第一次个人编程作业
https://github.com/pat-chou-li/sensitiveWord
———————————————————————————————————————————————————
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 30 | 10 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 300 | 300 |
| · Design Spec | · 生成设计文档 | 40 | 10 |
| · Design Review | · 设计复审 | 20 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 60 | 60 |
| · Coding | · 具体编码 | 400 | 1000 |
| · Code Review | · 代码复审 | 60 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 300 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 60 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 60 |
| · 合计 | 1200 | 1875 |
二、计算模块接口
(3.1)计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。(18')
3.1.2.1: 算法概述
tire树+递归函数进行状态转移查询
1.将敏感词进行变换,得到多类型的敏感词,如
"秋叶" -> 'qy' + 'qiuye' + '禾火口十'
2.将生成的多类型敏感词进行组合排列,如
'qy' + 'qiuye' + '禾火口十' -> 'qy' + 'qye' + 'q口十' + 'qiuy' + 'qiuye' + 'qiu口十' + '禾火y' + '禾火ye' + '禾火口叶'
3.构建tire树,标记isEnd节点。
4.如果我们遇到了原文中的一段字:'禾火叶',我们依次读取‘禾’、‘火’、‘叶’,并检测是否在部首List['禾','火',‘口’,‘叶’]中,在的话将其传入search中进行查询,并再将其转换成拼音再进行一次查询,否则只进行一次转换成拼音的查询。
无论任何情况都转换成拼音并进行查询的好处是,我们可以很容易的处理谐音,简繁体的情况,但是遇到部首则要特殊处理。
遇到非法字符跳过并计数即可,达到20次便return。
3.1.2.2: 算法细节
1.我们对于同一个节点Node_1,如果它存在于部首List,我们要进行两次查询。那么查询失败的时候怎么回到Node_1并保留在Node_1时的所有状态呢?
将函数写为递归形式,状态转移则是一次函数的递归调用。
当查询失败时自然而然会回到主函数继续执行下一条语句,由于只传递了参数的拷贝,在递归结束返回主函数时并不会有任何变量的改变,可以很轻易的发起下一次查询。
2.为什么要同时存‘qiu’和'q'->'i'->'u'
当丢入一个字进行查询,例如求,那么会从求转换成qiu导致增加了两个字符。如果你想要q->i->u依次进行查询则很难确定敏感词的起始和最终位置,起码会使代码复杂化。
如果存下'qiu'作为节点,那么求查到qiu就是一个一对一的对应关系,直接进行下一次查询,并将敏感词结束位置+1即可。
3.1.2: 类设计
-
Node类:作为Tire树节点,包含next、fail、isWord、depth成员变量
-
Ahocorasick类:Tire树类,需要完成树的构建和检索,存在以下方法:
-
def addWord(self, word)传入敏感词,作为tire树节点生成tire树
-
def search(self, content, Hanzi_to_pinyin, _bushou) def search2(self, content, ...)主函数调用search开始检测,search递归调用search2达成tire树的检索以及检索失败的回溯。
-
-
word类:敏感词类,需要完成敏感词的转换,存在以下方法:
-
def delWrap(self)删除原文和敏感词的换行符
-
def Transformation(self)生成多样化的敏感词。
-
def createRever(self)生成rever字典,用于将不同形式的敏感词映射至原敏感词,放在答案的<>中。
-
def _arrangement(self, word, ...) def _appendList(self, ListA)全排列方法,传入Transformation生成的数组,并进行全排列。appendList配合.List.copy()方法便于浅拷贝。
-
def createLastWords(self)调用self._arrangement()方法得到全排列结果,根据中英文不同做处理,得出最终的敏感词数组。
-
def createBushou(self)利用Transformer()生成的部首数组(words4)创建部首List,便于在查询树时选择部首branch。
为什么不直接使用words4呢,此函数还起到过滤英文的作用。
-
def getAnswer(self)调用Ahocorasick树类,传入最终生成的敏感词和字典,在Tire树上查询并根据条件过滤,得到答案。
-
(3.2)计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。(12')
此处大约花费一小时。
最大的性能消耗是search2函数,即在Tire树上的状态转移递归调用。
对于搜索函数的性能改进,最需要的就是剪枝:
- 改进前:对任何一个被检测的字word都转换成pinyin_word,如'法'转换成'法'和'fa'进行两次检测。
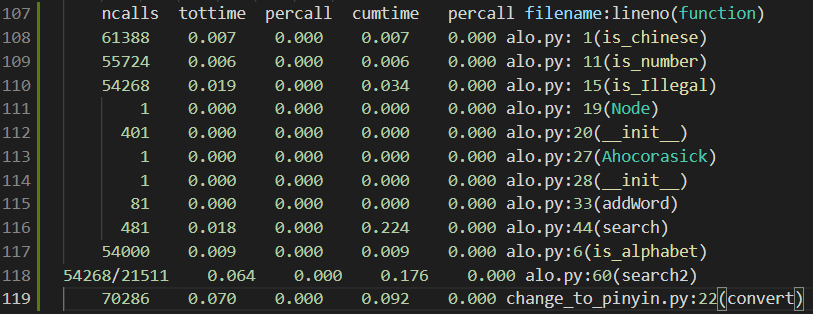
可以看到,search2函数加上子函数调用总耗时达到了0.176s
- 改进后:对任何一个被检测的字,先检查是否为汉字且为部首,是的话就执行两次检测,否则只检测其拼音形式。(英文的拼音形式就是本身)

正如预期,search2的时间大幅减少,到达了0.132s。
而且由于剪枝,递归中涉及到的所有函数的被调用次数都减少了。
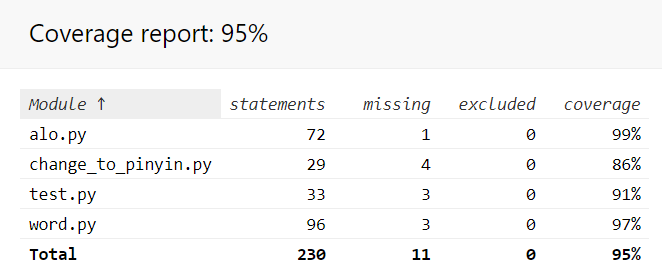
(3.3)计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。(12')
部分单元测试代码:
1.验证全排列函数word.arrangement()
样例构建思路:该样例用于测试word类的全排列功能是否正常,此函数基本没有任何特殊情况,是一个基本的全排列递归算法。
def test_arrangement(self):
words = '秋叶'
words1 = ['秋', '叶']
words2 = ['qiu', 'ye']
words3 = ['q', 'y']
words4 = ['禾火', '口十']
ans = [['qiu', 'ye'], ['qiu', 'y'], ['qiu', '\\ye'], ['qiu', '\\口十'], ['q', 'ye'], ['q', 'y'], ['q', '\\ye'], ['q', '\\口十'], [
'\\qiu', 'ye'], ['\\qiu', 'y'], ['\\qiu', '\\ye'], ['\\qiu', '\\口十'], ['\\禾火', 'ye'], ['\\禾火', 'y'], ['\\禾火', '\\ye'], ['\\禾火', '\\口十']]
test = sensitiveWord([words], [])
res = test._arrangement(words, words1, words2, words3,
words4, 0, len(words), [], [])
flag = True
if len(res) != len(ans):
flag = False
else:
for item in res:
if item not in ans:
flag = False
break
self.assertEqual(flag, True)
2.验证Tire树搜索函数AhoTree.search()
样例构建思路:测试中文中插入乱码、拆字、拆字并加入乱码等情况
def test_search(self):
words = ['欢笑', '不可思议', '国度']
org = [
'……最后一次看到还能这样欢@#$%^&*(#$%^笑的孩子究竟已是多久之前呢。\n',
'从来没有听说过的不可12思议的歌声,不!!可思~~讠||义的舞蹈。看来今天似乎是祭典的日子。\n',
'我想,总有一天也要住进有这样的孩子们的笑脸的国chi度。\n'
]
ans_example = ['total: 2',
'Line1: <欢笑> 欢@#$%^&*(#$%^笑', 'Line2: <不可思议> 不!!可思~~讠||义']
_sensitiveWord = sensitiveWord(words, org)
_sensitiveWord.delWrap()
_sensitiveWord.Transformation()
_sensitiveWord.createRever()
_sensitiveWord.createLastWords()
_sensitiveWord.createBushou()
ans = _sensitiveWord.getAnswer()
self.assertEqual(ans_example, ans)
单元测试覆盖率截图:
(3.4)计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。(6')
IO异常:读取pinyin.txt等大文件时,未成功读入抛出异常:
def test_IO(self):
try:
fp = codecs.open(path.join(path.dirname(
__file__), 'pinyin.txt'), 'r', 'utf-8')
except IOError:
self.assertTrue(False)
raise Exception("Can't load data from pinyin.txt")
except UnicodeDecodeError:
self.assertTrue(False)
raise Exception("Can't decode data from pinyin.txt")
else:
for l in fp.readlines():
self.table[l[0]] = l[1:-1]
fp.close()
self.assertTrue(True)
三、心得
(4.1)在完成本次作业过程的心得体会(3')
由于最常用的语言JavaScript并没有被允许使用,临时学习了另一个动态语言python。用下来感觉虽然都是动态语言,但是差别还是蛮大的,很多js特性都没有在python有所体现。作为一个非python语言使用者,很多代码风格也被相关的静态代码分析器批判了。
起初建树的时候疏于考虑,将所有字的拼音放进node里觉得就已经完事了,检测的时候只检测拼音,完美解决了谐音、简繁体,非法字符的处理也很简单。但是处理部首却遇到了巨大的困难,以致于后期不得不完全重构核心代码,浪费了大量时间。并且加了很多不够优美的分支判断,不知道会不会出现一些意外的bug。还是感到在设计算法的时候要深入思考,面面俱到,否则到code的时候边写代码边改bug实在是太痛苦了。

