json模块
json模块
简介
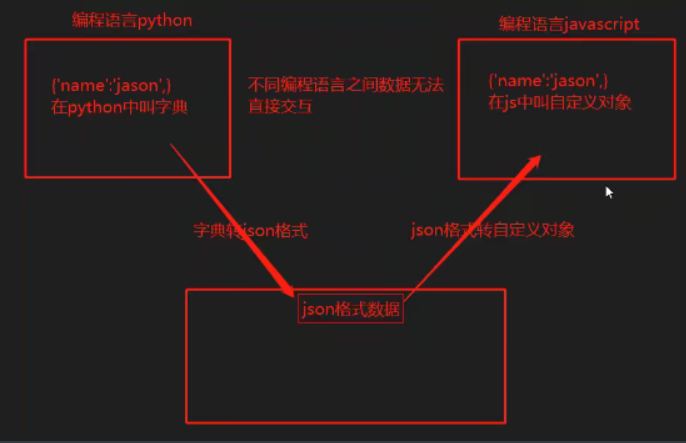
不同的编程语言之间的数据无法直接交互,需要中间有一个翻译官就是json模块。
所有编程语言拿到json数据,都可以将其转换为自己的一种数据类型,方便后续操作。
如python可以将json转为字典。
javascript可以将json转自定义对象。
json.dumps() 、json.loads()
# 1.dumps可以将字典类型转换为json格式的字符串
d1 = {'miku':'999','alice':'666','cloud':'0'}
print(d1,type(d1))
import json
json_str = json.dumps(d1) # {'miku': '999', 'alice': '666', 'cloud': '0'} <class 'dict'>
print(json_str,type(json_str)) # {"miku": "999", "alice": "666", "cloud": "0"} <class 'str'>
print(str(d1)) # {'miku': '999', 'alice': '666', 'cloud': '0'}
# 2.双引号是json字符串的特权
d1 = {"miku":"999","alice":"666","cloud":"0"} # 双引号字典
print(str(d1)) # {'miku': '999', 'alice': '666', 'cloud': '0'}
print(d1) # {'miku': '999', 'alice': '666', 'cloud': '0'}
# 也就是你在字典中使用双引号 实际还是单引号
# 2.loads就是反向操作 将json转字典
import json
d1 = {'miku':'999','alice':'666','cloud':'0'}
print(json.dumps(d1)) # {"miku": "999", "alice": "666", "cloud": "0"}
json_data = json.dumps(d1)
dict_obj = json.loads(json_data)
print(dict_obj) # {'miku': '999', 'alice': '666', 'cloud': '0'} # 注意,变单引号了
print(type(dict_obj)) # <class 'dict'>
json.dump() 、json.load()
'''dump load打交道的都是文件对象 可以在with下面子代码块使用'''
# 1.使用dump
d1 = {'miku':'999','alice':'666','cloud':'0'}
with open('a.txt','w',encoding='utf8') as f:
json.dump(d1,f) # 完成两个操作
# 1.将d1字典转化为json字符串
# 2.将json写入f文件对象
# 2.使用load
with open('a.txt','r',encoding='utf8') as f2:
dict_obj = json.load(f2) # load文件对象
print(dict_obj) # {'miku': '999', 'alice': '666', 'cloud': '0'}
print(type(dict_obj)) # <class 'dict'>
json支持的python数据类型
JSON建构于两种结构:
- “名称/值”对的集合(python中的字典)。不同的语言中,它被理解为对象(object),纪录(record),结构(struct),字典(dictionary),哈希表(hash table),有键列表(keyed list),或者关联数组 (associative array)。
- 值的有序列表(An ordered list of values)。在大部分语言中,它被理解为数组(array)。
json在默认情况下支持以下python对象和类型:
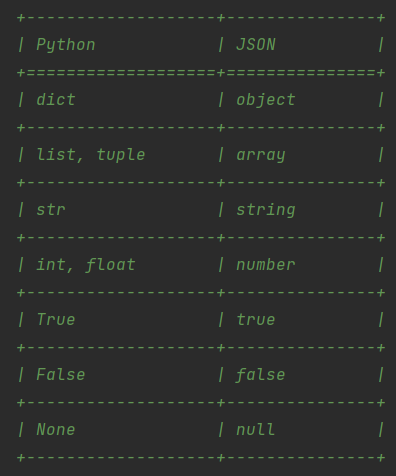
这表格的意思是:
将python中的字典使用json.dump方法转换,实际上是转换成了json object,也就是json数据交换语言中的一种数据类型。
将python中的字符串 转json 则会得到json字符串
import json
str_obj = '小松'
json_str = json.dumps(str_obj)
print(json_str) # "\u5c0f\u677e" # 注意双引号
print(json.loads(json_str)) # 小松
将python中的列表 转json 则会得到json array也就是数组,数组中的值都是用双引号括起来的
import json
list_obj = ['你好','hello','hi'] # python列表
json_array = json.dumps(list_obj)
print(json_array) # ["\u4f60\u597d", "hello", "hi"] # json中的array中的元素是用双引号包起来的
ps:其他的数据类型默认不能序列化, 但是可以继承JsonEncoder给这个方法添加功能,使其支持更多数据类型。
ensure_ascii参数
# json.dump(),json.dumps() 都包含关键字形参 ensure_ascii 这个参数默认为True
# 关于这个参数的解释:
如果ensure_ascii为true,会将非ascii码的字符转换成json字符串。
如果ensure_ascii为false,则dump输出可以包含非ascii字符。
import json
str_obj = '小松'
json_str = json.dumps(str_obj)
print(json_str) # "\u5c0f\u677e" # 注意双引号
json_str2 = json.dumps(str_obj, ensure_ascii=False)
print(json_str2) # "小松" # 注意双引号表示这还是一个json字符串
print(json_str2 == str_obj) # False
user_dict = {'username':'小松','password':'123'}
json_obj = json.dumps(user_dict)
print(json_obj) # {"username": "\u5c0f\u677e", "password": "123"}
json_obj2 = json.dumps(user_dict,ensure_ascii=False)
print(json_obj2) # {"username": "小松", "password": "123"}
indent参数
如果想保存json对象的缩进格式,可以使用indent参数,这个参数可以定义缩进字符的个数。
import json
a_dict = {
'name': 'cloud',
'age': 18,
'hobby': {
1: 'eat',
2: 'drink',
3: 'sleep',
}
}
with open('a.json', 'w', encoding='utf8') as f:
json.dump(a_dict, f)
如上保存的json文件不会缩进:

import json
a_dict = {
'name': 'cloud',
'age': 18,
'hobby': {
1: 'eat',
2: 'drink',
3: 'sleep',
}
}
with open('a.json', 'w', encoding='utf8') as f:
json.dump(a_dict, f, indent=4)
添加indent参数,并定义缩进为4:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号