
个人作业第四次——结对编程
一、项目地址:
GitHub仓库地址:https://github.com/Pastrain/WordCount
队友作业地址:https://www.cnblogs.com/xiaxiaoshux/p/11673232.html
二、时间估计(PSP表格):
解题思路:
当我们看到这个题目的时候,觉得还是有些复杂的。。。因为我们两个都对C++比较熟悉,所以我们决定用这个语言来完成项目。首先看到是要读取文件,并对文件内的内容进行统计,就先去网上稍微回顾了一下C++中的关于文件的操作。然后又去看了一下常用的容器,进行选择。确定下来之后,将要用到的一些资料的网站保存下来,然后就开始项目的设计。
PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | |
| · Estimate | · 估计这个任务需要多少时间 | 20 | |
| Development | 开发 | 360 | |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | |
| · Design Spec | · 生成设计文档 | 60 | |
| · Design Review | · 设计复审 (和同事审核设计文档) | 20 | |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | |
| · Design | · 具体设计 | 40 | |
| · Coding | · 具体编码 | 120 | |
| · Code Review | · 代码复审 | 40 | |
| · Test | · 测试(自我测试,修改代码,提交修改 | 20 | |
| Reporting | 报告 | 20 | |
| · Test Report | · 测试报告 | 20 | |
| · Size Measurement | · 计算工作量 | 30 | |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | |
| 合计 | 960 |
三、计算模块接口的设计与实现过程:
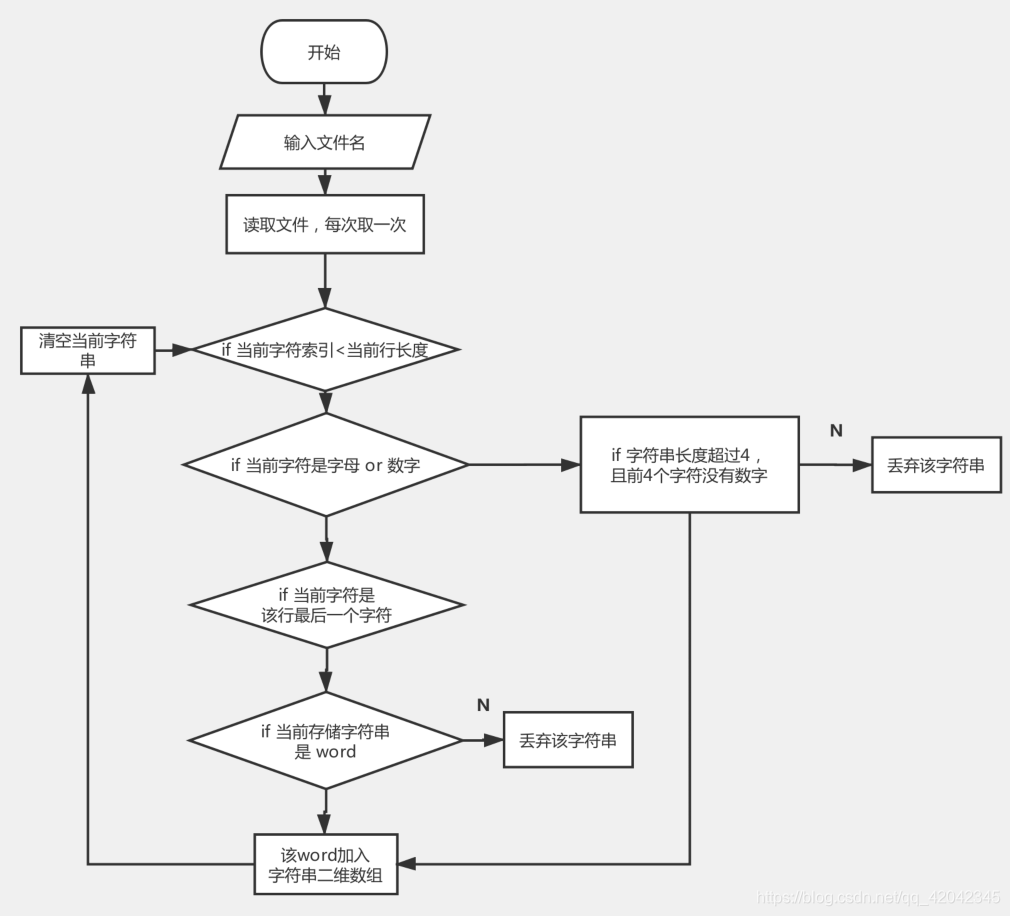
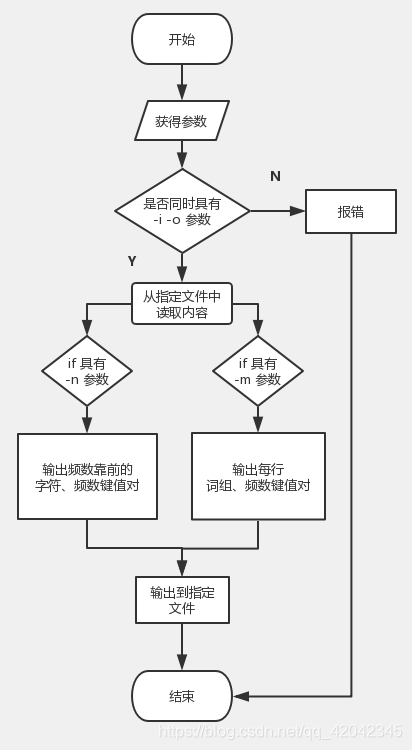
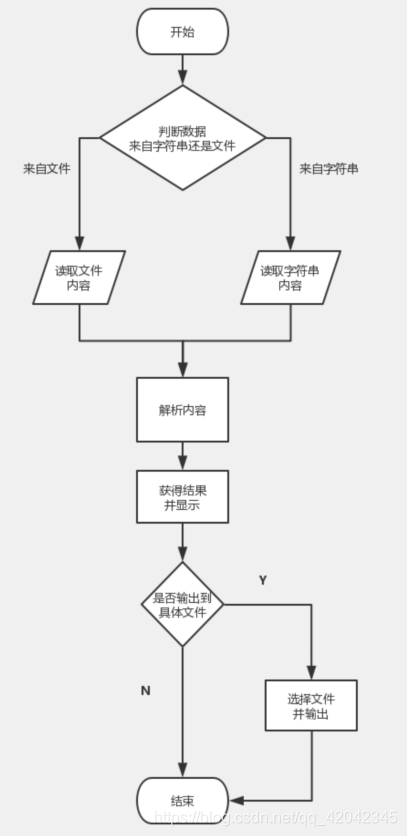
为了达到要求,我们两个进行了多次讨论。决定在将文档的内容读取出来之后,将后面的统计功能拆分成多个小功能进行实现。先将要处理的情况都列了出来,然后每个功能模块先用普通的文字描述出来,再用代码描述进行实现。
经讨论,我们对于真正的计算模块初步设计了如下几个接口:
bool isValid(char ch); //判断是否属于数字或字母
bool isNum(char ch); //判断是否为数字
bool isSplit(char chSplit); //判断是否属于标点符号(即分隔符)
map<string, int> frequency(string ** str, int& count); //用map求每种单词的频数
void countLine(ifstream &ifile, int * cntLines); //统计行数
void countChar(ifstream &ifile, int * cntChar); //统计字符数
map<string, int> countWords(ifstream &ifile, int &idx); //统计单词数
然后设计流程图:
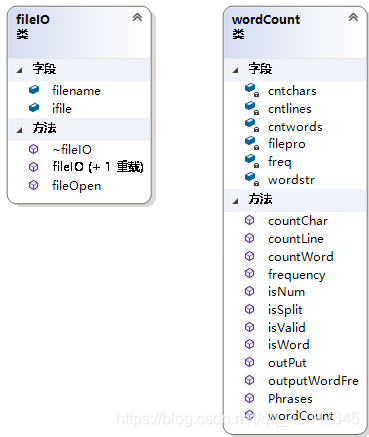
类图:
wordCount 类为主要计算及统计类;
fileIO类为文件操作类。
四、代码复审过程:
对代码进行复审的时候,我们决定统一使用华为编程规范。
代码规范如下:
1左花括号尽量成一行,右花括号要独自一行,括号内容为空时不用2.if/for/while/do等关键字后面与左括号之间需要加空格:if (x == 1)
2.方法名和左括号之间不能有空格
3.for语句中的表达式之间要加一个空格
4.for语句必须写{}
5.运算符左右需要加空格:a = b * c
6.要求代码行下一行相对于上一行缩进4个空格
7.适当增加空行,增强代码的可读性
8.注释应当增加代码的可读性,但注释也要保持简洁,过多显得繁琐
9.换行后的代码要缩进4个空格
10.边写代码边注释,修改代码同时修改相应的注释,以保证注释与代码的一致性。不再有用的注释要删除。
11.类声明放在.h头文件,类的实现放在.cpp文件
12.尽量复用代码
各个功能模块都进行相应的注释,将写代码时缺少的补全。
五、计算模块接口部分代码及性能改进:
在实际的实现过程中,我们将代码放到了wordCount和fileIO两个类中。其中的部分功能代码:
统计字符数:
// 统计字符数
void wordCount::countChar()
{
string line;
ifstream Ifile(filepro.filename);
while (!Ifile.eof())
{
getline(Ifile, line);
cntchars += line.size();
}
}
统计行数:
// 统计行数
void wordCount::countLine()
{
char line[1000];
ifstream Ifile(filepro.filename);
while (!Ifile.eof())
{
Ifile.getline(line, 1000, '\n');
cntlines++;
}
}
统计单词数:
//统计单词数
void wordCount::countWord()
{
ifstream Ifile(filepro.filename);
string lineStr; // lineStr为临时的一行
while (!Ifile.eof())
{
getline(Ifile, lineStr);
int i = 0;
string tmpStr = ""; // 存储当前可能是单词的字符
while (i < lineStr.length()) {
//if (lineStr[i] == 字母 / 数字)
if (isValid(lineStr[i]))
{
tmpStr += lineStr[i];
if (i + 1 == lineStr.length())
{
if (isWord(tmpStr) == true) {
wordstr[cntwords] = tmpStr;
tmpStr = "";
cntwords++;
}
}
}
else{
if (isWord(tmpStr) == true) {
wordstr[cntwords] = tmpStr;
tmpStr = "";
cntwords++;
}
else {
tmpStr = "";
}
}
i++;
}
}
}
统计单词及其词频:
//统计单词的词频
void wordCount::frequency()
{
map<string, int>::iterator it;
for (int i = 0; i < cntwords; i++)
{
for (it = freq.begin(); it != freq.end(); it++)
{
if (it->first == wordstr[i]) {
it->second++;
break;
}
}
if (it == freq.end())
freq.insert(make_pair(wordstr[i], 1));
}
}
性能分析图如下:
CPU占比分析图:
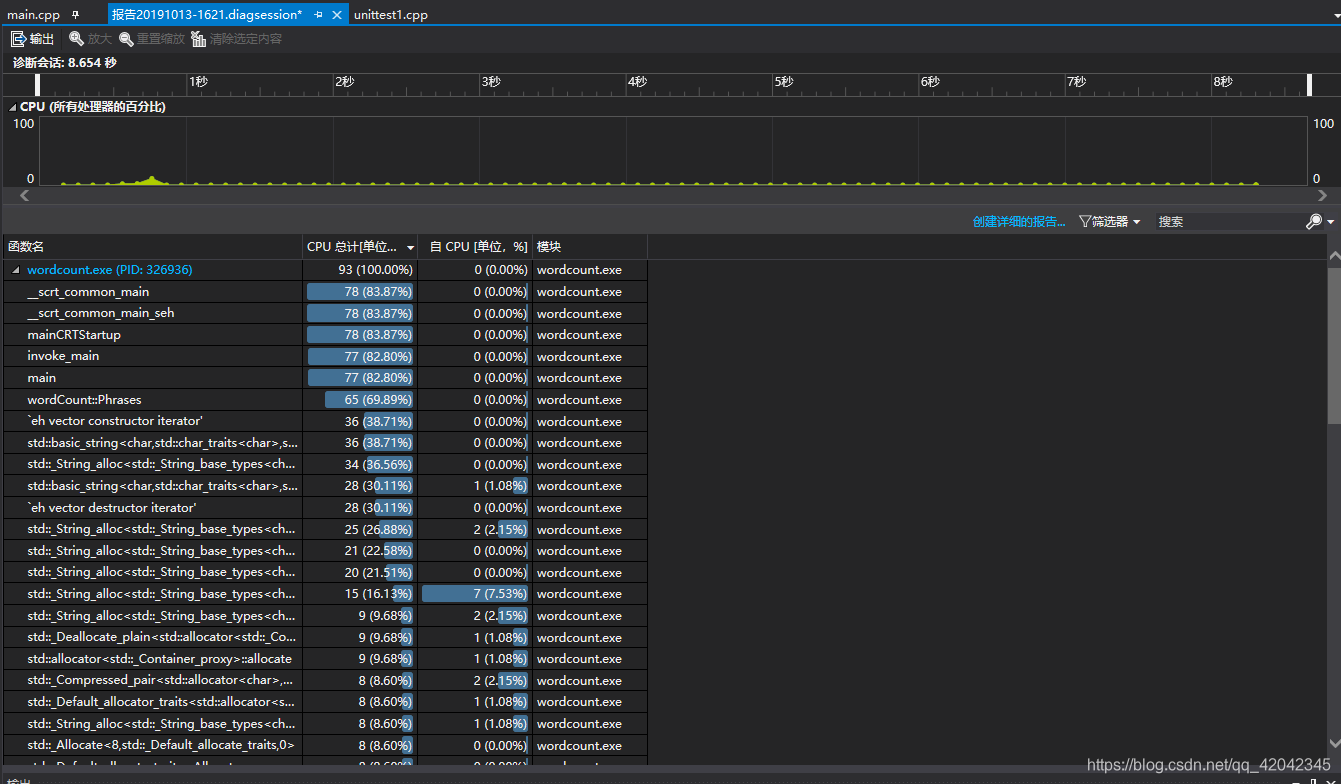
内存分析图:

其中占用最多的函数为 wordCount::Phrases,代码如下:
void wordCount::Phrases(int m, ostream &out)
{
ifstream ifile(filepro.filename);
string str[100][256]; // [100]存的是第i行,[256]存的是该行第j个单词
int idx = 0; // 用于str的行标
int idy[100] = { 0 }; // 用于str的列标
string lineStr; // lineStr为临时的一行
// 计算出str数组
int tmp = 0;
for (idx = 0; !ifile.eof(); idx++)
{
getline(ifile, lineStr);
int i = 0; // 用来循环一行(lineStr)
string wordStr = ""; // 存储当前可能是单词的字符
while (i < lineStr.length()) {
//if (lineStr[i] == 字母 / 数字)
if (isValid(lineStr[i]))
{
wordStr += lineStr[i];
if (i + 1 == lineStr.length())
{
if (isWord(wordStr) == true)
{
str[idx][idy[idx]] = wordStr;
wordStr = "";
idy[idx]++; // 当前idx行,idy列这一个单词找到了,++
}
}
}
else {
bool flag = 1;
// 如果当前临时存储的wordStr长度超过了4个字符,就可能属于单词了
if (wordStr.length() >= 4)
{
for (int in = 0; in < 4; in++)
{
//if (wordStr[newi] == 数字)
if (isNum(wordStr[in])) {
flag = false;
}
}
// 如果前4个字符里面没有数字,那就确定属于字符了
if (flag == true) {
str[idx][idy[idx]] = wordStr;
wordStr = "";
idy[idx]++; // 当前idx行,idy列这一个单词找到了,++
}
}
else
wordStr = "";
}
i++;
}
}
// san层循环
for (int curIdx = 0; curIdx < idx; curIdx++) {
for (int curIdy = 0; curIdy < idy[curIdx] - m + 1; curIdy++) {
for (int cur = curIdy; cur < curIdy + m; cur++)
{
out << str[curIdx][cur] << " ";
}
out << endl;
}
out << endl;
}
}
因为使用的本就是C++,并且在编码时算法已经充分考虑性能问题。未使用正则表达式等一系列内存占用极高的方法函数。所以我们的改进并没有很多。只是在文件的开关操作上进行了一点优化,就是直接将文件名保存下来,不用重复开关文件。
另外,在std命名空间中的方法使用时,还可以直接使用类似std::cout的形式,会再加快代码的生成和运行速度。但考虑到编码时会过于麻烦,因此未采用。
六、计算模块部分单元测试展示:
#include "stdafx.h"
#include "CppUnitTest.h"
#include "../wordcount/wordCount.h"
using namespace Microsoft::VisualStudio::CppUnitTestFramework;
namespace WordTest
{
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(TestMethod1)
{
// TODO: 在此输入测试代码
wordCount wordC("test.txt");
//测试行数统计
wordC.countLine();
//测试字符统计
wordC.countChar();
//测试单词统计
wordC.countWord();
//测试词频统计
wordC.frequency();
//测试词组统计
wordC.Phrases(3);
//测试输出词频统计
wordC.outputWordFre(5);
//测试输出到屏幕
wordC.outPut(cout);
//测试输出到文件
string filename("hello.txt");
ofstream ofile(filename);
wordC.outPut(ofile);
}
};
}
测试图如下:

七、计算模块部分异常处理说明:
我们设计的项目中出现的异常处理有这么几个:
文件无法打开:输出报错信息,并退出程序。
参数不符合规定:不执行操作,退出程序。
八、描述结对的过程:
我们两个先各自对题目进行了解读,然后再一起交流,对问题进行商讨,确定统一的解决方法。然后分工,将要做的工作分开独立完成,再汇总到一起。
我做的工作主要将队友写的实现功能的函数重新整合到类里,并制作了GUI程序。并且。。。费了很大的功夫使用了C++的Test项目来对我们的项目进行测试。。。不容易。。
结对过程记录图片如下:

九、各模块实际花费时间:
| PSP2.2 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 120 | |
| · Estimate | · 估计这个任务需要多少时间 | 50 | |
| Development | 开发 | 360 | |
| · Analysis | · 需求分析 (包括学习新技术) | 40 | |
| · Design Spec | · 生成设计文档 | 40 | |
| · Design Review | · 设计复审 (和同事审核设计文档) | 20 | |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | |
| · Design | · 具体设计 | 60 | |
| · Coding | · 具体编码 | 360 | |
| · Code Review | · 代码复审 | 20 | |
| · Test | · 测试(自我测试,修改代码,提交修改 | 60 | |
| Reporting | 报告 | 20 | |
| · Test Report | · 测试报告 | 30 | |
| · Size Measurement | · 计算工作量 | 30 | |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | |
| 合计 | 1270 |
十、附加功能:
在具体的功能及增加的功能都实现后,我们又用C++的MFC设计了可视化UI界面:
输入:
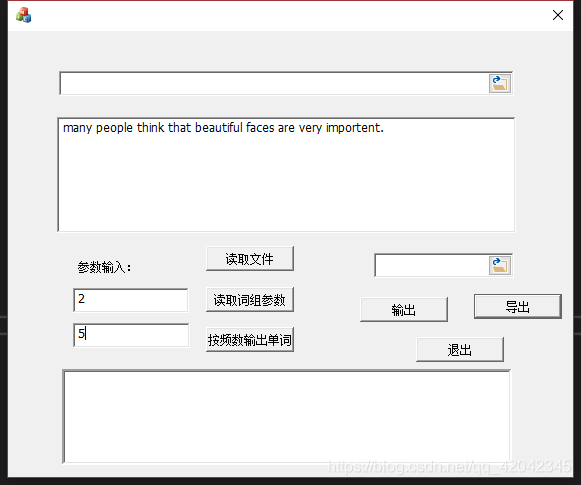
输出:
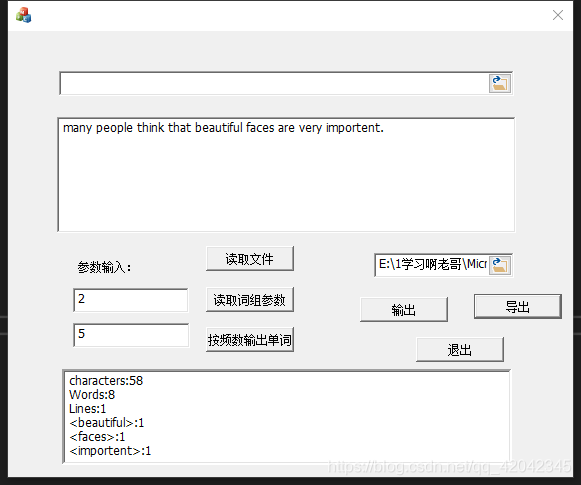
输出的文档(从我的电脑中选择的):

功能:
读取文件:从电脑中选择文本,或者从文本框中输入文本。
读取词组参数:从前面的输入框中读取一个数字,即为输出词组时的词组大小。
按词频输出单词:输出出现频率排名前几的单词。
输出:输出到屏幕上的文本框中。
导出:将结果导出到电脑中的文本中。
退出:退出程序。
总结:
这次的结对编程,我感觉还是成功的。1+1>2。
我们两个人对于这个问题的理解都非常独特,又可以很好的结合到一起,并且分工合适,解决起来得心应手。两个人一起解决问题,还互相给对方提供了灵感,思想交流让我们两个对工具的使用和编程语言的理解更加浓厚。
不得不说C++真的牛X,性能最高,工具种类又多。这一波选择C++来做,真是没有选错。
补充:
"Design by Contract" :我们两个人结对编程,对于开始时对问题的分析和解决方案的确定,是我们两个共同确定的。并且后期函数在编写以及整合的时候,也是共同完成的。
“Information Hiding”:当把函数重构成类之后,关键信息都是private属性,外部是无法直接访问的。我觉得这就是对信息的隐藏了。
“Interface Design”:这个方面我们没有实际去考虑。因为最开始我们功能的实现仅仅只是一个又一个函数,当我们重构成类之后,因为主要函数的编写已经完成了,并且C++分为.h的头文件和.cpp的类实现文件,所以我们没有使用接口设计。
“Loose Coupling”:这个方面,如果去看了我们的代码就知道了。我们所设计的函数,有isNum、isValid等几个判断函数,代码中重复的极少,只有一个还是两个函数中有几行重复代码,因此我觉得我们的设计已经是充分符合了“松耦合”的设计理念的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号