seqToseq
Seq2Seq,就是指一般的序列到序列的转换任务,比如机器翻译、自动文摘等等,这种任务的特点是输入序列和输出序列是不对齐的,如果对齐的话,那么我们称之为序列标注,序列标注任务也可以理解为序列到序列的转换。
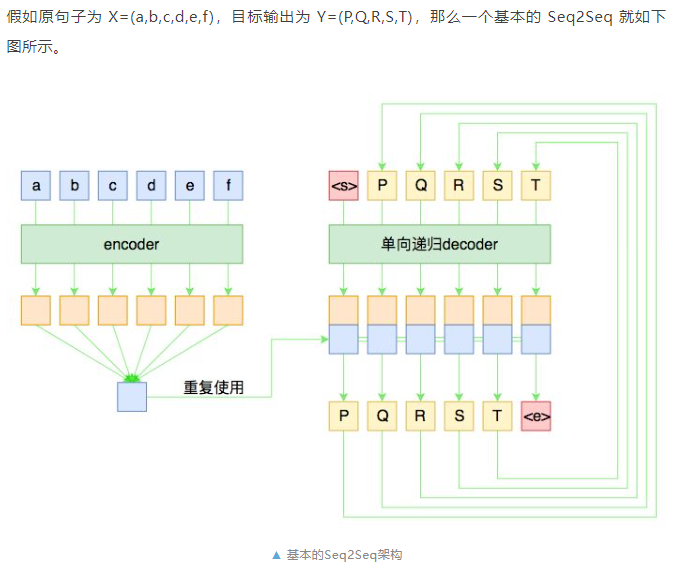
左边是输入的 encoder,它负责把输入(可能是变长的)编码为一个固定大小的向量,这个可选择的模型就很多了,用 GRU、LSTM 等 RNN 结构或者 CNN+Pooling、Google 的纯 Attention 等都可以,这个固定大小的向量,理论上就包含了输入句子的全部信息。
右边是decoder 负责将刚才我们编码出来的向量解码为我们期望的输出。与 encoder 不同,我们在图上强调 decoder 是“单向递归”的,因为解码过程是递归进行的,具体流程为:
1. 所有输出端,都以一个通用的<start>标记开头,以<end>标记结尾,这两个标记也视为一个词/字;
2. 将<start>输入 decoder,然后得到隐藏层向量,将这个向量与 encoder 的输出混合,然后送入一个分类器,分类器的结果应当输出 P;
3. 将 P 输入 decoder,得到新的隐藏层向量,再次与 encoder 的输出混合,送入分类器,分类器应输出 Q;
4. 依此递归,直到分类器的结果输出<end>。
这就是一个基本的 Seq2Seq 模型的解码过程,在解码的过程中,将每步的解码结果送入到下一步中去,直到输出<end>位置。
训练过程:
训练的时候有标注数据对,因此我们能提前预知 decoder 每一步的输入和输出,因此整个结果实际上是“输入 X 和 Y,预测 Y[1:],即将目标 Y 错开一位来训练。
decoder 同样可以用 GRU、LSTM 或 CNN 等结构,但注意再次强调这种“预知未来”的特性仅仅在训练中才有可能,在预测阶段是不存在的,因此 decoder 在执行每一步时,不能提前使用后面步的输入。
所以,如果用 RNN 结构,一般都只使用单向 RNN;如果使用 CNN 或者纯 Attention,那么需要把后面的部分给 mask 掉(对于卷积来说,就是在卷积核上乘上一个 0/1 矩阵,使得卷积只能读取当前位置及其“左边”的输入,对于 Attention 来说也类似,不过是对 query 的序列进行 mask 处理)。
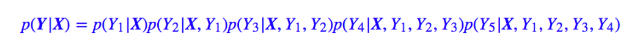
显然在解码时,我们希望能找到最大概率的 Y,那要怎么做呢?

Seq2Seq 模型是标准的,但它把整个输入编码为一个固定大小的向量,然后用这个向量解码,这意味着这个向量理论上能包含原来输入的所有信息,会对 encoder 和 decoder 有更高的要求,尤其在机器翻译等信息不变的任务上。因为这种模型相当于让我们“看了一遍中文后就直接写出对应的英文翻译”那样,要求有强大的记忆能力和解码能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号