pytorch TensorDataset和DataLoader区别
TensorDataset
TensorDataset可以用来对 tensor 进行打包,就好像 python 中的 zip 功能。该类通过每一个 tensor 的第一个维度进行索引。因此,该类中的 tensor 第一维度必须相等. 另外:TensorDataset 中的参数必须是 tensor
import torch
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
a = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9], [1, 2, 3], [4, 5, 6], [7, 8, 9], [1, 2, 3], [4, 5, 6], [7, 8, 9], [1, 2, 3], [4, 5, 6], [7, 8, 9]])
b = torch.tensor([44, 55, 66, 44, 55, 66, 44, 55, 66, 44, 55, 66])
train_ids = TensorDataset(a, b)
# 切片输出
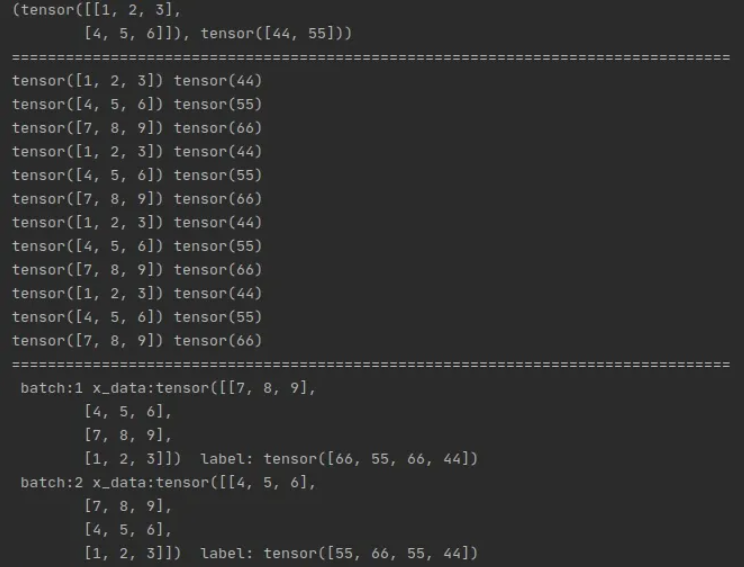
print(train_ids[0:2])
print('=' * 80)
# 循环取数据
for x_train, y_label in train_ids:
print(x_train, y_label)
# DataLoader进行数据封装
print('=' * 80)
train_loader = DataLoader(dataset=train_ids, batch_size=4, shuffle=True)
for i, data in enumerate(train_loader, 1): # 注意enumerate返回值有两个,一个是序号,一个是数据(包含训练数据和标签)
x_data, label = data
print(' batch:{0} x_data:{1} label: {2}'.format(i, x_data, label))
输出结果:
DataLoader
DataLoader就是用来包装所使用的数据,每次抛出一批数据,作为迭代器使用
import torch
import torch.utils.data as Data
BATCH_SIZE = 5
# linspace, 生成1到10的10个数构成的等差数列
x = torch.linspace(1, 10, 10)
y = torch.linspace(10, 1, 10)
# 把数据放在数据库中
torch_dataset = Data.TensorDataset(x, y)
# 从数据库中每次抽出batch size个样本
loader = Data.DataLoader(dataset=torch_dataset,
batch_size=BATCH_SIZE, # x, y 是相差为1个数为10的等差数列, batch= 5, 遍历loader就只有两个数据
shuffle=False, # 不打乱顺序,便于查看
num_workers=0)
def show_batch():
for step, (batch_x, batch_y) in enumerate(loader):
# training
print("steop:{}, batch_x:{}, batch_y:{}".format(step, batch_x, batch_y)) #方便输出
if __name__ == '__main__':
show_batch()
输出结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号