RNN/LSTM/GRU
RNN模型:
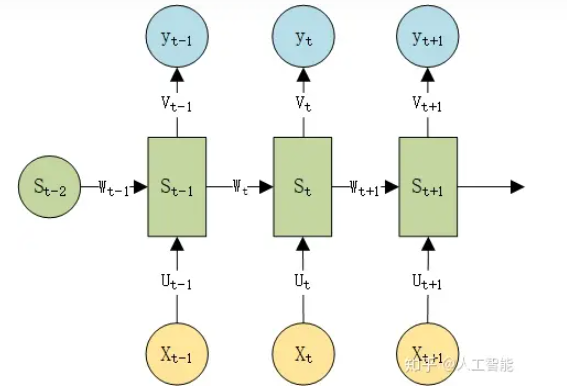


激活函数采用tanh()
LSTM(长短期记忆网络)
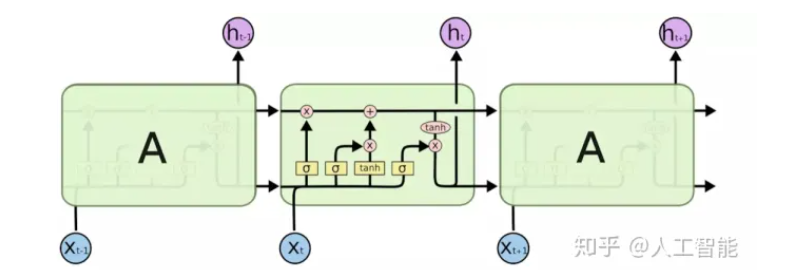
LSTM通过增加三个门,激活函数sigmoid输出0到1之间的数值,0表示不允许通过,1表示允许通过。
通过门来增加前后序列间的关联关系。
输入门、输出门、遗忘门(长记忆、短记忆)
GRU(Gated Recurrent Unit, LSTM变体)
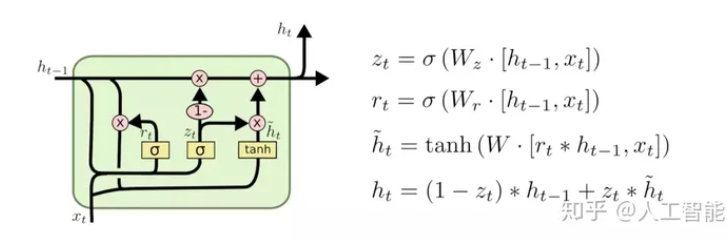
GRU作为LSTM的一种变体,将遗忘门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态,加诸其他一些改动。最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。
为什么CNN用ReLU
Sigmoid的导数范围在[0,0.25]内,如果采用Sigmoid作为激活函数,多个小于1的导数连续相乘容易引起梯度消失。
tanh的导数范围在(0,1]内,虽然导数可以达到1,但是在边缘区域仍然有梯度消失的问题。
ReLU的正半轴不存在梯度消失问题,负半轴的存在可以带来一定的稀疏性,但是也会带来梯度消失问题,可以用LeakyReLU和PReLU等方法缓解。此外,ReLU的计算量远远小于Sigmoid和tanh。
为什么RNN用tanh
在LSTM和GRU中,内部的各种门多采用sigmoid激活函数,因为需要确定“0-1”的各种状态;而隐状态的激活函数多采用tanh。
RNN的每个时间步的权重是相同的,bp过程相当于权重的连续相乘,因此比CNN更容易出现梯度消失和梯度爆炸,因此采用tanh比较多。tanh也会出现梯度消失和梯度爆炸,但是相比于Sigmoid好很多了。理论上ReLU+梯度裁切也可以。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号