构建RAG应用-day02: prompt技巧总结 llamaIndex入门
常见 prompt 技巧
# 两个原则
1.明确且具体的指令
具体的指令不等于短指令,长指令往往能提供更高的清晰度
1.使用分隔符划分不同的文本内容
2.请求模型输出HTML或者JSON格式
3.使用类似于异常捕获的理念,教会模型处理文本中遇到的不同情况
4.给模型提供少量示例,相当于让模型模仿着示例来进行任务。
2.给模型时间去思考
让更多的计算资源分配到我们想让模型做的事情上。
1.对一个复杂任务,将其拆分为多个步骤,这一目的是给模型提供更高的清晰度。对于每个步骤还可以再次细化,直到模型给出理想的结果。
2.不要让模型短时间的去下一个结论,而是请求模型在提供最终答案之前进行一系列相关的推理,然后再给出结论。
# 幻觉
模型在训练过程中接触了大量的知识,它并没有完全记住所见的信息,因此它并不很清楚自己知识的边界。这意味着它可能会尝试回答有关晦涩主题的问题,并编造听起来合理但实际上并不正确的答案。我们称这些编造的想法为幻觉。
也就是说对于模型不清楚的知识,模型更倾向于一本正经的胡说八道。
# prompt技巧:
结构化输入:角色 + 场景 + 思维链 + 回复示例
# 少样本提示
few-shot是普通的禁止指令的上位替代。与其告诉模型不能做什么,不如提供示例,告诉模型怎么做。如果一个例子的效果不好,可以尝试用多个。
# 思维链:
相当于把问题的解法给llm
Let's think step by step.
# ReAct
让模型去推理,推理的过程中自己决定调用哪个工具。再把工具结果告诉模型,模型再次推理下一步。
可以通过某个参数,让大模型输出xx内容时,停下来。
# ReAct类比程序员的开发过程
需求 写代码 运行代码看结果 改代码 运行代码看结果
think react think react
llamaIndex
LlamaIndex 是一个框架,用于构建称为 检索增强生成 (RAG) 的系统。
构建RAG系统,需要先将文本转化为向量表示,(这个过程被llamaIndex称为索引),然后将用户的问题(query)进行向量相似度计算(这个过程被llamaindex称为查询),匹配出和用户问题最相关的信息,最后传入大模型,以提高llm的输出效果。
入门示例 一篇文章的RAG
安装: pip install llama-index
import openai
import logging
import sys
import os.path
from llama_index.core import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
# https://github.com/chatanywhere/GPT_API_free
openai.base_url = 'https://api.chatanywhere.tech/v1'
# 使用日志查看内部详细行为
logging.basicConfig(stream=sys.stdout, level=logging.INFO) # INFO/DEBUG
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# 检查是否已经存在存储空间
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# 加载data目录下的文章
documents = SimpleDirectoryReader("data").load_data()
# 进行embedding
index = VectorStoreIndex.from_documents(documents)
# 储存起来以后使用
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# 加载现有索引
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
# 初始化搜索引擎
query_engine = index.as_query_engine()
# 搜索 "作者的成长经历是什么?" 这里向大模型提问了,显然: 默认情况下,LlamaIndex 带有一组经过实战考验的内置提示
response = query_engine.query("What did the author do growing up?")
# The author worked on writing short stories and programming, particularly on an IBM 1401 computer in 9th grade using an early version of Fortran. Later, with the availability of microcomputers, the author continued programming, eventually getting a TRS-80 computer and writing simple games and a word processor.
# 作者曾写过短篇小说和编程,特别是在9年级的IBM 1401计算机上使用早期版本的Fortran。后来,随着微型计算机的出现,作者继续编程,最终得到了一台TRS-80计算机,并编写了简单的游戏和文字处理器。
print(response)
大概有如下步骤:读取文件 - 分块 - 将文本向量化 - 匹配与问题最相关的文本 - 带着这些文本和gpt聊天
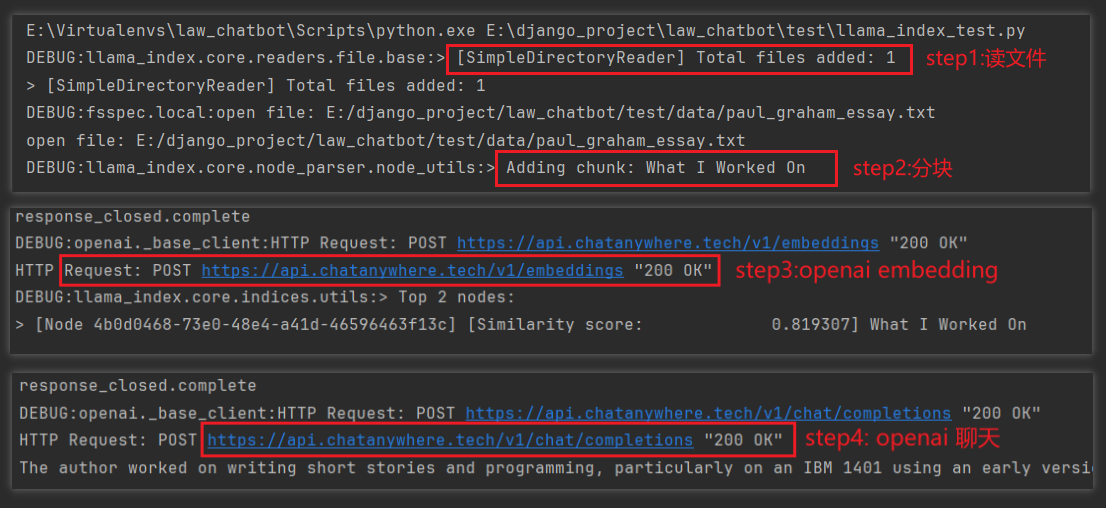
查看存储的内容:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号