机器学习定义 监督学习 无监督学习
机器学习定义
Arthur Samuel的定义:

使计算机无需明确编程即可学习的研究领域称为机器学习。

机器学习的两种主要类型:监督学习 无监督学习
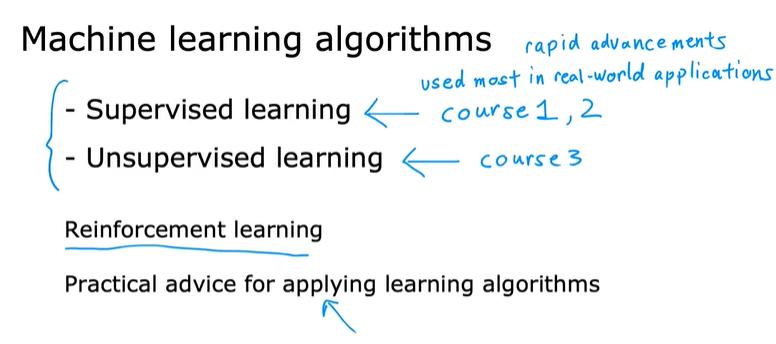
监督学习
当今机器学习创造经济价值的99%都是来自于一种机器学习 --- 监督学习
常见的监督学习是指:
学习x到y 或者输入到输出 二者之间映射关系的算法
监督学习的主要特点是:
你给你的学习算法提供学习的例子。
这些例子中有正确答案。
对于给定的输入x,表上正确的标签y。
通过学习正确的输入x和期望的输出y,算法最终能够只接受输入,而不需要接受输出标签,就能给出合理准确的输出预测或猜测。
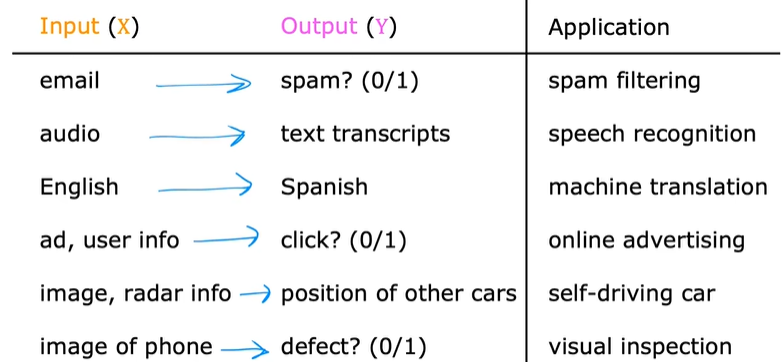
回归 Regression
房价预测例子:通过房屋的大小,预测房屋的价格
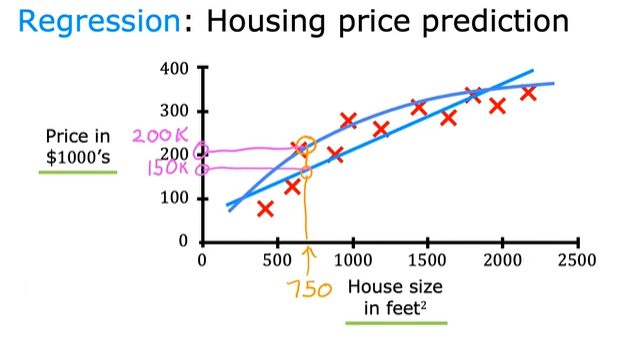
如何系统的选择最合适的直线或曲线,或其他方式来拟合数据?
图中的红色叉是标签、是房子的价格,也是所谓的正确答案。
机器学习算法的任务就是找出更多这样的正确答案。
房价预测的例子属于监督学习的一种特殊情况。
他被称为:回归(Regression)
回归:也就是从无限多个可能的数中预测出一个数。比如我们举例中的房价,房价预测的任务是预测数字。
分类 classification
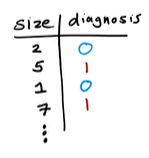
乳腺癌检测例子:
通过病人的医疗记录,判断一个肿块是恶性的,还是良性的。
肿块的大小、是否恶性肿块:
绘制图形:
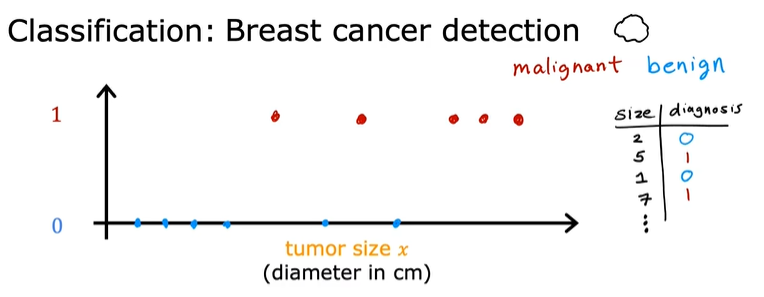
横轴表示肿块的大小,纵轴只有两个值:0、1
(0表示良性 、1表示恶性)
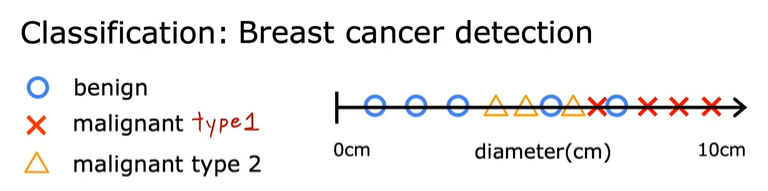
对于二分类问题,还可以在一根轴上作图:

可能的输出类别有三种时:
分类(classification)算法总结:
1.类别不一定是数字。可以是非数值的,比如预测一张图片是猫还是狗。
2.算法预测的结果是一个小的、有限的输出类别集合。
我们的乳腺癌监测例子中,只有一个输入值:肿块的大小。
但是也可以使用多个输入值来预测输出。
两个输入的情况: 年龄、肿瘤大小
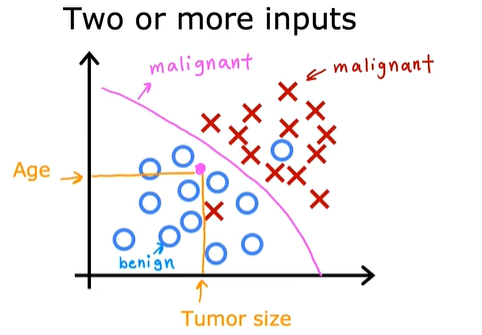
如何预测这个病人的肿瘤是良性的还是恶性的?
学习算法可能会找到一些边界:将恶性肿瘤与良性肿瘤区分开。
学习算法必须知道如何从数据集拟合出一条边界线,将病人区分开,找到的边界线将帮助医生进行诊断。
在机器学习任务中,可能需要更多的输入值:
如肿瘤块的厚度、细胞形状的均匀性等。
无监督学习
聚类 clustering
无监督学习和监督学习一样优秀!
对于监督学习:
每个样本都与一个输出标签y相关联,例如良性肿瘤和恶性肿瘤,用○与×来标记。
对于无监督学习:
我们得到的数据与任何输出标签都没有关联。
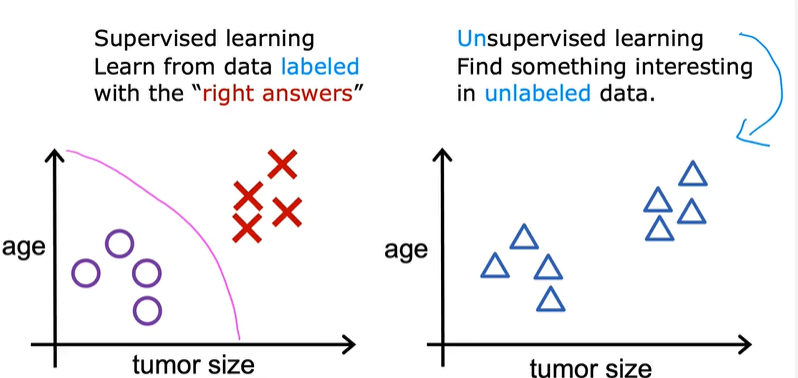
以乳腺癌监测举例,比如我们得到了病人肿瘤大小和年龄的数据,但是我们不知道肿瘤是良性还是恶性的(右图)。
我们没有被要求诊断肿瘤是良性还是恶性的,
相反,我们的工作是去找到这些数据中是否具有某些结构或者模式,
或者只是在数据中发掘有意思的东西,
这就是无监督学习。
称之为无监督学习,是因为我们不是试图监督算法,
而是让算法自己找出有趣的东西,或者数据中可能包含的模式或结构。
以下图为例子,一个非监督学习算法,可能会认为:
数据可以分配给两个不同的组或者两个不同的簇。
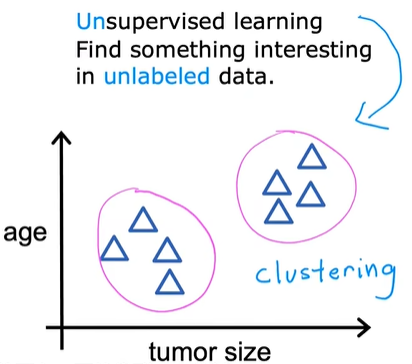
这是一种特殊类型的无监督学习,称为聚类算法(clustering),
聚类算法将未标记的数据放在不同的簇中。
聚类算法的应用
谷歌新闻聚类算法:
 谷歌新闻聚类算法查看成千上万的新闻文章,然后将相关的文章关联在一起。
谷歌新闻聚类算法查看成千上万的新闻文章,然后将相关的文章关联在一起。
比如点击一个熊猫的文章,会有很多跟熊猫相关的文章出现文章的底部或者旁边。
原理:找到所有文章中,提到相似词语的文章,并将他们分组聚类。
没有一个谷歌的员工告诉算法去找到含有熊猫、双胞胎和动物园这三个词的文章,并把他们放在同一个簇中。算法需要在没有监督的情况下,自己弄清楚,今天的新闻应该被划分为哪些簇。
聚类基因、DNA数据:
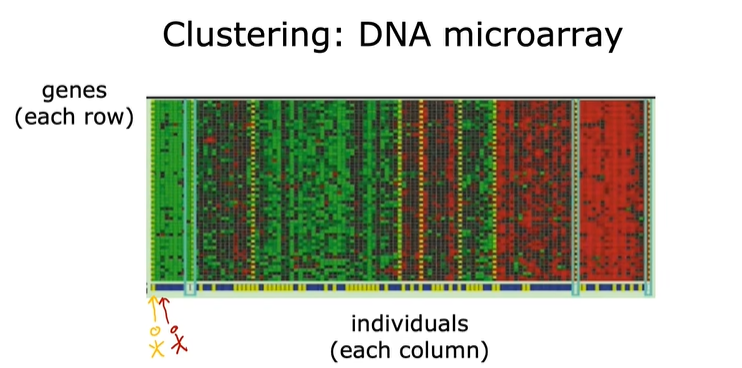
这张图片中的每一小列都代表着一个人的基因或DNA活动。
而每一行都代表一个特定的基因:
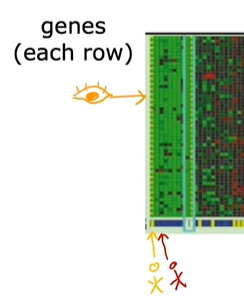
比如这里的一行可能代表影响眼睛颜色的基因。
对于DNA微阵列,其理念是测量每个人特定基因表达量:
这些小色块的颜色(红色、绿色、灰色),显示了不同的个体是否有特定的基因活动(比如眼睛的颜色、身高)。
使用聚类算法对不同类别或者类型的个体进行分类:
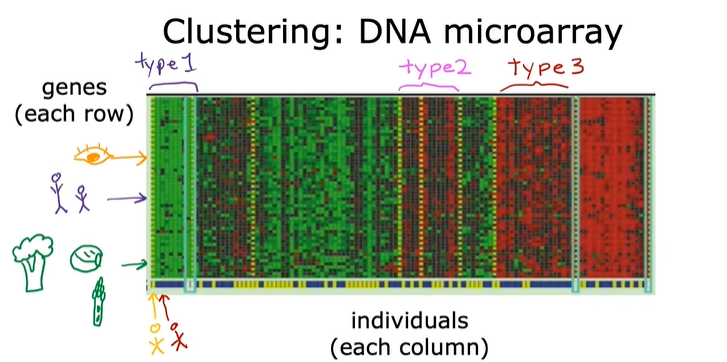
总而言之,无监督学习在没有提前告知这些人有哪些生理特征的情况下,通过DNA对人进行了分类。聚类算法自动寻找数据的结构,自动的找到每个人所属的类,这同样是无监督学习。
社区用户聚类:
通过客户数据,自动的将客户分组,以便于高效的服务客户。
聚类算法猜想客户的动机,将客户进行分组:
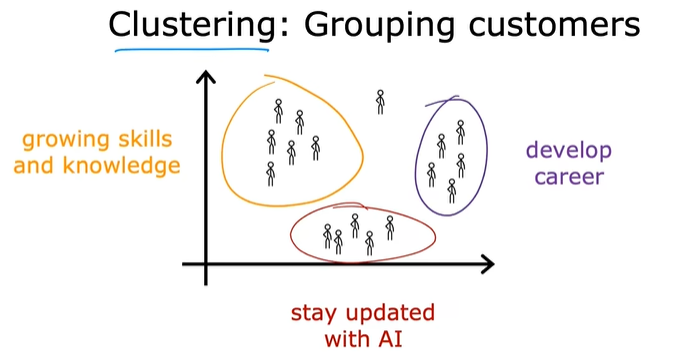
聚类算法总结:
这是一种无监督算法,它获取没有标签的数据,并尝试将它们自动分组到不同的簇中。
更多无监督学习算法
无监督学习定义:在无监督学习中,数据仅仅带有输入x,但是没有输出标签y。我们的算法从数据中找到一些结构、模式或者一些有趣的东西。

异常检测(Anomaly detetion):
异常检测算法用于检测异常事件。
最常见的是用于金融系统的欺诈检测,系统中的不寻常数据以及异常交易可能是欺诈的迹象。
降维(Dimensionality reduction):
降维可以帮助你将一个大数据集尽可能的压缩成一个小的数据集,同时丢失尽可能少的信息。
练习

答案:BC

 浙公网安备 33010602011771号
浙公网安备 33010602011771号