id, symbol, stockname, lasttrade, chg, change, volume, turnover, amplitude, highest, lowest, open, prevclose))
其中控制台输出分割线和插入语句,方便调试
在for循环爬取一页结束后
查看页面翻页信息

进行翻页操作
# 设置每版翻3页
if not page == 3:
page += 1
try:
nextPage = self.driver.find_element_by_xpath("//div[@class='listview full']/div[@class='dataTables_wrapper']/div[@class='dataTables_paginate paging_input']/a[@class='next paginate_button']")
nextPage.click()
time.sleep(5)
self.processSpider()
except:
print("err page")
爬取时我设置了每个版块爬取3页。在try中利用driver的xpath提取元素方法寻找翻页按钮,然后利用selenium的click方法进行模拟点击翻页。这里注意在翻页之后需要设置time.sleep(),等待页面加载完毕,随后递归调用process函数进行爬取。
- 编写完seleniumSpider类后,在外部新建对象进行调用;
新建对象后调用opendb函数连接数据库
spider = stockspider()
spider.open_db()
遍历需爬取的版块,初始化驱动并调用processSpider函数进行每个版块多个页面的爬取:
for boards in spider.boards:
page = 1
url = "http://quote.eastmoney.com/center/gridlist.html#" + boards
spider.start(url)
spider.processSpider()
最后调用closedb,提交数据到数据库并关闭数据库
- 查看结果
数据库中查看结果:
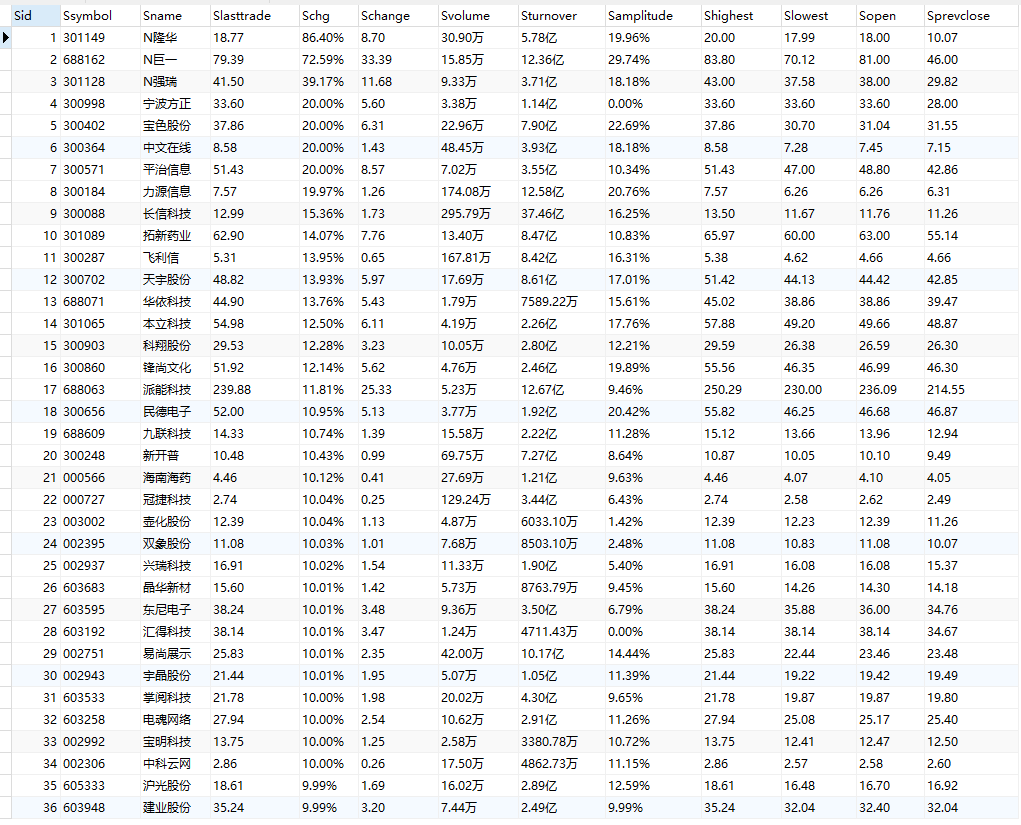
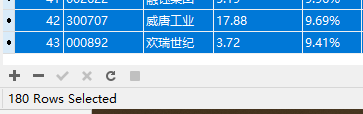
爬取数量(一页20条,每版块爬取3页,共180条):
2)、心得体会
第一次完成了selenium的实验,感觉selenium的功能特别强大,可以解决很多的反爬问题。这次试验运用了他的查找元素方法和翻页处理时的点击操作,其中由于selenium的xpath查找方法和原先的xpath查找方法略有不同,花费了一些时间。注意利用selenium进行爬取的过程中,在执行用户操作或者访问url,需要注意设置等待时间,让网页加载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号