蝴蝶书-task1: 大模型原理入门
ChatGPT基础科普——知其一点所以然
词向量
词向量(词嵌入):它本质上是找到一种编码方式,实现从自然语言中到数学空间的映射。(自然语言 -映射-> 向量)
我们为什么需要词向量呢?
计算机不能理解自然语言,比如:“我爱你”,要让计算机理解需要:
数字“1”代表“我”,数字“2”代表“爱”,数字“3”代表“你”,数字“0”代表“句号”。
如何进行编码才是最优的方式呢?
下面选择最经典的词袋模型和神经网络概率模型,做一些简单一点的介绍。
词袋模型
- 词袋模型(Bag of Words,BOW):从名字来看,词袋模型就像是一个大袋子,把所有的词都装进来。文本中的每个单词都看作是独立的,忽略单词之间的顺序和语法,只关注单词出现的次数。在词袋模型中,每个文本可以表示为一个向量,向量的每个维度对应一个单词,维度的值表示该单词在文本中出现的次数。
例如三个句子如下:
句子1:小孩喜欢吃零食。
句子2:小孩喜欢玩游戏,不喜欢运动。
句子3 :大人不喜欢吃零食,喜欢运动。
首先根据语料中出现的句子分词,然后构建词袋(每一个出现的词都加进来)。计算机不认识字,只认识数字,那在计算机中怎么表示词袋模型呢?其实很简单,给每个词一个位置索引就可以了。小孩放在第一个位置,喜欢放在第二个位置,以此类推。
{“小孩”:1,“喜欢”:2,“吃”:3,“零食”:4,“玩”:5,“游戏”:6,“大人”:7,“不”:8,“运动”:9}
其中key为词,value为词的索引,预料中共有9个单词, 那么每个文本我们就可以使用一个9维的向量来表示。
如果文本中含有的一个词出现了一次,就让那个词的位置置为1,词出现几次就置为几,那么上述文本可以表示为:
句子1:[1,1,1,1,0,0,0,0,0]
句子2:[1,2,0,0,1,1,0,1,1]
句子3:[0,2,1,1,0,0,1,1,1]
该向量与原来文本中单词出现的顺序没有关系,仅仅是词典中每个单词在文本中出现的频率。
神经概率语言模型
- 神经概率语言模型(Neural Probabilistic Language Model,NPLM):它可以通过学习大量的文本数据来预测下一个单词或字符的概率。其中,最早的神经网络语言模型是由Yoshua Bengio等人于2003年发表的《A Neural Probabilistic Language Model》提出的,它在得到语言模型的同时也产生了副产品词向量。
早期的词向量都是静态的,一旦训练完就固定不变了。随着NLP技术的不断发展,词向量技术逐渐演变成基于语言模型的动态表征。语言模型不仅可以表征词,还可以表征任意文本。
1. LM
-
语言模型 (LM) 定义:
- 语言模型是根据自然语言构建的模型。
- 输入文字 -计算-> 输出文字
-
概率语言模型:
- 通过已经有的词预测接下来的词。
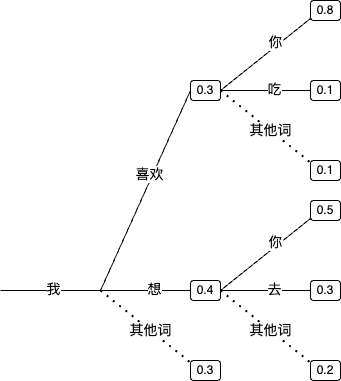
- 当模型仅了解到「我喜欢你」这句话时,当输入「我」时,模型预测下一个词很可能是「喜欢」。
- 当模型学习了大量的文本后,它会更加丰富地理解语言。比如,当输入「我」时,输出可能不再仅限于「喜欢」,而是更多样化的词汇。
- 问题:基于最大概率的贪心搜索可能导致模型生成重复的文本,因此语言模型通常会采用其他策略。
- 解决方案:模型会考虑多个可能的词,而不是仅仅选择概率最高的词,以提高生成文本的多样性和准确性。
2. Transformer
-
介绍:
- Transformer 是一种 Encoder-Decoder 架构,由 Google 在 2017 年发表的论文《Attention Is All You Need》中提出。它最重要的核心是 Self-Attention 机制,用于在语言模型建模过程中关注重要的 Token。
-
Self-Attention 机制:
- 在建模过程中,Transformer 通过自注意力机制将注意力集中在重要的 Token 上,而不是简单地依赖于固定的上下文窗口大小。
- 这种机制使得 Transformer 在处理长距离依赖关系时表现优秀,而且可以并行计算,加速了模型训练过程。
-
架构:
- Transformer 包含 Encoder 和 Decoder 两部分。Encoder 将输入序列映射到隐藏表示,而 Decoder 则根据 Encoder 的输出和已生成的部分序列来逐步生成输出序列。
- 在 Encoder 中,由于我们知道整个输入序列,因此可以同时利用当前 Token 的历史 Token 和未来(前面的) Token;而在 Decoder 中,由于是逐步生成输出序列,因此只能利用历史 Token 和 Encoder 的输出来建模。
-
Seq2Seq 架构:
- Transformer 实际上是一种 Seq2Seq 架构,即序列到序列模型,其中输入是一个文本序列,输出是另一个文本序列。这种架构在翻译等任务中表现良好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号