集成学习(Bagging、Boosting、Stacking)
https://blog.csdn.net/weixin_43776305/article/details/116895875
集成学习
集成学习有两个主要的问题需要解决,第一是如何得到若干个个体学习器,第二是如何选择一种结合策略,将这些个体学习器集合成一个强学习器。
集成算法会考虑多个评估器的建模结果,汇总之后得到一个综合结果,以此来获取比单个模型更好的回归或分类表现。
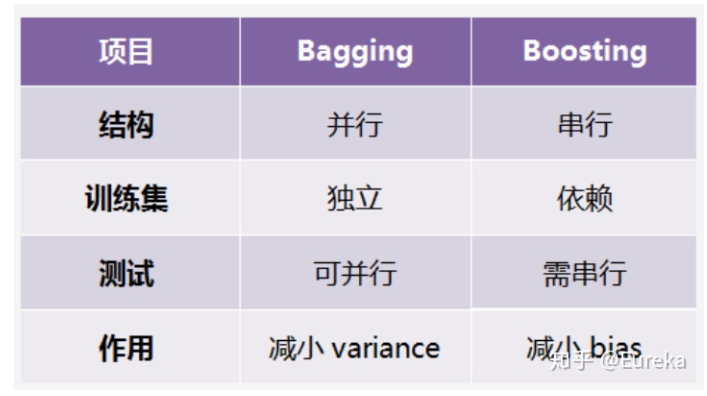
多个模型集成后的模型叫做集成评估器,集成评估器中的每一个模型叫做基评估器,通常来说有三类集成算法:Bagging、Boosting、Stacking
Boosting算法
Boosting算法的工作机制是首先从训练集用初始权重训练出一个弱学习器1,根据弱学习的学习误差率表现来更新训练样本的权重,使得之前弱学习器1学习误差率高的训练样本点的权重变高,使得这些误差率高的点在后面的弱学习器2中得到更多的重视。然后基于调整权重后的训练集来训练弱学习器2.,如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器。
Boosting系列算法里最著名算法主要有AdaBoost算法和提升树(boosting tree)系列算法。提升树系列算法里面应用最广泛的是梯度提升树(Gradient Boosting Tree)。
bagging算法
Bagging的算法原理和 boosting不同,它的弱学习器之间没有依赖关系,可以并行生成。bagging的个体弱学习器的训练集是通过随机采样得到的。通过3次的随机采样,我们就可以得到3个采样集,对于这3个采样集,我们可以分别独立的训练出3个弱学习器,再对这3个弱学习器通过集合策略来得到最终的强学习器。
随机森林是Bagging的代表模型, 他所有的基评估器都是决策树。Bagging法中每一个基评估器是平行的,最后的结果采用平均值或者少数服从多数的原则。
variance(方差) 和 bias(偏差)在模型中的作用可参考:https://www.cnblogs.com/pass-ion/p/17449101.html
Stacking算法
Bagging算法是对弱学习器的结果做平均或者投票,相对比较简单,但是可能学习误差较大,于是就有了学习法这种方法,对于学习法,代表方法是stacking,当使用stacking的结合策略时, 不是对弱学习器的结果做简单的逻辑处理,而是再加上一层学习器,也就是说,将训练集弱学习器的学习结果作为输入,将训练集的输出作为输出,重新训练一个学习器来得到最终结果。
在这种情况下,将弱学习器称为初级学习器,将用于结合的学习器称为次级学习器。对于测试集,我们首先用初级学习器预测一次,得到次级学习器的输入样本,再用次级学习器预测一次,得到最终的预测结果。
Stacking 就像是 Bagging的升级版,Bagging中的融合各个基础分类器是相同权重,而Stacking中则不同,Stacking中第二层学习的过程就是为了寻找合适的权重或者合适的组合方式。
随机森林在sklearn中ensemble模块下
from sklearn.ensemble import RandomForestClassifier from sklearn.datasets import make_classification X, y = make_classification(n_samples=1000, n_features=4, n_informative=2, n_redundant=0, random_state=0, shuffle=False) clf = RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0) clf.fit(X, y) #生成的随机森林具体的参数 #RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini', max_depth=2, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, in_samples_split=2,min_weight_fraction_leaf=0.0,
n_estimators=100, n_jobs=None,oob_score=False, random_state=0, verbose=0, warm_start=False) print(clf.feature_importances_) out:[0.14205973 0.76664038 0.0282433 0.06305659] print(clf.predict([[0, 0, 0, 0]])) out:[1]
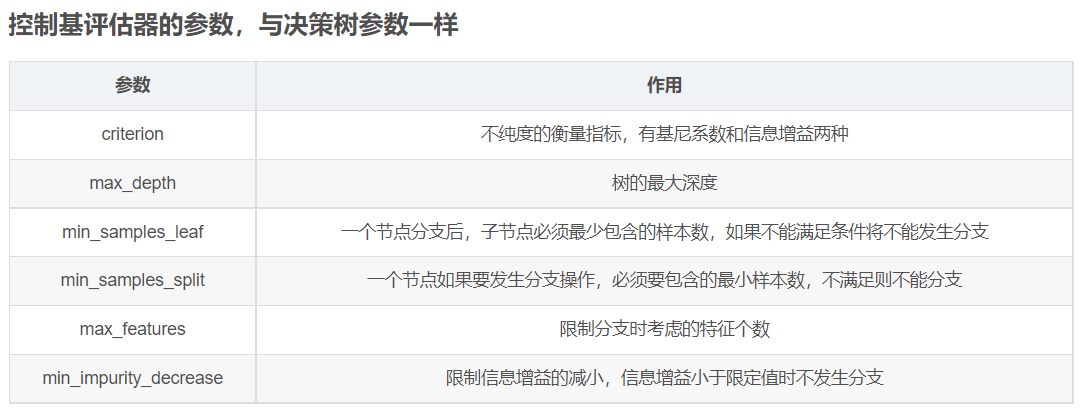
随机森林模型参数
n_estimators: 推荐0-200之间的数值
这是森林中树木的数量,即基评估器的数量。这个参数对随机森林模型的精确性影响是单调的,n_estimators越大,模型的效果往往越好。但是相应的,任何模型都有决策边界,n_estimators达到一定的程度之后,随机森林的精确性往往不在上升或开始波动,并且,n_estimators越大,需要的计算量和内存也越大,训练的时间也会越来越长。对于这个参数,我们是渴望在训练难度和模型效果之间取得平衡。
random_state: 控制生成随机森林的模式。并不能控制森林中的树的样式。随机性越大,模型效果越好,当然这样可能就不是很稳定,不便于调试。想要模型稳定,可以设置random_state参数
bootstrap: 控制抽样技术的参数,默认为True。采用有放回的随机抽样数据来形成训练数据。
对我们传入随机森林模型的数据集,对每一个基评估器采用有放回的随机抽样从原始数据集中抽取n个样本来组成自助集,并将自助集作为基评估器的训练数据。这样的作法大大增加了随机性,提高了模型的效果。
由于有放回,所以有一些样本可能在某些自助集中出现多次,而其他的一些样本可能被忽略。一般来说,自助集一般会包含63%的原始数据。那些被浪费掉的数据被称为袋外数据(out of bag data 简称oob)。除了我们最开始就划分好训练测试集外,这些被忽略的数据也可以用来作为测试集,也就是说在使用随机森林模型的时候可以不用划分数据集,只需要用袋外数据来测试我们的模型即可。当样本数量,和随机森林中树的数量不大的情况下,可能没有数据在袋外,也就不能用oob来测试模型了。
oob_score:默认为False,True表示用袋外数据来测试模型。可以通过oob_score_来查看模型的准取度。
随机森林函数的参数以及方法
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None, min_impurity_split=1e-07, bootstrap=True, oob_score=False, n_jobs=1, random_state=None, verbose=0, warm_start=False, class_weight=None)
参数
- n_estimators : integer, optional (default=10)
随机森林中树的数量; - criterion : string, optional (default=”gini”)
树分裂的规则:gini系数,entropy熵; - max_features : int, float, string or None, optional (default=”auto”)
查找最佳分裂所需考虑的特征数,
int:分裂的最大特征数,
float:分裂的特征占比,
auto、sqrt:sqrt(n_features),
log2:log2(n_features),
None:n_features, - max_depth : integer or None, optional (default=None)
树的最大深度; - min_samples_split:int, float, optional (default=2)
最小分裂样本数; - min_samples_leaf : int, float, optional (default=1)
最小叶子节点样本数; - min_weight_fraction_leaf : float, optional (default=0.)
最小叶子节点权重; - max_leaf_nodes : int or None, optional (default=None)
最大叶子节点数; - min_impurity_split : float, optional (default=1e-7)
分裂的最小不纯度; - bootstrap : boolean, optional (default=True)
是否使用bootstrap; - oob_score : bool (default=False)
是否使用袋外(out-of-bag)样本估计准确度; - n_jobs : integer, optional (default=1)
并行job数,-1 代表全部; - random_state : int, RandomState instance or None, optional (default=None)
随机数种子; - verbose : int, optional (default=0)
Controls the verbosity of the tree building process.(控制树冗余?) - warm_start : bool, optional (default=False)
如果设置为True,在之前的模型基础上预测并添加模型,否则,建立一个全新的森林; - class_weight : dict, list of dicts, “balanced”,
“balanced” 模式自动调整权重,每类的权重为 n_samples / (n_classes * np.bincount(y)),即类别数的倒数除以每类样本数的占比。
属性
- estimators_ : list of DecisionTreeClassifier
森林中的树; - classes_ : array of shape = [n_classes] or a list of such arrays
类标签; - n_classes_ : int or list
类; - n_features_ : int
特征数; - n_outputs_ : int
输出数; - feature_importances_ : array of shape = [n_features]
特征重要性; - oob_score_ : float
使用袋外样本估计的准确率; - oob_decision_function_ : array of shape = [n_samples, n_classes]
决策函数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号