ajax补充说明 多对多三种创建方式 django内置序列化组件 ORM批量操作数据 分页器 form组件入门
ajax补充说明
主要是针对回调函数args接收到的响应数据
1.后端request.is_ajax()
用于判断当前请求是否由ajax发出
2.后端返回的三板斧都会被args接收不再影响整个浏览器页面
3.选择使用ajax做前后端交互的时候 后端一般返回的都是字典数据
user_dict = {'code': 10000, 'username': '小阳人', 'hobby': '哎呦喂~'}
ajax自动反序列化后端的json格式的bytes类型数据
dataType:'json',
request.is_ajax()
request.is_ajax()在后端使用,
主要用于判断当前请求是否由ajax发出。
向后端发送ajax请求:
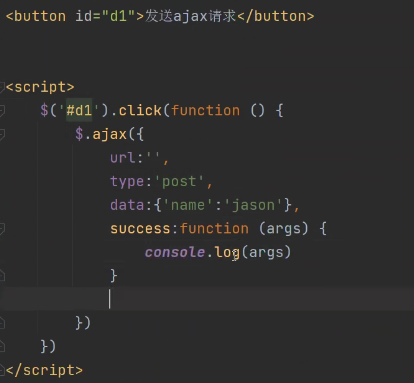
在视图函数用request.is_ajax()判断当前请求是否为ajax请求。结果会得到一个布尔值。

ajax可以发各种请求(post、get),这个方法能识别出ajax发送的任何请求。
第二种写法:
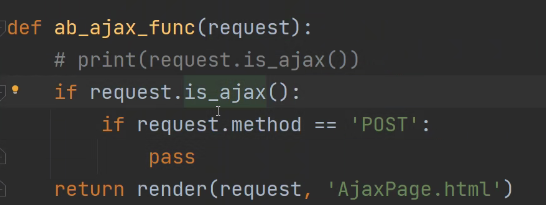
相当于对ajax请求进行二次筛选。第一次判断是否为ajax请求,第二次判断是哪一种ajax请求(get、post或者其他请求)
ajax回调函数接收返回值
后端返回的三板斧( HttpResponse、render、redirect)都会被回调函数args接收,而不再影响整个浏览器页面,不会导致整个页面刷新。
视图函数的返回值是什么数据格式?
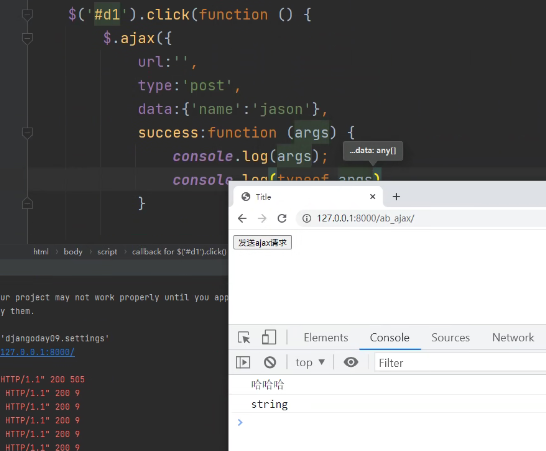
回调函数接受httpResponse:
如下图args的数据类型是string,也就是字符串。
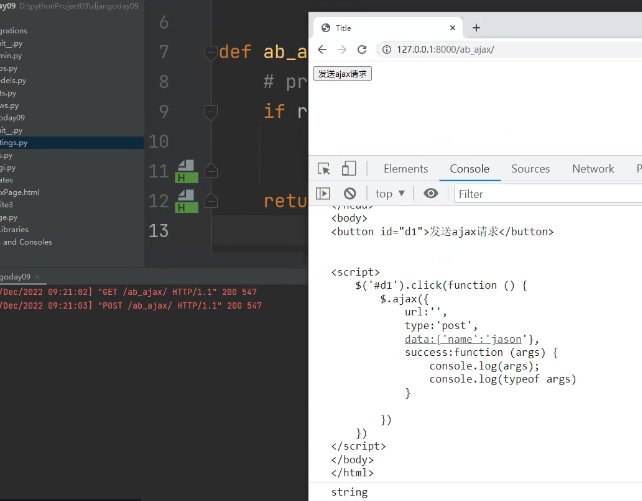
回调函数接受render:
如下图args将会接受到整个html页面,并且数据类型也是string
回调函数接收redirect重定向:
重定向会失效,页面会报错。
ajax回调函数 接受json数据
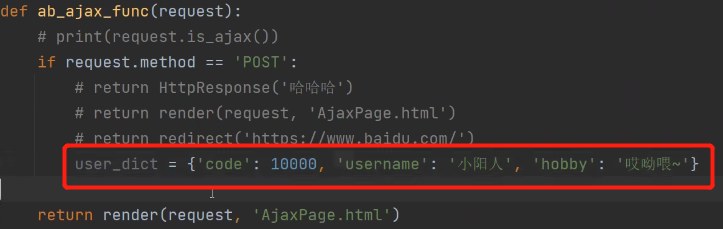
选择使用ajax做前后端交互的时候 后端一般返回的都是字典数据
user_dict = {'code': 10000, 'username': '小阳人', 'hobby': '哎呦喂~'}
ajax自动反序列化后端的json格式的bytes类型数据
dataType:'json',
选择使用ajax做前后端交互的时候 后端一般返回的都是字典数据
我们可以在这个字典中 自定义响应状态码 如'code': 10000
ajax回调函数可以依据不同的状态码做不同的操作。
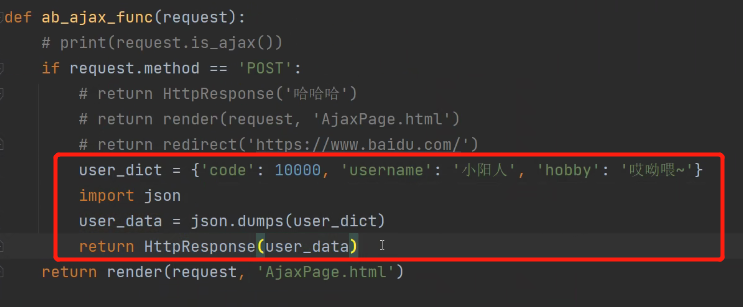
第一种方式:后端使用json模块
在后端使用json模块序列化处理字典:
在前端回调函数args接受:
从后端传来的这个字典到前端会变成JavaScript的字符串类型:
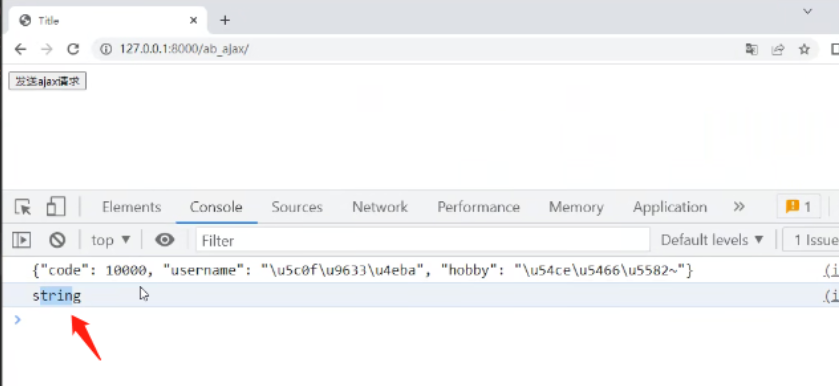
字符串是无法用点取值的。
所以需要在前端进行反序列化,转化为JavaScript字典对象。
使用JSON.parse方法对args获取到的字典进行反序列化:
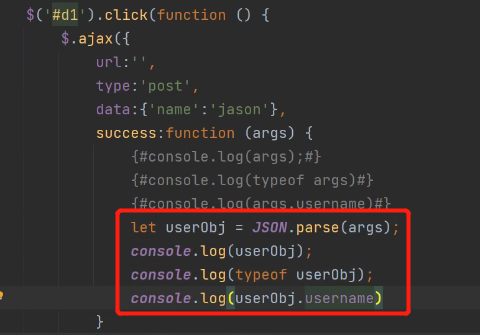
查看数据类型:

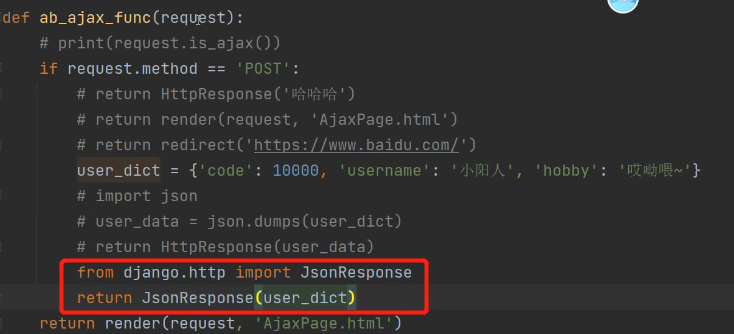
第二种方式:后端返回JsonResponse
如下图,将字典放入JsonResponse中返回给前端:
查看结果:
此时args接受的是JsonResponce。
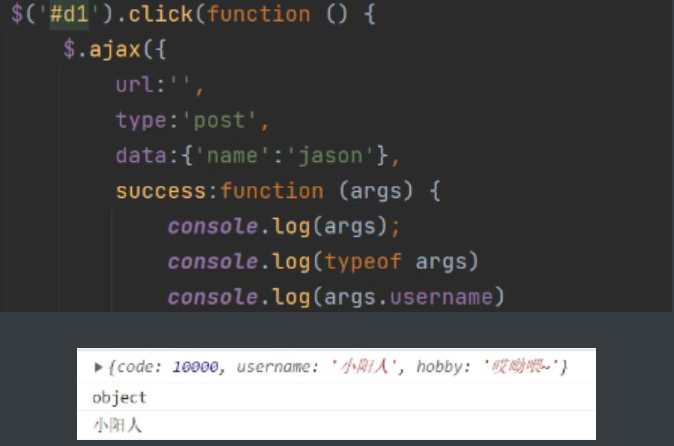
这时无需使用``JSON.parse`方法转换。
前端会识别JsonResponce对象,并自动反序列化,转换成JavaScript对象。
第三种方式:ajax配置参数
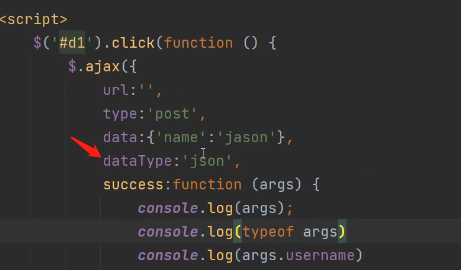
添加了dataType:'json'这个参数之后,ajax回调函数接受到json字符串会自动反序列化。
多对多三种创建方式
全自动创建
1.全自动创建
class Book(models.Model):
title = models.CharField(max_length=32)
authors = models.ManyToManyField(to='Author')
class Author(models.Model):
name = models.CharField(max_length=32)
优势:自动创建第三张表 并且提供了add、remove、set、clear四种操作
劣势:第三张表无法创建更多的字段 扩展性较差
'''以书籍表和作者表举例:
现在我想知道书和作者的关系是什么时候绑定的,这是无从得知的,因为第三张表没有这个字段,也无法新增一个时间字段。'''
纯手动创建
2.纯手动创建
class Book(models.Model):
title = models.CharField(max_length=32)
class Author(models.Model):
name = models.CharField(max_length=32)
class Book2Author(models.Model):
book = models.ForeignKey(to='Book')
author = models.ForeignKey(to='Author')
others = models.CharField(max_length=32)
join_time = models.DateField(auto_now_add=True)
优势:第三张表完全由自己创建 扩展性强
劣势: 1.编写繁琐
2.不再支持add、remove、set、clear(四个修改外键字段的方法) 3.不再具备正反向查询的概念(没有虚拟字段)
半自动创建
3.半自动创建
class Book(models.Model):
title = models.CharField(max_length=32)
authors = models.ManyToManyField(to='Author',
through='Book2Author', through_fields=('book','author')
)
class Author(models.Model):
name = models.CharField(max_length=32)
class Book2Author(models.Model):
book = models.ForeignKey(to='Book', on_delete=models.CASCADE)
author = models.ForeignKey(to='Author', on_delete=models.CASCADE)
others = models.CharField(max_length=32)
join_time = models.DateField(auto_now_add=True)
优势:第三张表完全由自己创建 扩展性强 正反向概念依然清晰可用
劣势:编写繁琐不再支持add、remove、set、clear
半自动创建的原理是:
让django用我们创的表来维系外键关系,并且声明外键关联字段是哪个字段。
首先我们在Book表里声明一个外键字段authors,所以Book表向Author表查询是一个正向查询。但是这样还不够,仅仅只是创建了虚拟字段,和原来的创建多对多没有区别。
这里需要再虚拟字段里面加参数,否则django又会创建第三张表。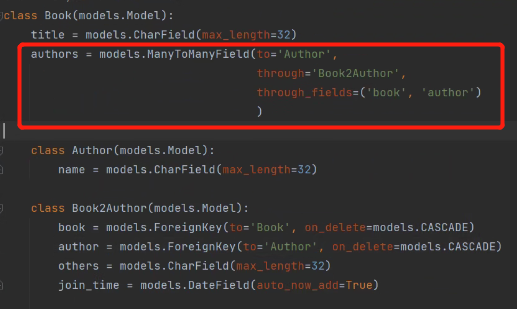
to :申明多对多关系的另外一张表
through: 告诉django第三张表是谁(用哪张表维系外键关系)
through_fields: 告诉django用第三张表的哪个两个字段维系外键关系。
through_fields的参数顺序:
through_fields参数内的字段的顺序不能写错。
我们这里的例子第三张表有两个外键字段:book、author。
虚拟字段在book表里,就把Book2Author中的外键字段book放前面。
虚拟字段在author表时。through_fields=('author','book')
关系表和基础表的概念
删掉表字段 可能会导致同步不了。
django内置序列化组件(drf前身)
'''前后端分离的项目 视图函数只需要返回json格式的数据即可'''
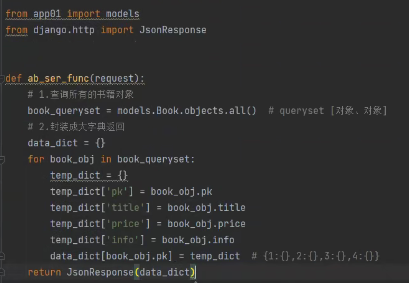
from app01 import models
from django.http import JsonResponse
def ab_ser_func(request):
# 1.查询所有的书籍对象
book_queryset = models.Book.objects.all() # queryset [对象、对象]
# 2.封装成大字典返回
data_dict = {}
for book_obj in book_queryset:
temp_dict = {}
temp_dict['pk'] = book_obj.pk
temp_dict['title'] = book_obj.title
temp_dict['price'] = book_obj.price
temp_dict['info'] = book_obj.info
data_dict[book_obj.pk] = temp_dict # {1:{},2:{},3:{},4:{}}
return JsonResponse(data_dict)
序列化组件(django自带 后续学更厉害的drf)
# 导入内置序列化模块
from django.core import serializers
# 调用该模块下的方法,第一个参数是你想以什么样的方式序列化你的数据
res = serializers.serialize('json', book_queryset)
return HttpResponse(res)
表创建:
不想换库可以把迁移文件删掉。并且源文件也有默认的注册表。
使用JsonResponse传递数据
在前后端分离项目中没有模板语法,前端不认识后端的对象。
此时后端与前端交互的唯一格式 → json格式数据。
在后端将对象中的数据拿出来,转成json大字典的过程,称之为写接口。
查询到所有的书籍对象:

拿到queryset,将queryset中每个对象的数据存入小字典:
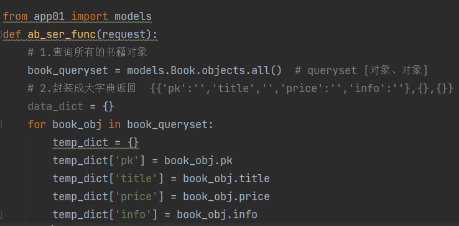
将小字典放入大字典:
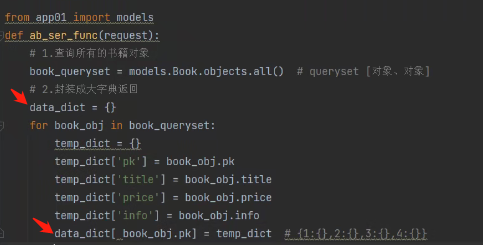
通过JsonResponse返回给前端Json格式数据:
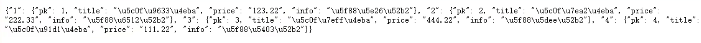
bejson网站:
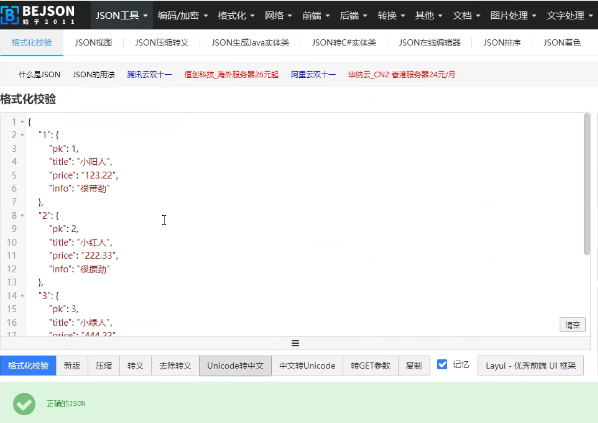
聚合数据:

使用django序列化组件
django自带的专门用来写接口(序列化)的工具:
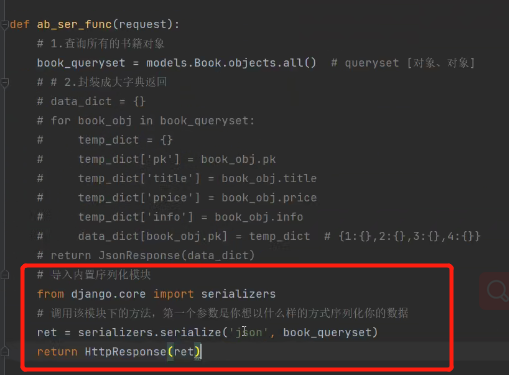
可以直接将queryset转换成json。
前端查看Json数据:

ORM批量操作数据(ORM操作优化)
def ab_bk_func(request):
# 1.往books表中插入10万条数据
# for i in range(1, 100000):
# models.Books.objects.create(title='第%s本书' % i)
"""直接循环插入 10s 500条左右"""
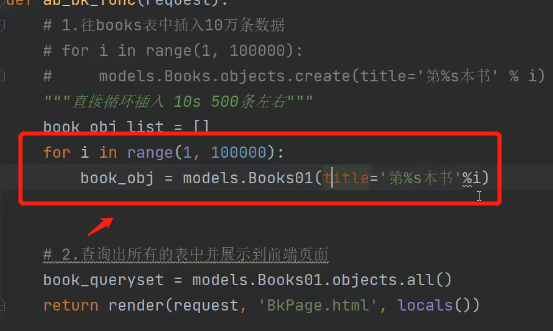
book_obj_list = [] # 可以用列表生成式[... for i in ... if ...] 生成器表达式(... for i in ... if ...)
for i in range(1, 100000):
book_obj = models.Books01(title='第%s本书' % i) # 单纯的用类名加括号产生对象
book_obj_list.append(book_obj)
# 批量插入数据
models.Books01.objects.bulk_create(book_obj_list)
"""使用orm提供的批量插入操作 5s 10万条左右"""
# 2.查询出所有的表中并展示到前端页面
book_queryset = models.Books01.objects.all()
return render(request, 'BkPage.html', locals())
create插入数据
当浏览器发送请求时,此视图函数将向数据库插入十万条数据:
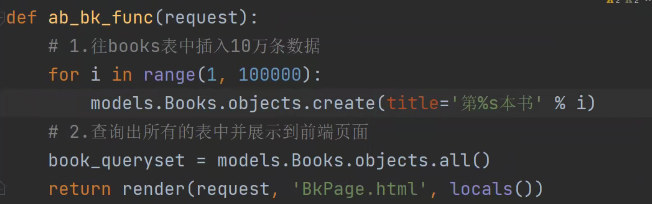
然后再查询表中的所有数据,展示到前端页面:

当我们向该路由发送请求时,会发现浏览器一直在加载:
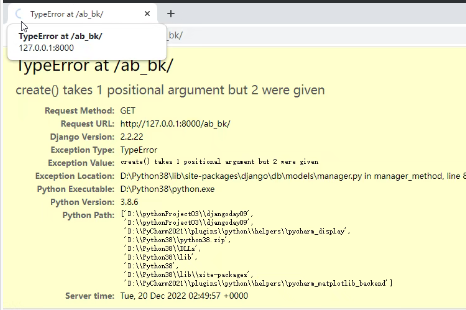
这不是浏览器的问题,而是我们服务端的问题。
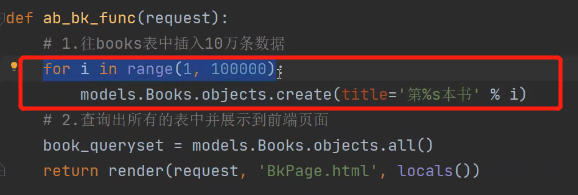
这里插入十万条数据,每次都要写SQL,频繁进行数据库操作,效率极低。
查看结果插入约500多条:
bulk_create批量插入
首先产生书籍对象,将数据存放在对象中,此时没有操作数据库。
将十万个对象存放在列表中。
使用django提供的批量插入数据的方法bulk_create:
将存放了十万个对象的列表放入bulk_create方法(先产生对象 将其放入列表 最后批量插入)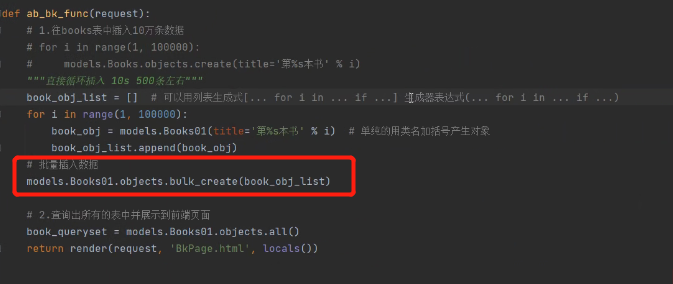
这里存放对象的列表也可以使用占用资源更小的列表生成式、生成器生成式。
django还提供bulk_updata方法可以批量更新数据,使用方法和bulk_create相同(先产生对象 将其放入列表 最后批量更新)。
分页器
为什么需要分页器?
不可能把所有数据都在一页展示!
分页器是前端的任务 分页器主要听处理逻辑
分页器重逻辑 代码少
推导流程
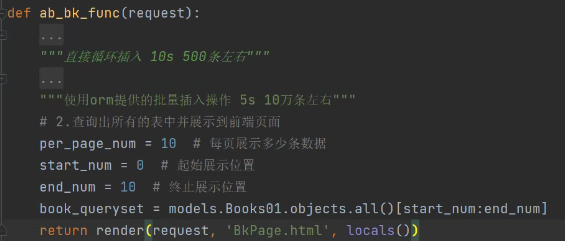
1.queryset支持切片操作(正数)
2.研究各个参数之间的数学关系
每页固定展示多少条数据、起始位置、终止位置
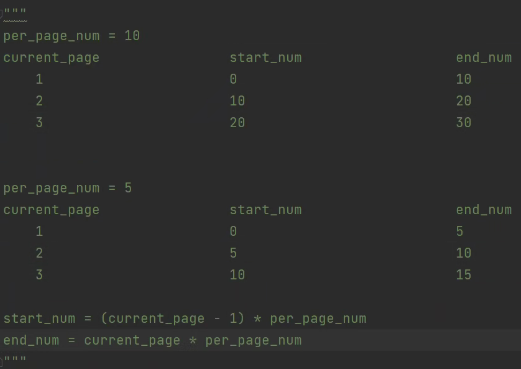
3.自定义页码参数
current_page = request.GET.get('page')
4.前端展示分页器样式
5.总页码数问题
divmod方法
6.前端页面页码个数渲染问题
后端产生 前端渲染
手写分页器
推导流程:
1.queryset支持切片(正数)
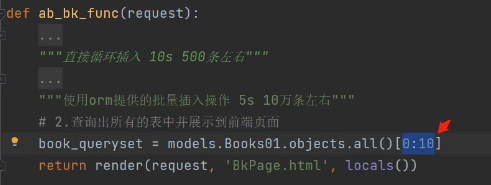
2.研究各个参数之间的数学关系
每页固定展示多少条数据、起始位置、终止位置。
参数配置:
找参数之间的关系:
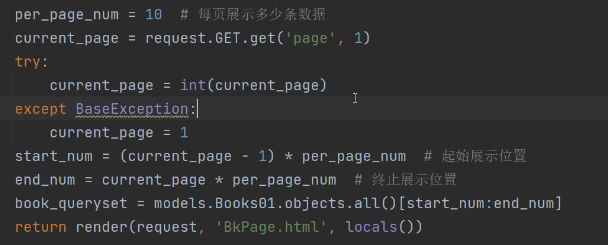
前端获取用户要查看第几页的信息,发get请求到后端&page=1:
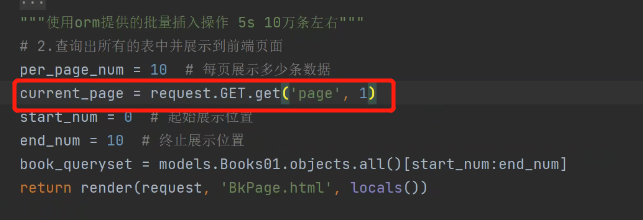
get不到就返回第一页。
考虑到get请求可能会发送非整型的数据,所以使用异常捕获:
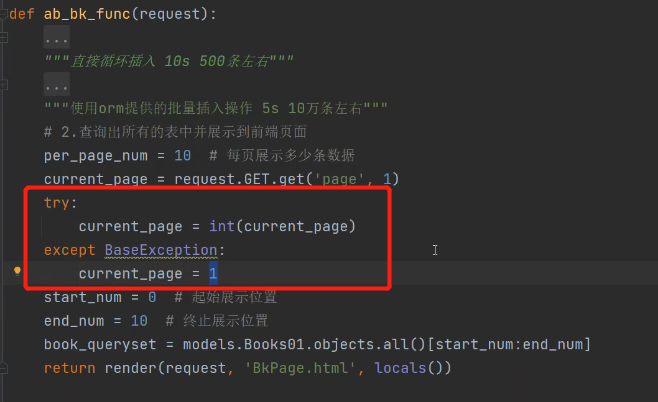
完整代码:
3.自定义页面参数:url匹配 或者 get请求
4.前端分页器代码:
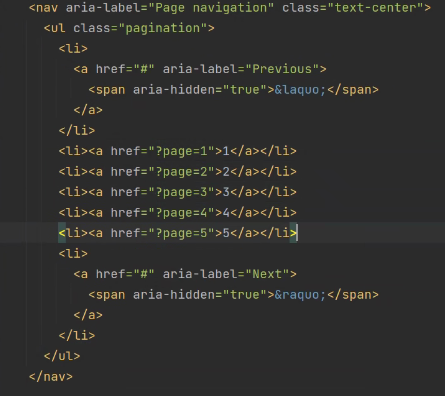 这实际是往本页面发送get请求。视图函数通过不同的参数返回不同的页面。
问题来了,这只能展示5页的数据,而我们有10万条数据。
这实际是往本页面发送get请求。视图函数通过不同的参数返回不同的页面。
问题来了,这只能展示5页的数据,而我们有10万条数据。
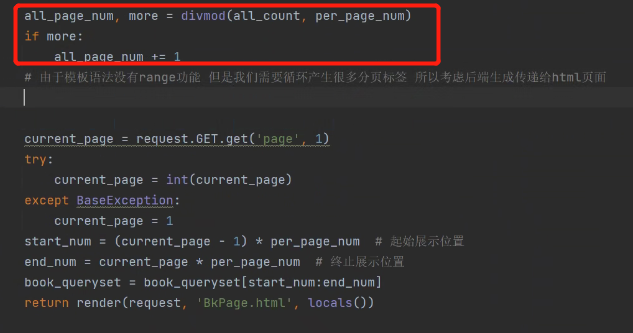
对于被展示的总数据和分页数有如下关系:

我们可以用divmod内置方法取余 通过代码动态计算出总共需要多少页。
余数不为零,就使分页数加一。
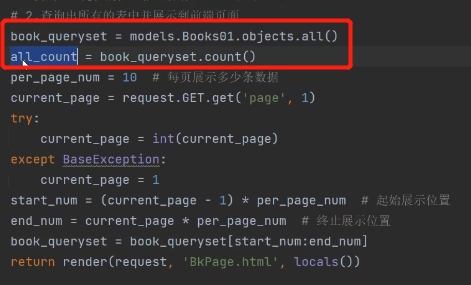
统计queryset中有多少个对象,对应着前端展示多少条数据:
divmod求分页数:
在后端产生标签字符串html_str:
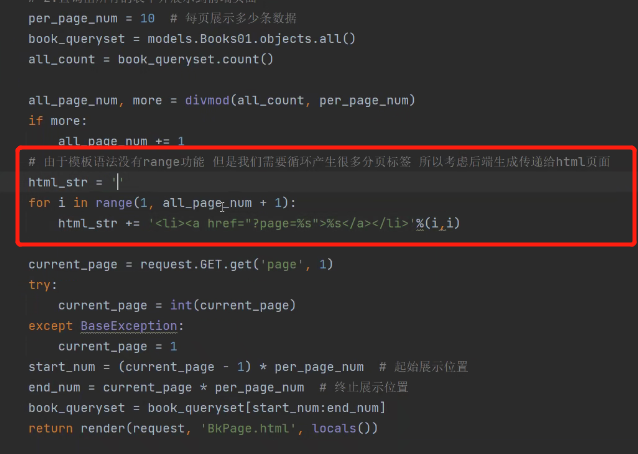
将html_str使用过滤器safe在前端执行:
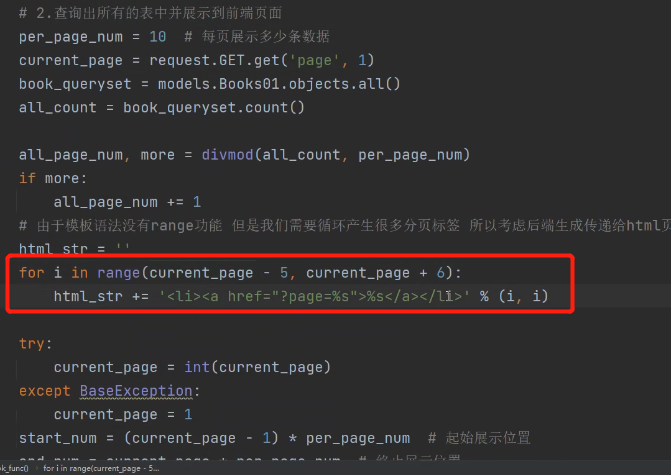
确实能查看所有的数据了,但是这分页数也太多了:

优化:每次只展示11个页码、并且当前页码在最中间。
修改代码:
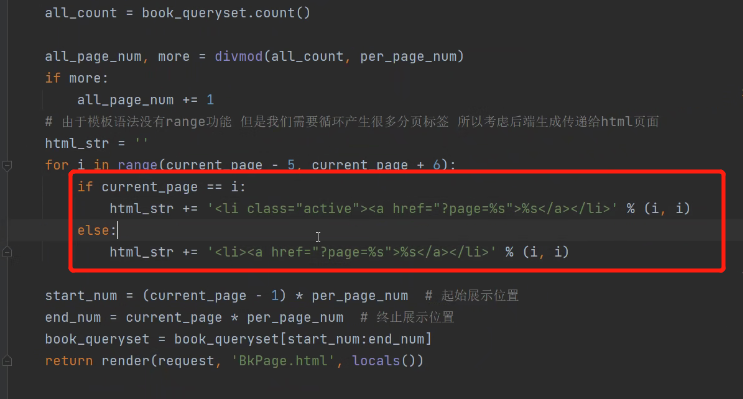
给分页栏添加active激活样式,让用户知道现在处于哪一页:
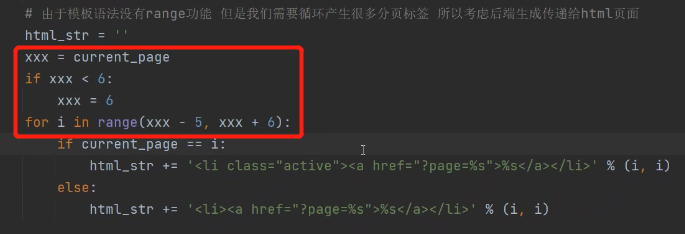
解决5以下页码的问题:
自定义分页器的使用
代码
封装好的分页器代码:
class Pagination(object):
def __init__(self, current_page, all_count, per_page_num=2, pager_count=11):
"""
封装分页相关数据
:param current_page: 当前页
:param all_count: 数据库中的数据总条数
:param per_page_num: 每页显示的数据条数
:param pager_count: 最多显示的页码个数
"""
try:
current_page = int(current_page)
except Exception as e:
current_page = 1
if current_page < 1:
current_page = 1
self.current_page = current_page
self.all_count = all_count
self.per_page_num = per_page_num
# 总页码
all_pager, tmp = divmod(all_count, per_page_num)
if tmp:
all_pager += 1
self.all_pager = all_pager
self.pager_count = pager_count
self.pager_count_half = int((pager_count - 1) / 2)
@property
def start(self):
return (self.current_page - 1) * self.per_page_num
@property
def end(self):
return self.current_page * self.per_page_num
def page_html(self):
# 如果总页码 < 11个:
if self.all_pager <= self.pager_count:
pager_start = 1
pager_end = self.all_pager + 1
# 总页码 > 11
else:
# 当前页如果<=页面上最多显示11/2个页码
if self.current_page <= self.pager_count_half:
pager_start = 1
pager_end = self.pager_count + 1
# 当前页大于5
else:
# 页码翻到最后
if (self.current_page + self.pager_count_half) > self.all_pager:
pager_end = self.all_pager + 1
pager_start = self.all_pager - self.pager_count + 1
else:
pager_start = self.current_page - self.pager_count_half
pager_end = self.current_page + self.pager_count_half + 1
page_html_list = []
# 添加前面的nav和ul标签
page_html_list.append('''
<nav aria-label='Page navigation>'
<ul class='pagination'>
''')
first_page = '<li><a href="?page=%s">首页</a></li>' % (1)
page_html_list.append(first_page)
if self.current_page <= 1:
prev_page = '<li class="disabled"><a href="#">上一页</a></li>'
else:
prev_page = '<li><a href="?page=%s">上一页</a></li>' % (self.current_page - 1,)
page_html_list.append(prev_page)
for i in range(pager_start, pager_end):
if i == self.current_page:
temp = '<li class="active"><a href="?page=%s">%s</a></li>' % (i, i,)
else:
temp = '<li><a href="?page=%s">%s</a></li>' % (i, i,)
page_html_list.append(temp)
if self.current_page >= self.all_pager:
next_page = '<li class="disabled"><a href="#">下一页</a></li>'
else:
next_page = '<li><a href="?page=%s">下一页</a></li>' % (self.current_page + 1,)
page_html_list.append(next_page)
last_page = '<li><a href="?page=%s">尾页</a></li>' % (self.all_pager,)
page_html_list.append(last_page)
# 尾部添加标签
page_html_list.append('''
</nav>
</ul>
''')
return ''.join(page_html_list)
前后端代码:
django自带分页器模块但是使用起来很麻烦 所以我们自己封装了一个
只需要掌握使用方式即可
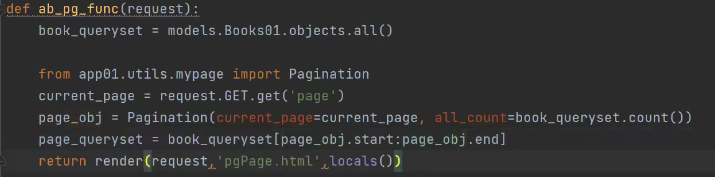
def ab_pg_func(request):
book_queryset = models.Books01.objects.all()
from app01.utils.mypage import Pagination
current_page = request.GET.get('page')
page_obj = Pagination(current_page=current_page, all_count=book_queryset.count())
page_queryset = book_queryset[page_obj.start:page_obj.end]
return render(request, 'pgPage.html', locals())
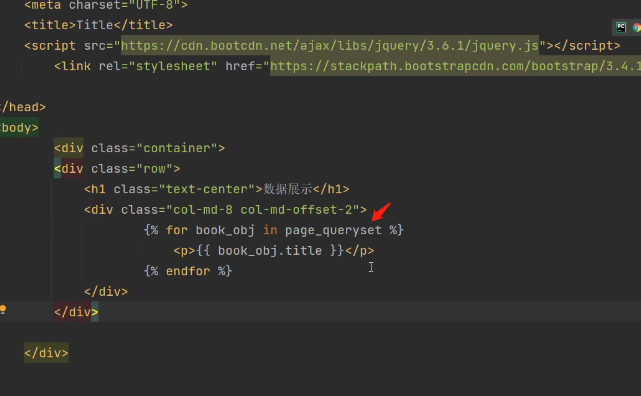
{% for book_obj in page_queryset %}
<p>{{ book_obj.title }}</p>
{% endfor %}
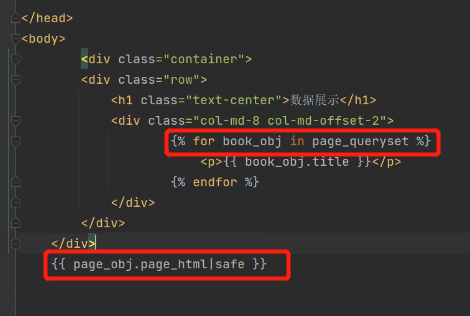
{{ page_obj.page_html|safe }}
django自带分页器组件不好用。我们用自己的。在django app目录下创建目录utils,然后新建一个py文件,将上述代码复制到py文件内
使用说明
1.从数据库查询到所有要展示的数据
2.count方法统计总数据
3.request.GET方法获取用户想要访问的是第几页
4.使用我们封装好的分页器,传入参数,产生page_obj
5.依据page_obj对总数据进行切片,得到page_queryset
 6.在前端页面使用page_queryset,for循环获取一个个书籍对象
6.在前端页面使用page_queryset,for循环获取一个个书籍对象
7.使用page_obj对象的page_html方法,并使用过滤器safe,产生用户可以点击的分页器:
ps: 把函数形参放在双下init 将数据放在对象或者类中
form组件
小需求:获取用户数据并发送给后端校验 后端返回不符合校验规则的提示信息
form组件
1.自动校验数据
2.自动生成标签
3.自动展示信息
from django import forms
class MyForm(forms.Form):
username = forms.CharField(min_length=3, max_length=8) # username字段最少三个字符最大八个字符
age = forms.IntegerField(min_value=0, max_value=200) # 年龄最小0 最大200
email = forms.EmailField() # 必须符合邮箱格式
校验数据的功能(初识)
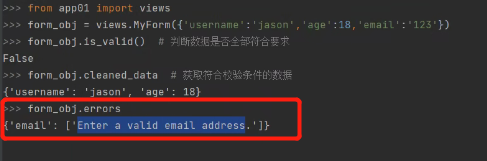
form_obj = views.MyForm({'username':'jason','age':18,'email':'123'})
form_obj.is_valid() # 1.判断数据是否全部符合要求
False # 只要有一个不符合结果都是False
form_obj.cleaned_data # 2.获取符合校验条件的数据
{'username': 'jason', 'age': 18}
form_obj.errors # 3.获取不符合校验规则的数据及原因
{'email': ['Enter a valid email address.']}
1.只校验类中定义好的字段对应的数据 多传的根本不做任何操作
2.默认情况下类中定义好的字段都是必填的
模板语法实现局部刷新
需求: 获取用户数据并发送给后端校验 后端返回不符合校验规则的提示信息
在后端编写提交表单后执行的操作、将字典传入前端页面:
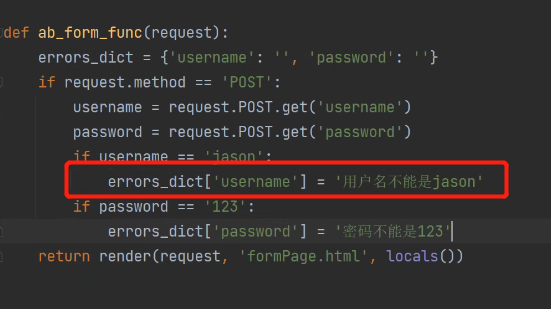
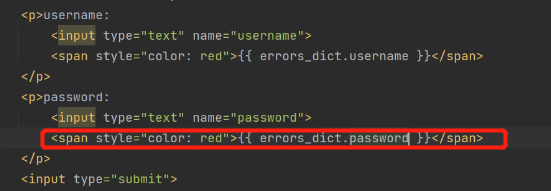
在input标签下面定义红色的span标签。当字典有值时,会将其值展示在前端页面上:
查看效果:
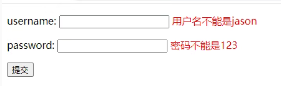
每次提交都会刷新页面。
不需要ajax,也可以产生局部刷新的效果。(使用这个的前提是模板语法:前后端结合的项目)
form组件之校验数据
使用form组件之前需要提前定义好表单类:
表单类有3个属性,意味着后端接受到的表单也应该只有3个数据。

is_valid
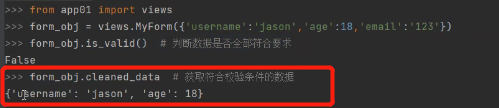
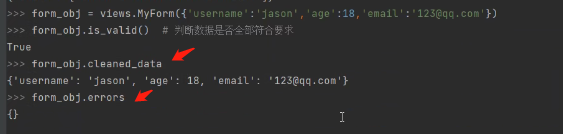
比如我们发送往后端的表单里有3个键值对。使用is_valid方法可以校验这三个键对是否全部符合要求:

如上图可知email不符合数据格式。只要有一个不符合结果就是false.
cleand_data
获取符合校验条件的数据:
errors
获取数据不符合校验条件的原因:
校验功能底层原理
1.表单类中的字段 和 字典的键是一一对应的:
2.表单字段中设定了数据校验条件,如min_length=3
3.会依次取字典的值,根据类中字段的校验条件进行校验。
4.校验通过的数据会存放在cleaned_data,失败的会存放在errors
5.数据传多了:

只会拿类中填写的字段对应的数据。多了不拿。
6.数据传少了:
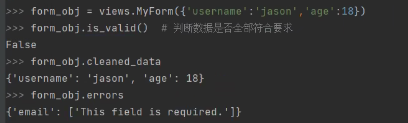
默认的情况下,类中定义好的字段,都是必填的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号