MetaGPT day05 MetaGPT 爬虫工程师智能体
Metagpt 爬虫智能体
需求
1.用ActionNode重写订阅智能体,实现自然语言爬取解析网站内容
2. 根据尝试实现思路1,即使用llm提取出需要的信息而不是写爬虫代码。
3. 目前,订阅智能体是通过RunSubscription运行的,即RunSubscription这个action,不仅创建了订阅智能体代码,并启动了SubscriptionRunner,这会让我们的RunSubscription一直无法退出,请尝试将二者分离,即从RunSubscription分离出AddSubscriptionTask的action,并且让SubscriptionRunner单独运行(可以是同一个进程也可以是不同的进程。
实现思路
可以有两个思路:
1. 我们实现一个智能体,它可以爬取我们要求的任意网站,然后进行数据的分析,最后再总结;
2. 实现一个可以写订阅智能体代码的智能体,这个智能体可以浏览我们需要爬取的网页,写爬虫和网页信息提取的代码,生成Role,甚至根据我们的订阅需求,直接完整调用SubscriptionRunner,实现我们的订阅需求
提取页面梗概内容
def get_outline(page):
"""
从 HTML 页面提取文档大纲信息,返回一个包含元素信息的列表。
Args:
page: 包含 HTML 内容的页面对象。
Returns:
list: 包含元素信息的列表,每个元素信息是一个字典,包括元素的名称、深度、文本内容、
可能的 ID 和类别信息。
Note:
该函数通过调用 _get_soup 函数,使用 BeautifulSoup 解析 HTML 页面。
然后,通过递归处理 HTML 树中的每个元素,提取其名称、深度、文本内容等信息。
在递归过程中,忽略了一些特定的元素(如 script 和 style 标签)。
对于某些特殊标签(如 svg),只提取名称和深度,而不提取文本内容。
最终,将提取的元素信息以字典形式组织成列表,表示文档的大纲结构。
"""
# 使用 _get_soup 函数解析 HTML 页面
soup = _get_soup(page.html)
# 初始化存储文档大纲信息的列表
outline = []
def process_element(element, depth):
"""
递归处理 HTML 元素,提取其信息并添加到大纲列表中。
Args:
element: 当前处理的 HTML 元素。
depth: 元素的深度。
Returns:
None
"""
# 获取元素名称
name = element.name
# 忽略没有名称的元素
if not name:
return
# 忽略特定的元素(script 和 style 标签)
if name in ["script", "style"]:
return
# 初始化元素信息字典
element_info = {"name": element.name, "depth": depth}
# 对于特殊标签(如 svg),只提取名称和深度,不提取文本内容
if name in ["svg"]:
element_info["text"] = None
outline.append(element_info)
return
# 提取元素文本内容
element_info["text"] = element.string
# 检查元素是否具有 "id" 属性,如果是则添加到元素信息中
if "id" in element.attrs:
element_info["id"] = element["id"]
# 检查元素是否具有 "class" 属性,如果是则添加到元素信息中
if "class" in element.attrs:
element_info["class"] = element["class"]
# 将当前元素信息添加到大纲列表
outline.append(element_info)
# 递归处理当前元素的子元素
for child in element.children:
process_element(child, depth + 1)
# 遍历 HTML body 元素的子元素,开始构建文档大纲
for element in soup.body.children:
process_element(element, 1)
# 返回最终的文档大纲列表
return outline
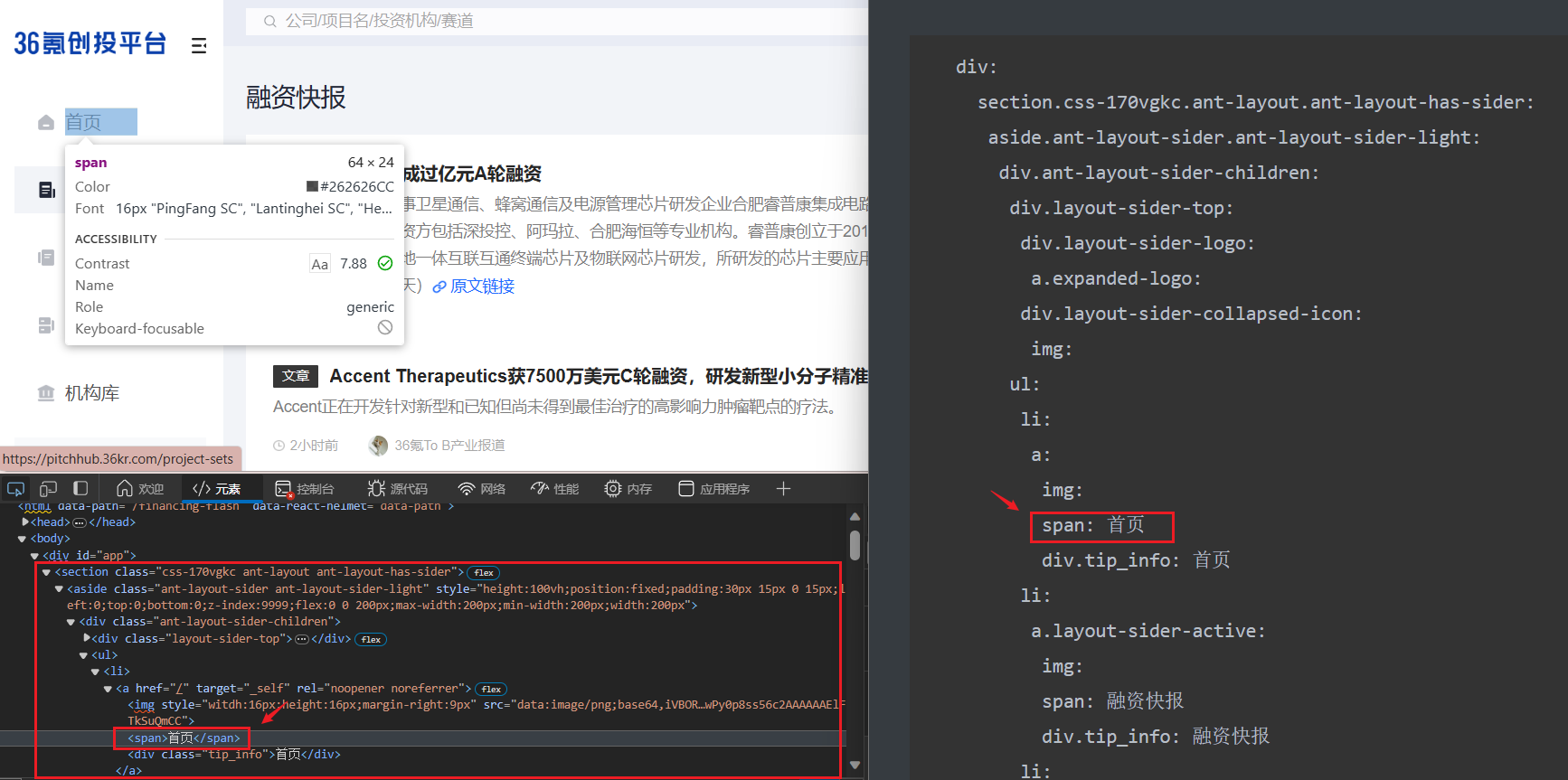
如下是传给爬虫工程师智能体的网页梗概,爬虫工程师根据这个来写爬虫代码:
div:
section.css-170vgkc.ant-layout.ant-layout-has-sider:
aside.ant-layout-sider.ant-layout-sider-light:
div.ant-layout-sider-children:
div.layout-sider-top:
div.layout-sider-logo:
a.expanded-logo:
div.layout-sider-collapsed-icon:
img:
ul:
li:
a:
img:
span: 首页
div.tip_info: 首页
li:
a.layout-sider-active:
img:
span: 融资快报
div.tip_info: 融资快报
li:
a:
img:
span: 融资事件
div.tip_info: 融资事件
li:
a:
img:
span: 项目库
div.tip_info: 项目库
li:
a:
img:
span: 机构库
div.tip_info: 机构库
li:
a:
img:
span: 项目集
div.tip_info: 项目集
li:
a:
img:
span: 定向对接
div.tip_info: 定向对接
li:
a:
img:
span: 融通创新
div.tip_info: 融通创新
section.site-layout.content-transition-big.ant-layout:
main.ant-layout-content:
div.pc-layout-header-wrp:
div.css-1h3sp1q:
div.header-content:
div.header-row.css-vxgrp0:
div.css-tpekb2:
div.search:
div.css-1sg8hfp:
div.custom-search-input.ant-select-show-search.ant-select-auto-complete.ant-select.ant-select-combobox.ant-select-enabled:
div.ant-select-selection.ant-select-selection--single:
div.ant-select-selection__rendered:
div.ant-select-selection__placeholder: 公司/项目名/投资机构/赛道
ul:
li.ant-select-search.ant-select-search--inline:
div.ant-select-search__field__wrap:
input.ant-input.ant-select-search__field:
span.ant-select-search__field__mirror:
span.ant-select-arrow:
i.anticon.anticon-down.ant-select-arrow-icon:
svg:
div.css-aiepd8:
div.login:
a.backTo36Kr: 返回36氪
div.css-0: 登录
div.css-b1f3kf: 登录
div.login-text: 登录
div.pc-layout-content-wrapper-outer.css-w72mzi:
div.pc-layout-content-wrapper.css-cw5dhi:
div:
div.css-s23dpp:
div.css-vxgrp0:
div.css-tpekb2:
div.css-kpimdk:
h1.page-title: 融资快报
div.content-flow:
div.newsflash-catalog-flow:
div.kr-loading-more:
div:
div.css-xle9x:
div.item-title:
span.type: 快讯
a.title: 睿普康完成过亿元A轮融资
div.item-desc:
span: 近日,国内专业从事卫星通信、蜂窝通信及电源管理芯片研发企业合肥睿普康集成电路有限公司(简称“睿普康”)成功完成A轮融资,融资总额过亿元。本轮投资方包括深投控、阿玛拉、合肥海恒等专业机构。睿普康创立于2019年,是专业的卫星通信、蜂窝通信及电源管理芯片研发企业,专注于天地一体互联互通终端芯片及物联网芯片研发,所研发的芯片主要应用于汽车通信、智能手机、物联网、智能电网、智慧家庭等领域。(一元航天)
... 后续省略
使用自然语言写爬虫代码
import datetime
import sys
from typing import Optional
from uuid import uuid4
from aiocron import crontab
from metagpt.actions import UserRequirement
from metagpt.actions.action import Action
from metagpt.actions.action_node import ActionNode
from metagpt.roles import Role
from metagpt.schema import Message
from metagpt.tools.web_browser_engine import WebBrowserEngine
from metagpt.utils.common import CodeParser, any_to_str
from metagpt.utils.parse_html import _get_soup
from pytz import BaseTzInfo
from metagpt.logs import logger
# 先写NODES
LANGUAGE = ActionNode(
key="Language",
expected_type=str,
instruction="Provide the language used in the project, typically matching the user's requirement language.",
example="en_us",
)
CRON_EXPRESSION = ActionNode(
key="Cron Expression",
expected_type=str,
instruction="If the user requires scheduled triggering, please provide the corresponding 5-field cron expression. "
"Otherwise, leave it blank.",
example="15 14 * * *",
)
CRAWLER_URL_LIST = ActionNode(
key="Crawler URL List",
expected_type=list[str],
instruction="List the URLs user want to crawl. Leave it blank if not provided in the User Requirement.",
example=["https://example1.com", "https://example2.com"],
)
PAGE_CONTENT_EXTRACTION = ActionNode(
key="Page Content Extraction",
expected_type=str,
instruction="Specify the requirements and tips to extract from the crawled web pages based on User Requirement.",
example="Retrieve the titles and content of articles published today.",
)
CRAWL_POST_PROCESSING = ActionNode(
key="Crawl Post Processing",
expected_type=str,
instruction="Specify the processing to be applied to the crawled content, such as summarizing today's news.",
example="Generate a summary of today's news articles.",
)
INFORMATION_SUPPLEMENT = ActionNode(
key="Information Supplement",
expected_type=str,
instruction="If unable to obtain the Cron Expression, prompt the user to provide the time to receive subscription "
"messages. If unable to obtain the URL List Crawler, prompt the user to provide the URLs they want to crawl. Keep it "
"blank if everything is clear",
example="",
)
NODES = [
LANGUAGE,
CRON_EXPRESSION,
CRAWLER_URL_LIST,
PAGE_CONTENT_EXTRACTION,
CRAWL_POST_PROCESSING,
INFORMATION_SUPPLEMENT,
]
PARSE_SUB_REQUIREMENTS_NODE = ActionNode.from_children("ParseSubscriptionReq", NODES)
PARSE_SUB_REQUIREMENT_TEMPLATE = """
### User Requirement
{requirements}
"""
SUB_ACTION_TEMPLATE = """
## Requirements
Answer the question based on the provided context {process}. If the question cannot be answered, please summarize the context.
## context
{data}"
"""
PROMPT_TEMPLATE = """Please complete the web page crawler parse function to achieve the User Requirement. The parse \
function should take a BeautifulSoup object as input, which corresponds to the HTML outline provided in the Context.
```python
from bs4 import BeautifulSoup
# only complete the parse function
def parse(soup: BeautifulSoup):
...
# Return the object that the user wants to retrieve, don't use print
```
## User Requirement
{requirement}
## Context
The outline of html page to scrabe is show like below:
```tree
{outline}
```
"""
# 辅助函数: 获取html css大纲视图
def get_outline(page):
soup = _get_soup(page.html)
outline = []
def process_element(element, depth):
name = element.name
if not name:
return
if name in ["script", "style"]:
return
element_info = {"name": element.name, "depth": depth}
if name in ["svg"]:
element_info["text"] = None
outline.append(element_info)
return
element_info["text"] = element.string
# Check if the element has an "id" attribute
if "id" in element.attrs:
element_info["id"] = element["id"]
if "class" in element.attrs:
element_info["class"] = element["class"]
outline.append(element_info)
for child in element.children:
process_element(child, depth + 1)
for element in soup.body.children:
process_element(element, 1)
return outline
# 触发器:crontab
class CronTrigger:
def __init__(self, spec: str, tz: Optional[BaseTzInfo] = None) -> None:
segs = spec.split(" ")
if len(segs) == 6:
spec = " ".join(segs[1:])
self.crontab = crontab(spec, tz=tz)
def __aiter__(self):
return self
async def __anext__(self):
await self.crontab.next()
return Message(datetime.datetime.now().isoformat())
# 写爬虫代码的Action
class WriteCrawlerCode(Action):
async def run(self, requirement):
requirement: Message = requirement[-1]
data = requirement.instruct_content.dict()
urls = data["Crawler URL List"]
query = data["Page Content Extraction"]
codes = {}
for url in urls:
codes[url] = await self._write_code(url, query)
return "\n".join(f"# {url}\n{code}" for url, code in codes.items())
async def _write_code(self, url, query):
page = await WebBrowserEngine().run(url)
outline = get_outline(page)
outline = "\n".join(
f"{' '*i['depth']}{'.'.join([i['name'], *i.get('class', [])])}: {i['text'] if i['text'] else ''}"
for i in outline
)
code_rsp = await self._aask(PROMPT_TEMPLATE.format(outline=outline, requirement=query))
code = CodeParser.parse_code(block="", text=code_rsp)
return code
# 分析订阅需求的Action
class ParseSubRequirement(Action):
async def run(self, requirements):
requirements = "\n".join(i.content for i in requirements)
context = PARSE_SUB_REQUIREMENT_TEMPLATE.format(requirements=requirements)
node = await PARSE_SUB_REQUIREMENTS_NODE.fill(context=context, llm=self.llm)
return node
# 运行订阅智能体的Action
class RunSubscription(Action):
async def run(self, msgs):
from metagpt.roles.role import Role
from metagpt.subscription import SubscriptionRunner
code = msgs[-1].content
req = msgs[-2].instruct_content.dict()
urls = req["Crawler URL List"]
process = req["Crawl Post Processing"]
spec = req["Cron Expression"]
SubAction = self.create_sub_action_cls(urls, code, process)
SubRole = type("SubRole", (Role,), {})
role = SubRole()
role._init_actions([SubAction])
runner = SubscriptionRunner()
async def callback(msg):
print(msg)
await runner.subscribe(role, CronTrigger(spec), callback)
await runner.run()
@staticmethod
def create_sub_action_cls(urls: list[str], code: str, process: str):
modules = {}
for url in urls[::-1]:
code, current = code.rsplit(f"# {url}", maxsplit=1)
name = uuid4().hex
module = type(sys)(name)
exec(current, module.__dict__)
modules[url] = module
class SubAction(Action):
async def run(self, *args, **kwargs):
pages = await WebBrowserEngine().run(*urls)
if len(urls) == 1:
pages = [pages]
data = []
for url, page in zip(urls, pages):
data.append(getattr(modules[url], "parse")(page.soup))
return await self.llm.aask(SUB_ACTION_TEMPLATE.format(process=process, data=data))
return SubAction
# 定义爬虫工程师角色
class CrawlerEngineer(Role):
name: str = "John"
profile: str = "Crawling Engineer"
goal: str = "Write elegant, readable, extensible, efficient code"
constraints: str = "The code should conform to standards like PEP8 and be modular and maintainable"
def __init__(self, **kwargs) -> None:
super().__init__(**kwargs)
self._init_actions([WriteCrawlerCode])
self._watch([ParseSubRequirement])
# 定义订阅助手角色
class SubscriptionAssistant(Role):
"""Analyze user subscription requirements."""
name: str = "Grace"
profile: str = "Subscription Assistant"
goal: str = "analyze user subscription requirements to provide personalized subscription services."
constraints: str = "utilize the same language as the User Requirement"
def __init__(self, **kwargs) -> None:
super().__init__(**kwargs)
self._init_actions([ParseSubRequirement, RunSubscription])
self._watch([UserRequirement, WriteCrawlerCode])
async def _think(self) -> bool:
cause_by = self._rc.history[-1].cause_by
if cause_by == any_to_str(UserRequirement):
state = 0
elif cause_by == any_to_str(WriteCrawlerCode):
state = 1
if self._rc.state == state:
self._rc.todo = None
return False
self._set_state(state)
return True
async def _act(self) -> Message:
logger.info(f"{self._setting}: ready to {self._rc.todo}")
response = await self._rc.todo.run(self._rc.history)
msg = Message(
content=response.content,
instruct_content=response.instruct_content,
role=self.profile,
cause_by=self._rc.todo,
sent_from=self,
)
self._rc.memory.add(msg)
return msg
if __name__ == "__main__":
import asyncio
from metagpt.team import Team
team = Team()
team.hire([SubscriptionAssistant(), CrawlerEngineer()])
team.run_project("从36kr创投平台https://pitchhub.36kr.com/financing-flash爬取所有初创企业融资的信息,获取标题,链接, 时间,总结今天的融资新闻,然后在14:20发送给我")
asyncio.run(team.run())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号