elasticSearch入门-ES入门
1. ES简介
Elasticsearch 是由Apache开源的一个兼有搜索引擎和NoSQL数据库功能的系统,其特点主要如下。
l 基于Java/Lucene构建,支持全文搜索、结构化搜索
l 低延迟,支持实时搜索
l 分布式部署,可横向集群扩展
l 支持百万级数据
l 支持多条件复杂查询,如聚合查询
l 高可用性,数据可以进行切片备份
l 支持Restful风格的api调用
2. ES应用场景
ES作为全文检索的搜索引擎,在以下几个方面都存在着相应的应用:
l 监控。针对日志类数据进行存储、分析、可视化。针对日志数据,ES给出了ELK的解决方案。其中logstash采集日志,ES进行复杂的数据分析,kibana进行可视化展示。
l 电商网站。用于商品信息检索。
l Json文档数据库。用于存放json格式的文档
l 维基百科。提供全文搜索并高亮关键字
3. ES核心概念
下面分别介绍ES中的核心概念词:
l 集群(Cluster): 包含一个或多个具有相同 cluster.name 的节点.
l 节点(node): 是一个逻辑上独立的服务,可以存储数据,并参与集群的索引和搜索功能, 每个节点都有其唯一的名字,集群通过节点名称进行管理和通信。节点可以充当一个或多个角色。ES集群中的每个节点都会存储集群状态,知道索引内各分片所在的节点位置。
l 主节点(master node):主要负责集群方面的操作,比如节点的加入和退出、索引的创建和删除、分片被分配到哪个节点、节点状态监测。
l 数据节点(Data Node):存储文档数据的节点,执行文档数据的查询和写入等操作。
l 协调节点(Coordinate Node):客户端请求可以发送到集群的任何节点,集群中的每个节点都知道所有文档的位置。接收到客户端请求的节点自动变为协调节点,进行请求的转发,并整合数据返回给客户端。比如创建索引的请求,就转发到主节点。
l 映射(Mapping): mapping是对索引库中的索引字段及其数据类型进行定义,类似于关系型数据库中的表结构。ES默认动态创建索引和索引类型的mapping,这就像是关系型数据库中无需定义表结构,更不用指定字段的数据类型。也可以手动指定mapping类型。mapping机制可以自动检测数据的结构和类型,创建索引并使数据可搜索。
l 分片(shard):索引数据量很大,超过硬件存放单个文件的限制,就会影响查询请求的速度,Es引入了分片技术。一个分片本身就是一个完成的搜索引擎,文档存储在分片中,而分片会被分配到集群中的各个节点中,随着集群的扩大和缩小,ES会自动的将分片在节点之间进行迁移,以保证集群能保持平衡。一个索引中含有shard的数量,默认值为5,在索引创建后这个值是不能被更改的。
l 副本(replica):切片(shard)的冗余备份,每个切片默认的副本数为1。副本数可以随时进行调整。
l 索引(Index): 索引与关系型数据库实例(Database)相当。索引只是一个逻辑命名空间。ES可以把索引数据存放到服务器中,也可以sharding(分片)后存储到多台服务器上。每个索引有一个或多个分片,每个分片可以有多个副本。
l 文档类型(Type):相当于数据库中的table概念。每个文档在ElasticSearch中都必须设定它的类型。文档类型使得同一个索引中在存储结构不同文档时,只需要依据文档类型就可以找到对应的参数映射(Mapping)信息,方便文档的存取
l 文档(Document) :相当于数据库中的row, 是可以被索引的基本单位。其可以理解为关系型数据库中表的一行数据记录。每个文档由多个字段(field)组成,区别于关系型数据库的是,ES是一个非结构化的数据库,每个文档可以有不同的字段,并且有一个唯一标识。
ES和关系型数据库概念对比如下:
|
ES |
关系型数据库 |
|
索引(Index) |
数据库(DataBase) |
|
类型(Type) |
表(Table) |
|
映射(mapping) |
表结构(Schema) |
|
文档(Document) |
行(Row) |
|
字段(Field) |
列(Column) |
|
反向索引 |
正向索引 |
|
DSL查询 |
SQL查询 |
l Segment:段,Lucence中存储是按段来进行存储,每个段相当于一个数据集。
l Commit Point:提交点,记录着Lucence中所有段的集合。
l Lucene Index:Lucene索引,由一堆Segment段集合和commit point组成。
l Lucene:Apache开源的全文检索开发工具包,通俗理解是一个java的jar包。
4. ES架构
4.1整体架构
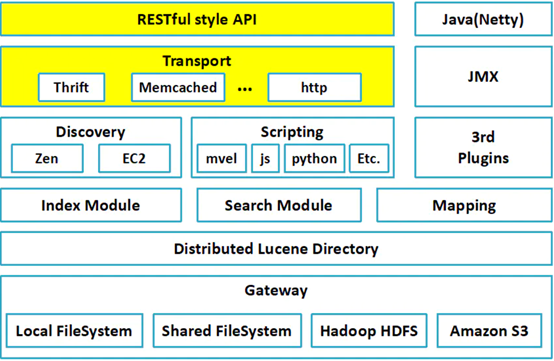
ES整体架构图
下面将由下到上的对ES整体架构图中的各个部分进行介绍:
- 最底层的Gateway部分是ES的数据持久化,ES中的数据可以存储在本地,也可以通过分片的形式进行集群存储,还可以使用hadoop的hdfs分布式文件系统和亚马逊的s3来进行分布式存储。
- Distributed Lucence Directory:顾名思义,指的是每个索引下切片的Lucence目录
- ES中间的三个模块分别为索引模块、搜索模块、映射模块,这三个模块构成了ES的整个工作流程。
- Discovery:发现,指的是集群的发现机制。当集群中有节点进入和离开,会对一个分片进行重新的分片。发现机制通过zen组件的形式或通过插件EC2来进行实现。
- Scripting:顾名思义,指的是脚本。ES支持的脚本语言包括mvel、js、python、etc等
- 3rd Plugins:代表第三方插件
- Transport:表示集群间的信息交互,传输协议包括Thrift、Memcached、Http等
- JMX:监控
- Restful style API:Restful风格的API操作
- Java(Netty):ES的编程框架
4.2集群架构

集群副本架构图
集群架构图主要展示了3个节点组成的集群。其中P0、P1、P2表示一个索引的三个切片,R0、R1、R2表示上述三个切片对应的副本,可以看到每个切片和其对应的副本都存储在不同的节点上,这样保证了当其中某一个节点挂掉后,索引的数据不会丢失,仍可以从切片的副本中进行读取,保证整个系统的高可用性。通过每个客户端都能通过ES集群中的任一节点来查询数据。

集群整体架构图
集群整体架构图主要展示了集群中索引的切片分布情况,以及每个切片所进行操作。从图中可以看出Index存存储在节点NodeA和NodeB上,分成4个切片。每个切片都包含了一个Lucence实例,Lucence将切片划分成多个Lucence段进行存储,每个Lucence段一旦被创建,就不能被修改,因此ES的数据存储主要取决于Lucence的数据存储。
5. ES原理
5.1 Lucence存储和检索
这部分主要对Lucence的存储和查询过程进行简要的描述。针对Lucence的存储和查询过程如下图所示。

ES简要原理
存储过程:
1) 存储文档经过词法分析得到一系列的词(Term)
2) 通过一系列词来创建形成词典和反向索引表
3) 将索引进行存储并写入硬盘。
查询过程:
a) 用户输入查询语句。
b) 对查询语句经过词法分析得到一系列词(Term) 。
c) 通过语法分析得到一个查询树。
d) 通过索引存储将索引读入到内存。
e) 利用查询树搜索索引,从而得到每个词(Term) 的文档链表,对文档链表进行交、差、并得到结果文档。
f) 将搜索到的结果文档对查询的相关性进行排序。
g) 返回查询结果给用户。
5.2 ES写数据
ES写数据包含两种情况,分别为写入一个新的文档和在原有文档的基础上进行数据的追加(覆盖原有的文档)。两者基本上没有什么区别,后者是把原来的文档进行删除,再重新写入。
ES写数据流程:
(1) 客户端选择一个ES节点发送写请求,ES节点接收请求变为协调节点。
(2) 协调节点判断写请求中如果没有指定文档id,则自动生成一个doc_id。协调节点对doc_id进行哈希取值,判断出文档应存储在哪个切片中。协调节点找到存储切片的对应节点位置,将请求转发给对应的node节点。
(3) Node节点的primary shard处理请求,并将数据同步到replica shard
(4) 协调节点发现所有的primary shard和所有的replica shard都处理完之后,就返回结果给客户端。
ES写数据底层原理:
(1) 数据先写入内存 buffer,然后每隔 1s,将数据 refresh 到操作系统缓存(os cache),生成新的segment。(os cache 中存储的数据能被搜索到)
(2) 写入 os cache 中的translog数据,默认每隔 5 秒刷一次到磁盘中去,如果translog 大到一定程度,或者默认每隔 30mins,会触发 commit 操作,将缓冲区的数据都 flush 到 segment file 磁盘文件中。
5.3 ES读数据
ES读数据是通过doc_id来进行查询,先根据doc_id判断出文档存储在哪个切片上,再从切片上把数据读取过来。
ES读数据流程:
(1) 客户端给任意一个节点发送请求,该节点变为协调节点
(2) 协调节点根据doc_id,进行哈希取值,判断出文档存储在哪个切片上。
(3) 协调节点将请求转发到对应的节点上,然后使用随机轮询算法(round-robin),在切片和副本切片中随机选择一个,以使读请求负载均衡
(4) 接收请求的节点返回文档数据给协调节点,协调节点再返回数据给客户端。
5.4 ES检索关键词
ES检索关键词流程:
ES检索关键词是ES最常使用的做法,通过关键词,将包含关键词的文档全部搜索出来。
(1) 客户端向任意一个节点发送请求,该节点变为协调节点
(2) 协调节点将搜索请求转到所有的shard上
(3) 每个shard将自身的检索结果(搜索到的doc_id和分数),返回给协调节点。
(4) 协调节点根据检索结果进行相关性排序,产出最终的结果。再把doc_id发送给各个节点,拉取文档数据,最终返回给客户端。
5.5 ES删数据
删除数据底层原理:
删除操作,是在commit 的时候会生成一个.del文件,里面将doc标识为deleted状态,搜索的时候根据.del文件就知道这个 doc 是否被删除了。
6. ES安装
ES7.x参考文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.x/getting-started-install.html
ES windows官网下载地址:https://www.elastic.co/cn/downloads/elasticsearch
ES Linux下载:curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.13.0-linux-x86_64.tar.gz
1.访问https://www.elastic.co/cn/downloads/elasticsearch页面
2.下载安装包后,运行tar -xzf elasticsearch-7.12.0-linux-x86_64.tar.gz进行解压
3.进入解压后的文件夹,工作目录如下所示:
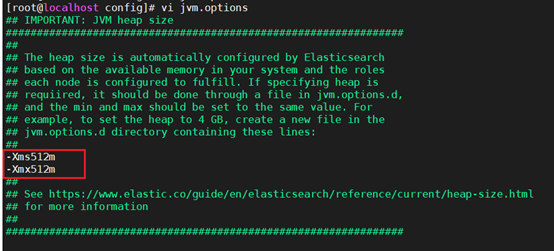
4.根据安装机器的内存大小来修改es的堆内存大小,默认为4g。运行vim ./config/jvm.options,将文件修改成如下图所示。
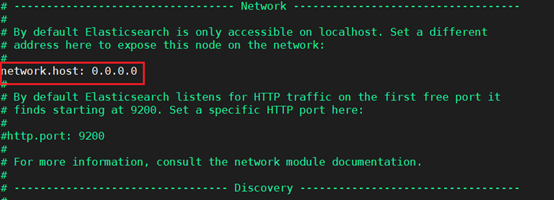
5.修改./config/elasticsearch.yml配置文件,运行vim ./config/elasticsearch.yml,将文件修改成如下所示,表示es可以被任何ip访问。
6.运行vim /etc/sysctl.conf,在配置文件中加入vm.max_map_count = 655360,设置最大连接数。

7.运行/sbin/sysctl –p,使步骤6的配置生效。
8.ES默认只能由非root用户来运行,因此需要先创建一个普通用户。创建用户如下图所示。

9.将elasticsearch文件夹的权限赋给新创建的用户。

10.运行su yonghu_test,切换到新创建的用户。在elasticsearch解压目录下运行sh ./ elasticsearch执行启动脚本。
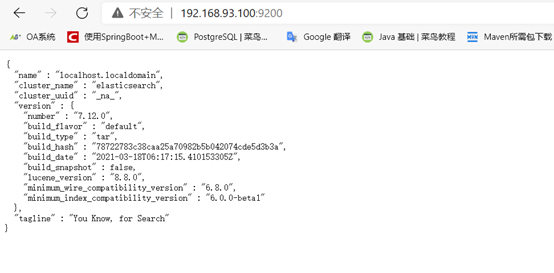
11.关闭机器的防火墙,通过浏览器访问ip:9200,显示以下界面,表示启动成功。
启动错误处理:
[1]: max file descriptors [4096] for elasticsearch process is too low, increase
to at least [65536]
解决办法:
编辑 /etc/security/limits.conf,追加以下内容;
* soft nofile 65536
* hard nofile 65536
此文件修改后需要重新登录用户,才会生效。
[2]: max virtual
memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决办法:
编辑 /etc/sysctl.conf,追加以下内容:
vm.max_map_count=655360
保存后,执行:
sysctl -p
[3]: max number
of threads [2048] for user [tongtech] is too low, increase to at least [4096]
错误原因:启动检查未通过
elasticsearch用户的最大线程数太低
解决办法:
vim /etc/security/limits.d/20-nproc.conf
将2048改为4096或更大
[4]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
解决办法:
修改elasticsearch.yml
取消注释保留一个节点
cluster.initial_master_nodes: ["node-1"]
注:ES机器的内存最小要大于1.5G。
7. ES常用API
ES Restful API GET、POST、PUT、DELETE、HEAD含义:
1)GET:获取请求对象的当前状态。
2)POST:改变对象的当前状态。
3)PUT:创建一个对象。
4)DELETE:销毁对象。
5)HEAD:请求获取对象的基础信息。
7.1 索引操作
(1)查看集群健康状况
GET /_cat/health?v&pretty
(2)查看指定索引(my_index)的mapping和setting的相关信息
GET /my_index?pretty
(3)查看所有的index
GET /_cat/indices?v&pretty
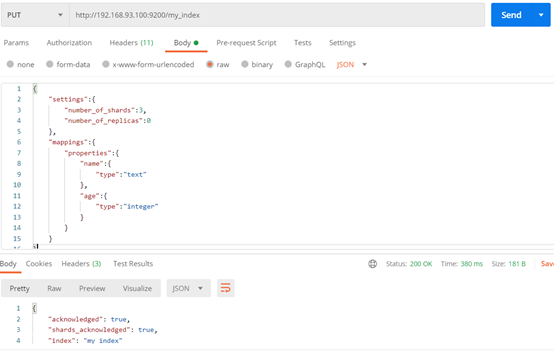
(4)创建有三个主分片,没有复制分片的小索引。
PUT /my_index
{
"settings":{
"number_of_shards":3,
"number_of_replicas":0
},
"mappings":{
"properties":{
"name":{
"type":"text"
},
"age":{
"type":"integer"
}
}
}
}
(5)修改索引的分片副本数
PUT /my_index/_settings
{
"number_of_replicas": 1
}
(6)删除索引
DELETE /my_index
(7)删除多个索引
DELETE /index_one,index_two
DELETE /index_*
DELETE /_all
7.2 文档操作
(1)添加文档
如果文档ID为1不存在,创建新的文档。否则,先删除现有文档,再创建新的文档
PUT my_index/_doc/1
{
“user”:”nihao”
}
如果文档ID为1 已经存在,会创建失败
PUT my_index/_create/1
{
“user”:”nihao”
}
(2)更新文档
文档必须已经存在,更新只会对相应的字段做增量修改
POST my_index/_update/1
{
“doc”:{
“user”:”nihao”
}
}
(3)删除文档
DELETE my_index/_doc/1
7.3 查询操作
(1)单关键词查询
GET /my_index/_doc/_search
{
"query": {
"match": {
"user": "nihao"
}
}
}
(2)多关键词查询
GET /my_index/_doc/_search
{
"query": {
"multi_match": {
“user": ["nihao","again"]
}
}
}
(3)精确查询
单词精确查询
GET /my_index/_doc/_search
{
"query": {
"term": {
"hostname": "xxx"
}
}
}
多词精确查询
GET /my_index/_doc/_search
{
"query": {
"terms": {
"status": [
304,
302
]
}
}
}
(4)范围查询
GET /my_index/_doc/_search
{
"query": {
"range": {
"age": {
"gte": 20,
"lt": 30
}
}
}
gt : 大于
gte: 大于等于
lt : 小于
lte: 小于等于
to:小于
from:大于等于
(5)通配符查询
GET /my_index/_doc/_search
{
"query": {
"wildcard": {
"postcode": "W?F*HW"
}
}
}
通配符的含义:
?,匹配任何单个字符
*,可以匹配零或更多字符,包括一个空的
(6)正则表达式查询
GET /my_index/_doc/_search
{
"query":{
"regex":{
"title":{
"value":'cr.m[ae]',
"boost":10.0
}
}
}
}
(6)布尔查询
布尔查询把多个子查询组合(combine)成一个布尔表达式,所有子查询之间的逻辑关系是与(and);只有当一个文档满足布尔查询中的所有子查询条件时,ElasticSearch引擎才认为该文档满足查询条件。
布尔查询支持的子查询类型共有四种,分别是:must,should,must_not和filter:
- must子句:文档必须匹配must查询条件;
- should子句:文档应该匹配should子句查询的一个或多个;
- must_not子句:文档不能匹配该查询条件;
- filter子句:过滤器,文档必须匹配该过滤条件,跟must子句的唯一区别是,filter不影响查询的score;
should子句是数组字段,包含多个should子查询,默认情况下,匹配的文档必须满足其中一个子查询条件。如果查询需要改变默认匹配行为,查询DSL必须显式设置布尔查询的参数minimum_should_match的值,该参数控制一个文档必须匹配的should子查询的数量。
GET /my_index/_doc/_search
{
"bool" : {
"must" : {
"term" : { "user" : "kimchy" }
},
"filter": {
"term" : { "tag" : "tech" }
},
"must_not" : {
"range" : {
"age" : { "from" : 10, "to" : 20 }
}
},
"should" : [
{ "term" : { "tag" : "wow" } },
{ "term" : { "tag" : "elasticsearch" } }
],
"minimum_should_match" : 1
}
}
(7)聚合查询
聚合查询是在数据上生成复杂的分析统计。聚合查询中有两个概念Buckets(桶)、Metrics(指标)。
Buckets(桶):满足某个条件的文档集合。
Metrics(指标):为某个桶中的文档计算得到的统计信息(比如对数据集进行avg,max操作)。
一个聚合就是一些桶和指标的组合,类似于sql中的group by。
GET /my_index/_doc/_search
{
"sizes":0
"aggs": {
"t_shirts": {
"filter": { "term": { "type": "t-shirt" } },
"aggs": {
"avg_price": { "avg": { "field": "price" } }
}
}
}
}
注:size不设置为0,除了返回聚合结果外,还会返回其它所有的数据。
8 演示
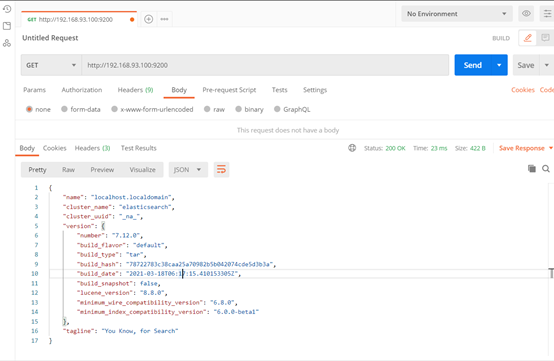
查看安装版本
创建索引
删除索引

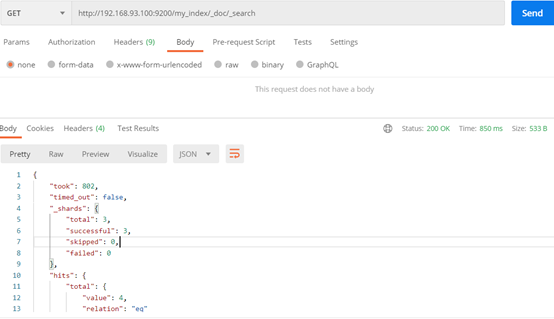
添加文档
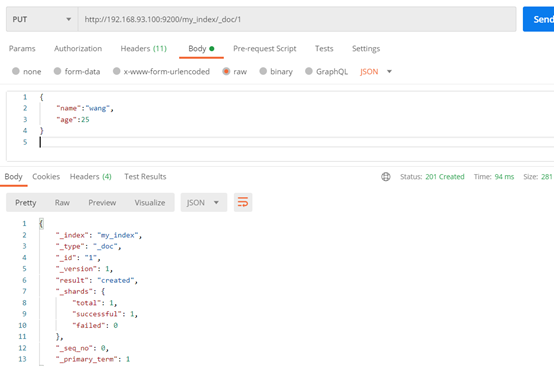
查询索引中所有文档信息
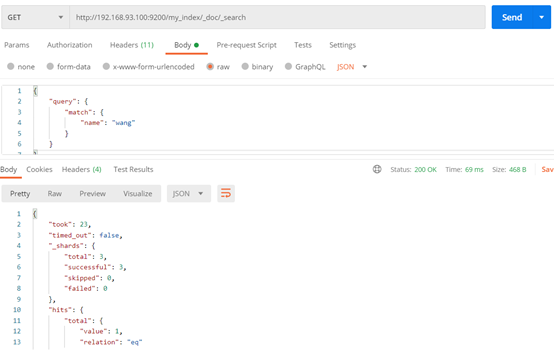
关键词查询


 浙公网安备 33010602011771号
浙公网安备 33010602011771号