


hadoop的运行机制
如要了解hadoop的运行机制过程,
需要先了解几个概念:
mapreduce中概念:
1、首先用户程序(JobClient)提交了一个job,job的信息会发送到Job Tracker,Job Tracker是Map-reduce框架的中心,他需要与集群中的机器定时通信heartbeat,需要管理哪些程序应该跑在哪些机器上,需要管理所有job失败、重启等操作。
2、TaskTracker是Map-Reduce集群中每台机器都有的一个部分,他做的事情主要是监视自己所在机器的资源情况。
3、TaskTracker同时监视当前机器的tasks运行状况。TaskTracker需要把这些信息通过heartbeat发送给JobTracker,JobTracker会搜集这些信息以给新提交的job分配运行在哪些机器上。
yarn中概念:
4、NM:NodeManager,管理每个节点上的资源和任务,主要有两个作用:定期向RM汇报该节点的资源使用情况和各个container的运行状态、接受并处理AM的作业任务启动,停止等请求。
5、RM:ResourceManager,负责管理所有应用程序计算资源的分配。
6、AM: ApplicationManager,每一个应用程序的AM负责相应的调度和协调。
7、containers:yarn为将来的资源隔离而提出的框架,每一个任务对应一个container,且只能在该container中运行。
如下图,所示:
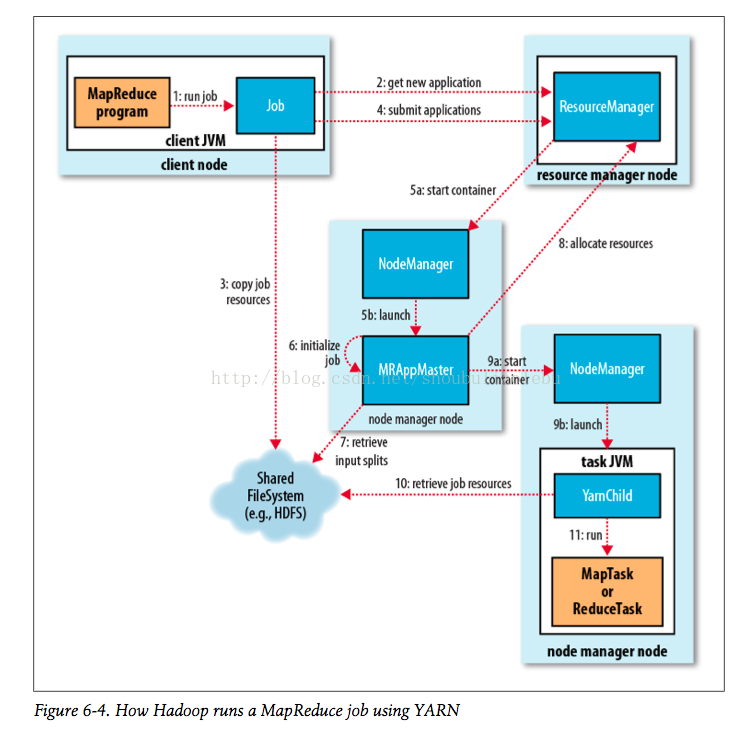
基本的步骤:作业提交--作业初始化--任务的分配--任务的执行--任务进度和状态的更新--任务结束;
更细的步骤:
(0)Mr 程序提交到客户端所在的节点。
(1)Yarnrunner 向 Resourcemanager 申请一个 Application。
(2)rm 将该应用程序的资源路径返回给 yarnrunner。
(3)该程序将运行所需资源提交到 HDFS 上。
(4)程序资源提交完毕后,申请运行 mrAppMaster。
(5)RM 将用户的请求初始化成一个 task。
(6)其中一个 NodeManager 领取到 task 任务。
(7)该 NodeManager 创建容器 Container,并产生 MRAppmaster。
(8)Container 从 HDFS 上拷贝资源到本地。
(9)MRAppmaster 向 RM 申请运行 maptask 资源。
(10)RM 将运行 maptask 任务分配给另外两个 NodeManager,另两个 NodeManager 分
别领取任务并创建容器。
(11)MR 向两个接收到任务的 NodeManager 发送程序启动脚本,这两个 NodeManager
分别启动 maptask,maptask 对数据分区排序。
(12)MrAppMaster 等待所有 maptask 运行完毕后,向 RM 申请容器,运行 reduce task。
(13)reduce task 向 maptask 获取相应分区的数据。
(14)程序运行完毕后,MR 会向 RM 申请注销自己。
mapreduce运行失败模式:
1-任务运行失败;主要是程序代码中bug或者JVM出现问题所致;
2-tasktracker失败:jobstacker和tasktracker是通过心跳进行通信的,如心跳停止,则认为map和reduce运行失败,这时,jobstacker会重新安排map任务运行。
此外,心跳正常也可能会导致tasktracker失败,对同一个作业的运行失败多次。次tasktracker会被拉入到黑名单(正常通信但不会安排任务)。
3-jobstracker失败:概率很小,目前没有机制能处理单点故障问题,降低单点失败是主要的方法(yarn对此有改进,引入了辅助主节点)。
yarn运行失败模式(和mapreduce相似):
1-任务运行失败;
2-AM运行失败;和tasktracker相似
3-NM运行失败;和tasktracker相似
4-RM运行失败;和jobtracker相似
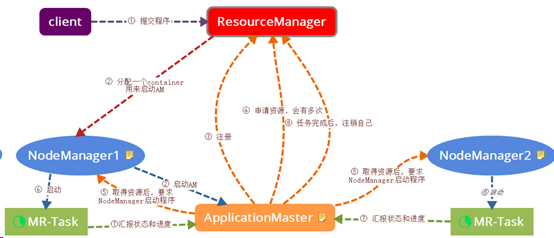
额外附一张明了提交图:
参考文献:
hadoop权威指南


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!