
《Google C++ 风格指南》读书笔记
一.头文件
1)所有头文件都应该使用 #define 防止头文件被多重包含, 命名格式当是: <PROJECT>_<PATH>_<FILE>_H_
例如, 项目 foo 中的头文件 foo/src/bar/baz.h 可按如下方式保护:
#ifndef FOO_BAR_BAZ_H_
#define FOO_BAR_BAZ_H_
…
#endif // FOO_BAR_BAZ_H_
2)能用前置声明的地方尽量不使用 #include.减少代码的重新编译。
3)只有当函数只有 10 行甚至更少时才将其定义为内联函数.
4)复杂的内联函数的定义, 应放在后缀名为 -inl.h 的头文件中.
5)定义函数时, 参数顺序依次为: 输入参数, 然后是输出参数.输入参数一般传值或传 const 引用, 输出参数或输入/输出参数则是非const 指针.
使用 UNIX 特殊的快捷目录 . (当前目录) 或 .. (上级目录)。
二.作用域
1)鼓励在 .cc 文件内使用匿名名字空间. 使用具名的名字空间时, 其名称可基于项目名或相对路径. 不要使用
using 关键字.
2)公有嵌套类作为接口的一部分时, 虽然可以直接将他们保持在全局作用域中, 但将嵌套类的声明置于名字空间内是更好的选择.
3)使用静态成员函数或名字空间内的非成员函数, 尽量不要用裸的全局函数.
4)将函数变量尽可能置于最小作用域内, 并在变量声明时进行初始化.如果变量是一个对象, 每次进入作用域都要
调用其构造函数, 每次退出作用域都要调用其析构函数.
5) 禁止使用 class 类型的静态或全局变量: 它们会导致很难发现的 bug 和不确定的构造和析构函数调用顺序.
三.类
1)构造函数中只进行那些没什么意义的初始化, 可能的话, 使用 Init() 方法集中初始化有意义的 (non-trivial) 数据.
2)如果一个类定义了若干成员变量又没有其它构造函数, 必须 定义一个默认构造函数. 否则编译器将自动生产一个
很糟糕的默认构造函数.
3)对单个参数的构造函数使用 C++ 关键字 explicit,防止发生隐式转换.
4)仅在代码中需要拷贝一个类对象的时候使用拷贝构造函数; 大部分情况下都不需要, 此时应使用
DISALLOW_COPY_AND_ASSIGN.
1 |
// 禁止使用拷贝构造函数和 operator= 赋值操作的宏 |
2 |
// 应该在类的 private: 中使用 |
3 |
4 |
#define DISALLOW_COPY_AND_ASSIGN(TypeName) \ |
5 |
TypeName(const TypeName&); \ |
6 |
void operator=(const TypeName&) |
在 class foo: 中:
1 |
class Foo { |
2 |
public: |
3 |
Foo(int f); |
4 |
~Foo(); |
5 |
6 |
private: |
7 |
DISALLOW_COPY_AND_ASSIGN(Foo); |
8 |
}; |
5)仅当只有数据时使用 struct, 其它一概使用 class.为了和 STL 保持一致, 对于 仿函数 (functors)和 特性
(traits) 可以不用 class 而是使用 struct.
6) 使用组合常常比使用继承更合理. 如果使用继承的话, 定义为 public 继承.
7)真正需要用到多重实现继承的情况少之又少. 只在以下情况我们才允许多重继承: 最多只有一个基类是非抽象
类; 其它基类都是以 Interface 为后缀的纯接口类.
8)接口是指满足特定条件的类, 这些类以 Interface 为后缀 (不强制).
当一个类满足以下要求时, 称之为纯接口
.只有 纯虚函数 (“=0“) 和 静态函数 (除了下文提到的析构函数).
.没有非静态数据成员.
.没有定义任何构造函数. 如果有, 也不能带有参数, 并且必须为 protected.
.如果它是一个子类, 也只能从满足上述条件并以 Interface 为后缀的类继承.
9)除少数特定环境外,不要重载运算符.
10)将 所有 数据成员声明为 private, 并根据需要提供相应的 存取函数. 例如, 某个名为 foo_ 的变量, 其取
值函数是 foo(). 还可能需要一个赋值函数 set_foo().
一般在头文件中把存取函数定义成内联函数.
11)在类中使用特定的声明顺序: public: 在 private: 之前, 成员函数在数据成员 (变量) 前;
类的访问控制区段的声明顺序依次为: public:, protected:, private:. 如果某区段没内容,可以不声明.
每个区段内的声明通常按以下顺序:
- typedefs 和枚举
- 常量
- 构造函数
- 析构函数
- 成员函数, 含静态成员函数
- 数据成员, 含静态数据成员
12)倾向编写简短, 凝练的函数.
四.来自 Google 的奇技
1)如果确实需要使用智能指针的话, scoped_ptr 完全可以胜任. 你应该只在非常特定的情况下使用
std::tr1::shared_ptr, 例如 STL 容器中的对象. 任何情况下都不要使用 auto_ptr.
2)使用 cpplint.py 检查风格错误.
五.其他 C++ 特性
1)所有按引用传递的参数必须加上 const,如果需要改变值,则用指针。
输入参数是值参或 const 引用, 输出参数为指针. 输入参数可以是 const 指针, 但决不能是 非 const 的引
用参数.(《API Design for C++》也有同样的说法)
2)仅在输入参数类型不同, 功能相同时使用重载函数 (含构造函数). 不要用函数重载模拟 缺省函数参数。
3)我们不允许使用缺省函数参数.
4)我们不允许使用变长数组和 alloca().使用安全的内存分配器, 如 scoped_ptr / scoped_array.
5)我们允许合理的使用友元类及友元函数.通常友元应该定义在同一文件内。
6)我们不使用 C++ 异常.
7)我们禁止使用 RTTI.
在运行时判断类型通常意味着设计问题. 如果你需要在运行期间确定一个对象的类型, 这通常说明你需要考虑重
新设计你的类.
(A)除单元测试外, 不要使用 RTTI. 如果你发现自己不得不写一些行为逻辑取决于对象类型的代码, 考虑换
一种方式判断对象类型.
(B)如果要实现根据子类类型来确定执行不同逻辑代码, 虚函数无疑更合适. 在对象内部就可以处理类型识别问
题.
(C)如果要在对象外部的代码中判断类型, 考虑使用双重分派方案, 如访问者模式. 可以方便的在对象本身之外
确定类的类型.
8) 使用 C++ 的类型转换, 如 static_cast<>(). 不要使用 int y = (int)x 或 int y = int(x) 等转
换方式;
- 用 static_cast 替代 C 风格的值转换, 或某个类指针需要明确的向上转换为父类指针时.
- 用 const_cast 去掉 const 限定符.
- 用 reinterpret_cast 指针类型和整型或其它指针之间进行不安全的相互转换. 仅在你对所做一切了然于心时使用.
- dynamic_cast 测试代码以外不要使用. 除非是单元测试, 如果你需要在运行时确定类型信息, 说明有 设计缺陷。
9)只在记录日志时使用流.
流使得 pread() 等功能函数很难执行. 如果不使用 printf 风格的格式化字符串, 某些格式化操作 (尤其是
常用的格式字符串 %.*s) 用流处理性能是很低的. 流不支持字符串操作符重新排序 (%1s), 而这一点对于软件
国际化很有用.
采用 printf + read/write.
10)对于迭代器和其他模板对象使用 前缀形式 (++i) 的自增, 自减运算符.效率更高。
11)我们强烈建议你在任何可能的情况下都要使用 const.
const 变量, 数据成员, 函数和参数为编译时类型检测增加了一层保障; 便于尽早发现错误. 因此, 我们强烈
建议在任何可能的情况下使用 const:
- 如果函数不会修改传入的引用或指针类型参数, 该参数应声明为 const.
- 尽可能将函数声明为 const. 访问函数应该总是 const. 其他不会修改任何数据成员, 未调用非 const 函数, 不会返回数据成员非 const 指针或引用的函数也应该声明成 const.
- 如果数据成员在对象构造之后不再发生变化, 可将其定义为 const.
12)C++ 内建整型中, 仅使用 int. 如果程序中需要不同大小的变量, 可以使用 <stdint.h> 中长度精确的整
型, 如 int16_t.
13)代码应该对 64 位和 32 位系统友好. 处理打印, 比较, 结构体对齐时应切记:
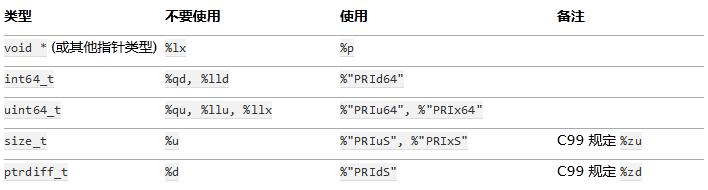
.记住 sizeof(void *) != sizeof(int). 如果需要一个指针大小的整数要用 intptr_t.
.你要非常小心的对待结构体对齐, 尤其是要持久化到磁盘上的结构体。
.创建 64 位常量时使用 LL 或 ULL 作为后缀。
.如果你确实需要 32 位和 64 位系统具有不同代码, 可以使用 #ifdef _LP64 指令来切分 32/64 位代码.
(尽量不要这么做, 如果非用不可, 尽量使修改局部化)
14)使用宏时要非常谨慎, 尽量以内联函数, 枚举和常量代替之.宏的作用域是全局的。
- 不要在 .h 文件中定义宏.
- 在马上要使用时才进行 #define, 使用后要立即 #undef.
- 不要只是对已经存在的宏使用#undef,选择一个不会冲突的名称;
- 不要试图使用展开后会导致 C++ 构造不稳定的宏, 不然也至少要附上文档说明其行为.
15)整数用 0, 实数用 0.0, 指针用 NULL, 字符 (串) 用 '\0'.
16)尽可能用 sizeof(varname) 代替 sizeof(type).
17)只使用 Boost 中被认可的库.

六.命名约定
1)函数命名, 变量命名, 文件命名应具备 描述性; 不要过度缩写. 类型和变量应该是名词, 函数名可以用 “命令
性”动词.
2)文件名要全部小写, 可以包含下划线 (_) 或连字符 (-). 按项目约定来.
C++ 文件要以 .cc 结尾, 头文件以 .h 结尾.
3)类型名称的每个单词首字母均大写, 不包含下划线: MyExcitingClass, MyExcitingEnum.
4)变量名一律小写, 单词之间用下划线连接.类的成员变量以下划线结尾.结构体的数据成员可以和普通变量一样,
不用像类那样接下划线.对全局变量没有特别要求, 少用就好, 但如果你要用, 可以用 g_ 或其它标志作为前缀,
以便更好的区分局部变量.
5)在名称前加 k: kDaysInAWeek..
6)常规函数使用大小写混合, 取值和设值函数则要求与变量名匹配.
7)名字空间用小写字母命名, 并基于项目名称和目录结构: google_awesome_project.
8)枚举的命名应当和 常量或宏一致: kEnumName 或是 ENUM_NAME.
9)你并不打算使用宏对吧? 如果你一定要用, 像这样命名: MY_MACRO_THAT_SCARES_SMALL_CHILDREN.
10)如果你命名的实体与已有 C/C++ 实体相似, 可参考现有命名策略.
七.注释
1)使用 // 或 /* */, 统一就好.
2)在每一个文件开头加入版权公告, 然后是文件内容描述.
3)每个类的定义都要附带一份注释, 描述类的功能和用法.
4)函数声明处注释描述函数功能; 定义处描述函数实现.
5)通常变量名本身足以很好说明变量用途. 某些情况下, 也需要额外的注释说明.
6)对于代码中巧妙的, 晦涩的, 有趣的, 重要的地方加以注释.
7)注意标点, 拼写和语法; 写的好的注释比差的要易读的多.
8)对那些临时的, 短期的解决方案, 或已经够好但仍不完美的代码使用 TODO 注释.
八.格式
1)每一行代码字符数不超过 80.
2)尽量不使用非 ASCII 字符, 使用时必须使用 UTF-8 编码.
3)只使用空格, 每次缩进 2 个空格.
4)返回类型和函数名在同一行, 参数也尽量放在同一行(放不下的话让参数对齐).
5)函数调用尽量放在同一行, 否则, 将实参封装在圆括号中.
6)switch 语句可以使用大括号分段. 空循环体应使用 {} 或 continue.
7)句点或箭头前后不要有空格. 指针/地址操作符 ( *, &) 之后不能有空格.
8)如果一个布尔表达式超过标准行宽, 断行方式要统一一下.
9)return 表达式中不要用圆括号包围.
10)变量及数组初始化用 = 或 () 均可.
11)预处理指令不要缩进, 从行首开始.
12)问控制块的声明依次序是 public:, protected:, private:, 每次缩进 1 个空格.
13)构造函数初始化列表放在同一行或按四格缩进并排几行.
14)名字空间内容不缩进.
15)水平留白的使用因地制宜. 永远不要在行尾添加没意义的留白.
16)垂直留白越少越好.
九.规则特例
1)对于现有不符合既定编程风格的代码可以网开一面.
2)Windows 程序员有自己的编程习惯, 主要源于 Windows 头文件和其它 Microsoft 代码. 我们希望任何人都可以
顺利读懂你的代码, 所以针对所有平台的 C++ 编程只给出一个单独的指南.
如果你习惯使用 Windows 编码风格, 这儿有必要重申一下某些你可能会忘记的指南:
- 不要使用匈牙利命名法 (比如把整型变量命名成 iNum). 使用 Google 命名约定, 包括对源文件使用 .cc 扩展名.
- Windows 定义了很多原生类型的同义词, 如 DWORD, HANDLE 等等. 在调用 Windows API 时这是完全可以接受甚至鼓励的. 但还是尽量使用原有的 C++ 类型, 例如, 使用 const TCHAR * 而不是 LPCTSTR.
- 使用 Microsoft Visual C++ 进行编译时, 将警告级别设置为 3 或更高, 并将所有 warnings 当作 errors 处理.
- 不要使用 #pragma once; 而应该使用 Google 的头文件保护规则. 头文件保护的路径应该相对于项目根目录 (yospaly 注: 如 #ifndef SRC_DIR_BAR_H_, 参考#define保护 一节).
- 除非万不得已, 不要使用任何非标准的扩展, 如 #pragma 和 __declspec. 允许使用 __declspec(dllimport) 和 __declspec(dllexport); 但你必须通过宏来使用, 比如 DLLIMPORT 和 DLLEXPORT, 这样其他人在分享使用这些代码时很容易就去掉这些扩展.
在 Windows 上, 只有很少的一些情况下, 我们可以偶尔违反规则:
- 通常我们 禁止使用多重继承, 但在使用 COM 和 ATL/WTL 类时可以使用多重继承. 为了实现 COM 或 ATL/WTL 类/接口, 你可能不得不使用多重实现继承.
- 虽然代码中不应该使用异常, 但是在 ATL 和部分 STL(包括 Visual C++ 的 STL) 中异常被广泛使用. 使用 ATL 时, 应定义 _ATL_NO_EXCEPTIONS 以禁用异常. 你要研究一下是否能够禁用 STL 的异常, 如果无法禁用, 启用编译器异常也可以. (注意这只是为了编译 STL, 自己代码里仍然不要含异常处理.)
- 通常为了利用头文件预编译, 每个每个源文件的开头都会包含一个名为 StdAfx.h 或 precompile.h 的文件. 为了使代码方便与其他项目共享, 避免显式包含此文件 (precompile.cc), 使用 /FI 编译器选项以自动包含.
- 资源头文件通常命名为 resource.h, 且只包含宏的, 不需要遵守本风格指南。
十.结束语
1)运用常识和判断力, 并 保持一致.
另外,推荐《高质量C/C++编程》 & 《API Design for C++》。

