

ElasticSearch基础
ElasticSearch的主要用处是相关性搜索:
每个文档都有相关性评分,用一个正浮点数字段 _score 来表示 。 _score 的评分越高,相关性越高。相似度计算主要包含;
1- 检索词频率 检索词在该字段出现的频率?出现频率越高,相关性也越高。 字段中出现过 5 次要比只出现过 1 次的相关性高。
2- 反向文档频率 每个检索词在索引中出现的频率?频率越高,相关性越低。检索词出现在多数文档中会比出现在少数文档中的权重更低。
3- 字段长度准则 字段的长度是多少?长度越长,相关性越低。 检索词出现在一个短的 title 要比同样的词出现在一个长的 content 字段权重更大。
一:一个 Elasticsearch 请求和任何 HTTP 请求一样由若干相同的部件组成
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'
被 < > 标记的部件:
| VERB | 适当的 HTTP 方法 或 谓词 : GET`、 `POST`、 `PUT`、 `HEAD 或者 `DELETE`。 |
| PROTOCOL | http 或者 https`(如果你在 Elasticsearch 前面有一个 `https 代理) |
| HOST | Elasticsearch 集群中任意节点的主机名,或者用 localhost 代表本地机器上的节点。 |
| PORT | 运行 Elasticsearch HTTP 服务的端口号,默认是 9200 。 |
| PATH | API 的终端路径(例如 _count 将返回集群中文档数量)。Path 可能包含多个组件,例如:_cluster/stats 和 _nodes/stats/jvm 。 |
| QUERY_STRING | 任意可选的查询字符串参数 (例如 ?pretty 将格式化地输出 JSON 返回值,使其更容易阅读) |
| BODY | 一个 JSON 格式的请求体 (如果请求需要的话) |
例如,计算集群中文档的数量:
curl -XGET 'http://localhost:9200/_count?pretty' -d ' { "query": { "match_all": {} } } '
缩写格式显示:
GET /_count { "query": { "match_all": {} } }
二:ES数据架构的主要概念(与关系数据库Mysql对比)
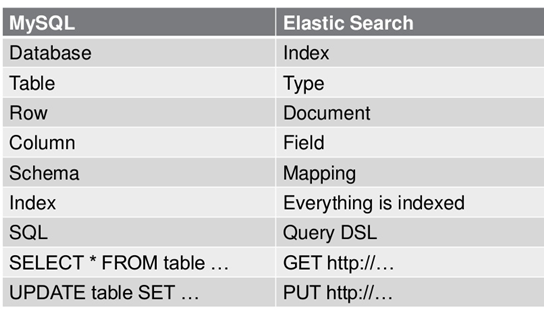
三:基础的常用命令
创建自定义id文档:
PUT /{index}/{type}/{id} { "field": "value", ... }
创建非自定义id文档:
POST /{index}/{type}/ { "field": "value", ... }
取回一个文档:
GET /{index}/{type}/{id} //获取该id所有信息
GET /{index}/{type}/{id}/_source //获取不含任何元数据,所有内容
GET /{index}/{type}/{id}?_source=name,sex //获取该id,name和sex内容
检查文档是否存在:
curl -i -XHEAD http://localhost:9200/website/blog/123 //200-文档存在;404-文档不存在
删除文档:
DELETE /{index}/{type}/{id}
更新文档:
POST /website/blog/1/_update { "doc" : { "tags" : [ "testing" ], "views": 0 } }
多搜索,多类型:
-
/_search - 在所有的索引中搜索所有的类型
-
/gb/_search - 在
gb索引中搜索所有的类型 -
/gb,us/_search - 在
gb和us索引中搜索所有的文档 -
/g*,u*/_search - 在任何以
g或者u开头的索引中搜索所有的类型 -
/gb/user/_search - 在
gb索引中搜索user类型 -
/gb,us/user,tweet/_search - 在
gb和us索引中搜索user和tweet类型 -
/_all/user,tweet/_search - 在所有的索引中搜索
user和tweet类型
分页:
GET /_search?size=5 GET /_search?size=5&from=5 GET /_search?size=5&from=10
查询语句的结构:
典型结构:
{
QUERY_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
针对某个字段:
{
QUERY_NAME: {
FIELD_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
}
合并查询语句;
{
"bool": {
"must": { "match": { "tweet": "elasticsearch" }},
"must_not": { "match": { "name": "mary" }},
"should": { "match": { "tweet": "full text" }},
"filter": { "range": { "age" : { "gt" : 30 }} }
}
}
四:常用命令的例题
创建雇员1:
megacorp为索引名称(相当于database),employee为类型名称(相当于table)-
_index文档在哪存放 -
_type文档表示的对象类别 -
_id文档唯一标识
PUT /megacorp/employee/1
{ "first_name" : "John", "last_name" : "Smith", "age" : 25, "about" : "I love to go rock climbing", "interests": [ "sports", "music" ] }
搜索雇员1的详细信息:
GET /megacorp/employee/1
获取所有雇员:
GET /megacorp/employee/_search
获取姓氏为Smith的雇员:
GET /megacorp/employee/_search?q=last_name:Smith
用查询表达式,获取姓氏为Smith的雇员:
GET /megacorp/employee/_search { "query" : { "match" : { "last_name" : "Smith" } } }
搜索姓氏为 Smith 的雇员,但这次我们只需要年龄大于 30 的:
GET /megacorp/employee/_search { "query" : { "bool": { "must": { "match" : { "last_name" : "smith" } }, "filter": { "range" : { "age" : { "gt" : 30 } } } } } }
搜索下所有喜欢攀岩(rock climbing)的雇员:
这样会有一个相关性得分。如有雇员爱好中只有rock或climbing也会被检索到。并且分支明显低于rock climbing
GET /megacorp/employee/_search { "query" : { "match" : { "about" : "rock climbing" } } }
短语搜索,不会返回rock或climbing的雇员:
GET /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
}
}
高亮搜索:
GET /megacorp/employee/_search { "query" : { "match_phrase" : { "about" : "rock climbing" } }, "highlight": { "fields" : { "about" : {} } } }
聚合搜索:
GET /megacorp/employee/_search { "aggs": { "all_interests": { "terms": { "field": "interests" } } } }
参考文献:ElasticSearch权威指南

 浙公网安备 33010602011771号
浙公网安备 33010602011771号