
最近事情比较多,本篇文章算是把遇到的问题杂糅到一起了。
背景:笔者最近在写一个mongo查询小程序,由于建立索引时字段名用大写,而查询的时候用小写。
代码如下:
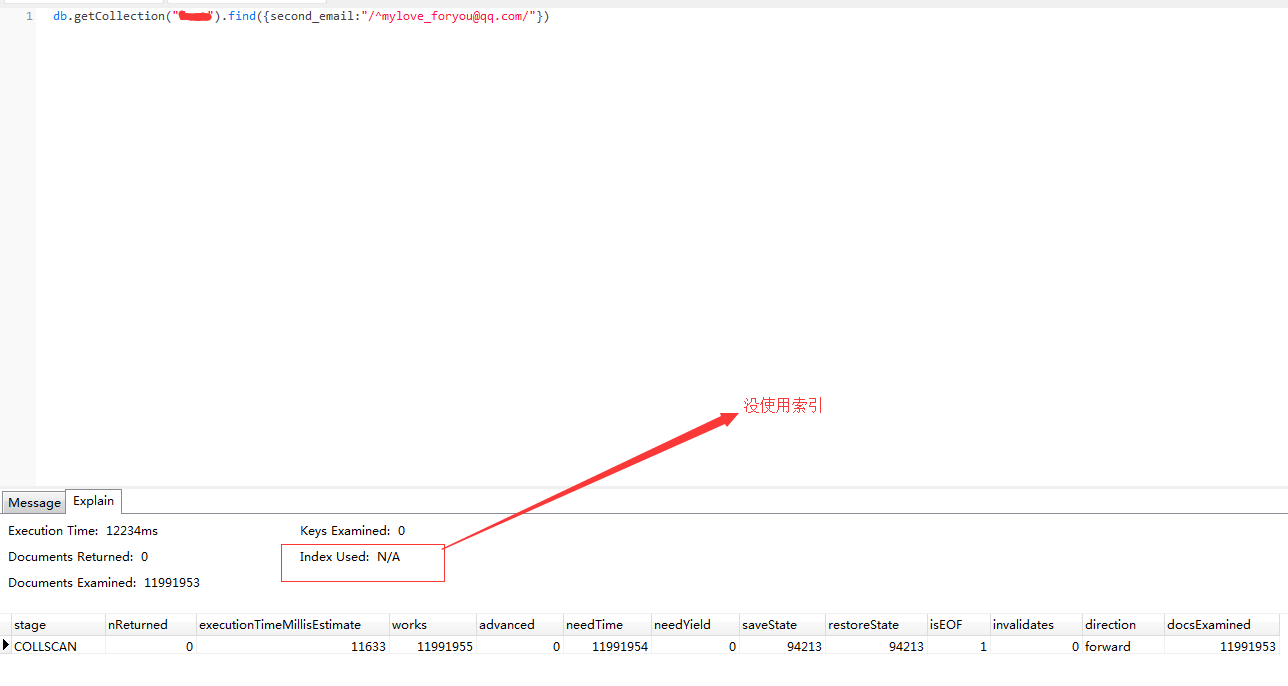
db.getCollection("xxx.aa").find({second_email:"/^mylove_foryou@qq.com/"})
1200万的数据,第一次执行耗时:43.741秒,这在正式环境肯定是不允许的。
通过查询执行计划,发现并没有使用时索引,导致查询的时候很慢。
笔者在mongo3.4/4.0环境下使用以下命令创建索引,
db.getCollection("xxx.com").createIndex({
SECOND_EMAIL: ""
}, {
name: "email1"
})
而是用表结构字段大小写,则会使用索引
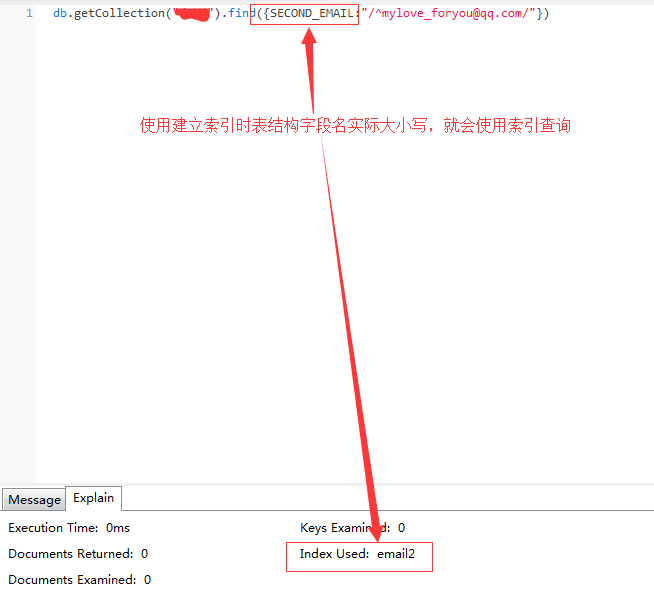
笔者是通过配置文件将原始字段(from属性)映射成xx系统内标准字段(to属性)名称。

由于将来还有很多不确定的表结构进来,也懒得在查询时去维护字段名大小写,
最终想到通过to属性给定的字段名,进行字符串比较,匹配对应集合(collection)中实际字段大小写,翻译成建立索引的字段名。
例如查询时使用realname,而建立索引使用second_email,通过遍历索引,把second_email转译成SECOND_EMAIL,以便使用索引。
于是编写执行以下demo查询索引
mongoTemplate.indexOps(collection).getIndexInfo(); #笔者正式环境不是这么写的,这里方便大家理解,使用语法糖式代码 ;p
每次走到xxx.com表的时候总是报错
Exception in thread "Configuration Initializer" java.lang.NumberFormatException: empty String at sun.misc.FloatingDecimal.readJavaFormatString(FloatingDecimal.java:1842) at sun.misc.FloatingDecimal.parseDouble(FloatingDecimal.java:110) at java.lang.Double.parseDouble(Double.java:538) at java.lang.Double.<init>(Double.java:608) at org.springframework.data.mongodb.core.IndexConverters.lambda$getDocumentIndexInfoConverter$1(IndexConverters.java:147) at org.springframework.data.mongodb.core.DefaultIndexOperations$1.getIndexData(DefaultIndexOperations.java:126) at org.springframework.data.mongodb.core.DefaultIndexOperations$1.doInCollection(DefaultIndexOperations.java:116) at org.springframework.data.mongodb.core.DefaultIndexOperations$1.doInCollection(DefaultIndexOperations.java:110) at org.springframework.data.mongodb.core.DefaultIndexOperations.execute(DefaultIndexOperations.java:141) at org.springframework.data.mongodb.core.DefaultIndexOperations.getIndexInfo(DefaultIndexOperations.java:110) at com.xmd.model.db.MongoDBHelper$1.run(MongoDBHelper.java:97) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
本地是jar版本是托管给maven,笔者本地mongodb配置如下
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-commons</artifactId>
<version>2.0.0.M1</version>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-mongodb</artifactId>
<version>2.0.0.M1</version>
</dependency>
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>bson</artifactId>
<version>3.9.1</version>
</dependency>
如果使用2.0.1版本则不需要那个bson的jar包,最初怀疑是框架bug,想整合新版本(2.13)进去,浪费了好久时间最终没能成功。
又回到了2.0.0.M1,最终硬着头皮调试。
用navicat mongo查看索引,的确是没有排序

后来想到mongo控制台创建索引有1,-1两个值,1是正序 -1是倒序;而笔者创建索引时指定了空字符串,格式化自然就失败了,于是到官方查询文档
db.collection.createIndex(keys, options)
For an ascending index on a field, specify a value of 1; for descending index, specify a value of -1.
问题的症结就是没有建立索引,到这里基本解决问题了,方法如下:
1、删除索引
db.getCollection('xxx.com').dropIndex("mobile_mac")
2、重建索引
db.getCollection("xxx.com").createIndex({
mobile: 1
}, {
name: "mobile_mac"
})
本博客文章绝大多数为原创,少量为转载,代码经过测试验证,如果有疑问直接留言或者私信我。
创作文章不容易,转载文章必须注明文章出处;如果这篇文章对您有帮助,点击右侧打赏,支持一下吧。
创作文章不容易,转载文章必须注明文章出处;如果这篇文章对您有帮助,点击右侧打赏,支持一下吧。
