二分法、三元表达式、列表推导式、匿名函数、常见内置函数
目录
基础算法之二分法
# 最经典的一个问题:猜一个人的年龄,最少要猜几次才能猜中:
1.先猜50岁 啊 猜大了
2.再猜25岁 猜小了
3.所以估计年龄在26-49之间 所以再猜一个中间值
4.周而复始 这种猜年龄的策略就是: 二分法
二分法+递归函数
l1 = [12, 21, 32, 43, 56, 76, 87, 98, 123, 321, 453, 565, 678, 754, 812, 987, 1001, 1232]
# 查找列表中某个数据值
# 方式1:for循环 次数较多
# 方式2:二分法 不断的对数据集做二分切割
'''代码实现二分法'''
# 定义我们想要查找的数据值
target_num = 987
def get_middle(l1, target_num):
# 添加一个结束条件
if len(l1) == 0:
print('很抱歉 没找到')
return
# 1.获取列表中间索引值
middle_index = len(l1) // 2 # 先除2 再向下取整
# 2.比较目标数据值与中间索引值的大小
if target_num > l1[middle_index]:
# 切片保留列表右边一半
right_l1 = l1[middle_index + 1:]
print(right_l1)
# 针对右边一半的列表继续二分并判断 >>>: 感觉要用递归函数
return get_middle(right_l1, target_num)
elif target_num < l1[middle_index]:
# 切片保留列表左边一半
left_l1 = l1[:middle_index]
print(left_l1)
# 针对左边一半的列表继续二分并判断 >>>: 感觉要用递归函数
return get_middle(left_l1, target_num)
else:
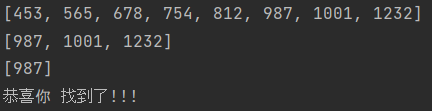
print('恭喜你 找到了!!!')
get_middle(l1, 987) # 结果如下
二分法补充
# 1.二分法使用前提:
数据必须有序 比如列表中的数字必须从小到大排序 此时才能使用
如果列表中的数字无序 就会发现二分法分不开
# 2.二分法的缺点
对于找列表中的数这个问题 如果查找的数在开头、结尾时 二分法效率低
此时还不如for循环 一个一个取出比较效率高
# 补充中的补充
常见的算法: 二分法 冒泡 快排 插入 堆排 桶排
数据结构 (链表 约瑟夫问题 判断链表是否有环)
三元表达式
# 适用情况:我们要进行if判断二选一问题的时候使用
# 注意:三元表达式不要嵌套使用 不要套娃!! 会降低代码可读性
# 简化步骤1:代码简单并且只有一行 那么可以直接在冒号后面编写
name = 'miku'
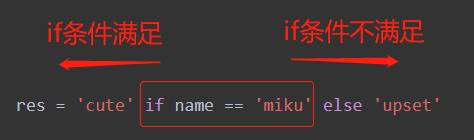
res = 'cute' if name == 'miku' else 'upset'
print(res) # cute
"""
数据值1 if 条件 else 数据值2
条件成立则使用数据值1 条件不成立则使用数据值2
# 阅读的时候从中间的if条件开始阅读就好:
三元表达式适用情况
# 适用情况:我们要进行if判断二选一问题的时候使用
# 注意:三元表达式不要嵌套使用 不要套娃!! 会降低代码可读性
各种生成式/推导式

列表生成式
# 1.给列表所有的字符串加上后缀
name_list = ['jason', 'kevin', 'oscar', 'tony', 'jerry']
new_list = []
for name in name_list:
data = f'{name}miku'
new_list.append(data)
print(new_list)
# 2.用列表生成式实现
name_list = ['jason', 'kevin', 'oscar', 'tony', 'jerry']
new_list = [one + 'miku' for one in name_list]
# 先看for循环
# for循环左边是对one的操作
# 操作完直接把现在one放列表里 [jasonmiku]
# 在for循环取下一个值 操作完也放列表里 [jasonmiku,kevinmiku]
# 周而复始
print(new_list) # ['jasonmiku', 'kevinmiku', 'oscarmiku', 'tonymiku', 'jerrymiku']
# 3.复杂情况
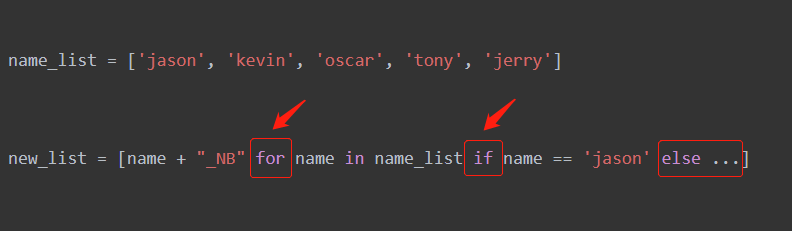
new_list = [name + "_NB" for name in name_list if name == 'jason']
print(new_list)
# 阅读顺序: 先for循环 在看if判断 最后看for循环左边(对name值的一个后处理)
# 4.在列表生成式for循环前面使用 三元表达式
new_list = ['大佬' if name == 'jason' else '小赤佬' for name in name_list if name != 'jack']
print(new_list)
# 阅读顺序:
# 1.先看for循环 再看if判断 再看左边的三元表达式
# 2.进入三元表达式 '大佬' if name == 'jason' else '小赤佬'
# 3.先看if判断 满足if 执行左边 不满足 执行右边的else
注意事项
# 1.生成式只能进行简单的判断 (不要在里面加各种判断 这不是生成式擅长的事儿)
# 2.生成式不支持else 因为if-else for-else会导致逻辑冲突
# 在下图这里加一个else 那这个else到底是属于if 还是属于for 这样会让人迷惑
字典生成式
内置方法enumerate
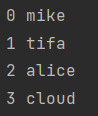
# 1.enumerate用于把列表的引索和数据值一并取出
for i,j in enumerate(['miku','tifa','alice','cloud']):
print(i,j)
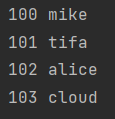
# 2.enumerate还可以传入一个关键字参数start
for i, j in enumerate(['miku', 'tifa', 'alice', 'cloud'], start=100):
print(i, j)
# start的作用是控制索引的起始位置
# 100 miku
字典生成式例子
d1 = {i: j for i, j in enumerate('hello')} # 字符串也可以使用enumerate函数
print(d1)

集合生成式
res = {i for i in 'hello'}
print(res) # {'o', 'e', 'h', 'l'} # 集合是无序的 所以会这样
元祖生成式
# 元组生成式>>>:没有元组生成式 下列的结果是生成器(后面讲)
# 理解成是个工厂 要用就生成
# 可以节省内存
res = (i+'SB' for i in 'hello')
print(res) # <generator object <genexpr> at 0x00000192D42FF120>
for i in res:
print(i)
匿名函数
匿名函数介绍
没有名字的函数 需要使用关键字lambda
语法结构
lambda 形参:返回值
使用场景
lambda a,b:a+b
匿名函数一般不单独使用 需要配合其他函数一起用
常见内置函数
map
l1 = [1, 2, 3, 4, 5]
def func(a):
return a + 1
res = map(func, l1)
print(res) # <map object at 0x000002A3580A5160>
print(list(res)) # [2, 3, 4, 5, 6]
# map作用:
# 对l1这个列表执行func函数
max、min
# 1.简单使用
l1 = [11, 22, 33, 44]
res = max(l1) # 44
# 2.对字典使用
d1 = {
'zj': 100,
'jason': 8888,
'berk': 99999999,
'oscar': 1
}
print(max(d1)) # zj
# 1.max会先对传入的字典使用for循环
# 2.for循环字典只有键会参与
# 3.键是字符串 会取字符串的第一个字母进行比较
# 4.比较的方法是看这个字母对应ASCII表的数字 数字大的在比较中胜出
# 5.a-z对应97-122 A-Z对应65-90
# 6.在键中z对应的数字最大
# 7.所以会输出zj
# 3.更复杂的使用
d1 = {
'zj': 100,
'jason': 8888,
'berk': 99999999,
'oscar': 1
} # 比较字典键值对中的值 输出最大的
# 9999999最大
res = max(d1, key=lambda k: d1.get(k))
print(res) # berk
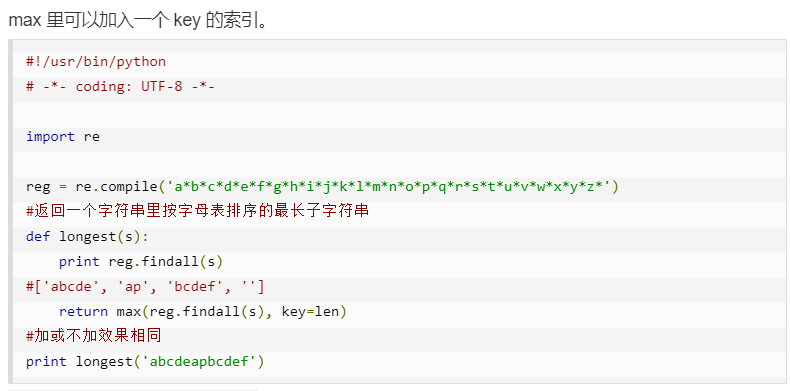
reduce
# 传入多个值返回一个值
# 可以用于列表求和
# 因为使用少 从内置函数中移除
from functools import reduce
l1 = [11, 22, 33, 44, 55, 66, 77, 88]
res = reduce(lambda a, b: a + b, l1) # 将列表所有值求和
print(res) # 396
res2 = reduce(lambda a, b: a + b, l1,100) # 第三个参数的意思 求和之后再加100
print(res2) # 496

 浙公网安备 33010602011771号
浙公网安备 33010602011771号