两篇文章搞懂base64编解码
文章一:
文章参考维基百科——《base64词条》
Base64是一种基于64个可打印字符来表示二进制数据的表示方法。由于2的6次方等于64,所以每6个位元为一个单元,对应某个可打印字符。三个字节有24个位元,对应于4个Base64单元,即3个字节需要用4个可打印字符来表示。它可用来作为电子邮件的传输编码。在Base64中的可打印字符包括字母A-Z、a-z、数字0-9 ,这样共有62个字符,此外两个可打印符号在不同的系统中而不同。一些如uuencode的其他编码方法,和之后binhex的版本使用不同的64字符集来代表6个二进制数字,但是它们不叫Base64。
Base64常用于在通常处理文本数据的场合,表示、传输、存储一些二进制数据。包括MIME的email,email via MIME, 在XML中存储复杂数据.
MIME[编辑]
在MIME格式的电子邮件中,base64可以用来将binary的字节序列数据编码成ASCII字符序列构成的文本。使用时,在传输编码方式中指定base64。使用的字符包括大小写字母各26个,加上10个数字,和加号“+”,斜杠“/”,一共64个字符,等号“=”用来作为后缀用途。
完整的base64定义可见 RFC 1421和 RFC 2045。编码后的数据比原始数据略长,为原来的 。在电子邮件中,根据RFC 822规定,每76个字符,还需要加上一个回车换行。可以估算编码后数据长度大约为原长的135.1%。(andy:((76+1)*8)\(76*6)= 1.350877……)
。在电子邮件中,根据RFC 822规定,每76个字符,还需要加上一个回车换行。可以估算编码后数据长度大约为原长的135.1%。(andy:((76+1)*8)\(76*6)= 1.350877……)
转换的时候,将三个byte的数据,先后放入一个24bit的缓冲区中,先来的byte占高位。数据不足3byte的话,于缓冲区中剩下的bit用0补足。然后,每次取出6(因为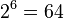 )个bit,按照其值选择
)个bit,按照其值选择ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/中的字符作为编码后的输出。不断进行,直到全部输入数据转换完成。
如果最后剩下两个输入数据,在编码结果后加1个“=”;如果最后剩下一个输入数据,编码结果后加2个“=”;如果没有剩下任何数据,就什么都不要加,这样才可以保证资料还原的正确性。
(andy:所说的一个或者两个输入数据是指8比特的一个字符,剩下一个字节也就是8bit的时候,会被分成6位+6位(2位有效+四位0),然后还剩6+6,就用两个=号来代替。如果剩两个字节也就是16位的话,就是6位+6位+6位(4位有效+2位0),剩下的一个6位用一个=号代替。下边验证了我的理解。)
例子[编辑]
| Man is distinguished, not only by his reason, but by this singular passion from other animals, which is a lust of the mind, that by a perseverance of delight in the continued and indefatigable generation of knowledge, exceeds the short vehemence of any carnal pleasure. |
经过base64编码之后变成:
TWFuIGlzIGRpc3Rpbmd1aXNoZWQsIG5vdCBvbmx5IGJ5IGhpcyByZWFzb24sIGJ1dCBieSB0aGlz IHNpbmd1bGFyIHBhc3Npb24gZnJvbSBvdGhlciBhbmltYWxzLCB3aGljaCBpcyBhIGx1c3Qgb2Yg dGhlIG1pbmQsIHRoYXQgYnkgYSBwZXJzZXZlcmFuY2Ugb2YgZGVsaWdodCBpbiB0aGUgY29udGlu dWVkIGFuZCBpbmRlZmF0aWdhYmxlIGdlbmVyYXRpb24gb2Yga25vd2xlZGdlLCBleGNlZWRzIHRo ZSBzaG9ydCB2ZWhlbWVuY2Ugb2YgYW55IGNhcm5hbCBwbGVhc3VyZS4=
- 编码“Man”
| 文本 | M | a | n | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ASCII编码 | 77 | 97 | 110 | |||||||||||||||||||||
| 二进制位 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 |
| 索引 | 19 | 22 | 5 | 46 | ||||||||||||||||||||
| Base64编码 | T | W | F | u | ||||||||||||||||||||
在此例中,Base64算法将三个字符编码为4个字符
Base64索引表:
| Value | Char | Value | Char | Value | Char | Value | Char | |||
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A | 16 | Q | 32 | g | 48 | w | |||
| 1 | B | 17 | R | 33 | h | 49 | x | |||
| 2 | C | 18 | S | 34 | i | 50 | y | |||
| 3 | D | 19 | T | 35 | j | 51 | z | |||
| 4 | E | 20 | U | 36 | k | 52 | 0 | |||
| 5 | F | 21 | V | 37 | l | 53 | 1 | |||
| 6 | G | 22 | W | 38 | m | 54 | 2 | |||
| 7 | H | 23 | X | 39 | n | 55 | 3 | |||
| 8 | I | 24 | Y | 40 | o | 56 | 4 | |||
| 9 | J | 25 | Z | 41 | p | 57 | 5 | |||
| 10 | K | 26 | a | 42 | q | 58 | 6 | |||
| 11 | L | 27 | b | 43 | r | 59 | 7 | |||
| 12 | M | 28 | c | 44 | s | 60 | 8 | |||
| 13 | N | 29 | d | 45 | t | 61 | 9 | |||
| 14 | O | 30 | e | 46 | u | 62 | + | |||
| 15 | P | 31 | f | 47 | v | 63 | / |
如果要编码的字节数不能被3整除,最后会多出1个或2个字节,那么可以使用下面的方法进行处理:先使用0字节值在末尾补足,使其能够被3整除,然后再进行base64的编码。在编码后的base64文本后加上一个或两个'='号,代表补足的字节数。也就是说,当最后剩余一个八位字节(一个byte)时,最后一个6位的base64字节块有四位是0值,最后附加上两个等号;如果最后剩余两个八位字节(2个byte)时,最后一个6位的base字节块有两位是0值,最后附加一个等号。 参考下表:
| 文本(1 Byte) | A | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 二进制位 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | ||||||||||||||||
| 二进制位(补0) | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | ||||||||||||
| Base64编码 | Q | Q | ||||||||||||||||||||||
| 文本(2 Byte) | B | C | ||||||||||||||||||||||
| 二进制位 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | x | x | x | x | x | x | ||
| 二进制位(补0) | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | x | x | x | x | x | x |
| Base64编码 | Q | k | M | |||||||||||||||||||||
UTF-7[编辑]
UTF-7 是一个修改的Base64(Modified Base64)。主要是将UTF-16的数据,用Base64的方法编码为可打印的 ASCII 字符序列。目的是传输 Unicode 数据。主要的区别在于不用等号"="补余,因为该字符通常需要大量的转译。
标准可见RFC 2152,《A Mail-Safe Transformation Format of Unicode》。
IRCu[编辑]
在IRCu等软件所使用的P10 IRC服务器间协议中,对客户与服务器的消息类型号(client/server numerics)和二进制IP地址采用了base64编码。消息类型号的长度固定为3字节,故可直接编码为4个字节而不需要加填充。对IP地址进行编码时,则需要在地址前添加一些0比特,使之可以编码为整数个字节。这里所用的符号集与前述MIME的也有所不同,将+/改成了[]。
在URL中的应用[编辑]
Base64编码可用于在HTTP环境下传递较长的标识信息。例如,在Java持久化系统Hibernate中,就采用了Base64来将一个较长的唯一标识符(一般为128-bit的UUID)编码为一个字符串,用作HTTP表单和HTTP GET URL中的参数。在其他应用程序中,也常常需要把二进制数据编码为适合放在URL(包括隐藏表单域)中的形式。此时,采用Base64编码不仅比较简短,同时也具有不可读性,即所编码的数据不会被人用肉眼所直接看到。
然而,标准的Base64并不适合直接放在URL里传输,因为URL编码器会把标准Base64中的“/”和“+”字符变为形如“%XX”的形式,而这些“%”号在存入数据库时还需要再进行转换,因为ANSI SQL中已将“%”号用作通配符。
为解决此问题,可采用一种用于URL的改进Base64编码,它不在末尾填充'='号,并将标准Base64中的“+”和“/”分别改成了“-”和“_”,这样就免去了在URL编解码和数据库存储时所要作的转换,避免了编码信息长度在此过程中的增加,并统一了数据库、表单等处对象标识符的格式。
(andy:上边那一段的“并将标准Base64中的“+”和“/”分别改成了“-”和“_””在百度百科里写错了,把"-"写成了"*",学过数据库的我当时就想,"*"在数据库里不也是特殊符号么?是一个通配符。结果在维基百科里看到这个写法才更加确定了我的怀疑,并且修改了百度百科里的内容。)
另有一种用于正则表达式的改进Base64变种,它将“+”和“/”改成了“!”和“-”,因为“+”,“*”以及前面在IRCu中用到的“[”和“]”在正则表达式中都可能具有特殊含义。
此外还有一些变种,它们将“+/”改为“_-”或“._”(用作编程语言中的标识符名称)或“.-”(用于XML中的Nmtoken)甚至“_:”(用于XML中的Name)。
文章二:
文章参考空间站北极心空——《JavaScript 的 BASE64 算法》
* 我在网上看到过很多BASE64的JavaScript算法,都觉得不满意,于是自己写了一个,在这里分享一下。
* 我的代码在质量的效率都较高,没有一些冗余的操作。总体来讲我觉得非常不错。
* 如果大家有什么不懂的地方可以问我。
*/
var BASE64={
/**
* 此变量为编码的key,每个字符的下标相对应于它所代表的编码。
*/
enKey: 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/',
/**
* 此变量为解码的key,是一个数组,BASE64的字符的ASCII值做下标,所对应的就是该字符所代表的编码值。
*/
deKey: new Array(
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 62, -1, -1, -1, 63,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, -1,
-1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1,
-1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,
41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1
),
/**
* 编码
*/
encode: function(src){
//用一个数组来存放编码后的字符,效率比用字符串相加高很多。
var str=new Array();
var ch1, ch2, ch3;
var pos=0;
//每三个字符进行编码。
while(pos+3<=src.length){
ch1=src.charCodeAt(pos++);
ch2=src.charCodeAt(pos++);
ch3=src.charCodeAt(pos++);
str.push(this.enKey.charAt(ch1>>2), this.enKey.charAt(((ch1<<4)+(ch2>>4))&0x3f));
str.push(this.enKey.charAt(((ch2<<2)+(ch3>>6))&0x3f), this.enKey.charAt(ch3&0x3f));
}
//给剩下的字符进行编码。
if(pos<src.length){
ch1=src.charCodeAt(pos++);
str.push(this.enKey.charAt(ch1>>2));
if(pos<src.length){
ch2=src.charCodeAt(pos);
str.push(this.enKey.charAt(((ch1<<4)+(ch2>>4))&0x3f));
str.push(this.enKey.charAt(ch2<<2&0x3f), '=');
}else{
str.push(this.enKey.charAt(ch1<<4&0x3f), '==');
}
}
//组合各编码后的字符,连成一个字符串。
return str.join('');
},
/**
* 解码。
*/
decode: function(src){
//用一个数组来存放解码后的字符。
var str=new Array();
var ch1, ch2, ch3, ch4;
var pos=0;
//过滤非法字符,并去掉'='。
src=src.replace(/[^A-Za-z0-9\+\/]/g, '');
//decode the source string in partition of per four characters.
while(pos+4<=src.length){
ch1=this.deKey[src.charCodeAt(pos++)];
ch2=this.deKey[src.charCodeAt(pos++)];
ch3=this.deKey[src.charCodeAt(pos++)];
ch4=this.deKey[src.charCodeAt(pos++)];
str.push(String.fromCharCode(
(ch1<<2&0xff)+(ch2>>4), (ch2<<4&0xff)+(ch3>>2), (ch3<<6&0xff)+ch4));
}
//给剩下的字符进行解码。
if(pos+1<src.length){
ch1=this.deKey[src.charCodeAt(pos++)];
ch2=this.deKey[src.charCodeAt(pos++)];
if(pos<src.length){
ch3=this.deKey[src.charCodeAt(pos)];
str.push(String.fromCharCode((ch1<<2&0xff)+(ch2>>4), (ch2<<4&0xff)+(ch3>>2)));
}else{
str.push(String.fromCharCode((ch1<<2&0xff)+(ch2>>4)));
}
}
//组合各解码后的字符,连成一个字符串。
return str.join('');
}
};
使用方法:
var enstr=BASE64.encode(str);
alert(enstr);
var destr=BASE64.decode(enstr);
alert(destr);
andy:起初关于base64解码需要的128个元素的数组我不知道是什么作用,也曾想过是充当查表的作用,但是一想查表的话总共就需要64个元素就可以了,并且查表的话不可能用那么多重复的"-1"。在这篇文章中发现,就是充当查表的作用,我数了一下,在这个表中算上"-1"恰巧有64个不重复的字符,之所以要加上那么多"-1"形成128个元素的原因是:可以直接通过ASCII码的下标来进行"查表",而不用其它运算,快速、高效。所以那些"-1"只有一个可以用的到,其它的都是为了填充以达到ascii码对应数组下标的效果。我自己核对了一下,那些非"-1"的值正好对应着字符的ASCII编码,如下图:
| Value | Char | Value | Char | Value | Char | Value | Char | |||
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A | 16 | Q | 32 | g | 48 | w | |||
| 1 | B | 17 | R | 33 | h | 49 | x | |||
| 2 | C | 18 | S | 34 | i | 50 | y | |||
| 3 | D | 19 | T | 35 | j | 51 | z | |||
| 4 | E | 20 | U | 36 | k | 52 | 0 | |||
| 5 | F | 21 | V | 37 | l | 53 | 1 | |||
| 6 | G | 22 | W | 38 | m | 54 | 2 | |||
| 7 | H | 23 | X | 39 | n | 55 | 3 | |||
| 8 | I | 24 | Y | 40 | o | 56 | 4 | |||
| 9 | J | 25 | Z | 41 | p | 57 | 5 | |||
| 10 | K | 26 | a | 42 | q | 58 | 6 | |||
| 11 | L | 27 | b | 43 | r | 59 | 7 | |||
| 12 | M | 28 | c | 44 | s | 60 | 8 | |||
| 13 | N | 29 | d | 45 | t | 61 | 9 | |||
| 14 | O | 30 | e | 46 | u | 62 | + | |||
| 15 | P | 31 | f | 47 | v | 63 | / |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号