端侧部署 pytorch mobile、TensorFlow Lite、
PyTorch Mobile网站介绍,处在Beta阶段,待API稳定之后,很快会推出稳定版。Feature包括:
- 为ios,Android,Linux提供支持;
- 提供API,涵盖将 ML 集成到移动应用中所需的常见预处理和集成任务;
- 通过TorchScript IR支持tracing与scripting;
- 支持 XNNPACK为ARM CPU上执行浮点运算;
- 集成QNNPACK 支持INT8量化内核库,可支持per-channel量化、动态量化以及其他方式;
- 根据用户的应用需求进行构建级别的优化和选择性编译,也就是根据应用如用的模型里的算子可定制选择算子从而改变最终编译出目标程序的尺寸;
- GPU/DSP/NPU等backends会在后续支持。
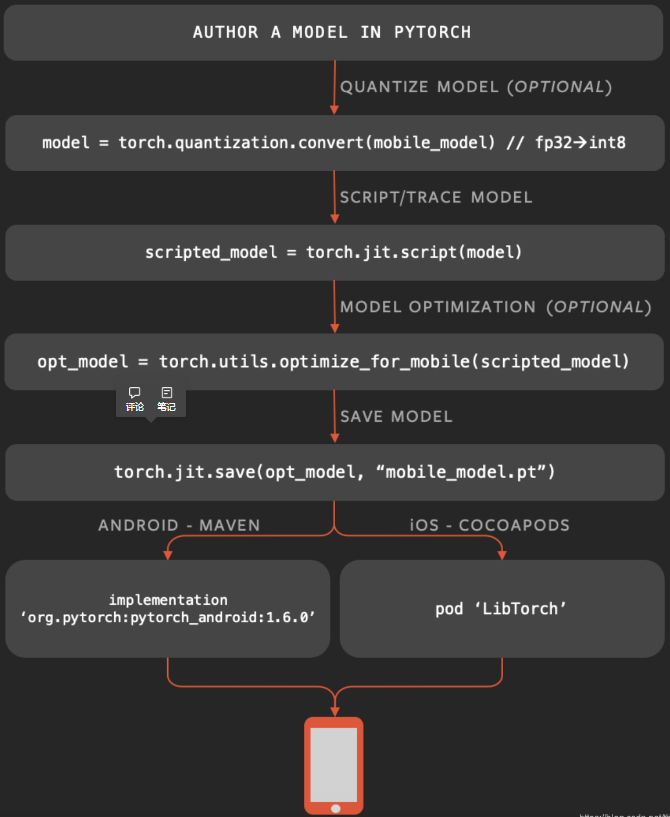
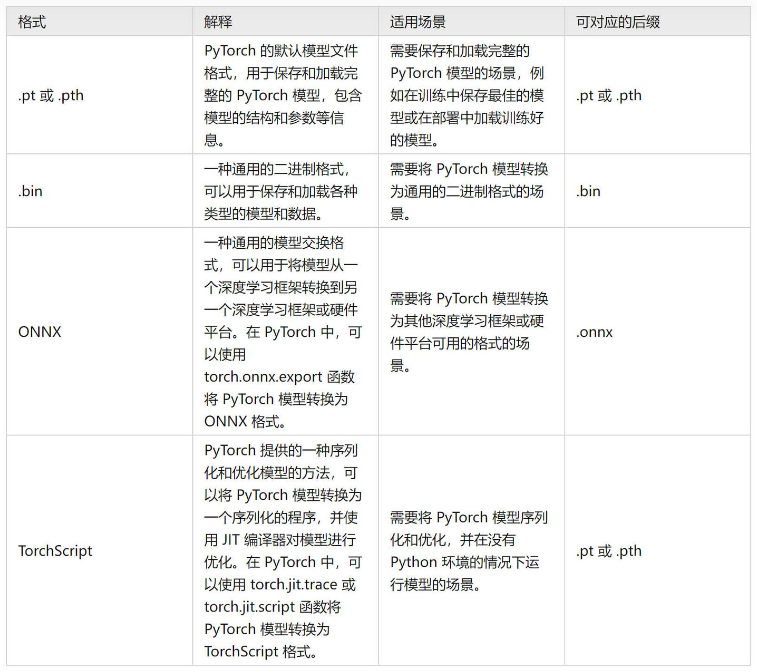
- 把训练出的模型进行量化(可选)
- 模型转换:pt(TorchScript)
- 优化(可选)
- 保存
- 部署到终端上执行
只是,上述1~4步骤中在Host上完成;步骤5在手机或别的端侧设备上部署。别的方案把这些都明白的交代清楚了而已。
import torch from torch.utils.mobile_optimizer import optimize_for_mobile # 加载训练好的模型 model = torch.hub.load('pytorch/vision:v0.9.0', 'deeplabv3_resnet50', pretrained=True) # 设置为推理模式 model.eval() # 将训练好的模型转换为jit脚本模型 scripted_module = torch.jit.script(model) # 优化jit脚本模型,提高在移动设备上的推理性能 optimized_scripted_module = optimize_for_mobile(scripted_module) # 导出完整的jit版本模型(不兼容轻量化解释器) scripted_module.save("deeplabv3_scripted.pt") # 导出轻量化解释器版本模型(与轻量化解释器兼容) scripted_module._save_for_lite_interpreter("deeplabv3_scripted.ptl") # 使用优化的轻量化解释器模型比未优化的轻量化解释器模型推理速度快60%左右,比未优化的jit脚本模型推理速度快6%左右 optimized_scripted_module._save_for_lite_interpreter("deeplabv3_scripted_optimized.ptl")
安卓端通过java来调用模型ptl
mModule = LiteModuleLoader.load(MainActivity.assetFilePath(getApplicationContext(), "monodepth_scripted_optimized.ptl"));