NLP 概念
序列标注,给定一个序列,找出序列中每个元素对应的标签。
中文分词、词性标注、命名实体识别都可以转化为序列标注问题。
词法分析:中文分词、词性标注、命名实体识别
中文分词:将文本分隔为有意义的词语
词性标注:确定每个词语的类别和浅层的歧义消除
命名实体识别:识别出较长的专有名词(人名、地名、机构名、股票基金、医学术语)
将中文分词和词性标注组合成联合标签,进行序列预测
命名实体识别是在分词和词性标注的结果上,再进行一次复合词的识别(由多个单词构成的复合词)。
信息抽取、文本分类与文本聚类、句法分析(给译文重新排序)、语义分析与篇章分析(消除歧义)
语料库
词语种数:语料库中有多少个不重复的词语
总词频:所有词语的词频之和
词语种数和总词频分别用来衡量语料库用语的丰富程度和规模大小。
N元语法模型
N元语法模型利用前面N-1个单词来预测下一个单词。
单词序列模型是概率模型,概率模型是给单词的符号串指派概率的方法,不论是计算整个句子的概率,还是在一个序列中预测下一个单词的概率,都要使用概率模型。
马尔科夫模型是一种概率模型,假设不必查看很远的过去就可以遇见某个单位的将来概率。在二元语法模型的基础上,我们可以推广到三元语法模型(看过去2个单词),再推广到N元语法模型(看过去N-1个单词)。
将每个汉字组词时所处的位置(首尾等)作为标签,则可以将中文分词转化为给定给定汉字序列找出标签序列的问题,字构词是 序列标注 模型的一种应用。
HMM(Hidden Markov Model) 和 CRF
隐马尔可夫模型 和 条件随机场
马尔可夫假设:每个事件的发生概率只取决于前一个事件。
将满足马尔科夫假设的连续多个事件串联在一起,就构成了马尔可夫链。在NLP语境下,马尔可夫模型可以具象为二元语法模型。
隐马尔可夫模型是描述两个时序序列联合分布的概率模型,外界可见的称为观测序列,外界不可见的称为状态序列。
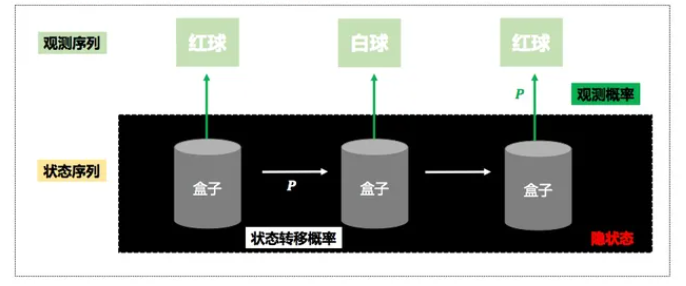
隐马尔可夫链包含状态序列和观测序列,满足两个假设:
1.当前状态仅仅依赖于前一个状态;
2.任意时刻的观测只依赖于该时刻的状态,与其他时刻的状态或观测独立无关。
隐马尔可夫模型,具有三元组(初始状态概率向量、状态转移概率矩阵、发射概率矩阵)
样本生成问题:给定模型三元组,通过构造随机的方式,生成满足模型约束的样本,即生成一系列观测序列及其对应的状态序列
模型训练问题:给定训练集,估计模型三元组。(采用极大似然法进行求解转移概率)(统计训练集上各事件的发生次数,然后利用极大似然估计归一化频次后得到相关概率)
序列预测问题:给定模型三元组和观测序列x,求最可能的状态序列y
条件随机场(CRF)
条件随机场是一种给定输入随机变量x,求解条件概率p(x|y)的概率无向图模型。用于序列标注时,特例化为线性链条件随机场,其输入输出随机变量为等长的两个序列。
信息抽取
信息抽取是从非结构化文本中提取结构化信息的一类技术。(通过基于规则的正则匹配、无监督模型、监督模型)
新词提取:采用信息熵和互信息进行无监督的新词提取。
关键词提取(提取文章中重要的单词):简单实用的无监督关键词提取算法,如单文档算法(词频、TextRank)(单文档算法能够独立分析每篇文章的关键词)、多文档算法(TF-IDF)(多文档算法利用了其他文档中的信息来辅助决定当前文档的关键词,同时容易受到噪声干扰)。
1)词频统计
统计文章中每种词语的词频并排序,取前100个单词。为了排除一些不重要、无意义的词语,在排序前先进行停用词过滤(如标点符号、语气词等)。
流程:分词---->停用词过滤---->按词频取前n个
2) TF-IDF(词频-倒排文档频次)
TF-IDF中 一个词语的重要程度不光正比于它在文档中的频次,还反比于有多少文档包含它。(体现文档的特色)
3) TextRank
TextRank是PageRank(用于排序网页的随机算法)在文本上的应用。
PageRank是计算每个网页的得分,通过外链到该网页的网页权重和上个网页的外置链接数量是计算本网页的得分。得分公式中外链权重和外链总数成反比,与提供外链的网页权重成正比。
TextRank是PageRank中将网页该为单词,每个单词的外链来自单词自身前后固定大小的窗口内的所有单词。
短语提取:从文本中提取中文短语,即固定多字词表达串的识别,多用于搜索引擎的自动推荐、文档的简介生成。
利用互信息和左右信息熵,将新词提取算法扩展到短语提取。(先进行分词,并进行停用词过滤,再将新词提取算法中的字符替换为单词,字符串替换为单词列表)
关键句提取:提取关键句子。
BM25算法用来衡量两个句子之间的相似程度。
通过TextRank算法来提取关键句子,默认所有句子都是相邻的,由于一篇文档中几乎不可能出现相似的句子,因此通过BM25算法来计算相邻句子之间的相似度,以此相似度作为TextRank的链接权重。
文本聚类(无监督学习)
自动发现大量样本之间的相似性,并将其划分为不同的小组。
聚类可用于为用户提供大众化推荐。
文本聚类可分为 特征提取和向量聚类两步。
词袋模型是信息检索与自然语言处理中最常用的文档表示模型,它将文档想象为一个装有词语的袋子,通过袋子中每种词语的计数等统计量将文档表示为向量。
文本分类(监督学习)
文本分类是将一个文档归类到一个或多个类别中的自然语言处理任务。
语法分析
语法分析是分析句子的语法结构并将其表示为容易理解的结构。(如树形结构,短语结构树、依存句法树)
短语结构树是将句子分解为短语,再将短语分解为单词。
依存句法树关注的是句子中词语之间的语法联系,并将其约束为树形结构。输入为词语和词性,输出为依存句法树。
向量余弦用于计算文本相似度


 浙公网安备 33010602011771号
浙公网安备 33010602011771号