


Hbase架构
本文主要借鉴W3Cschool翻译的Hbase官方文档,非本人原创。
一: Hbase架构组成
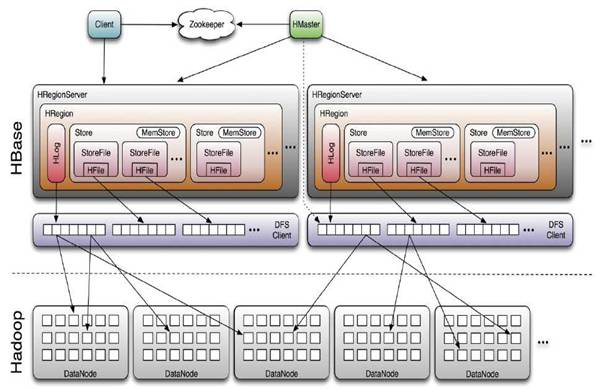
1.1 Master:
HMaster是主服务器(Master Server)的实现。主服务器负责监视群集中的所有RegionServer实例,并且是所有元数据更改的接口。在分布式集群中,Master通常在NameNode上运行。
1.1.1 启动行为
如果在多主机(multi-Master)环境中运行,所有Master竞争运行集群。如果活动Master在ZooKeeper中失去租约(或Master关闭),则剩下的Master将争相接管角色。
1.1.2 运行时影响
当Master发生故障时,一个常见的dist-list问题涉及一个HBase集群会发生什么。由于HBase客户端直接与RegionServer对话,因此群集仍可以“稳定状态”运行。此外,每个目录表(Catalog Tables),hbase:meta作为HBase的表存在,而不是在Master中不存在。但是,Master控制关键功能,如RegionServer故障切换和完成区域分割。因此,虽然群集仍可以在没有Master的情况下运行很短的时间,但应尽快重新启动Master形状。
1.1.3 接口
HMasterInterface公开的方法主要是面向元数据(metadata-oriented)的方法:
- 表(createTable,modifyTable,removeTable,enable,disable)
- ColumnFamily(addColumn,modifyColumn,removeColumn)
- 区域(move,assign,unassign),例如,调用该Admin方法disableTable时,它由Master服务器提供服务。
1.1.4 Master运行几个后台线程:
1- 负载平衡器
周期性地,当没有转换区域时,负载均衡器将运行并移动区域以平衡群集的负载。
有关区域分配的更多信息,将在后续的章节中介绍。
2-定期检查并清理hbase:meta表格。
1.2 RegionServer:
HRegionServer是RegionServer实现。负责区域的服务和管理。在分布式群集中,RegionServer在DataNode上运行。
1.2.1 RegionServer接口
HRegionRegionInterface公开的方法包含面向数据的和区域维护:
- 数据(get,put,delete,next等)
- 区域(splitRegion,compactRegion等)例如,当在表上调用该Admin方法majorCompact时,客户端实际上遍历指定表的所有区域,并直接向每个区域请求重大压缩。
1.2.2 RegionServer运行各种后台进程:
1- 检查分割并处理较小的压缩。
2- 检查重大压实。
3- 定期将MemStore中的内存中写入刷新到StoreFiles。
定期检查RegionServer的WAL。
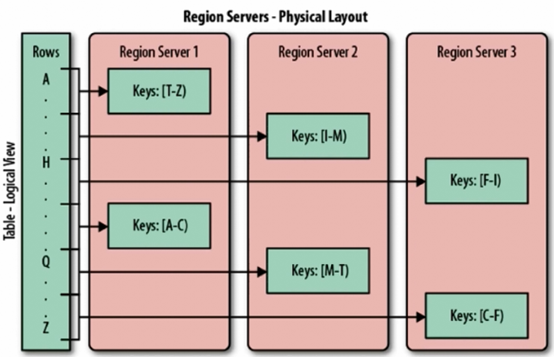
1.3 Region
分片就是region,一个regionServer包含若干region;
HBase使用RowKey将表水平切割成多个HRegion,从HMaster的角度,每个HRegion都纪录了它的StartKey和EndKey(第一个HRegion的StartKey为空,
最后一个HRegion的EndKey为空),由于RowKey是排序的,因而Client可以通过HMaster快速的定位每个RowKey在哪个HRegion中。HRegion由HMaster分
配到相应的HRegionServer中,然后由HRegionServer负责HRegion的启动和管理,和Client的通信,负责数据的读(使用HDFS)。
region储存的形式:
Hbase数据存储是以HFile文件存储。也就是说HFile是Hbase存储到hdfs上的最终形式。
二 HBase目录表
目录表hbase:meta以HBase表的形式存在,并且被HBase shell的list命令过滤掉,但实际上与其他表一样。
hbase:meta表
该hbase:meta表(以前称为.META.)保存了系统中所有区域的列表,并且该hbase:meta位置存储在ZooKeeper中。
该hbase:meta表结构如下:
键(key)
- 格式的区域键([table],[region start key],[region id])
值(value)
- info:regioninfo(该区域的序列化HRegionInfo实例)
- info:server (服务器:包含此区域的RegionServer端口)
- info:serverstartcode (包含此区域的RegionServer进程的开始时间)
当一个表处于拆分过程中时,另外两个列将被创建,称为info:splitA和info:splitB。这些列代表两个子区域。这些列的值也是序列化的HRegionInfo实例。该区域被拆分后,最终该行将被删除。
关于 HRegionInfo 的说明
空键用于表示表格开始和表结尾。具有空启动键的区域是表中的第一个区域。如果区域同时具有空的开始和空的结束键, 则它是表中唯一的区域。
启动排序
首先,hbase:meta在ZooKeeper中查找位置。接下来,使用服务器和startcode值更新hbase:meta。
三 RegionServer拆分实现
5.1 RegionServer拆分实现
由于写入请求由区域服务器处理,它们累积在一个名为memstore的内存存储系统中。一旦memstore填充,它的内容就会作为附加的存储文件写入磁盘。这个事件被称为memstore刷新。当存储文件堆积时,RegionServer会将它们压缩成更少、更大的文件。每次刷新或压缩完成后,该区域中存储的数据量将发生变化。RegionServer会咨询区域拆分策略,以确定该地区是否因为其他策略特定的原因而变得太大或应该拆分。如果策略建议,则区域拆分请求排队。
从逻辑上讲,分割区域的过程很简单。我们在该区域的密钥空间找到一个合适的点,我们应该将该区域分成两半,然后在该点将区域的数据分成两个新的区域。然而,这个过程的细节并不简单。当发生拆分时,新创建的子区域不会立即将所有数据重新写入新文件。相反,他们创建类似于符号链接文件的小文件,称为引用文件,根据拆分点指向父存储文件的顶部或底部。引用文件与常规数据文件一样使用,但只考虑一半的记录。如果不再有对父区域的不可变数据文件的引用,则只能分割该区域。这些引用文件通过压缩逐渐清理,以便该地区将停止引用其父文件,并且可以进一步拆分。
尽管拆分区域是由RegionServer做出的本地决定,但拆分过程本身必须与许多参与者协调。RegionServer在拆分之前和之后通知Master,更新.META.表以便客户端可以发现新的子区域,并重新排列HDFS中的目录结构和数据文件。拆分是一个多任务过程。为了在发生错误时启用回滚,RegionServer会保留关于执行状态的内存日志。RegionServer拆分过程说明了RegionServer执行拆分所采取的步骤。每个步骤都标有其步骤编号。来自RegionServers或Master的操作显示为红色,而来自客户端的操作显示为绿色。
下图为RegionServer拆分过程:
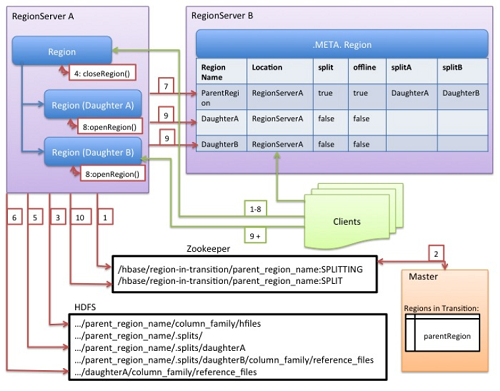
- RegionServer决定在本地拆分区域,并准备拆分。拆分已开始。作为第一步,RegionServer获取表上的共享读锁定,以防止在拆分过程中修改架构。然后它在zookeeper下的/hbase/region-in-transition/region-name创建一个znode,并将znode的状态设置为SPLITTING。
- Master开始了解znode,因为它有一个父region-in-transitionznode的观察器。
- RegionServer在HDFS中的父级region目录下创建一个子目录.splits。
- RegionServer关闭父区域并在其本地数据结构中将区域标记为离线。拆分区域现在处于离线状态。在这一点上,来到父区域的客户端请求将抛出NotServingRegionException。客户端将重试一些备份。关闭区域被刷新。
- RegionServer在.splits目录下为子区域A和B创建地区目录,并创建必要的数据结构。然后,它会拆分存储文件,因为它会在父区域中为每个存储文件创建两个引用文件。这些引用文件将指向父区域的文件。
- RegionServer在HDFS中创建实际的区域目录,并为每个子区域移动引用文件。
- RegionServer向.META.表发送一个Put请求,并将.META.表中的父级设置为离线,添加有关子区域的信息。在这一点上,.META.中的子区域将不会有单独的条目。客户端将看到父区域在扫描.META.时被拆分。但直到他们出现在.META.其中才会知道这些子区域。此外,如果Put到.META.成功后,父区域将会有效地拆分。如果RegionServer在此RPC成功之前失败,则Master和下一个Region Server打开该区域将清除有关区域拆分的不干净状态。更新.META.之后,区域分割将由Master进行前滚。
- RegionServer并行打开子区域A和B.
- RegionServer将子区域A和B添加到.META.,连同它承载区域的信息。拆分区域现在处于在线状态。在此之后,客户端可以发现新的区域并向他们发出请求。客户端在本地缓存.META.条目,但是当他们向RegionServer或者.META.发出请求时,他们的缓存将失效,他们将从.META.中了解新的区域。
- RegionServer更新ZooKeeper中的znode /hbase/region-in-transition/region-name以表示状态SPLIT,以便主服务器可以了解它。必要时,平衡器可以自由地将子区域重新分配给其他区域服务器。拆分事务现在已完成。
- 拆分之后,.META.和HDFS仍将包含对父区域的引用。在子区域中进行压缩重写数据文件时,这些引用将被删除。主服务器中的垃圾收集任务会定期检查子区域是否仍然引用父区域的文件。否则,父区域将被删除。
四 HBase客户端
HBase客户端查找正在服务特定行范围的RegionServers。它通过查询hbase:meta表格来做到这一点。找到所需的区域后,客户端将与服务该区域的RegionServer联系,而不是通过主服务器,并发出读取或写入请求。这些信息被缓存在客户端中,以便后续请求不需要经过查找过程。如果区域由主负载平衡器重新分配或由于RegionServer已经死亡,客户端将重新查询目录表以确定用户区域的新位置。
管理功能是通过Admin的一个实例完成的。
五 Hbase的存储过程(批量顺序存储)
1 输入数据先存储到预写文件中。
目的:为了防止数据丢失,所以在写进存储中进行备份下;
2 储存到内存中;
目的:可以加快查询速度,数据排序,并且可以进行批量写处理。加快写速度。
3 当内存空间逐渐被占满后,内存中存储的数据会被批量写到日志文件中。
写磁盘时,数据是以顺序进行存储,有利于快速读。
region数目太多,查询时会有大量的region需要记录到内存中。数目太少,达不到负载均衡的效果。可能会造成热点问题。
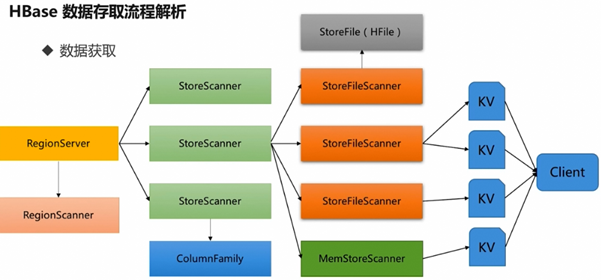
六 Hbase的读取过程
client-->Zookeeper-->-ROOT-表-->.META.表-->RegionServer-->Region-->client
(1) Client访问Zookeeper,获取含有-ROOT-表的服务器名,查找-ROOT-表,获取.META.表信息。
(2) 从.META.表查找,获取存放目标数据的Region信息,从而找到对应的RegionServer。
(3) 通过RegionServer获取需要查找的数据。
(4) Regionserver的内存分为MemStore和BlockCache两部分,MemStore主要用于写数据,BlockCache主要用于读数据。读请求先到MemStore中查数据,查不到就到BlockCache中查,再查不到就会到StoreFile上读,并把读的结果放入BlockCache。
七 Hbase的写过程
(1) Client通过Zookeeper的调度,向RegionServer发出写数据请求,在Region中写数据。
(2) 数据被写入Region的MemStore,直到MemStore达到预设阈值。
(3) MemStore中的数据被Flush成一个StoreFile。
(4) 随着StoreFile文件的不断增多,当其数量增长到一定阈值后,触发Compact合并操作,将多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除。
(5) StoreFiles通过不断的Compact合并操作,逐步形成越来越大的StoreFile。
(6) 单个StoreFile大小超过一定阈值后,触发Split操作,把当前Region Split成2个新的Region。父Region会下线,新Split出的2个子Region会被HMaster分配到相应的RegionServer上,使得原先1个Region的压力得以分流到2个Region上。
参考文献:https://blog.csdn.net/u011833033/article/details/79773421
慕课网


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!