【Interview】Java 高频面试题(二)
Java 高频面试题(二)
Java 基础
JUC
谈谈对 volatile 关键字的理解?
基本概念
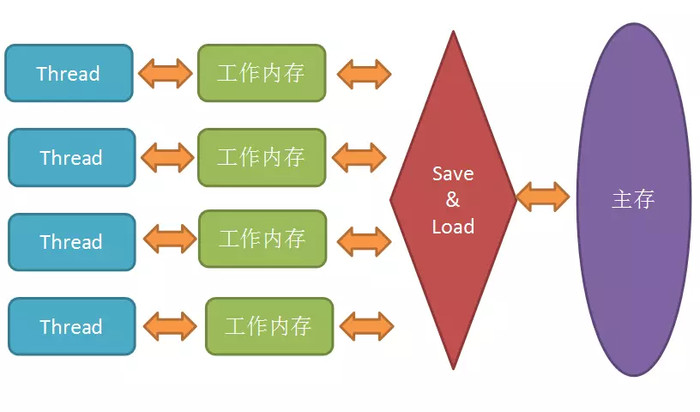
volatile 是 JVM 提供的轻量级(不会引起线程上下文的切换和调度)同步机制,它保证可见性和禁止指令重排(保证有序性),不保证原子性。
值得一提的是,JMM(Java 内存模型,Java Memory Model)本身是一种抽象的概念,它并不真实存在,它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式。
JMM 关于同步的规定:
- 线程加锁前,必须读取主内存的最新值到自己的工作内存
- 线程解锁前,必须把共享变量的值刷新回主内存
- 加锁和解锁是同一把锁
保证可见性说明
可见性指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
当一个变量被 volatile 修饰后,表示着线程本地内存无效,当一个线程修改共享变量后它会立即被更新到主内存中,其他线程读取共享变量时,会直接从主内存中读取。当然 synchronize 和 Lock 都可以保证可见性,但是开销更大。
package java_two;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
/**
* @author parzulpan
* @version 1.0
* @date 2021-05
* @project JavaInterview
* @package java_two
* @desc volatile 保证可见性说明
*/
public class VolatileDemo1 {
public static ExecutorService executorService = Executors.newSingleThreadExecutor();
public static void main(String[] args) {
MyData myData = new MyData();
executorService.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " come in");
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
myData.addTo60();
System.out.println(Thread.currentThread().getName() + " update number value is " + myData.number);
}
});
while (myData.number == 0) { }
System.out.println(Thread.currentThread().getName() + " end");
executorService.shutdown();
}
}
class MyData {
/** 不用 volatile 修饰,main 线程一直卡住 */
volatile int number = 0;
// int number = 0;
public void addTo60() {
this.number = 60;
}
}
不保证原子性说明
原子性指一个操作或者多个操作要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
Java 中的原子性操作包括:
- 基本类型的读取和赋值操作,且赋值必须是值赋给变量,变量之间的相互赋值不是原子性操作
- 所有引用 reference 的赋值操作
java.concurrent.Atomic.*包中所有类的一切操作
package java_two;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* @author parzulpan
* @version 1.0
* @date 2021-05
* @project JavaInterview
* @package java_two
* @desc volatile 不保证原子性说明
*/
public class VolatileDemo2 {
public static ExecutorService executorService = Executors.newFixedThreadPool(10);
public static void main(String[] args) {
MyData2 myData2 = new MyData2();
for (int i = 0; i < 10; i++) {
executorService.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
for (int i = 0; i < 1000; i++) {
myData2.addPlusPlus();
}
}
});
}
executorService.shutdown();
// 等待上面的 10 个线程都计算完成
// 默认是有两个线程的,一个 main 线程,一个 gc 线程
while (Thread.activeCount() > 2) { }
// 可以发现最后的结果总是小于 10000
System.out.println(Thread.currentThread().getName() + " finally number value is " + myData2.number);
}
}
class MyData2 {
volatile int number = 0;
public void addPlusPlus() {
number ++;
}
}
最后的结果总是小于 10000 的原因是因为 number ++; 在多线程下是非线程安全的。将代码编译成字节码,可以看出其被编译成 3 条指令:
getfield
iconst_1
iadd
putfield
解决这个不保证原子性的问题,有几种方法:
- 使用 synchronized 和 Lock,但性能较差
- 使用 Atomic 原子类
class MyData2 {
volatile int number = 0;
public synchronized void addPlusPlus() {
number ++;
}
}
// 或者
class MyData2 {
AtomicInteger number = new AtomicInteger();
public void addPlusPlus() {
number.getAndIncrement();
}
}
保证有序性说明
有序性指程序执行的顺序按照代码的先后顺序执行。
如果在本线程内观察,所有操作都是有序的;如果在一个线程中观察另一个线程,所有操作都是无序的。前半句是指“线程内表现为串行语义”,后半句是指“指令重排序”现象和“工作内存与主内存同步延迟”现象。
重排序是指编译器和处理器为了优化程序性能而对指令序列进行排序的一种手段。重排序需要遵守一定规则:
- 重排序操作不会对存在数据依赖关系的操作进行重排序
- 重排序是为了优化性能,但是不管怎么重排序,单线程下程序的执行结果不能被改变
但是在多线程环境下,可能发生重排序,影响结果。
package java_two;
/**
* @author parzulpan
* @version 1.0
* @date 2021-05
* @project JavaInterview
* @package java_two
* @desc volatile 保证有序性说明
*/
public class VolatileDemo3 {
int a = 0;
boolean flag = false;
public void method01(){
//语句1
a = 1;
//语句2
flag = true;
}
public void method02(){
if(flag){
//语句3
a = a + 5;
}
// 多线程情况下,结果可能是6或1或5或0
System.out.println("retValue: " + a);
}
}
使用 volatile 关键字修饰共享变量便可以禁止这种重排序。若用 volatile 修饰共享变量,在编译时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。具体规则为:执行到 volatile 变量时,其前面的所有语句都执行完,后面所有语句都未执行。且前面语句的结果对 volatile 变量及其后面语句可见。
volatile 原理分析
volatile 可以保证线程可见性并提供一定的有序性,但是无法保证原子性。这是因为 JVM 底层 volatile 是采用内存屏障来实现的。加了 volatile 关键字后,其汇编代码会多出一个 lock 前缀指令,lock 前缀指令实际上就相当于一个内存屏障,它提供三个功能:
- 它确保指令重排序时不会把其 后面/前面 的指令排到内存屏障 之前/之后 的位置,即在执行到内存屏障这句指令时,它前面的操作已经全部完成;
- 对 volatile 变量进行写操作时,会在写操作后加入一条 store 屏障指令,将工作内存中的共享变量值刷新回到主内存;
- 对 volatile 变量进行读操作时,会在读操作前加入一条 load 屏障指令,从主内存中读取共享变量到工作内存。
volatile 实际应用
1,状态量标记,volatile boolean flag = false; 就保证了有序性。
2,单例模式的 DCL(Double Check Lock) 写法:
package java_two;
/**
* @author parzulpan
* @version 1.0
* @date 2021-05
* @project JavaInterview
* @package java_two
* @desc 单例模式双重共锁写法
*/
public class VolatileDCL {
private static volatile VolatileDCL instance;
private VolatileDCL() {}
public static VolatileDCL getInstance() {
if (instance == null) {
synchronized (VolatileDCL.class) {
if (instance == null) {
// 3
instance = new VolatileDCL();
}
}
}
return instance;
}
}
为什么要加 volatile ?
在多线程的情况下,instance = new VolatileDCL(); 可以分解为
memory = allocate() // 1. 分配内存
ctorInstanc(memory) // 2. 初始化对象
instance = memory // 3. 设置instance指向刚分配的地址
步骤 2 和步骤 3 不存在数据依赖关系,而且无论重排前还是重排后程序的执行结果在单线程中并没有改变,因此这种重排优化是允许的,这就可能造成有序性的问题。加了 volatile 就禁止了指令重排,解决了有序性的问题。
谈谈对 CAS(Compare And Swap) 的理解?
一个前导问题:原子类为什么能保证原子性?
回答:因为 CAS。
基本概念
CAS 是指 Compare And Swap,比较并交换,是一种很重要的同步思想。如果主内存的值跟期望值一样,那就进行修改,否则一直重试,直到一致为止。CAS 是一条 CPU 并发原语,不会造成所谓的数据不一致问题。
public class CASDemo {
public static void main(String[] args) {
AtomicInteger atomicInteger = new AtomicInteger(5);
// true current value 999
System.out.println(atomicInteger.compareAndSet(5, 999) + " current value " + atomicInteger.get());
// false current value 999 修改失败
System.out.println(atomicInteger.compareAndSet(5, 1024) + " current value " + atomicInteger.get());
}
}
第一次修改,期望值为5,主内存也为5,修改成功,为999。第二次修改,期望值为5,主内存为999,修改失败。
CAS 底层原理
查看AtomicInteger.getAndIncrement()方法,发现其没有加synchronized也实现了同步。这是为什么?
atomiclnteger.getAndIncrement() 源码为:
public class AtomicInteger extends Number implements java.io.Serializable { private static final long serialVersionUID = 6214790243416807050L; // setup to use Unsafe.compareAndSwapInt for updates // Unsafe 是 CAS 核心类,由于 Java 方法无法直接访问底层系统,需要通过本地(native)方法来访问 // Unsafe 相当于一个后门,基于该类可以直接操作特定内存的数据 // Unsafe 类存在于 sun.misc 包中,其内部方法操作可以像 C 的指针一样直接操作内存 // Unsafe 类中的方法都直接调用操作系统底层资源执行相应任务 private static final Unsafe unsafe = Unsafe.getUnsafe(); // 表示该变量值在内存中的偏移地址,因为 Unsafe 就是根据内存偏移地址获取数据的 private static final long valueOffset; static { try { valueOffset = unsafe.objectFieldOffset (AtomicInteger.class.getDeclaredField("value")); } catch (Exception ex) { throw new Error(ex); } } // 用 volatile 修饰,保证了多线程之间的内存可见性 private volatile int value; /** * Creates a new AtomicInteger with the given initial value. * * @param initialValue the initial value */ public AtomicInteger(int initialValue) { value = initialValue; } /** * Creates a new AtomicInteger with initial value {@code 0}. */ public AtomicInteger() { } /** * Atomically increments by one the current value. * * @return the previous value */ public final int getAndIncrement() { return unsafe.getAndAddInt(this, valueOffset, 1); } // ...}
unsafe.getAndAddInt() 源码为:
// var1 指 AtomicInteger 对象本身// var2 指 该对象值的引用地址// var4 指 需要变动的数量,这里为 1// var5 指 通过 var1 和 var2 找出的主内存中真实的值// 用该对象当前的值与 var5 进行比较:// 如果相同,更新值为 var5+var4 并返回 true// 如果不同,继续取值然后再比较,直到更新完成public final int getAndAddInt(Object var1, long var2, int var4) { int var5; do { var5 = this.getIntVolatile(var1, var2); } while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4)); return var5; }
比如有 A、B 两个线程,一开始都从主内存中拷贝了原值为 3,A 线程执行到var5=this.getIntVolatile,即 var5=3。此时 A 线程挂起,B 修改原值为 4,B 线程执行完毕,由于加了 volatile,所以这个修改是立即可见的。A 线程被唤醒,执行this.compareAndSwapInt()方法,发现这个时候主内存的值不等于快照值 3,所以继续循环,重新从主内存获取。
CAS 缺点
CAS 实际上是一种自旋锁,有如下缺点:
- 一直循环,开销比较大
- 只能保证一个变量的原子操作,多个变量依然要加锁
- 引出了 ABA 问题
谈谈对原子类 AtomicInteger 的 ABA 问题的理解?原子引用知道吗?
ABA 问题
所谓 ABA 问题,就是比较并交换的循环过程中,存在一个时间差,而这个时间差可能带来意想不到的问题。
比如线程 T1 将值从 A 修改为 B,然后又从 B 修改为 A。线程 T2 看到的就是 A,但是却不知道这个 A 发生了改变。
尽管线程 T2 的 CAS 操作成功,但不代表就没有问题。 有的需求,比如CAS,只注重头和尾,只要首尾一致就接受。但是有的需求,还看重过程,中间不能发生任何修改,这就引出了AtomicReference原子引用。
原子引用
AtomicInteger 是对整数进行原子操作,如果是一个 实体类 呢?可以用AtomicReference来包装这个实体类,使其操作原子化。
package java_two;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.TimeUnit;import java.util.concurrent.atomic.AtomicReference;/** * @author parzulpan * @version 1.0 * @date 2021-05 * @project JavaInterview * @package java_two * @desc 原子引用 */public class AtomicReferenceDemo { public static ExecutorService executorService = Executors.newFixedThreadPool(2); public static void main(String[] args) { User aa = new User("AA", 23); User bb = new User("BB", 24); AtomicReference<User> atomicReference = new AtomicReference<>(); atomicReference.set(aa); executorService.execute(new Runnable() { @Override public void run() { try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } // true System.out.println(atomicReference.compareAndSet(aa, bb)); // true System.out.println(atomicReference.compareAndSet(bb, aa)); } }); executorService.execute(new Runnable() { @Override public void run() { // 保证完成一次 ABA try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { e.printStackTrace(); } // true,但是业务要求它返回 false System.out.println(atomicReference.compareAndSet(aa, bb)); } }); executorService.shutdown(); }}class User { private String name; private Integer age; public User(String name, Integer age) { this.name = name; this.age = age; } @Override public String toString() { return "User{" + "name='" + name + '\'' + ", age=" + age + '}'; }}
时间戳原子引用
使用AtomicStampedReference类可以解决 ABA 问题。这个类维护了一个“版本号”Stamp,在进行 CAS 操作的时候,不仅要比较当前值,还要比较版本号。只有两者都相等,才执行更新操作。
package java_two;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.TimeUnit;import java.util.concurrent.atomic.AtomicStampedReference;/** * @author parzulpan * @version 1.0 * @date 2021-05 * @project JavaInterview * @package java_two * @desc 时间戳原子引用,解决 ABA 问题 */public class AtomicStampedReferenceDemo { public static ExecutorService executorService = Executors.newFixedThreadPool(2); public static void main(String[] args) { User cc = new User("CC", 23); User dd = new User("DD", 24); User ee = new User("EE", 25); AtomicStampedReference<User> atomicStampedReference = new AtomicStampedReference<>(cc, 1); executorService.execute(new Runnable() { @Override public void run() { try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } // true System.out.println(atomicStampedReference.compareAndSet(cc, dd, atomicStampedReference.getStamp(), atomicStampedReference.getStamp() + 1)); // true System.out.println(atomicStampedReference.compareAndSet(dd, cc, atomicStampedReference.getStamp(), atomicStampedReference.getStamp() + 1)); } }); executorService.execute(new Runnable() { @Override public void run() { int stamp = atomicStampedReference.getStamp(); // 保证完成一次 ABA try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { e.printStackTrace(); } // false System.out.println(atomicStampedReference.compareAndSet(cc, ee, stamp, stamp + 1)); } }); executorService.shutdown(); }}
ArrayList 是线程安全的吗?请编写一个线程不安全的 demo 并给出解决方案?
ArrayList 不是线程安全的,在多线程同时写的情况下,会抛出并发修改异常 java.util.ConcurrentModificationException。
故障现象:
- 抛出 java.util.ConcurrentModificationException
导致原因:
- 并发争抢修改的资源
解决方案:
-
使用
Vector(ArrayList所有方法加synchronized,太重) -
使用
Collections.synchronizedList()转换成线程安全类 -
使用
java.util.concurrent.CopyOnWriteArrayList(推荐使用)-
这是 JUC 的类,它通过写时复制来实现读写分离
-
比如其
add()方法,就是先复制一个新数组,长度为原数组长度+1,然后将新数组最后一个元素设为添加的元素,源码为:public boolean add(E e) { final ReentrantLock lock = this.lock; lock.lock(); try { //得到旧数组 Object[] elements = getArray(); int len = elements.length; //复制新数组 Object[] newElements = Arrays.copyOf(elements, len + 1); //设置新元素 newElements[len] = e; //设置新数组 setArray(newElements); return true; } finally { lock.unlock(); }}
-
优化建议:
- 使用 JUC 相关类
总结:
- Collection 接口:单列集合,用来存储一个一个的对象
- List 接口:存储有序的、可重复的对象
- ArrayList:作为 List 接口的主要实现类;底层使用
Object[] elementData存储,适用于频繁随机访问操作;add(E e)默认情况下,扩容为原来的容量的 1.5 倍;线程不安全的,效率高; - LinkedList: 底层使用双向链表存储,适用于频繁插入、删除操作;线程不安全的,效率高;
- Vector:作为 List 接口的古老实现类;底层使用
Object[] elementData存储,适用于频繁随机访问操作;add(E e)默认情况下,扩容为原来的容量的 2 倍;线程安全的,效率低;
- ArrayList:作为 List 接口的主要实现类;底层使用
- Set 接口:存储无序的、不可重复的对象
- HashSet:作为 Set 接口的主要实现类;底层使用 HashMap 存储(
HashMap.put()需要传两个参数,而HashSet.add()只传一个参数的原因为:实际上HashSet.add()就是调用的HashMap.put(),只不过 value 被写死了,是一个private static final Object对象);线程不安全的,效率高; - LinkedHashSet:作为 HashSet 的子类,遍历其内部数据时,可以按照添加的顺序遍历;线程不安全的,效率高;
- TreeSet:作为 SortedSet 接口的实现类,底层使用红黑树存储,可以按照添加对象的指定属性进行排序;线程不安全的,效率高;
- HashSet:作为 Set 接口的主要实现类;底层使用 HashMap 存储(
- List 接口:存储有序的、可重复的对象
- Map 接口:双列集合,用来存储一对一对的对象
- HashMap:作为 Map 接口的主要实现类;可以存储
null的 key 和 value;底层使用 数组+链表+红黑树(JDK8,JDK7无红黑树)存储;线程不安全的,效率高; - LinkedHashMap:作为 HashMap 的子类,遍历其内部数据时,可以按照添加的顺序遍历;线程不安全的,效率高;
- TreeMap:底层使用红黑树存储,可以按照添加对象的指定属性进行排序;线程不安全的,效率高;
- Hashtable:作为 Map 接口的古老实现类;不可以存储
null的 key 和 value;线程安全的,效率低; - Properties:作为 Hashtable 的子类;常用来处理配置文件,key 和 value 都是 String 类型;线程安全的,效率低;
- HashMap:作为 Map 接口的主要实现类;可以存储
package java_two;import java.util.*;import java.util.concurrent.ConcurrentHashMap;import java.util.concurrent.CopyOnWriteArrayList;import java.util.concurrent.CopyOnWriteArraySet;/** * @author parzulpan * @version 1.0 * @date 2021-05 * @project JavaInterview * @package java_two * @desc 集合线程安全性说明 */public class ContainerNotSafeDemo { public static void main(String[] args) {// arrayListNotSafe();// LinkedListNotSafe();// VectorSafe();// hashSetNotSafe();// linkedHashSetNotSafe();// treeSetNotSafe();// hashMapNotSafe();// linkedHashMapNotSafe();// treeMapSafe(); hashTableNotSafe(); } /** * ArrayList 线程不安全,使用 CopyOnWriteArrayList 解决线程安全问题 */ public static void arrayListNotSafe() {// List<String> list = new ArrayList<>(); List<String> list = new CopyOnWriteArrayList<>(); for (int i = 0; i < 30; i++) { new Thread(() -> { list.add(UUID.randomUUID().toString().substring(0, 8)); System.out.println(Thread.currentThread().getName() + "\t" + list); }, String.valueOf(i)).start(); } } /** * LinkedList 线程不安全,使用 CopyOnWriteArrayList 解决线程安全问题 */ public static void LinkedListNotSafe() {// List<String> list = new LinkedList<>(); List<String> list = new CopyOnWriteArrayList<>(); for (int i = 0; i < 30; i++) { new Thread(() -> { list.add(UUID.randomUUID().toString().substring(0, 8)); System.out.println(Thread.currentThread().getName() + "\t" + list); }, String.valueOf(i)).start(); } } /** * Vector 线程安全 */ public static void VectorSafe() { List<String> list = new Vector<>(); for (int i = 0; i < 30; i++) { new Thread(() -> { list.add(UUID.randomUUID().toString().substring(0, 8)); System.out.println(Thread.currentThread().getName() + "\t" + list); }, String.valueOf(i)).start(); } } /** * HashSet 线程不安全,使用 CopyOnWriteArraySet 解决线程安全问题 * CopyOnWriteArraySet 底层维护了一个CopyOnWriteArrayList数组。 */ public static void hashSetNotSafe() {// Set<String> set = new HashSet<>(); Set<String> set = new CopyOnWriteArraySet<>(); for (int i = 0; i < 30; i++) { new Thread(() -> { set.add(UUID.randomUUID().toString().substring(0, 8)); System.out.println(Thread.currentThread().getName() + "\t" + set); }, String.valueOf(i)).start(); } } /** * LinkedHashSet 线程不安全,使用 CopyOnWriteArraySet 解决线程安全问题 */ public static void linkedHashSetNotSafe() {// Set<String> set = new LinkedHashSet<>(); Set<String> set = new CopyOnWriteArraySet<>(); for (int i = 0; i < 30; i++) { new Thread(() -> { set.add(UUID.randomUUID().toString().substring(0, 8)); System.out.println(Thread.currentThread().getName() + "\t" + set); }, String.valueOf(i)).start(); } } /** * TreeSet 线程不安全,使用 CopyOnWriteArraySet 解决线程安全问题 */ public static void treeSetNotSafe() {// Set<String> set = new TreeSet<>(); Set<String> set = new CopyOnWriteArraySet<>(); for (int i = 0; i < 30; i++) { new Thread(() -> { set.add(UUID.randomUUID().toString().substring(0, 8)); System.out.println(Thread.currentThread().getName() + "\t" + set); }, String.valueOf(i)).start(); } } /** * HashMap 线程不安全,使用 ConcurrentHashMap 解决线程安全问题 */ public static void hashMapNotSafe() {// Map<String, String> map = new HashMap<>(); Map<String, String> map = new ConcurrentHashMap<>(); for (int i = 0; i < 30; i++) { new Thread(() -> { map.put(Thread.currentThread().getName(), UUID.randomUUID().toString().substring(0, 8)); System.out.println(Thread.currentThread().getName() + "\t" + map); }, String.valueOf(i)).start(); } } /** * LinkedHashMap 线程不安全,使用 ConcurrentHashMap 解决线程安全问题 */ public static void linkedHashMapNotSafe() {// Map<String, String> map = new LinkedHashMap<>(); Map<String, String> map = new ConcurrentHashMap<>(); for (int i = 0; i < 30; i++) { new Thread(() -> { map.put(Thread.currentThread().getName(), UUID.randomUUID().toString().substring(0, 8)); System.out.println(Thread.currentThread().getName() + "\t" + map); }, String.valueOf(i)).start(); } } /** * TreeMap 线程不安全,使用 ConcurrentHashMap 解决线程安全问题 */ public static void treeMapSafe() {// Map<String, String> map = new TreeMap<>(); Map<String, String> map = new ConcurrentHashMap<>(); for (int i = 0; i < 30; i++) { new Thread(() -> { map.put(Thread.currentThread().getName(), UUID.randomUUID().toString().substring(0, 8)); System.out.println(Thread.currentThread().getName() + "\t" + map); }, String.valueOf(i)).start(); } } /** * Hashtable 线程安全 */ public static void hashTableNotSafe() { Map<String, String> map = new Hashtable<>(); for (int i = 0; i < 30; i++) { new Thread(() -> { map.put(Thread.currentThread().getName(), UUID.randomUUID().toString().substring(0, 8)); System.out.println(Thread.currentThread().getName() + "\t" + map); }, String.valueOf(i)).start(); } }}
推荐阅读:
谈谈 HashMap、Hashtable、ConcurrentHashMap 的原理与区别?
谈谈对公平锁、非公平锁、可重入锁/递归锁、自旋锁的理解?请编写一个自旋锁 demo?
公平锁和非公平锁
概念:
-
所谓公平锁,即多个线程按照申请锁的顺序来获取锁,类似排队,先到先得。
-
所谓非公平锁,即多个线程抢夺锁,它会导致优先级反转和饥饿现象。
区别:
- 公平锁在获取锁时会先查看此锁维护的等待队列,为空或者当前线程时等待队列的队首,则直接占有锁,否则插入到等待队列,按照先进先出的原则。
- 非公平锁会直接先尝试占有锁,失败则采用公平锁方式。它的优点是吞吐量比公平锁更大。
synchronized 和 juc.ReentrantLock 默认都是非公平锁,ReentrantLock 在构造的时候传入 true 则是公平锁。
可重入锁/递归锁
可重入锁又称为递归锁,即同一个线程在外层方法获得锁时,进入内层方法会自动获取锁。也就是说,线程可以进入任何一个它已经拥有锁的代码块。比如有了家门口的锁,像卧室、书房、厨房等就可以自由进出了。
可重入锁可以避免死锁的问题。
synchronized 和 juc.ReentrantLock 是比较典型的可重入锁。
package java_two;import java.util.concurrent.locks.Lock;import java.util.concurrent.locks.ReentrantLock;/** * @author parzulpan * @version 1.0 * @date 2021-05 * @project JavaInterview * @package java_two * @desc 可重入锁 */public class ReentrantLockDemo { public static void main(String[] args) {// runInfo(); runInfo2(); } public static void runInfo() { Info info = new Info(); new Thread(() -> info.getInfo(), "t1").start(); new Thread(() -> info.getInfo(), "t2").start(); } public static void runInfo2() { Info2 info2 = new Info2(); new Thread(info2, "t3").start(); new Thread(info2, "t4").start(); }}class Info { public synchronized void getInfo() { System.out.println(Thread.currentThread().getName() + " invoked getInfo()"); getInfoName(); } public synchronized void getInfoName() { System.out.println(Thread.currentThread().getName() + " invoked getInfoName()"); }}class Info2 implements Runnable { Lock lock = new ReentrantLock(); public void getInfo() { lock.lock(); try { System.out.println(Thread.currentThread().getName() + " invoked getInfo()"); getInfoName(); } finally { lock.unlock(); } } public void getInfoName() { lock.lock(); try { System.out.println(Thread.currentThread().getName() + " invoked getInfoName()"); } finally { lock.unlock(); } } @Override public void run() { getInfo(); }}
值得注意的是,锁与锁之间要讲究配对,加了几把锁,最后就得解开几把锁。下面的代码编译和运行都没有任何问题,但锁的数量不匹配会导致死循环。
lock.lock();lock.lock();try{ someAction();}finally{ lock.unlock();}
自旋锁
所谓自旋锁,即在尝试获取锁的线程时不会立即阻塞,而是采用循环的方式去尝试获取。自己在哪儿一致循环获取,就好像自己在旋转一样。它的优点是减少线程切换的上下文开销,缺点是消耗 CPU。CAS 底层 的 getAndAddInt 就是自旋锁的思想,同时还存在 ABA 问题。
package java_two;import java.util.concurrent.TimeUnit;import java.util.concurrent.atomic.AtomicReference;/** * @author parzulpan * @version 1.0 * @date 2021-05 * @project JavaInterview * @package java_two * @desc 自旋锁 */public class SpinLockDemo { /** 原子引用线程 */ AtomicReference<Thread> atomicReference = new AtomicReference<>(); public static void main(String[] args) { SpinLockDemo spinLockDemo = new SpinLockDemo(); // 启动 t1 线程,开始操作 new Thread(() -> { // 开始占有锁 spinLockDemo.myLock(); try { TimeUnit.SECONDS.sleep(5); } catch (InterruptedException e) { e.printStackTrace(); } // 开始释放锁 spinLockDemo.myUnLock(); }, "t1").start(); // 让 main 线程暂停1秒,使得 t1 线程先执行 try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } // 1 秒后,启动 t2 线程,开始占用这个锁 new Thread(() -> { // 开始占有锁 spinLockDemo.myLock(); // 开始释放锁 spinLockDemo.myUnLock(); }, "t2").start(); } public void myLock() { // 获取当前进来的线程 Thread thread = Thread.currentThread(); System.out.println(thread.getName() + " come in"); while (!atomicReference.compareAndSet(null, thread)) { // 开始自旋,期望值是 null,更新值是当前线程,如果是 null,则更新为当前线程,否则自旋 } System.out.println(thread.getName() + " come out"); } public void myUnLock() { // 获取当前进来的线程 Thread thread = Thread.currentThread(); // 使用完后,将其原子引用变为 null atomicReference.compareAndSet(thread, null); System.out.println(thread.getName() + " invoked myUnLock()"); }}
读写锁/共享独占锁
读锁是共享的,写锁是独占的。
共享锁就是一个锁能被多个线程所持有。
独占锁就是一个锁只能被一个线程所持有。synchronized 和 juc.ReentrantLock 都是独占锁。
但是有的时候,需要读写分离,那么就要引入读写锁,即 juc.ReentrantReadWriteLock,其读锁是共享锁,其写锁是独占锁。以下例子,就避免了写被打断,但实现了多个线程同时读。
package java_two;import java.util.HashMap;import java.util.Map;import java.util.concurrent.TimeUnit;import java.util.concurrent.locks.ReentrantReadWriteLock;/** * @author parzulpan * @version 1.0 * @date 2021-05 * @project JavaInterview * @package java_two * @desc 读写锁 */public class ReentrantReadWriteLockDemo { public static void main(String[] args) { MyCache myCache = new MyCache(); // 线程操作资源类,5 个线程写 for (int i = 0; i < 5; i++) { final int tempInt = i; new Thread(() -> { myCache.put(tempInt + "", tempInt + ""); }, String.valueOf(i)).start(); } // 线程操作资源类, 5 个线程读 for (int i = 0; i < 5; i++) { final int tempInt = i; new Thread(() -> { myCache.get(tempInt + ""); }, String.valueOf(i)).start(); } }}class MyCache { private volatile Map<String, Object> map = new HashMap<>(); /** 可以看到有些线程读取到 null,可用 ReentrantReadWriteLock 解决 */ private ReentrantReadWriteLock lock = new ReentrantReadWriteLock(); public void put(String k, Object v) { // 创建一个写锁 lock.writeLock().lock(); try { System.out.println(Thread.currentThread().getName() + " 正在写入"); try { // 模拟网络拥堵,延迟 0.3s TimeUnit.MILLISECONDS.sleep(300); } catch (InterruptedException e) { e.printStackTrace(); } map.put(k, v); System.out.println(Thread.currentThread().getName() + " 写入完成"); } finally { lock.writeLock().unlock(); } } public void get(String k) { // 创建一个读锁 lock.readLock().lock(); try { System.out.println(Thread.currentThread().getName() + " 正在读取"); try { // 模拟网络拥堵,延迟 0.3s TimeUnit.MILLISECONDS.sleep(300); } catch (InterruptedException e) { e.printStackTrace(); } Object o = map.get(k); System.out.println(Thread.currentThread().getName() + " 读取完成 " + o); } finally { lock.readLock().unlock(); } }}
synchronized 和 Lock 的区别
线程通信 synchronized 到 Lock 的方法演变:
- sync -> Lock
- wait -> await
- notify -> signal
- notifyAll -> signalAll
主要有以下几个方面的区别:
- 原始构成:sync 是关键字,属于 JVM 层面(通过 monitor 对象来完成)的,而 Lock 是一个接口,属于 JDK API 层面的
- 使用方法:sync 不需要手动释放锁,而 Lock 需要 在 finally 中手动释放
- 是否可中断:sync 不可中断,除非抛出异常或者正常运行完成,而 Lock 通过 设置超时时间 或 调用
interrupt()可被中断 - 是否为公平锁:sync 只能为非公平锁,而 Lock 既可以为 公平锁,又可以为非公平锁
- 是否可绑定多个条件:sync 不能,它只能随机唤醒,而 Lock 可以通过 Condition 来绑定多个条件,进行精确唤醒
谈谈对 CountDownLatch、CyclicBarrier、Semaphore 的理解?
CountDownLatch
CountDownLatch 内部维护了一个计数器,只有当计数器等于 0 时,某些线程才会停止阻塞,开始执行。
它主要有两个方法:
countDown()让计数器减 1await()让线程阻塞- 当计数器等于 0 时,阻塞线程会自动唤醒
package java_two;import java.util.concurrent.*;/** * @author parzulpan * @version 1.0 * @date 2021-05 * @project JavaInterview * @package java_two * @desc CountDownLatch 教室关门例子 */public class CountDownLatchDemo { private static ExecutorService threadPoolExecutor = new ThreadPoolExecutor(6, 200, 10L, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(1000), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy()); public static void main(String[] args) throws InterruptedException { CountDownLatch countDownLatch = new CountDownLatch(6); for (int i = 0; i < 6; i++) { threadPoolExecutor.execute(() -> { System.out.println("ThreadName: " + Thread.currentThread().getName() + ",离开教室"); countDownLatch.countDown(); }); } countDownLatch.await(); System.out.println("ThreadName: " + Thread.currentThread().getName() + ",学生全部离开,已关闭教室"); threadPoolExecutor.shutdown(); }}
CyclicBarrier
CyclicBarrier 与 CountDownLatch 相反,只有当 计数器 等于 指定值 时,某些线程才会停止阻塞,开始执行。
CyclicBarrier 与 CountDownLatch 的主要区别是,前者可以复用,而后者不行。
它主要有一个方法:
await()线程进入屏障
package java_two;import java.util.concurrent.*;/** * @author parzulpan * @version 1.0 * @date 2021-05 * @project JavaInterview * @package java_two * @desc CyclicBarrier 召唤神龙例子 */public class CyclicBarrierDemo { private static ExecutorService threadPoolExecutor = new ThreadPoolExecutor(7, 200, 10L, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(1000), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy()); public static void main(String[] args) { // 定义一个循环屏障,参数1 为需要累加的值,参数2 为需要执行的方法 CyclicBarrier cyclicBarrier = new CyclicBarrier(7, () -> { System.out.println("召唤神龙"); }); for (int i = 0; i < 7; i++) { final int tempInt = i; threadPoolExecutor.execute(() -> { System.out.println("ThreadName: " + Thread.currentThread().getName() + ",收集到第 " + tempInt + " 颗龙珠"); try { // 先到的被阻塞,等全部线程完成后,才能执行方法 cyclicBarrier.await(); } catch (InterruptedException | BrokenBarrierException e) { e.printStackTrace(); } }); } threadPoolExecutor.shutdown(); }}
Semaphore
信号量主要用于两个目的,一个是用于多个共享资源的互斥使用,另一个用于并发线程数的控制。
生产过程中,是不建议使用 Executors 中的静态方法来创建线程池的,因为会产生 OOM,如果非得使用,可以通过使用 Semaphore 对任务的执行进行限流。
常规的锁(例如 synchronied 和 Lock)在任何时刻都只允许 1 个任务访问一项资源,而 Semaphore 允许 n 个任务同时访问一项资源。
并且 CountDownLatch 不能复用,而 Semaphore 完美的解决了这个问题,
它主要有两个方法:
- accquire() 抢占资源/锁
- release() 释放资源/锁
package java_two;import java.util.concurrent.*;/** * @author parzulpan * @version 1.0 * @date 2021-05 * @project JavaInterview * @package java_two * @desc Semaphore 抢车位例子 */public class SemaphoreDemo { private static ExecutorService threadPoolExecutor = new ThreadPoolExecutor(6, 200, 10L, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(1000), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy()); public static void main(String[] args) { // 初始化一个信号量为 3,非公平锁,模拟3个停车位 Semaphore semaphore = new Semaphore(3, false); for (int i = 0; i < 6; i++) { threadPoolExecutor.execute(() -> { try { semaphore.acquire(); System.out.println("ThreadName: " + Thread.currentThread().getName() + ",抢到车位 "); // 停车 3s TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { e.printStackTrace(); }finally { System.out.println("ThreadName: " + Thread.currentThread().getName() + ",离开车位 "); semaphore.release(); } }); } threadPoolExecutor.shutdown(); }}
阻塞队列知道吗?谈谈其理解?
我们知道线程池的工作原理:
线程池创建,准备好 corePoolSize 数量的核心线程,准备接受任务
- 如果核心线程已满,就会将任务放入阻塞队列中,空闲的核心线程就会自己去阻塞队列中获取任务
- 如果阻塞队列已满,就会直接开启新线程执行,但是最大不超过 maximumPoolSize 数
- 如果超过 maximumPoolSize 数,就会使用拒绝策略拒绝任务,当执行完成后,在指定的 keepAliveTime 时间以后释放 maximumPoolSize - corePoolSize 这些数量的线程
基本概念
当阻塞队列为空时,获取(take)操作是阻塞的;当阻塞队列为满时,添加(put)操作时阻塞的。
在多线程中,所谓阻塞,指在某些情况下挂起线程(即阻塞),一旦条件满足,被挂起的线程又会自动被唤醒。
使用 BlockingQueue 阻塞队列不用手动控制什么时候该被阻塞,什么时候该被唤醒,进而简化了操作。
种类分析
关系:
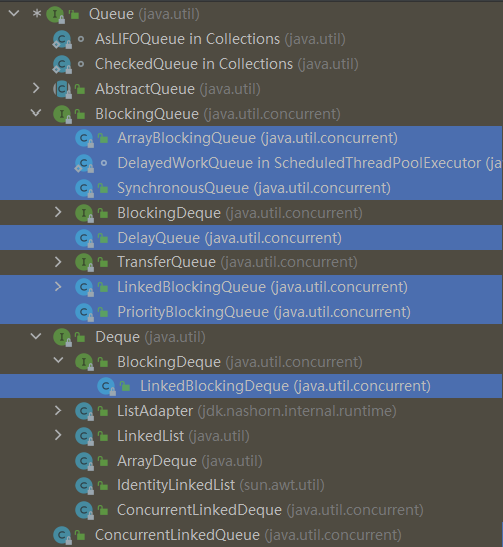
Collection→Queue→BlockingQueue→七个阻塞队列实现类,具体为:
| 类名 | 作用 |
|---|---|
| ArrayBlockingQueue | 由数组构成的有界阻塞队列 |
| LinkedBlockingQueue | 由链表构成的有界阻塞队列,但大小默认值为 Integer.MAX_VALUE |
| PriorityBlockingQueue | 支持优先级排序的无界阻塞队列 |
| DelayQueue | 支持优先级延迟的无界阻塞队列 |
| SynchronousQueue | 不存储元素的阻塞队列,即单个元素的阻塞队列 |
| LinkedTransferQueue | 由链表构成的无界阻塞队列 |
| LinkedBlockingDeque | 由链表构成的双向阻塞队列 |
BlockingQueue 的核心方法:
| 方法类型 | 抛出异常 | 返回布尔 | 阻塞 | 超时 |
|---|---|---|---|---|
| 插入 | add(E e) | offer(E e) | put(E e) | offer(E e, Time time, TimeUnit unit) |
| 移除 | remove() | poll() | take() | poll(Time time, Unit unit) |
| 检查/队首 | element() | peek() | 无 | 无 |
方法类型解释:
- 抛出异常:指阻塞队列满时,再次插入会抛出
IllegalStateException:Queue full异常;阻塞队列空时,再次移除会抛出NoSuchException异常; - 返回布尔:指插入成功返回 true,失败返回 false;移除成功返回队列元素,移除失败返回空;
- 阻塞:指阻塞队列满时,生产者继续往队列里 put 元素,队列会一直阻塞生产者线程,直到队列可用;阻塞队列空时,消费者线程试图从队列里 take 元素,队列会一直阻塞消费者线程,直到队列可用;
- 超时:指阻塞队列满时,队里会阻塞生产者线程一定时间,超过限时后生产者线程会退出;
package java_two;import java.util.concurrent.ArrayBlockingQueue;import java.util.concurrent.BlockingQueue;import java.util.concurrent.TimeUnit;/** * @author parzulpan * @version 1.0 * @date 2021-05 * @project JavaInterview * @package java_two * @desc BlockingQueue */public class BlockingQueueDemo { static BlockingQueue<String> blockingQueue = new ArrayBlockingQueue<>(3); public static void main(String[] args) {// test1();// test2(); try { test3(); } catch (InterruptedException e) { e.printStackTrace(); }// try {// test4();// } catch (InterruptedException e) {// e.printStackTrace();// } } /** 抛出异常 */ public static void test1() { System.out.println(blockingQueue.add("a")); System.out.println(blockingQueue.add("b")); System.out.println(blockingQueue.add("c")); try { // java.lang.IllegalStateException: Queue full System.out.println(blockingQueue.add("x")); } catch (Exception e) { e.printStackTrace(); } System.out.println(blockingQueue.element()); System.out.println(blockingQueue.remove()); System.out.println(blockingQueue.remove()); System.out.println(blockingQueue.remove()); try { // java.util.NoSuchElementException System.out.println(blockingQueue.remove()); } catch (Exception e) { e.printStackTrace(); } try { // java.util.NoSuchElementException System.out.println(blockingQueue.element()); } catch (Exception e) { e.printStackTrace(); } } /** 返回布尔 */ public static void test2() { System.out.println(blockingQueue.offer("a")); System.out.println(blockingQueue.offer("b")); System.out.println(blockingQueue.offer("c")); System.out.println(blockingQueue.offer("d")); System.out.println(blockingQueue.peek()); System.out.println(blockingQueue.poll()); System.out.println(blockingQueue.poll()); System.out.println(blockingQueue.poll()); System.out.println(blockingQueue.poll()); } /** 阻塞 */ public static void test3() throws InterruptedException { new Thread(() -> { try { blockingQueue.put("a"); blockingQueue.put("b"); blockingQueue.put("c"); System.out.println(Thread.currentThread().getName() + " start..."); // 将会阻塞,直到 take blockingQueue.put("d"); System.out.println(Thread.currentThread().getName() + " end..."); } catch (InterruptedException e) { e.printStackTrace(); } }, "t1").start(); TimeUnit.SECONDS.sleep(2); try { blockingQueue.take(); blockingQueue.take(); blockingQueue.take(); blockingQueue.take(); System.out.println(Thread.currentThread().getName() + " start..."); // 将会阻塞 blockingQueue.take(); System.out.println(Thread.currentThread().getName() + " end..."); } catch (InterruptedException e) { e.printStackTrace(); } } /** 超时 */ public static void test4() throws InterruptedException { System.out.println(blockingQueue.offer("a", 2L, TimeUnit.SECONDS)); System.out.println(blockingQueue.offer("b", 2L, TimeUnit.SECONDS)); System.out.println(blockingQueue.offer("c", 2L, TimeUnit.SECONDS)); System.out.println(blockingQueue.offer("d", 2L, TimeUnit.SECONDS)); System.out.println(blockingQueue.peek()); System.out.println(blockingQueue.poll(2L, TimeUnit.SECONDS)); System.out.println(blockingQueue.poll(2L, TimeUnit.SECONDS)); System.out.println(blockingQueue.poll(2L, TimeUnit.SECONDS)); System.out.println(blockingQueue.poll(2L, TimeUnit.SECONDS)); }}
实际应用
生产者消费者模式 - 传统版本
传统模式使用Lock来进行操作,需要手动加锁、解锁
package java_two;import java.util.concurrent.*;import java.util.concurrent.locks.Condition;import java.util.concurrent.locks.Lock;import java.util.concurrent.locks.ReentrantLock;/** * @author parzulpan * @version 1.0 * @date 2021-05 * @project JavaInterview * @package java_two * @desc 生产者消费者模式-传统版本 */public class ProducerConsumerTraditional { private static final ExecutorService THREAD_POOL_EXECUTOR = new ThreadPoolExecutor(2, 10, 10L, TimeUnit.SECONDS, new LinkedBlockingQueue<>(1000), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy()); public static void main(String[] args) { Share share = new Share(); // 生产 THREAD_POOL_EXECUTOR.execute(() -> { for (int i = 0; i < 5; i++) { share.increment(); } }); // 消费 THREAD_POOL_EXECUTOR.execute(() -> { for (int i = 0; i < 5; i++) { share.decrement(); } }); THREAD_POOL_EXECUTOR.shutdown(); }}class Share { private int number = 0; private final Lock lock = new ReentrantLock(); private final Condition condition = lock.newCondition(); public void increment() { lock.lock(); try { // 判断 while (number != 0) { // 不等于 0,等待 condition.await(); } // 处理任务 number++; System.out.println(Thread.currentThread().getName() + " 生产 " + number); // 通知唤醒其他所有线程 condition.signalAll(); } catch (Exception e) { e.printStackTrace(); } finally { lock.unlock(); } } public void decrement() { lock.lock(); try { // 判断 while (number == 0) { // 等于 0,等待 condition.await(); } // 处理任务 number--; System.out.println(Thread.currentThread().getName() + " 消费 " + number); // 通知唤醒其他所有线程 condition.signalAll(); } catch (Exception e) { e.printStackTrace(); } finally { lock.unlock(); } }}
生产者消费者模式 - 阻塞队列版本
使用阻塞队列就不需要手动加锁了
package java_two;import java.util.concurrent.*;import java.util.concurrent.atomic.AtomicInteger;/** * @author parzulpan * @version 1.0 * @date 2021-05 * @project JavaInterview * @package java_two * @desc 生产者消费者模式-阻塞队列版本 */public class ProducerConsumerQueue { private static final ExecutorService THREAD_POOL_EXECUTOR = new ThreadPoolExecutor(2, 10, 10L, TimeUnit.SECONDS, new LinkedBlockingQueue<>(1000), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy()); public static void main(String[] args) { Resource resource = new Resource(new ArrayBlockingQueue<>(10)); THREAD_POOL_EXECUTOR.execute(resource::increment); THREAD_POOL_EXECUTOR.execute(resource::decrement); // 5 秒后停止生产和消费 try { TimeUnit.SECONDS.sleep(5); resource.stop(); System.out.println(Thread.currentThread().getName() + " 停止生产和消费"); } catch (InterruptedException e) { e.printStackTrace(); } THREAD_POOL_EXECUTOR.shutdown(); }}class Resource { private volatile boolean flag = true; private final AtomicInteger atomicInteger = new AtomicInteger(); BlockingQueue<String> blockingQueue; public Resource(BlockingQueue<String> blockingQueue) { this.blockingQueue = blockingQueue; } public void increment() { String data; while (flag) { data = atomicInteger.incrementAndGet() + ""; // 2s 插入一个数据 try { boolean offer = blockingQueue.offer(data, 2L, TimeUnit.SECONDS); if (offer) { System.out.println(Thread.currentThread().getName() + " 生产成功"); } else { System.out.println(Thread.currentThread().getName() + " 生产失败"); } TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } } System.out.println(Thread.currentThread().getName() + " 停止生产"); } public void decrement() { while (flag) { // 2s 移除一个数据 String poll; try { poll = blockingQueue.poll(2L, TimeUnit.SECONDS); if (poll != null && !"".equals(poll)) { System.out.println(Thread.currentThread().getName() + " 消费成功"); } else { System.out.println(Thread.currentThread().getName() + " 消费失败"); flag = false; } } catch (InterruptedException e) { e.printStackTrace(); } } } public void stop() { flag = false; }}
线程池
用于定义等待队列
消息中间件
其底层实现用的是阻塞队列
线程池用过吗?谈谈对 ThreadPoolExecutor 的理解?
基本概念
线程池主要是控制运行线程的数量,将待处理任务放到等待/阻塞队列,然后创建线程执行这些任务。如果超过了最大线程数,则等待。
它的优点有:
- 降低资源消耗
- 提高响应速度
- 提供可管理性
它的继承体系为:
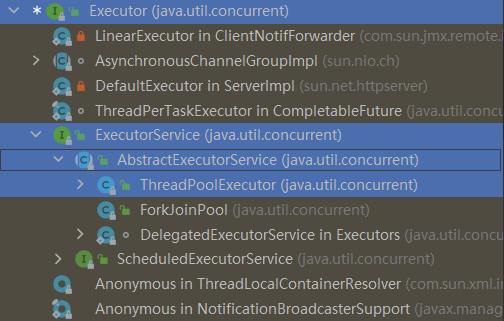
ThreadPoolExcutor 是线程池创建的核心类。类似Arrays、Collections工具类,Executor也有自己的工具类Executors。
但是不推荐使用 工具类Executors 创建线程池。主要的理由有两个:
- 通过 ThreadPoolExecutor 去创建线程池,这样更能明白线程池的运行原理,从而避免资源浪费
- 使用 工具类
Executors静态方法去创建线程池而产生 OOM 问题:- FixedThreadPool 和 SingleThreadPool:允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM
- CachedThreadPool 和 ScheduledThreadPool:允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM
线程池参数
| corePoolSize | 线程池常驻核心线程数 |
|---|---|
| maximumPoolSize | 能够容纳的最大线程数,必须大于等于 1 |
| keepAliveTime | 空闲线程存活时间 |
| unit | 存活时间单位 |
| workQueue | 存放提交但未执行任务的队列 |
| threadFactory | 创建线程的工厂类 |
| handler | 等待队列满后的拒绝策略 |
理解:线程池的创建参数,就像一个银行。corePoolSize 就像银行的 “当值窗口“,比如今天有 2 位柜员在受理 客户请求(任务)。如果超过2个客户,那么新的客户就会在 等候区(等待队列workQueue)等待。当 等候区 也满了,这个时候就要开启 “加班窗口”,让其它3位柜员来加班,此时达到 最大窗口maximumPoolSize,为5个。如果开启了所有窗口,等候区依然满员,此时就应该启动 ”拒绝策略“handler,告诉不断涌入的客户,叫他们不要进入,已经爆满了。由于不再涌入新客户,办完事的客户增多,窗口开始空闲,这个时候就通过keepAlivetTime将多余的3个”加班窗口“取消,恢复到2个”当值窗口“。
底层原理
线程池创建,准备好 corePoolSize 数量的核心线程,准备接受任务
- 如果核心线程已满,就会将任务放入阻塞队列中,空闲的核心线程就会自己去阻塞队列中获取任务
- 如果阻塞队列已满,就会直接开启新线程执行,但是最大不超过 maximumPoolSize 数
- 如果超过 maximumPoolSize 数,就会使用拒绝策略拒绝任务,当执行完成后,在指定的 keepAliveTime 时间以后释放 maximumPoolSize - corePoolSize 这些数量的线程
拒绝策略
当等待队列满时,且达到最大线程数,再有新任务到来,就需要启动拒绝策略。JDK提供了四种拒绝策略,分别是:
- AbortPolicy:默认的策略,直接抛出
RejectedExecutionException异常,阻止系统正常运行。 - CallerRunsPolicy:既不会抛出异常,也不会终止任务,而是将任务返回给调用者。
- DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加入队列中尝试再次提交任务。
- DiscardPolicy:直接丢弃任务,不做任何处理。
也可以自定义拒绝策略,只需要实现 RejectedExecutionHandler 接口即可。
推荐阅读:
生产过程中如何合理的设置线程池参数?拒绝策略怎么配置?
对于 CPU 密集型任务,需要大量的运算,但是没有阻塞,最大线程数可以是 CPU核数(Runtime.getRuntime().availableProcessors())+ 1。对于IO密集型任务,需要大量的 IO,有大量的阻塞,尽量多配点,可以是CPU核数 * 2 或者 CPU核数/(1-阻塞系数), 阻塞系数一般在 0.8~0.9 之间。
对于拒绝策略问题同上。
死锁编码问题以及如何定位分析?
死锁是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力干涉那它们都将无法推进下去。如果系统资源充足,进程的资源请求都能够碍到满足,死锁出现的可能性就很低,否则就会因争夺有限的资源而陷入死锁。
产生死锁主要原因:
- 系统资源不足
- 进程运行推进的顺序不合适
- 资源分配不当
发生死锁的四个条件:
- 互斥条件,线程使用的资源至少有一个不能共享的
- 至少有一个线程必须持有一个资源且正在等待获取一个当前被别的线程持有的资源
- 资源不能被抢占
- 循环等待
解决死锁问题:
- 破坏发生死锁的四个条件之一即可
查看是否死锁工具:
- **jps **指令:
jps -l可以查看运行的 Java 进程 - jstack 指令:
jstack pid可以查看某个 Java 进程的堆栈信息,同时分析出死锁
❯ jps -l65610516 java_two.DeadLockDemo12836 org.jetbrains.jps.cmdline.Launcher14068 D:\Dev\Tools\nacos-server-1.3.2\nacos\target\nacos-server.jar190929956 sun.tools.jps.Jps
❯ jstack 10516// ...Found one Java-level deadlock:============================="Thread B": waiting to lock monitor 0x000001f9316c7ba8 (object 0x000000076b815550, a java.lang.Object), which is held by "Thread A""Thread A": waiting to lock monitor 0x000001f9316c7af8 (object 0x000000076b815560, a java.lang.Object), which is held by "Thread B"Java stack information for the threads listed above:==================================================="Thread B": at java_two.MyTask.run(DeadLockDemo.java:35) - waiting to lock <0x000000076b815550> (a java.lang.Object) - locked <0x000000076b815560> (a java.lang.Object) at java.lang.Thread.run(Thread.java:748)"Thread A": at java_two.MyTask.run(DeadLockDemo.java:35) - waiting to lock <0x000000076b815560> (a java.lang.Object) - locked <0x000000076b815550> (a java.lang.Object) at java.lang.Thread.run(Thread.java:748)Found 1 deadlock.
JVM
谈谈对 JVM 体系结构 的理解?GC 的作用区域是什么?
JVM 的整个体系结构为:
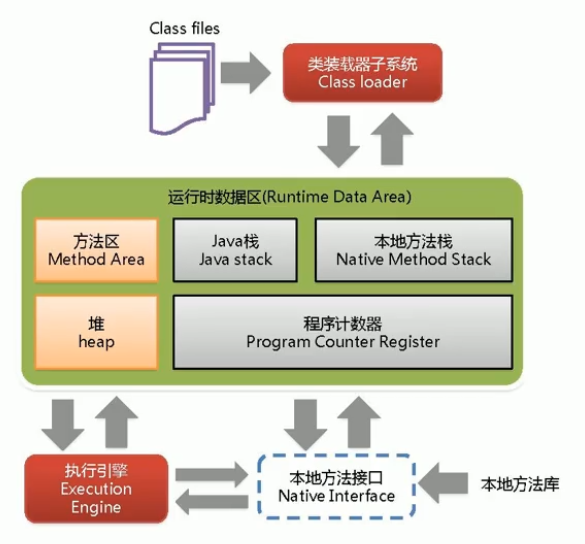
其中 Java 栈、本地方法栈、程序计数器 是线程私有的,而 方法区、堆 是线程共有的。
GC 的作用区域是 方法区、堆。
谈谈对垃圾回收算法的理解?
JVM 垃圾回收时如何确定垃圾?什么是 GC Roots?
简单的说,内存中已经不再被使用的就是垃圾。即确定对象是否存活。
主要有两种方法:
- 引用计数法:给每个对象设置一个计数器,当有地方引用这个对象时,计数器加一;当引用失效的时候,计数器减一;当计数器为零时,JVM 就认为该对象不再被使用。
- 优点:实现简单,效率高
- 缺点:每次对对象赋值时均要维护引用计数器,增加了额外开销;并且很难解决循环引用的问题
- 根搜索法:通过一些
GC Roots对象作为起点,从这些节点开始往下搜索,搜索通过的路径成为引用链,当一个对象没有被GC Roots的引用链连接时,JVM 就认为该对象不再被使用。
GC Roots 就是一组活跃对象的引用。它包括:
- 虚拟机栈(栈帧中的局部变量表)中引用的对象
- 方法区中的类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中 Native 方法引用的对象
有 JVM 调优和参数配置经验吗?如何查看 JVM 系统默认值?
JVM 参数类型:
- 标配参数,比如
-version、-help、-showversion等,几乎不会改变。 - X 参数,比如
-Xint解释执行模式;-Xcomp编译模式;-Xmixed开启混合模式(默认)等,用的很少。 - XX 参数,比如
XmsXmx等,主要用于 JVM 调优,用的很多。
JVM XX 参数
布尔类型:
- 公式:
-XX:+某个属性、-XX:-某个属性,开启或关闭某个功能。 - 例子:
-XX:+/-PrintGCDetails,是否开启 GC 详细信息;-XX:+/-UserSerialGC是否使用串行垃圾回收器
键值类型:
- 公式:
-XX:属性key=值value - 例子:
-XX:Metaspace=128m、-XX:MaxTenuringThreshold=15。
值得注意的是, -Xms 和 -Xmx 十分常见,用于设置初始堆大小和最大堆大小。第一眼看上去,既不像 X 参数,也不像 XX 参数。实际上 -Xms 等价于 -XX:InitialHeapSize ,-Xmx 等价于 -XX:MaxHeapSize。所以 -Xms 和 -Xmx 属于 XX 参数。
JVM 查看参数
查看某个参数:
-
使用
jps -l查看正在运行中的 Java 进程,选择某个进程号 pid。 -
配合
jinfo -flag JVM参数 pid查看它的指定参数信息 -
配合
jinfo -flags pid查看它的所有参数信息> jps -l19280 sun.tools.jps.Jps16040 java_two.JVMParameters22520> jinfo -flag PrintGCDetails 16040-XX:-PrintGCDetails> jinfo -flags 16040Attaching to process ID 16040, please wait...Debugger attached successfully.Server compiler detected.JVM version is 25.291-b10Non-default VM flags: -XX:CICompilerCount=12 -XX:InitialHeapSize=257949696 -XX:MaxHeapSize=4127195136 -XX:MaxNewSize=1375731712 -XX:MinHeapDeltaBytes=524288 -XX:NewSize=85983232 -XX:OldSize=171966464 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseFastUnorderedTimeStamps -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGCCommand line: -javaagent:D:\Dev\Tools\jetbrains-toolbox\apps\IDEA-U\ch-0\211.7142.45\lib\idea_rt.jar=10219:D:\Dev\Tools\jetbrains-toolbox\apps\IDEA-U\ch-0\211.7142.45\bin -Dfile.encoding=UTF-8
查看所有参数:
-
java -XX:+PrintFlagsInitial查看初始默认参数值 -
java -XX:+PrintFlagsFinal查看修改更新参数值,其中=表示默认,:=表示修改过的 -
java -XX:+PrintFlagsFinal -XX:MetaspaceSize=512m HelloWorld运行 Java 命令的同时打印出参数 -
java -XX:+PrintCommandLineFlags打印命令行参数> java -XX:+PrintFlagsInitial[Global flags] intx ActiveProcessorCount = -1 {product} uintx AdaptiveSizeDecrementScaleFactor = 4 {product} uintx AdaptiveSizeMajorGCDecayTimeScale = 10 {product} uintx AdaptiveSizePausePolicy = 0 {product}··· uintx YoungPLABSize = 4096 {product} bool ZeroTLAB = false {product} intx hashCode = 5 {product}>java -XX:+PrintFlagsFinal intx ActiveProcessorCount = -1 {product} uintx AdaptiveSizeDecrementScaleFactor = 4 {product} uintx AdaptiveSizeMajorGCDecayTimeScale = 10 {product}... uintx YoungPLABSize = 4096 {product} bool ZeroTLAB = false {product} intx hashCode = 5 {product}> java -XX:+PrintCommandLineFlags-XX:InitialHeapSize=257905728 -XX:MaxHeapSize=4126491648 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC
用过 JVM 的那些基本配置参数?
Xmx Xms 参数
最大和初始堆大小。最大默认为物理内存的 1/4,初始默认为物理内存的 1/64。
Xss 参数
等价于 -XX:ThreadStackSize,用于设置单个线程栈的大小,系统默认为 0,但是不一定代表栈大小为 0。而是根据操作系统的不同,有不同的值。比如 64 位的 Linux 系统是 1024K,而 Windows 系统依赖于虚拟内存。
Xmn 参数
设置新生代大小,一般不调整。
MetaspaceSize 参数
设置元空间大小。永久代使用的是 JVM 的堆内存,而元空间并在虚拟机中而是使用本机物理内存,所以元空间的大小是受本地内存限制的。
典型使用:-Xms128m -Xmx4096m -Xss1024k -XX:MetaspaceSize=512m -XX:+PrintCommandLineFlags -XX:+PrintGCDetails -XX:+UseSerialGC
PrintGCDetails 参数
输出 GC 详细信息,包括 GC 和 FullGC 信息。
SurvivorRatio 参数
新生代中,Eden Space 和 两个 Survivor Space 的默认比例是 8:1:1,可以通过 -XX:SurvivorRatio=4 改成 4:1:1
即 SurvivorRatio 值就是设置 Eden Space 的比例占多少,Survivor Space 0 和 Survivor Space 1相同。
NewRatio 参数
新生代和老年代的默认比例是 1:2,可以通过 -XX:NewRatio=4 改成 1:4
即 NewRadio 值就是设置老年代的比例占多少。
MaxTenuringThreshold 参数
新生代设置进入老年代的时间,默认是新生代“逃过” 15 次 GC后(任职期限 15 次之后),会进入老年代。可以通过设置 -XX:MaxTenuringThreshold=0 ,则对象不会在新生代分配,会直接进入老年代。
对于年老代比较多的应用,这个值越小,可以提高效率。如果将此值设置为一个较大的值,则年轻代对象会在 Survivor 区进行多次复制,这样可以增加对象在年轻代的存活时间,增加在年轻代即被回收的概率。
谈谈对四大引用的理解?
强引用
使用 new 方法创造出来的对象,默认都是强引用。GC 的时候,就算内存不够,抛出 OOM 也不会回收对象,即死了也不会回收。 因此强引用是造成 Java 内存泄漏的主要原因之一。
对于一个普通的对象,如果没有其他的引用关系,只要超过了引用的作用域或者显式地将相应(强)引用赋值为 null,则一般认为就是可以被垃圾收集了(当然具体回收时机还是要看垃圾收集策略)。
package java_two;/** * @author parzulpan * * 强引用 * VM options: -Xms5m -Xmx5m -XX:+PrintGCDetails */public class StrongReferenceDemo { public static void main(String[] args) { Object o1 = new Object(); // o2 引用赋值 Object o2 = o1; o1 = null; System.gc(); // java.lang.Object@1b6d3586 System.out.println(o2); }}
软引用
需要用 Object.Reference.SoftReference 来显式创建。GC的时候,如果内存够,不回收;内存不够,则回收。常用于内存敏感的应用,比如高速缓存。
package java_two;import java.lang.ref.SoftReference;/** * @author parzulpan * * 软引用 * VM options: -Xms5m -Xmx5m -XX:+PrintGCDetails */public class SoftReferenceDemo { public static void main(String[] args) { memoryEnough(); System.out.println("\n---\n"); memoryUnEnough(); } private static void memoryEnough() { Object o = new Object(); SoftReference<Object> softReference = new SoftReference<>(o); System.out.println(o); System.out.println(softReference.get()); System.out.println(); o = null; System.gc(); System.out.println(o); // java.lang.Object@4554617c System.out.println(softReference.get()); } private static void memoryUnEnough() { Object o = new Object(); SoftReference<Object> softReference = new SoftReference<>(o); System.out.println(o); System.out.println(softReference.get()); System.out.println(); o = null; System.gc(); try { // 堆空间压满 byte[] bytes = new byte[30 * 1024 * 1024]; } catch (Exception e) { e.printStackTrace(); } finally { System.out.println(o); // null System.out.println(softReference.get()); } }}
弱引用 和 WeakHashMap
需要用 Object.Reference.WeakReference 来显式创建。GC的时候,无论内存够不够都回收,也可以用在高速缓存上。
传统的 HashMap 就算 key==null 了,也不会回收键值对。但是如果是 WeakHashMap,一旦内存不够用时,且 key==null 时,会回收这个键值对。
package java_two;import java.lang.ref.WeakReference;/** * @author parzulpan * * 弱引用 * VM options: -Xms5m -Xmx5m -XX:+PrintGCDetails */public class WeakReferenceDemo { public static void main(String[] args) { Object o = new Object(); WeakReference<Object> weakReference = new WeakReference<>(o); System.out.println(o); System.out.println(weakReference.get()); System.out.println("\n---\n"); o = null; System.gc(); System.out.println(o); // null System.out.println(weakReference.get()); }}
package java_two;import java.util.HashMap;import java.util.WeakHashMap;/** * @author parzulpan * * WeakHashMap 和 HashMap * VM options: -Xms5m -Xmx5m -XX:+PrintGCDetails */public class WeakHashMapDemo { public static void main(String[] args) { testHashMap(); System.out.println("\n---\n"); testWeakHashMap(); } private static void testHashMap() { HashMap<Integer, String> map = new HashMap<>(); Integer key = 1024; String value = "HashMap"; map.put(key, value); System.out.println(map); key = null; // {1024=HashMap} System.out.println(map); System.gc(); // {1024=HashMap} 1 System.out.println(map + "\t" + map.size()); } private static void testWeakHashMap() { WeakHashMap<Integer, String> map = new WeakHashMap<>(); Integer key = 1024; String value = "WeakHashMap"; map.put(key, value); System.out.println(map); key = null; // {1024=WeakHashMap} System.out.println(map); System.gc(); // {} 0 System.out.println(map + "\t" + map.size()); }}
软、弱引用的应用场景
假如有一个应用需要读取大量的本地图片:
- 如果每次读取图片都从硬盘读取,则会严重影响性能
- 如果一次性全部加载到内存中,则可能造成内存溢出
使用软、弱引用可以解决这个问题,设计思路:
- 使用 HashMap 来保存 图片的路径 和 相应图片对象关联的软引用 之间的映射关系
- 在内存不足时,JVM 会自动回收这些缓存图片对象所占的空间,从而有效地避免了 OOM 的问题
- 定义:
Map<String, SoftReference<Bitmap>> imageCache = new HashMap<String, SoftReference<Bitmap>>();
虚引用 和 引用队列
软引用和弱引用可以通过 get() 方法获得对象,但是虚引用不行。虚引用即形同虚设,在任何时候都可能被 GC,不能单独使用,必须配合引用队列(ReferenceQueue)来使用。
设置虚引用的唯一目的,就是在这个对象被回收时,收到一个通知以便进行后续操作,有点像 Spring 的后置通知。
弱引用、虚引用被回收后,会被放到引用队列里面,通过 poll 方法可以得到。
package java_two;import java.lang.ref.PhantomReference;import java.lang.ref.ReferenceQueue;/** * @author parzulpan * * 虚引用 * VM options: -Xms5m -Xmx5m -XX:+PrintGCDetails */public class PhantomReferenceDemo { public static void main(String[] args) throws InterruptedException { Object o = new Object(); ReferenceQueue<Object> referenceQueue = new ReferenceQueue<>(); PhantomReference<Object> phantomReference = new PhantomReference<>(o, referenceQueue); System.out.println(o); // null System.out.println(phantomReference.get()); // null System.out.println(referenceQueue.poll()); System.out.println("\n---\n"); o = null; System.gc(); Thread.sleep(500); System.out.println(o); // null System.out.println(phantomReference.get()); // java.lang.ref.PhantomReference@4554617c System.out.println(referenceQueue.poll()); }}
谈谈对 OOM 的理解?
OOM - Java heap space
JVM 的堆内存不够,造成堆内存溢出。一般原因有两点
- JVM 的堆内存设置太小,可以通过参数
-Xms和-Xmx来调整。 - 代码中创建了大量对象,并且长时间不能被 GC 回收(存在被引用)。
package java_two;import java.util.Random;/** * @author parzulpan * * OOM - Java heap space * VM options: -Xms5m -Xmx5m -XX:+PrintGCDetails */public class OOMJavaHeapSpace { public static void main(String[] args) { String str = "oom"; while (true) { str += str + new Random().nextInt(111111) + new Random().nextInt(999999); // System.out.println(str); } }}
OOM - GC overhead limit exceeded
我们知道 GC 的时候会产生 “Stop the World”,理论上 STW 越小越好,正常情况下 GC 操作只会占到很少的一部分时间。但是如果用到超过 98% 的时间去做 GC 操作,而且效果很差,JVM 就会报错。
package java_two;import java.util.ArrayList;import java.util.List;/** * @author parzulpan * * OOM - GC overhead limit exceeded * VM options: -Xms10m -Xmx10m -XX:MaxDirectMemorySize=5m -XX:+PrintGCDetails */public class OOMGCOverhead { public static void main(String[] args) { int i = 0; List<String> list = new ArrayList<>(); try { while (true) { list.add(String.valueOf(++i).intern()); } } catch (Exception e) { System.out.println(" i = " + i); e.printStackTrace(); throw e; } }}
OOM - GC Direct buffer memory
在写 NIO 程序的时候,会用到 ByteBuffer 来读取和存入数据。与 Java 堆的数据不一样,ByteBuffer 使用 native方法,直接在 堆外分配内存。当堆外内存(也即本地物理内存)不够时,就会抛出这个错误。
package java_two;import sun.misc.VM;import java.nio.ByteBuffer;/** * @author parzulpan * * OOM - GC Direct buffer memory * VM options: -Xms10m -Xmx10m -XX:MaxDirectMemorySize=5m -XX:+PrintGCDetails */public class OOMGCDirect { public static void main(String[] args) { System.out.println("MaxDirectMemorySize = " + (VM.maxDirectMemory() / 1024 / 1024) + "M"); try { Thread.sleep(300); } catch (InterruptedException e) { e.printStackTrace(); } // 分配 OS 本地内存,不属于 GC管辖范围,由于不需要内存拷贝所有速度相对较快 ByteBuffer byteBuffer = ByteBuffer.allocateDirect(6 * 1024 * 1024); }}
OOM - unable to create new native thread
在高并发场景,如果创建超过了系统默认的最大线程数,就会抛出这个错误。Linux 单个进程默认不能超过 1024 个线程。
解决方法:
- 要么降低程序线程数
- 要么修改系统最大线程数,修改命令
vi /etc/security/limits.d/20-nproc.conf
package java_two;/** * @author parzulpan * * OOM - unable to create new native thread * VM options: -XX:+PrintGCDetails */public class OOMUnableCreateNewNativeThread { public static void main(String[] args) { for (int i = 0; i < Integer.MAX_VALUE; i++) { new Thread(() -> { try { Thread.sleep(Integer.MAX_VALUE); } catch (InterruptedException e) { e.printStackTrace(); } }, "" + i).start(); } }}
OOM - Metaspace
JDK1.8 之后,永久代被元空间替代,它们最大的区别是永久代使用的是 JVM 的堆空间,而元空间使用的是本机物理内存。因此,默认情况下,元空间的大小仅受本地内存限制。当本地内存不够,即元空间内存不够,就会抛出这个错误。
元空间主要存放:
- 虚拟机加载的类信息
- 常量池
- 静态变量
- 即时编译的代码
模拟 Metaspace 空间溢出,可以借助 CGLib 直接操作字节码运行时不断生成类往元空间灌,类占据的空间总是会超过 Metaspace 指定的空间大小的。
package java_two;import net.sf.cglib.proxy.Enhancer;import net.sf.cglib.proxy.MethodInterceptor;/** * @author parzulpan * * OOM - Metaspace * VM options: -XX:MetaspaceSize=10m -XX:MaxMetaspaceSize=10m -XX:+PrintGCDetails */public class OOMMetaspace { /** 静态类 */ static class OOMObject {} public static void main(final String[] args) { int i = 0; try { while (true) { ++i; // 使用 Spring 的动态字节码技术 Enhancer enhancer = new Enhancer(); enhancer.setSuperclass(OOMObject.class); enhancer.setUseCache(false); enhancer.setCallback((MethodInterceptor) (o, method, objects, methodProxy) -> methodProxy.invokeSuper(o, args)); enhancer.create(); } } catch (Throwable throwable) { System.out.println("循环 " + i + " 次发生OOM - Metaspace"); } finally { ; } }}
谈谈对垃圾收集器的理解?
GC 算法(引用计数/复制/标清/标整)是内存回收的方法论,而垃圾收集器就是算法的落地实现。
垃圾收集器种类
Java 8 将垃圾收集器分为四类:
- 串行收集器 Serial:为单线程环境设计且只使用一个线程进行 GC,会暂停所有用户线程,不适用服务器。就像去餐厅吃饭,只有一个清洁工在打扫卫生。
- 并行收集器 Parrallel:为多线程环境设计且使用多个线程并行的进行 GC,适用于科学计算、大数据等交互性不敏感的场合。就像去餐厅吃饭,有多个清洁工在同时打扫卫生。
- 并发收集器 ConcMarkSweep(CMS):用户线程和 GC 线程同时执行(不一定是并行),不会暂停用户线程,适用于互联网高并发等对响应时间敏感的场合。就像去餐厅吃饭,有多个清洁工在同时打扫卫生,并且同时也有人在就餐。
- G1 收集器:对内存的划分与前面 3 种很大不同,将堆内存分割成不同的区域,然后并发地进行垃圾回收。
默认收集器主要有 Serial、Parallel、CMS、ParNew、ParallelOld、G1,还有一个快被淘汰的 SerialOld。
可以通过 java -XX:+PrintCommandLineFlags 查看默认使用的垃圾收集器,Java8 默认使用-XX:+UseParallelGC。
> java -XX:+PrintCommandLineFlags-XX:InitialHeapSize=257905728 -XX:MaxHeapSize=4126491648 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC
GC 约定参数说明
- DefNew:Default New Generation
- Tenured:Old
- ParNew:Parallel New Generation
- PSYoungGen:Parallel Scavenge
- ParOldGen:Parallel Old Generation
Server/Client 模式分别是什么意思?
-
使用范围:一般使用 Server 模式,Client 模式基本不会使用
-
操作系统
- 32 位的 Windows 操作系统,不论硬件如何都默认使用 Client 的 JVM 模式
- 32 位的其它操作系统,2G 内存同时有 2 个 CPU 以上用 Server 模式,低于该配置还是 Client 模式
- 64 位只有 Server 模式
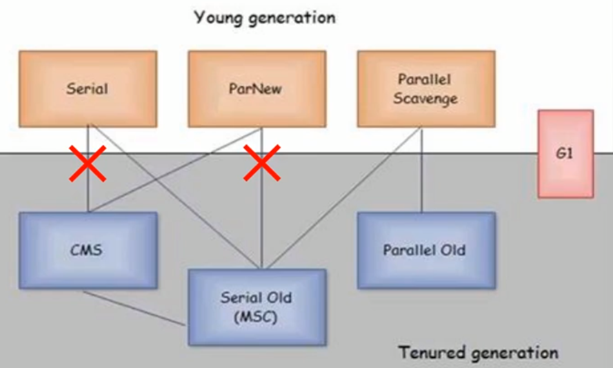
七大垃圾收集器
Serial、Parallel Scavenge(Parallel)、ParNew 适用于回收新生代,SerialOld、ParallelOld、CMS 适用于回收老年代,而 G1 既适用于回收新生代,也适用于回收老年代。体系结构为:
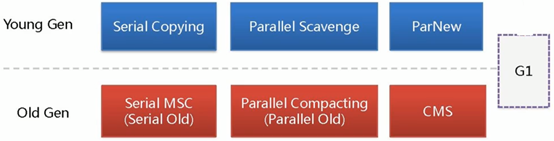
其中连线的推荐搭配组合使用,例如新生代用 Serial,老年代用 SerialOld
红叉的不推荐搭配组合使用,比如新生代用 Serial,而老年代用 CMS
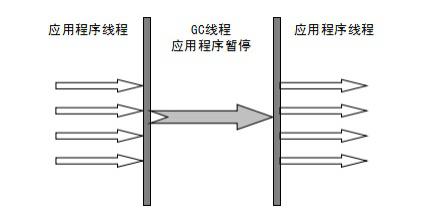
Serial 收集器
-Xms10m -Xmx10m -XX:+PrintGCDetails -XX:+PrintCommandLineFlags -XX:+UseSerialGC
年代最久远,是 Client VM 模式下的默认新生代收集器,采用复制算法。
- 优点:单个线程收集,没有线程切换开销,拥有最高的单线程 GC 效率。
- 缺点:收集的时候会暂停用户线程。
使用 -XX:+UseSerialGC 可以显式开启,开启后默认使用 Serial+SerialOld 的组合。
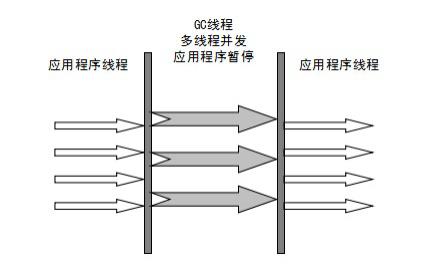
ParNew 收集器
-Xms10m -Xmx10m -XX:+PrintGCDetails -XX:+PrintCommandLineFlags -XX:+UseParNewGC
也就是 Serial 的多线程版本,GC 的时候不再是一个线程,而是多个,是 Server VM 模式下的默认新生代收集器,采用复制算法。
使用 -XX:+UseParNewGC 可以显式开启,开启后默认使用 ParNew+SerialOld 的组合。但是由于 SerialOld 已经过时,所以建议配合CMS使用。
Parallel Scavenge(Parallel) 收集器
-Xms10m -Xmx10m -XX:+PrintGCDetails -XX:+PrintCommandLineFlags -XX:+UseParallelGC
ParNew收集器仅在新生代使用多线程收集,老年代默认是 SerialOld,所以是单线程收集。而 Parallel Scavenge 在新、老两代都采用多线程收集。Parallel Scavenge 还有一个特点就是吞吐量优先收集器,可以通过自适应调节,保证最大吞吐量(比如程序运行 100 分钟,垃圾收集时间 1 分钟,吞吐量就是 99%),采用复制算法。
使用 -XX:+UseParallelGC 可以显式开启, 开启后默认使用 Parallel+ParallelOld 的组合。
其它参数,比如 -XX:ParallelGCThreads=N 可以选择 N 个线程进行GC,-XX:+UseAdaptiveSizePolicy 使用自适应调节策略。当 CPU 核数大于 8 时,N = 5/8,否则 N = 实际核数。
SerialOld 收集器
-Xms10m -Xmx10m -XX:+PrintGCDetails -XX:+PrintCommandLineFlags -XX:+UseParallelOldGC
Serial的老年代版本,采用标准压缩/整理算法。JDK1.5 之前跟Parallel Scavenge配合使用,现在已经不用了,它作为 CMS 的后备收集器。
ParallelOld 收集器
Parallel 的老年代版本,JDK1.6 之前,新生代用 Parallel 而老年代用 SerialOld,只能保证新生代的吞吐量。JDK1.8 后,老年代改用 ParallelOld。采用标准压缩/整理算法。
使用 -XX:+UseParallelOldGC 可以显式开启, 开启后默认使用 Parallel+ParallelOld 的组合。
CMS 收集器
-Xms10m -Xmx10m -XX:+PrintGCDetails -XX:+PrintCommandLineFlags -XX:+UseConcMarkSweepGC
是一种以获得最短 GC 停顿为目标的收集器,适用于互联网或者 B/S 系统的服务器上,这类应用尤其重视服务器的响应速度,希望停顿时间最短。它是 G1 收集器出来之前的首选收集器,采用标准清除算法。在 GC 的时候,会与用户线程并发执行,不会停顿用户线程。但是在 标记 的时候,仍然会 STW。
使用 -XX:+UseConcMarkSweepGC 可以显式开启,开启后默认使用 ParNew+CMS + SerialOld 的组合。SerialOld 将作为 CMS 出错的后备收集器。
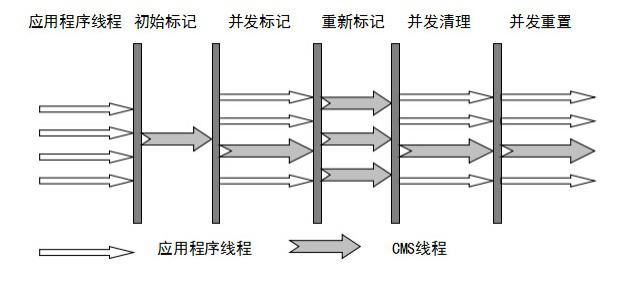
由上图,大致过程为:
- 初始标记 CMS Initial mark:只是标记一下 GC Roots 能直接关联的对象,速度很快,需要 STW
- 并发标记 CMS concurrent mark:主要的标记过程,标记全部对象,和用户线程一起工作,不需要 STW
- 重新标记 CMS remark:修正并发标记阶段出现的变动,需要 STW
- 并发清除 CMS concurrent sweep:清理垃圾,和用户线程一起工作,不需要 STW
优缺点:
- 优点:停顿时间少,响应速度快,用户体验好
- 缺点:使用标准清除算法会产生内存碎片;由于需要并发工作,会占用系统线程资源;标记时用户线程也在工作,无法有效处理新产生的垃圾
G1 收集器
-Xms10m -Xmx10m -XX:+PrintGCDetails -XX:+PrintCommandLineFlags -XX:+UseG1GC
之前的收集器都有三个区域(新生代、老年代、元空间),而 G1 收集器只有 G1 区和元空间。其中 G1 区不分为新生、老年代,而是一个一个 区域(Region),每个区域既可能包含新生代,也可能包含老年代。整体上采用标准压缩/整理算法,局部上采用复制算法,不会产生内存碎片。
G1 收集器,是一款面向服务端应用的收集器,它既可以提高吞吐量,又可以减少 GC 时间。最重要的是 STW 可控,增加了预测机制,可以让用户指定停顿时间。
使用 -XX:+UseG1GC 可以显式开启,还有 -XX:G1HeapRegionSize=n、-XX:MaxGCPauseMillis=n 等参数可指定。
参数说明:
-XX:G1HeapRegionSize=n:设置的 G1 区域的大小。值是 2 的幂,范围是 1MB 到 32MB。目标是根据最小的 Java 堆大小划分出约 2048 个区域。-XX:MaxGCPauseMillis=n:最大 GC 停顿时间,这是个软目标,JVM将尽可能(但不保证)停顿小于这个时间。-XX:InitiatingHeapOccupancyPercent=n:堆占用了多少的时候就触发 GC,默认为45。-XX:ConcGCThreads=n:并发 GC 使用的线程数。-XX:G1ReservePercent=n:设置作为空闲空间的预留内存百分比,以降低目标空间溢出的风险,默认值是 10%。
同 CMS 类似,大致过程为:
- 初始标记:只标记 GC Roots 能直接关联到的对象
- 并发标记:进行 GC Roots Tracing 的过程
- 最终标记:修正并发标记期间,因程序运行导致标记发生变化的那一部分对象
- 筛选回收:根据时间来进行价值最大化的回收
优点:
- 并行和并发:充分利用多核 CPU,尽量缩短 STW
- 分代收集:虽然还保留着新、老两代的概念,但物理上不再隔离,而是融合在Region中
- 空间整合:
G1整体上看是标准整理算法,但在局部看又是复制算法,不会产生内存碎片 - 可预测停顿:用户可以指定一个 GC 停顿时间,
G1收集器会尽量满足。
生产过程中如何合理的选择垃圾收集器
- 单 CPU 或者小内存,单机程序
- -XX:+UseSerialGC
- 多 CPU,需要最大的吞吐量,如后台计算型应用
- -XX:+UseParallelGC(这两个相互激活)
- -XX:+UseParallelOldGC
- 多 CPU,追求低停顿时间,需要快速响应,如高并发互联网应用
- -XX:+UseConcMarkSweepGC(这两个相互激活)
- -XX:+ParNewGC
微服务结合 JVM 调优
启动微服务时,同时配置 JVM 调优参数:java -server VM options -jar jar/war包名。
如果生产环境服务器变慢,你有什么诊断思路和性能评估手段?
常用组合命令:
- 查看整体性能:
top- 查看
%CPU和%MEM数值 - 查看
load average数值,它表示系统负载,即任务队列的平均长度。 三个数值分别为 1 分钟、5 分钟、15 分钟前到现在的平均值。如果 三个值之和/3 * 100 % > 60 %,说明系统在超负荷运转 - 整体性能精简版命令
uptime
- 查看
- 查看 CPU:
vmstat -n n1 n2- n1 参数代表采样的时间间隔(单位为秒),n2 参数代表采样的次数
- 输出结果的 procs 项说明
- r:运行和等待的 CPU 时间片的进程数,原则上 1 核的 CPU 的运行队列不要超过 2,整个系统的运行队列不超过总核数的 2 倍,否则代表系统压力过大
- b:等待资源的进程数,比如正在等待磁盘 I/O、网络 I/O等
- 输出结果的 cpu 项说明
- us:用户进程消耗 CPU 时间百分比,us 值越高,则用户进程消耗 CPU 时间越多,如果长期大于 50%,则需要优化程序
- sy:内核进程消耗的 CPU 时间百分比
- us + sy 参考值为 80%,如果 us + sy 大于80%,说明可能存在 CPU 不足
- id:处于空闲的 CPU 时间百分比
- wa:系统等待 IO 的 CPU 时间百分比
- st:来自于一个虚拟机偷取的 CPU 时间百分比
- 查看 CPU:
mpstat -P ALL n1- 查看所有 cpu 核信息,n1 参数代表采样的时间间隔(单位为秒)
- 查看 CPU:
pidstat -r n1 -p 进程编号- 每个进程使用 cpu 的用量信息,先用
ps -ef | grep java查出相关进程,n1 参数代表采样的时间间隔(单位为秒)
- 每个进程使用 cpu 的用量信息,先用
- 查看内存:
free -m- 应用程序可用内存 / 系统物理内存 > 70%,则内存充足
- 应用程序可用内存 / 系统物理内存 < 20%,则内存不足,需要增加内存
- 20% < 应用程序可用内存/系统物理内存 < 70%,则内存基本够用
- 查看磁盘:
df -h- 查看磁盘剩余空间数
- 查看磁盘 IO:
iostat -xdk n1 n2- 输出结果的 rkB/s 项:每秒读取数据量 kB
- 输出结果的 wkB/s 项:每秒写入数据量kB;
- rkB/s、wkB/s 根据系统应用不同会有不同的值,但有规律遵循,长期、超大数据读写,肯定不正常,需要优化程序读取
- 输出结果的 svctm 项:lO 请求的平均服务时间,单位毫秒;
- 输出结果的 await 项:l/O 请求的平均等待时间,单位毫秒;值越小,性能越好;
- 输出结果的 svctm 的值与 await 的值很接近,表示几乎没有 IO 等待,磁盘性能好。
- 如果 await 的值远高于 svctm 的值,则表示 IO 队列等待太长,需要优化程序或更换更快磁盘。
- 输出结果的 util 项:一秒中有百分几的时间用于 I/O 操作。接近 100% 时,表示磁盘带宽跑满,需要优化程序或者增加磁盘;
- 查看网络 IO:
ifstat
如果生产环境 CPU 占用过高,谈谈你的分析思路和定位?
先用 top 找到 CPU 占用最高的进程 pid,然后使用 ps -mp pid -o THREAD,tid,time,得到该进程里面占用最高的线程。这个线程是 10 进制的,将其转换成 16 进制,然后 jstack pid | grep tid 可以定位到具体哪一行导致了占用过高。
> top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 14825 root 10 -10 146292 25420 6408 S 1.0 1.4 64:47.30 AliYunDun
# ps 代表 process status 进程状态
# -A 显示有关其他用户进程的信息,包括那些没有控制终端的进程的信息
# -e 与 -A 相同
# -f 显示 uid,pid,父 pid,最近的 CPU 使用率,进程开始时间,控制 tty,已用的 CPU 使用率以及关联的命令
> ps -ef | grep 14825
root 14825 1 1 May22 ? 01:04:49 /usr/local/aegis/aegis_client/aegis_10_95/AliYunDun
root 18852 10331 0 00:07 pts/0 00:00:00 grep --color=auto 14825
# -m 显示所有的线程
# -p pid 进程使用 cpu 的时间
# -o 该参数后是用户自定义格式
> ps -mp 14825 -o THREAD,tid,time
USER %CPU PRI SCNT WCHAN USER SYSTEM TID TIME
root 1.5 - - - - - - 01:04:51
root 0.0 29 - hrtime - - 14825 00:03:31
> printf "%x\n" 14825
39e9
> jstack 14825 | grep 39e9
JDK 自带的 JVM 性能调优和监控工具用过那些?
jps
JVM Process Status Tool,显示指定系统内所有的 HotSpot 虚拟机进程。Java 版的 ps -ef 查看所有 JVM 进程。
格式:jps [ option ] [ hostid ]
示例:jps -l -v
主要选项:
-q只输出 LVMID/PID,省略主类的名称-m输出虚拟机进程启动时传递给主类main()函数的参数-l输出主类的全名,如果进程执行的是 Jar 包,输出 Jar 路径-v输出虚拟机进程启动时的 JVM 参数
jstat
JVM Statistics Monitoring Tool,用于收集 HotSpot 虚拟机各方面的运行数据,它是统计信息监视工具。
格式:jstat [ option vmid [ interval [ s | ms ] [ count ] ] ]
示例:jstat -gc 2739 2000 3
主要选项:
-class监视类装载、卸载数量、总空间以及类装载所耗费的时间-gc监视 Java 堆状况,包括两个 Survivor 区、Eden 区、老年代、元空间等的容量、已用空间、MinorGC 次数和耗时、FullGC 次数和耗时、总GC 时间合计等信息-gccapacity监视内容与-gc基本相同,但输出主要关注 Java 堆各个区域使用到的最大、最小空间-gcutil监视内容与-gc基本相同,但输出主要关注已使用空间占总空间的百分比-gccause监视内容与-gcutil基本相同,但是会额外输出导致上一次 GC 产生的原因-gcnew-gcnewcapacity-gcold-gcoldcapacity-compiler输出 JIT 编译器编译过的方法、耗时等信息-printcompilation输出已经被 JIT 编译的方法
jstack
Stack Trace for Java,显示虚拟机的线程快照。Java 堆栈跟踪工具,查看 JVM 中运行线程的状态,比较重要。可以定位 CPU 占用过高位置,定位死锁位置。
格式:jstack [option] vmid
示例:jstack -l -m -F 2739
主要选项:
-l除堆栈外,显示关于锁的附加信息-m如果调用到本地方法的话,可以显示 C/C++ 的堆栈-F当正常输出的请求不被响应时,强制输出线程堆栈
jinfo
Configuration Info for Java,显示虚拟机配置信息。查看 JVM 的运行环境参数,比如默认的 JVM 参数等。
格式: jinfo [ option ] pid
示例:jinfo -flags 2739
jmap
Memory Map for Java,生成虚拟机的内存转储快照(heapdump),它是 JVM 内存映像工具。
格式:jmap [ option ] vmid
示例:jmap -dump:format=b,file=jmaptest.dump -F 2739
主要选项:
- -dump 生成Java堆转储快照。格式为:-dump:[ live, ] format=b, file=, 其中live子参数说明是否只 dump 出存活的对象
- -finalizerinfo 显示在 F-Queue 中等待 Finalizer 线程执行 finalize 方法的对象,只在 Linux/Solaris 平台下有效
- -heap 显示 Java 堆详细信息,如使用哪种回收器、参数配置、分代状况等,只在 Linux/Solaris 平台下有效
- -histo 显示堆中对象统计信息,包括类、实例数量、合计容量
- -permstat 以 ClassLoader 为统计口径显示永久代内存状态,只在 Linux/Solaris 平台下有效
- -F 当虚拟机进程对 -dump 选项没有响应时,可使用这个选项强制生成 dump 快照,只在Linux/Solaris平台下有效
jhat
JVM Heap Analysis Tool,用于分析 heapdump 文件,它会建立一个 HTTP/HTML 服务器,让用户可以在浏览器上查看分析结果。在实际工作中,用它比较少。因为分析工作比较消耗服务器资源并且该功能相对简陋,推荐使用 VisualVM 或者 其他专业工具。
格式:jhat jmap_file
示例:jhat jmaptest.dump
JConsole
JConsole ( Java Monitoring and Management Console ) 是—种基于 JMX 的可视化监视管理工具。它管理部分的功能是针对 JMX MBean 进行管理,MBean可以使用代码、中间件服务器的管理控制台或者所有符合 JMX 规范的软件进行访问。可以进行内存监控、线程监控等。
JVisualVM
VisualVM(All-in-One Java Troubleshooting Tool) 是到目前为止随 JDK 发布的功能最强大的运行监视和故障处理程序,并且可以预见在未来一段时间内都是官方主力发展的虚拟机故障处理工具。
官方在 VisualVM 的软件说明中写上了 “All-in-One” 的描述字样,预示着它除了运行监视、故障处理外,还提供了很多其他方面的功能。
NIO
Linux
MQ
Redis
Spring
Netty&RPC
网络
数据库
微服务
项目
总结
蚂蚁花呗面试题
-
Java 容器有哪些?哪些是同步容器,哪些是并发容器?
-
ArrayList 和 LinkedList 的插入和访问的时间复杂度?
-
Java 反射原理,注解原理?
-
新生代分为几个区?使用什么算法进行垃圾回收?为什么使用这个算法?
-
HashMap 在什么情况下会扩容,或者有哪些操作会导致扩容?
-
HashMap push() 的执行过程?
-
HashMap 检测到 hash 冲突后,将元素插入在链表的末尾还是开头?
-
JDK1.8 还采用了红黑树,讲讲红黑树的特性,为什么人家一定要用红黑树而不是 AVL、B 树之类的?
-
Https 和 Http 区别,有没有用过其他安全传输手段?
-
线程池的工作原理,几个重要参数,然后给了具体几个参数分析线程池会怎么做?阻塞队列的作用是什么?
-
Linux 怎么查看系统负载情况?
-
请详细描述 SpringMVC 处理请求的全流程?Spring 一个 bean 装配的过程?
-
讲一讲 AtomicInteger,为什么要用 CAS 而不是 synchronized?
-
自我介绍、工作经历、技术栈?
-
项目中你学到了什么技术?
-
微服务划分的粒度?
-
微服务的高可用怎么保证的?
-
常用的负载均衡,该怎么用,你能说下吗?
-
网关能够为后端服务带来哪些好处?
-
Spring Bean 的生命周期
-
HashSet 是不是线程安全的?为什么不是线程安全的?
-
Java 中有哪些线程安全的 Map?
-
Concurrenthashmap 是怎么做到线程安全的?
-
HashTable 你了解过吗?
-
如何保证线程安全问题?
-
synchronized、lock 异同?
-
volatile 的原子性问题?为什么 i++ 这种不支持原子性?从计算机原理的设计来讲下不能保证原子性的原因?
-
谈谈 happens before 原则?
解析:由 volatile 关键字引出的。Java 内存模型(JMM)的三个特征:原子性、可见性、有序性。volatile 和 synchronized 和 Lock 都可以保证有序性。但是 JMM 也具备一些先天的有序性,即不需要通过任何手动也可以保证有序性,这通常被称为 happens before 原则。主要有:
- 程序顺序规则:一个线程中的每个操作,happens-before 于该线程中的任意后续操作。
- 监视器锁规则:对一个线程的解锁,happens-before 于随后对这个线程的加锁。
- volatile 变量规则:对一个 volatile 域的写,happens-before 于后续对这个 volatile 域的读。如果一个线程先去写一个变量,另外一个线程再去读,那么写入操作一定在读操作之前。
- 传递性规则:如果 A happens-before B,且 B happens-before C,那么 A happens-before C。
- start() 规则: 如果线程 A 中执行 start线程B 操作, 那么A线程的 start线程B happens-before 于 B 中的任意操作。
- join() 规则:如果线程 A 执行 join线程B 操作并且成功返回,那么线程 B 中的任意操作 happens-before 于线程 A 从 join线程B 操作并且成功返回。
- interrupt() 规则:
- finalize() 规则:
-
CAS 操作
-
公平锁和非公平锁
-
Java 读写锁
-
读写锁设计主要解决什么问题?
美团面试题
- 最近做的比较熟悉的项目是哪个,画一下项目技术架构图?
- JVM 老年代和新生代的比例?
- YGC 和 FGC 发生的具体场景?
- jstack,jmap,jutil 分别的意义?如何线上排查 JVM 的相关问题?
- 线程池的构造类的方法的 5 个参数的具体意义?
- 单机上一个线程池正在处理服务时如果忽然断电怎么办?正在处理和阻塞队列里的请求怎么处理?
- 使用无界阻塞队列会出现什么问题?接口如何处理重复请求?
百度面试题
- 介绍一下集合框架?
- hashmap hastable 底层实现什么区别?hashtable 和 concurrenthashtable 呢?
- hashmap 和 treemap 什么区别?底层数据结构是什么?
- 线程池用过吗?都有什么参数?底层如何实现的?
- synchronized 和 Lock 有什么区别?synchronized 什么情况是对象锁?什么情况是全局锁?为什么?
- ThreadLocal 是什么底层如何实现?写一个例子?
- volatile 的工作原理?
- CAS 知道吗?如何实现的?
- 请用至少四种写法写一个单例模式?
- 请介绍一下 JVM 内存模型?用过什么垃圾回收器?线上发送频繁 full gc 如何处理?CPU使用率过高怎么办?如何定位问题?如何解决?说一下解决思路和处理方法?
- 知道字节码吗?字节码都有哪些?
Integer x =5, int y =5,比较x =y都经过哪些步骤?讲讲类加载机制?都有哪些类加载器?这些类加载器都加载哪些文件? - 手写一下类加载 Demo?
- 知道 osgi 吗?它是如何实现的?
- 请问你做过哪些 JVM 优化?使用什么方法达到什么效果?
classforName(“java.lang.String”)和String classgetClassLoader() LoadClass(“java.lang.String”)有什么区别?
今日头条面试题
- HashMap 如果一直 put 元素会怎么样? hashcode 全都相同如何?
- ApplicationContext 的初始化过程?
- GC 用什么收集器?收集的过程如何?哪些部分可以作为 GC Root?
- volatile 关键字,指令重排序有什么意义 ?synchronied 怎么用?
- Redis 数据结构有哪些?如何实现 sorted set?
- 并发包里的原子类有哪些?怎么实现?
- MySQL 索引是什么数据结构? B tree 有什么特点?优点是什么?
- 慢查询怎么优化?
京东金融面试题
- Dubbo超时重试?Dubbo 超时时间设置?
- 如何保障请求执行顺序?
- 分布式事务与分布式锁(扣款不要出现负数)?
- 分布式 Session 设置?
- 执行某操作,前 50 次成功,第 51 次失败,a 全部回滚,b 前 50 次提交,第51次抛异常,a b 场景分别如何设计?
- Spring 的传播特性?
- Zookeeper 有那些作用?
- JVM 内存模型?
- 数据库的垂直和水平拆分?
- MyBatis 如何分页?如何设置缓存?MySQL 分页?

