序列标注问题
序列标注(Sequence Tagging)是NLP中最基础的任务(输入序列和输出序列长度相等),应用十分广泛,如分词、词性标注(POS tagging)、命名实体识别(Named Entity Recognition,NER)、关键词抽取、语义角色标注(Semantic Role Labeling)、槽位抽取(Slot Filling)等实质上都属于序列标注的范畴。
序列标注问题可以认为是分类问题的一个推广,或者是更复杂的结构预测(structure prediction)问题的简单形式。
序列标注问题的输入是一个观测序列,输出是一个标记序列或状态序列。问题的目标在于学习一个模型,使它能够对观测序列给出标记序列作为预测。
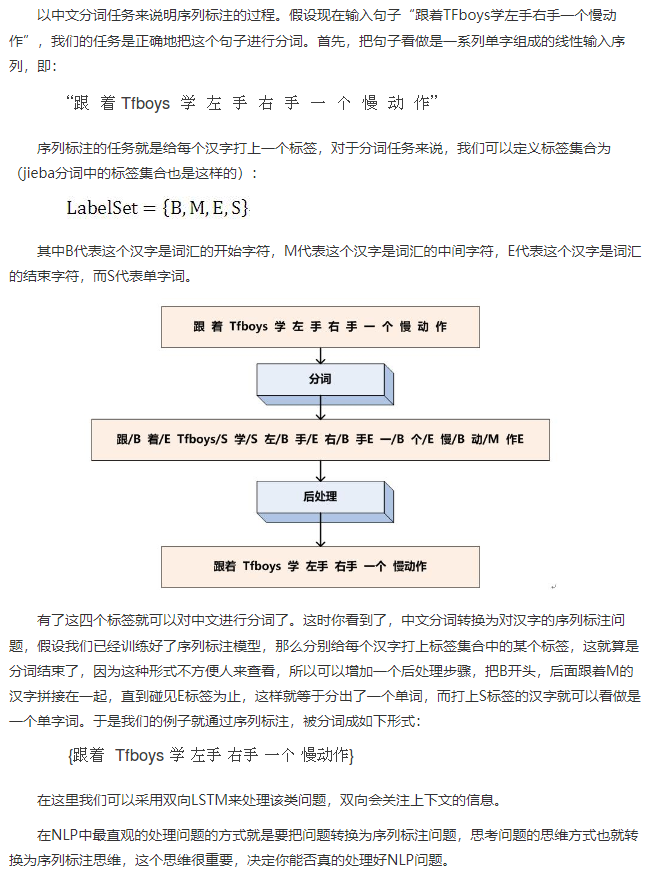
序列标注的前提是构建一个标签集合,通过标签集合给每个字进行标签预测。
在深度学习火起来之前,常见的序列标注问题的解决方案都是借助于HMM模型,最大熵模型,CRF模型。尤其是CRF,是解决序列标注问题的主流方法。随着深度学习的发展,RNN在序列标注问题中取得了巨大的成果。
所谓“序列标注”,就是说对于一个一维线性输入序列:

其本质上是对线性序列中每个元素根据上下文内容进行分类的问题。一般情况下,对于NLP任务来说,线性序列就是输入的文本,往往可以把一个汉字看做线性序列的一个元素,而不同任务其标签集合代表的含义可能不太相同,但是相同的问题都是:如何根据汉字的上下文给汉字打上一个合适的标签(无论是分词,还是词性标注,或者是命名实体识别)
序列标注问题之中文分词
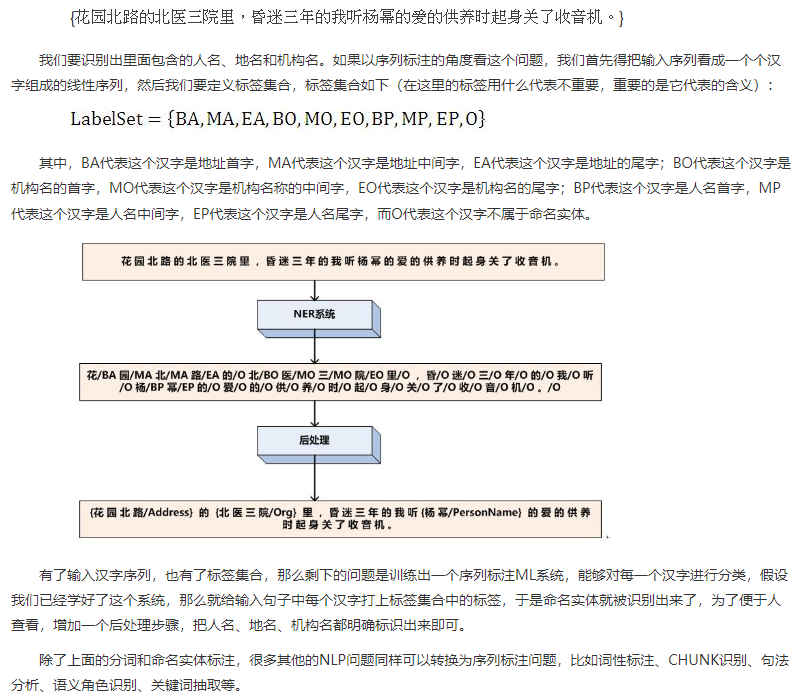
序列标注之命名实体识别(NER)
命名实体识别问题中的序列标注,命名实体识别任务是识别句子中出现的实体,通常识别人名、地名、机构名这三类实体。
假设输入中文句子:
传统解决序列标注问题的方法包括HMM/MaxEnt/CRF等,很明显RNN很快会取代CRF的主流地位,成为解决序列标注问题的标准解决方案,那么如果使用RNN来解决各种NLP基础及应用问题,我们又该如何处理呢,下面我们就归纳一下使用RNN解决序列标注问题的一般优化思路。
对于分词、词性标注(POS)、命名实体识别(NER)这种前后依赖不会太远的问题,可以用RNN或者BiRNN处理就可以了。而对于具有长依赖的问题,可以使用LSTM、RLSTM、GRU等来处理。关于GRU和LSTM两者的性能差不多,不过对于样本数量较少时,有限考虑使用GRU(模型结构较LSTM更简单)。此外神经网络在训练的过程中容易过拟合,可以在训练过程中加入Dropout或者L1/L2正则来避免过拟合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号