词袋模型、word2vec
Bag-of-words模型,BOW模型(词袋模型)假定对于一个文档,忽略它的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,文档中每个词汇的出现都是独立的,不依赖于其它词汇是否出现。也就是说,文档中任意一个位置出现的任何单词,都不受该文档语意影响而独立选择的。
基于词袋模型的文本离散化表示存在着数据稀疏、向量维度过高、字词之间的关系无法度量的问题,适用于浅层的机器学习模型,不适用于深度学习模型。
Word2vec使用大量未注释的纯文本,word2vec自动学习到词汇之间的关系,输出是向量,每个词汇一个向量,具有显着的线性语义关系,由此我们可以做诸如vec(“king”) - vec(“man”)+ vec(“woman”)= ~vec(“queen”)之类的加减运算,或vec(“蒙特利尔加拿大人队”) - vec(“蒙特利尔”)+ vec(“多伦多”)等于“多伦多枫叶队”的向量。
Word2Vec是语言模型中的一种,它是从大量文本预料中以无监督方式学习语义知识的模型,是用来生成词向量的工具。
word2vec通常是一种进行文本的向量提取的技术,利用单词的共现(共同出现,后续会有详细记录)思想,通过对文本语料库进行训练,得到的每个单词的向量,在应用的过程中,就可以通过单词向量来计算单词的相似性,或者说是共现概率。概率大表示单词之间比较相似。
Word2vec 是 Word Embedding 方式(Word Embedding 的模型本身并不重要,重要的是生成出来的结果——词向量。)之一,属于 NLP 领域。他是将词转化为「可计算」「结构化」的向量的过程。


词的向量化表达有两种形式:
One-Hot Representation:One-Hot编码,向量的长度为词典的大小,向量中只有一个 1 , 其他全为 0 ,1 的位置对应该词在词典中的位置。
Distributed Representation:通过训练将某种语言中的每一个词 映射成一个固定长度的短向量(当然这里的“短”是相对于One-Hot Representation的“长”而言的),所有这些向量构成一个词向量空间,而每一个向量则可视为 该空间中的一个点,在这个空间上引入“距离”,就可以根据词之间的距离来判断它们之间的语法、语义上的相似性了。Word2Vec中采用的就是这种Distributed Representation 的词向量。
Word2Vec原理:
Word2Vec是轻量级的神经网络,其模型仅仅包括输入层、隐藏层和输出层,模型框架根据输入输出的不同,主要包括CBOW和Skip-gram模型。 CBOW的方式是在知道词的上下文的情况下预测当前词。而Skip-gram是在知道了词的情况下,对词进行预测,如下图所示:
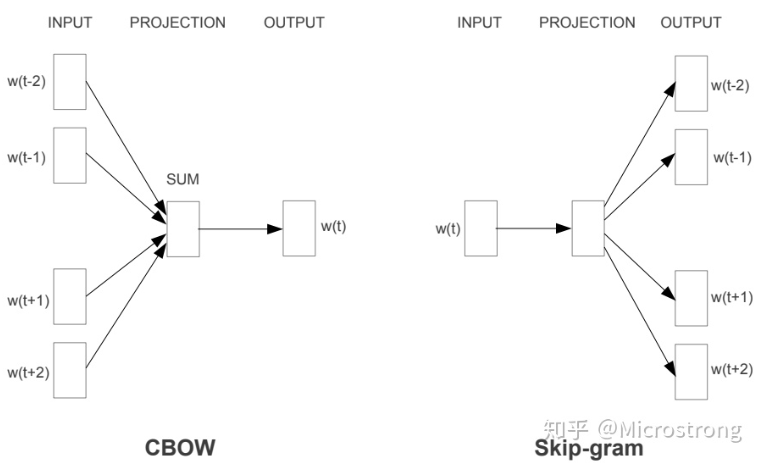

word2rec利用词的共性,通过滑动窗口自动生成正负样本,来实现无监督学习。
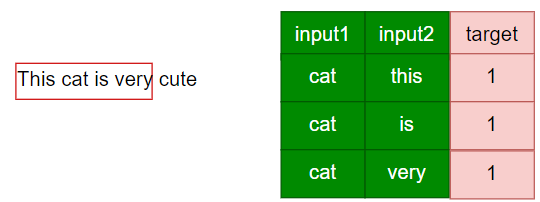
正样本是出现在滑窗中的所有词和中心词的组合,比如 cat cute就是负样本,label应该为1。
负样本就是以某个词为中心词时,未出现在滑窗中的所有词和中心词的组合,label应该为0。
负样本太多
问题描述:
当以cat为中心词时,thiscat is very 是滑窗内的正样本,但是如果此时语料库中有10w个单词,那除了the和is之外,其他的单词和cat的组合全部都为负样本,你想这才只是仅以cat为中心词时的负样本就这么多,全部滑窗循环下来,负样本将无比巨大。
解决办法:
既然负样本太多,最直观的减少负样本的解决方法不就是少取一点嘛,这里提出的一个负采样,其实就是抽样的取负样本,不全部取,而是取部分,这很好理解。至于到底取多少呢?通常是正负样本按照1:10的比例来取,也就是取正样本的10倍左右的量。
softmax计算量太大
问题描述:
在最开始的skip-gram的原理介绍中,每进行一次单词的共现预测时,都会涉及到一个问题:就是softmax计算, 可以回顾一下softmax的公式,你会发现每进行一次softmax计算,我们的分母上都要对全部单词的预测输出值进行计算,然后加和,显然这样的复杂度是n。虽然我们在word2vec中将softmax的多分类问题改为了共现的二分类问题。但是可以理解为计算的复杂程度依旧是一样的。那这个问题会有什么后果呢?
问题后果:
每一次要对某一个单词做预测时,都要对全量的单词的概率做计算,其实这是一个很复杂的事情,效率会极低。
问题解决:
这里引入了霍夫曼树的原理,首先要知道霍夫曼树的原理是什么,霍夫曼树的原理就是,将权重越大的节点,越靠近根节点。
根据每个单词出现的频率进行霍夫曼编码,首先会统计整个语料库中单词出现的次数,然后依据单词出现的次数进行霍夫曼编码(也就是将刚刚距离中的那些数字替换为具体单词出现的次数),将出现次数比较多的单词优先放到根节点附近,最终所有单词都会落到叶子节点上。
将cat和is送入到模型时,如果is是在全文出现最多,那么我们在哈夫曼树中马上就会找到is,那么他的概率马上就会计算出来,所以全文中和is搭配的所有样本的概率的求解速度会非常快,求得概率之后,然后与target=1做loss,反向梯度更新权重。就完成一次训练了,这就是优化的本质。
word2vec执行流程
下面通过举例cat来预测this的整体流程(由于原先画图的原件找不到,无法更改,下图的the就是this)
训练阶段:
1.将两个单词one-hot;
2.在矩阵A中找到cat单词和this对应的embedding向量(你也可以不在同一个矩阵中取向量)
3.将两个向量相乘得到预测概率;
4.将概率值保存到与this对应的边上;
那么在不断的训练中更新的就是这个边的权重;
预测的阶段:
1.将两个单词one-hot;
2.在矩阵A中找到两个单词的对应的embedding向量;
3.找到到this的边的权重,这个就是概率;
在中文文本数据里常常会涉及一些外文词汇,尤其是科技领域包含有大量的英文词汇,这时就需要对英文文本数据进行规范化处理了,主要是小写化、词干提取和词形还原。
小写化:lower()就可以转换
词干提取:Porter Stemming算法进行词干分析
词形还原:WordNet词法数据库进行词式化(词形还原就是去掉单词的词缀,提取单词的主干部分,通常提取后的词汇会是字典中的单词,不同于词干提取(stemming),提取后的单词不一定会出现在词汇中。)
Word2Vec接受几个影响训练速度和质量的参数,理解它们的大致原理对于训练出一个符合业务需要的Word2Vec模型是至关重要的。
word2Vec输入是词汇,输出是词向量
min_count:用于修剪内部字典(Prune the Internal Dictionary),设置记录词汇出现的最低次数,默认值为5
size:是gensim Word2Vec将词汇映射到的N维空间的维度数量(N),默认size是100,较大的size值需要更多的训练数据,但可以产生更好(更准确)的模型。 合理的size数值介于在几十到几百之间。 如果你拥有的数据较少,那就把维度值设置小一点,这将在一定程度上减少模型的过拟合,尽量提高模型的表现效果。
workers:workers是一个用于训练并行化的参数,可以加快训练速度,默认值3
iter:是模型训练时在整个训练语料库上的迭代次数,假如参与训练的文本量较少,就需要把这个参数调大一些。
sg:是模型训练所采用的的算法类型,默认值为0
1 代表 skip-gram,该模型从上下文语境(context)对目标词汇(target word)的预测中学习到其词向量的表达
0 代表 CBOW,该模型从目标词汇(target word)对上下文语境(context)的预测中学习到其词向量的表达
window:控制窗口,它指当前词和预测词之间的最大距离,默认值为5,如果设得较小,那么模型学习到的是词汇间的组合性关系(词性相异),比如“苹果”和“好红”,“主席”和“伟大”,后者对前者是一种修饰关系;如果设置得较大,会学习到词汇之间的聚合性关系(词性相同),比如“伟大”和“注明”、“可爱”和“卡哇伊”。
假如语料够多,笔者一般会设置得大一些,8~10,因为词汇间的聚合关系能很好的捕捉到词汇之间的相似性关系,能很好的解决词袋表示中多词一义的问题,发现词汇/语句之间的潜在语义相关性。
model = gensim.models.Word2Vec( sentences, size = 50, sg=1, min_count= 3, window = 8, iter = 20 )
Word2Vec有一种更为高级的用法,即在线训练,也就是说,当有了新的数据,就可以直接在原来已经训练好的模型上接着训练,而不用从头再来,后续可以不断加入新的语句(经过文本预处理)来提升模型的表现效果。
model.build_vocab(more_sentences, update=True) #注意该方法中的参数update,默认为False,增量更新模型时,需要设置为True model.train(more_sentences, total_examples=model.corpus_count, epochs=model.epochs)
文本先用jieba进行分词,再对词进行规范化处理,再用word2rec进行词向量转化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号