pytorch 基础函数
1. 二维卷积
tensor(B,C,H,W)
B - batchsize,例如你在使用dataloder的时候设置的batchsize是64那么此项则为64
C - channel,也就是输入的矩阵的通道数,若你输入的是RGB图片,那么此项为3
H - high,也就是你输入矩阵的高。
W - width,也就是你输入矩阵的宽

2.一维卷积
tensor(B,H,W)
B - batchsize,例如你在使用dataloder的时候设置的batchsize是64那么此项则为64
H-为句子最大长度
W-为词向量

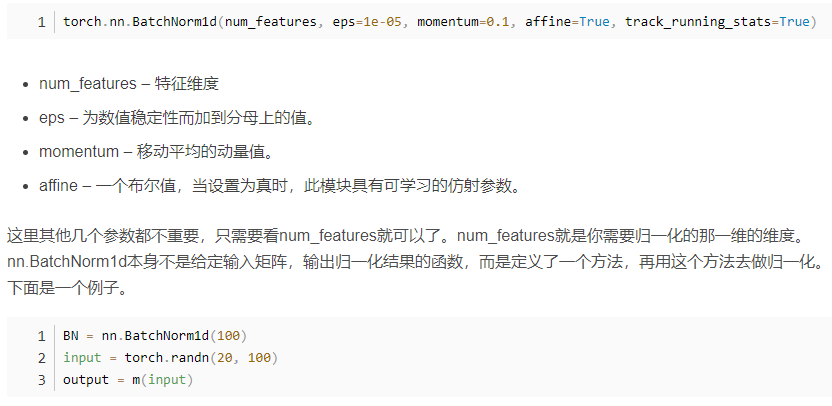
3. BatchNorm1d
一维标准化
4. convTransposed1d
一维转置卷积(进行上采样操作,用于恢复分辨率)(普通卷积都是下采样操作)

5. nn.MaxUnpool1d(kernel_size, stride=None, padding=0)
反最大值池化,从最大值池化后的数据进行恢复

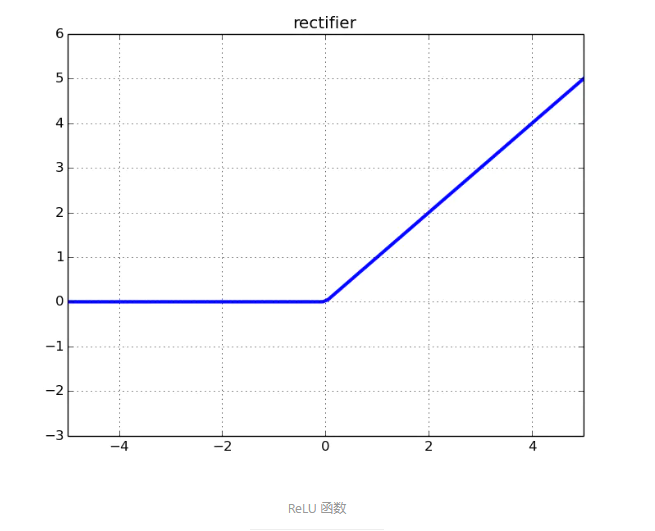
6. nn.ReLU()
激活函数,小于0的都被截为0
7. nn.BatchNorm2d() 批量归一化
机器学习中,进行模型训练之前,需对数据做归一化处理,使其分布一致。在深度神经网络训练过程中,通常一次训练是一个batch,而非全体数据。每个batch具有不同的分布产生了internal covarivate shift问题——在训练过程中,数据分布会发生变化,对下一层网络的学习带来困难。Batch Normalization强行将数据拉回到均值为0,方差为1的正太分布上,一方面使得数据分布一致,另一方面避免梯度消失
8. dropout()
设置 Dropout 时,torch.nn.Dropout(0.5), 这里的 0.5 是指该层(layer)的神经元在每次迭代训练时会随机有 50% 的可能性被丢弃(失活),不参与训练,一般多神经元的 layer 设置随机失活的可能性比神经元少的高
减低过拟合,一般可以通过:加大训练集、loss function 加入正则化项、Dropout 等途径
9. torch.flatten()
1)flatten(x,1)是按照x的第1个维度拼接(按照列来拼接,横向拼接);
2)flatten(x,0)是按照x的第0个维度拼接(按照行来拼接,纵向拼接);
3)有时候会遇到flatten里面有两个维度参数,flatten(x, start_dim, end_dimension),此时flatten函数执行的功能是将从start_dim到end_dim之间的所有维度值乘起来,其他的维度保持不变。例如x是一个size为[4,5,6]的tensor, flatten(x, 0, 1)的结果是一个size为[20,6]的tensor。
10 torch.cat()
按维数0拼接(竖着拼)
C = torch.cat( (A,B),0 )
按维数1拼接(横着拼)
C = torch.cat( (A,B),1 )
11. nn.Sequential()
一个有序的容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,同时以神经网络模块为元素的有序字典也可以作为传入参数。
12. nn.AdaptiveAvgPool2d(output_size)
作用:
自适应平均池化,指定输出(H,W)
13. nn.Linear()
作为全连接层(fc),可固定输出通道数。
[batch_size, out_features]
14. nn.softmax()
按照行或者列来做归一化的
nn.log_softmax():
在softmax的结果上再做多一次log运算\
Conv、BN、Relu 三个层融合为了一个层,即CBR融合
15. model.train() model.eval()区别
这两个方法是针对在网络训练和测试时采用不同方式的情况,比如Batch Normalization 和 Dropout。
model.train() :启用 BatchNormalization 和 Dropout。 在模型测试阶段使用model.train() 让model变成训练模式,此时 dropout和batch normalization的操作可以在训练起到防止网络过拟合的问题。
model.eval() :不启用 BatchNormalization 和 Dropout。此时pytorch会自动把BN和DropOut固定住,不会取平均,而是用训练好的值。不然的话,一旦test的batch_size过小,很容易就会因BN层导致模型performance损失较大;
16. torch.no_grad() 作用
torch.no_grad() 负责关掉梯度计算,节省eval的时间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号