第五章 网络与并发编程
第五章 网络与并发编程
1.网络编程
1.1 网络编程定义
基于多台机器之间的通信需要基于网络编程
1.2 web程序的架构
C/S架构:client(客户端)/server(服务端) 所有需要安装的.exe文件都属于客户端
B/S架构:breowser(浏览器)/server(服务端) 所有能被网页访问的网络都是B/S架构
C/S和B/S之间的关系:所有的B/S架构都需要一个浏览器才能访问,浏览器是一个软件,相当于客户端,多有的B/S架构也都是C/S架构的,浏览器(breowser)是特殊的客户端(client)
两种架构的优点:C/S装好了直接双击就可以使用。B/S几大的简化了我们使用软件的成本。
1.3 tcp协议
定义:tcp协议建立连接可靠,但是比较慢,全双工通信
建立连接的时候用三次握手,断开连接的时候用四次挥手
在建立连接之后发送的每一条信息都有回复,为了保证数据的完整性,还有重传机制
长连接,所以会占用双方的端口
#server端 import socket sk = socket.socket() #创建一个socket对象 sk.bind(('127.0.0.1',9000)) #绑定自己的环回地址端口为9000 sk.listen() #开始接受客户端给我的链接,可以设置最大连接数,如果有人在连接,其余人等待 while True: conn,addr = sk.accept() #阻塞等待被连 while True: msg = input('>>>') connsend(msg.encode('utf-8')) #给连接端发送一条消息,用utf-8格式 if msg.upper() =='Q'; break content = conn.recv(1024).decode('utf-8') #阻塞,直到收到连接放发来的消息,一次收不超过1024字节 if content.upper() == 'Q':break print(content) #打印收到的消息 conn.close() #断开连接 sk.close() #关闭连接 #client端 import socket sk = socket.socket() sk.connect(('serverIP',server端口) while True: ret = sk.recv(1024).decode('utf-8') #接收发送来的消息 if ret.ipper() == 'Q':break print(ret) msg = input('>>>') sk.send(msg.encode('utf-8')) if msg.upper() = 'Q': break sk.close()
1.4 udp协议
定义:无连接的,速度快,但是可能会丢失数据
#server端 import socket sk = socket.socket(type = socket.SOCK_DGRAM) #定义连接为UDP sk.bind(('127.0.0.1',9000) while True: msg,client_addr = sk.recvfrom(1024) print(msg.decode('utf-8')) cpntent = input('>>>') sk.sendto('收到'.encode('utf-8'),client_addr) sk.close() #client端 import socket sk = socket.socket(type = socket.SOCK_DGRAM) server_addr = ('127.0.0.1',9000) while True: content = input('>>>') if content.upper() == 'Q':break sk.sendto(content.encode('utf-8'),server_addr) msg = sk.recvfrom(1024) if msg.upper() == 'Q' :break print(msg.decode('utf-8')) sk.close()
1.5 粘包
定义:粘包是tcp协议中的一个现象,在发送端由于两条信息发送的时间间隔很短,且两条消息本身也很短,在发送之前被合成一条消息,在接收端由于接收不及时导致两条先后到达的信息在接收端黏在一起
本质:信息与信息之间没有边界
解决黏包:内置模块
#server端 import socket import struck sk.socket.socket() sk.bind(('127.0.0.1',9000)) sk.listen() conn,addr = sk.accept() msg = 'Parallel' bytes_msg = msg.encode('utf-8') #转换成字节码 num = len(bytes_msg) #计算出字节码的长度 len_bytes = struck.pack('i',num) #用struck模块总pack方法将具体长度转成4个字节 conn.send(len_bytes) #先发送4个字节 conn.send(bytes_msg) #发送转成字节码的内容 conn.close() sk.clock() #client端 import socket sk = socket.socket() sk.connect(('serverIP',端口)) num = sk.recv(4) #先接收4字节 bytes_num = struck.unpack('i',num)[0] #把4字节中打包的长度解包,变成要接收数据的具体长度 msg = sk.recv(bytes_num) #知道具体长度后确定自己要接收多少字节 print(msg.decode('utf-8')) sk.close
1.6 拆包机制和合包机制
定义:当TCP传输的是大文件时,需要将文件通过拆包机制拆分成多份陆续发送,接收方收到多个拆分后的信息后需要全部收到使用合包机制整合成大文件。
1.7 文件的传输
#信息通过字典传输文件 #server端 import os import json import socket sk = socket.socket() sk.connect(('127.0.0.1',9001)) filename = input('请输入文件路径:')###输入文件名 filename = os.path.basename(filepath)###从文件名中获取文件路径 filesize = os.path.getsize(filepath)###获取文件大小 dic = {'filename':filename,'filesize':filesize} bytes_dic = json.dumps(dic).encode('utf-8') len_dic = len(bytes_dic) bytes_len = struct.pack('i',len_dic) sk.send(bytes_len)###发送字典字节 sk.send(bytes_dic)###发送字典 with open(filepath,'rb') as f: content = f.read()###读出文件内容 sk.send(content)###发送文件内容 conn.close() sk.close() #client端 import os import socket sk = sk.socket.socket() sk.bind(('127.0.0.1',900)) sk.listen() conn,addr = sk.accept() num = conn.recv(4)###接收4字节 num = struct.unpack('i',num)[0]###通过接收的4个字节得到文件名长度 str_dic = conn.recv(num).decode('utf-8')###得到json类型的字典 dic = json.loads(str_dic) with open(dic['file_name'],'wb') as f: conntent = conn.recv(dic['filesize']) f.write(content) conn.close() sk.close()
2.网络并发编程
2.1 并发的模块
定义:并发使用socketserver模块,并发网络的连接操作是基于socket实现的
#server端 import socketserver class Myserver(socket.server.BaseRequestHandler): #固定格式 def handle(self): #固定格式 print(self.request) #打印conn连接,等同于self.request msg = self.request.recv(1024).decode('utf-8) self.request.send(msg.encode('utf-8)) #把收到的消息发送回去 server = socketserver.ThreadingTCPServer(('127.0.0.1',9000),Myserver) #类名 server.serve_forever() #相当于accept阻塞等待连接 #client端1 import socket sk = socket.socket() sk.connect((serverIP,端口)) #发送信息测试 sk.close() #client端2 import socket sk = socket.socket() sk.connect((serverIP,端口)) #发送信息测试 sk.close()
2.2 非阻塞IO模型
定义:server端没有IO状况且没有阻塞状态
#server端 import socket sk = socket.socket() sk.bind(('127.0.0.1',9000)) sk.setblocking(False) #设置非阻塞 sk.listen() conn_l = [] del_l = [] while True: try: conn,addr = sk.accept() #此处不再阻塞 print(conn) conn_l.append(conn) except BlockingIOError: for c in conn_l: try: msg = c.recv(1024).decode('utf-8') if not msg: del_l.append(c) continue print('-->',[msg]) c.send(msg.upper().encode('utf-8')) except BlockingIOError:pass for c in del_l: conn_l.remove(c) del_l.clear() sk.close() #client端1、2 import time import socket sk = socket.socket() sk.connect(('127.0.0.1',9000)) for i in range(30): sk.send(b'wusir') msg = sk.recv(1024) print(msg) time.sleep(0.2) sk.close()
2.3 验证用户端的合法性
定义:当客户端是提供给机器使用时,需要验证客户端是否合法,利用加密
#server端 import os import hashlib import socket def get_md5(secret_key,randseq): md5 = hashlib.md5(secret_key) md5.update(randseq) res = md5.hexdigest() return res def chat(conn): while True: msg = conn.recv(1024).decode('utf-8') print(msg) conn.send(msg.upper().encode('utf-8')) sk = socket.socket() sk.bind(('127.0.0.1',9000)) sk.listen() secret_key = b'alexsb' while True: conn,addr = sk.accept() randseq = os.urandom(32) conn.send(randseq) md5code = get_md5(secret_key,randseq) ret = conn.recv(32).decode('utf-8') print(ret) if ret == md5code: print('是合法的客户端') chat(conn) else: print('不是合法的客户端') conn.close() sk.close() #client端 import hashlib import socket import time def get_md5(secret_key,randseq): md5 = hashlib.md5(secret_key) md5.update(randseq) res = md5.hexdigest() return res def chat(sk): while True: sk.send(b'hello') msg = sk.recv(1024).decode('utf-8') print(msg) time.sleep(0.5) sk = socket.socket() sk.connect(('127.0.0.1',9000)) secret_key = b'alexsb' randseq = sk.recv(32) md5code = get_md5(secret_key,randseq) sk.send(md5code.encode('utf-8')) chat(sk) sk.close()
2.4 进程
1.定义:当一个文件或软件被CPU运行时,这个文件和软件就被称为进程
进程是计算机中最小的资源分配单位
标识符为PID,随机且唯一
进程之间的数据是隔离的,子进程中的数据不影响父进程
2.进程的三状态:创建进程后
就绪:等待CPU调用运行
运行:没有遇到IO操作则到时间片后回到就绪,遇到阻塞就停止,没有上述情况就运行到结束
阻塞:遇到阻塞后返回就绪状态重新等待CPU调用开始运行
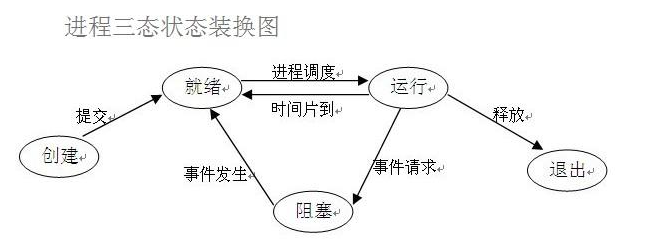
3.父子进程
在pycharm中所有的python程序都是pycharm的子进程
os,getpid()查看进程的pid,os.getppid()查看父进程的pid
主进程要等待子进程结束才算结束,负责回收子进程资源
如果子进程执行结束,父进程没有回收资源,那么这个子进程会变成一个僵尸进程
4.主进程结束逻辑
主进程的代码结束——>所有的子进程结束——>给子进程回收资源——>主进程结束
5.join方法
阻塞,直到子进程结束,主进程回收资源后才执行主进程后面,属于同步阻塞
将子进程赋值给一个变量(不可直接使用),变量.join()执行
6.并行与并发
并行:两个程序两个CPU每个程序分别占用一个CPU执行
并发:两个程序一个CPU每个程序交替的在一个CPU上执行
7.程序运行的分类
同步:单个程序运行结束或者被打断后才能运行下一个程序
异步:多个程序可以同时运行
阻塞:CPU不在该进程上工作
非阻塞:CPU在该进程上工作
同步阻塞:conn.recv
异步阻塞:多个进程遇见IO
同步非阻塞:func()且没有IO操作
异步非阻塞:把func()扔到其他任务里执行,且本身任务和其他任务都没有IO操作
8.Process类
开启进程的方式:
#面向函数 from multiprocessing import Process #进程类Process def func(i): time.sleep(1) print(0) if __name__ == '__main__': Process(target = func).start() Process(target = func).start() Process(target = func).start() #三个之间互不影响,同时执行且异步
#在windows中新的子进程需要通过import父进程的代码来完成数据的导入工作,所以有一些内容我们只希望在父进程中完成,就写在__name__ = '__main__'下面 #面向对象 from multiprocessing import Process class 类名(Process): def __init__(self,参数1,参数2) #需要传参数必须写init和super().__init__() self.a = 参数1 self.b = 参数2 super().__init__() #在继承Process类中也有init方法,必须引用过去 def run(self): #要在子进程中执行的代码 pass if __name__ =='__main__': mp = MyProcess(传参数) mp.start() #开启进程,异步非阻塞 mp.terminate() #结束进程 异步非阻塞 mp.join() #同步阻塞 mp.is_live() #获取当前进程的状态True为运行
9. 守护进程
定义:守护进程是随着主进程的代码结束而自动结束
import time from multiprocessing import Process def son1(): while True: print('is alive') time.sleep(0.5) if __name__ == '__main__': p = Process(target=son1) p.daemon = True #把p子进程设置成一个守护进程 p.start() p.terminate() #强制结束一个子进程且为异步非阻塞 p.is_alive() #判断一个进程是不是存活
10.锁Lock
定义:如果在一个并发的场景下设计到某部分内部是需要修改一些所有进程共享的数据资源,需要加锁来维护数据的安全,虽然会降低效率,但是需要在数据安全的基础上会考虑效率的问题
使用:在主进程中实例化lock=Lock(),把这把锁当做参数传递给子进程,在子进程中对需要加锁的代码执行with lock(相当于lock.acquire()#加锁,lock.release()#解锁)
应用场景;共享的数据资源(文件、数据库)对资源进行修改、删除操作
import time import json from multiprocessing import Process,Lock def search_ticket(user): with open('ticket_count') as f: dic = json.load(f) print('%s查询结果 : %s张余票'%(user,dic['count'])) def buy_ticket(user,lock): with lock: # lock.acquire()给这段代码加上一把锁 time.sleep(0.02) with open('ticket_count') as f: dic = json.load(f) if dic['count'] > 0: print('%s买到票了'%(user)) dic['count'] -= 1 else: print('%s没买到票' % (user)) time.sleep(0.02) with open('ticket_count','w') as f: json.dump(dic,f) # lock.release()给这段代码解锁 def task(user, lock): search_ticket(user) with lock: #默认做异常处理(推荐) buy_ticket(user, lock) if __name__ == '__main__': lock = Lock() for i in range(10): p = Process(target=task,args=('user%s'%i,lock)) p.start()
11.进程之间数据通信——IPC
定义:IPC(inter process communication),在进程与进程中形成一个Queue的队列,把数据传去队列中相互传递,Queue是基于socket连接和写文件pickle实现通信,并且存在lock
from multiprocessing imoprt Queue,Process def func(exp): ret = eval(exp) print(ret) q.put(ret) if __name__ =='__main__': q = Queue(5) #先进先出,规定队列中的数据最多5个,当队列满了,继续传输会阻塞,直到队列有数据被拿走 Process(target=func,args=('1+2+3',q)).start() print(q.get()) #当没有数据的时候会阻塞直到取出数据
12.生产者消费者模型
定义:生产者是生产数据,消费者是处理数据
解耦:把写在一起的大的功能分开成多个小的功能,修改、复用、可读性大大提高
from multiprocessing import Process,Queue def producer(q,name,food): for i in range(10): time.sleep(random.random()) fd = '%s%s'%(food,i) q.put(fd) print('%s生产了一个%s'%(name,food)) def consumer(q,name,): while True: food = q.get() print(%s吃了%s'%(name,food)) if __name__=='__main__': q = Queue(10) Process(target=prodecer,args=(q,'Parallel','火锅')) p1.start() c1 = Process(target=consumer,args=(q,'World')) c1.start() p1.join() q.put(None) #有几个用户需要输几个q.put(None)
2.5 线程
1.定义:在进程中存在多个线程,多个线程可以同时执行
相对于线程来说,创建进程时间开销大,销毁进程时间开销大,进程之间切换时间开销大
线程属于进程的一部分,不能脱离进程存在
每个进程至少有一个线程,线程是负责执行具体代码的
进程是计算机中最小的资源分配单位
线程是计算机中能被CPU调度的最小单位
线程的创建也需要一些开销,但是创建、销毁、切换远远小于进程4
2.特点:数据共享,开销小
3.GIL全局解释器锁:在cpython解释器中,有GIL的情况下不能实现多线程利用多核
因为cpython解释器中特殊的垃圾回收机制
4.thread线程模块
主线程必须等子线程结束,因为主线程结束了,主进程也就结束了
在线程中主线程不能结束子线程,只能等运行完毕
#面向对象方式启动线程 from threading import Thread class MyThread(Thread): def __init__(self,i): self.i = i super()._init__() def run(self): print('start',self.i) time.sleep(1) print('end',self.i) for i in range(10): #开启多个子线程 MyThread(i).start() print(t.ident)
5.join方法
阻塞,直到子线程执行结束
#函数式线程 from threading import Thread def func(): print('start son thread') time.sleep(1) print('end son thread',i,os.getpid()) t_l = [] for i in range(10): t = Thread(target=func,agrs=(0,)) t.start() t_l.append(t) for t in t_l : t.join() print('子线程执行完毕')
6.线程中的其他方法
from threading import current_thread,enumerate,active_count def func(i): print('start son thread',i,current_thread() #在哪个线程中执行,拿到当前子线程) time.sleep(1) print('end son thread',i,os.getpid()) t = Thread(target=func,args=(1,)) t.start() print(t) print(current_thread().ident) #在哪一个线程里,得到的就是这个当前线程的信息 print(enumerate()) #显示有几个线程存活(包括主线程) print(active_count()) #==len(enumerate)##表示有几个线程存活
7.守护线程
守护线程一直等到所有的非守护线程都结束之后才结束
除了会守护主线程的代码之外也会守护子线程
#守护进程睡眠时间完全取决于线程中最大时间,并不叠加 from threading import Thread def son1(): while True: time.sleep(0.5) print('in son1') def son2(): for i in range(5): time.sleep(1) print('in son2') t = Thread(target=son1) t.daemon = True t.start() Thread(target=son2).start() time.sleep(3)
8.互斥锁和递归锁
定义:即便是线程和GIL锁也会出现数据不安全的问题
在全局变量中:因为线程之间数据共享,在+= -= /= *=先计算再赋值才容易出现数据不安全的问题
包括lst[0] += 1 dic['key'] -=1
在同一个线程中,一个acquire必须对应一个release,不能连续acquire多次
9.死锁
现象:指两个或两个以上的进程或线程执行过程中,因争夺资源而造成的一种互相等待得到现象,若无外力作用,他们都将无法推进下去
解决:
递归锁:快速结局问题,但执行效率差,当递归锁出现多把锁交替使用也会出现死锁
优化代码:可以使用互斥锁解决问题,执行效率高,解决问题的效率相对低
10.递归锁
定义:在同一个线程中,可以连续aquire多次不会被锁住,但是占用了较多的资源
import time from threading import RLock,Thread # noodle_lock = RLock() 同时开启会导致死锁 # fork_lock = RLock() 同时开启会导致死锁 noodle_lock = fork_lock = RLock() #使用递归锁代替 print(noodle_lock,fork_lock) def eat1(name,noodle_lock,fork_lock): noodle_lock.acquire() print('%s抢到面了'%name) fork_lock.acquire() print('%s抢到叉子了' % name) print('%s吃了一口面'%name) time.sleep(0.1) fork_lock.release() print('%s放下叉子了' % name) noodle_lock.release() print('%s放下面了' % name) def eat2(name,noodle_lock,fork_lock): fork_lock.acquire() print('%s抢到叉子了' % name) noodle_lock.acquire() print('%s抢到面了'%name) print('%s吃了一口面'%name) time.sleep(0.1) noodle_lock.release() print('%s放下面了' % name) fork_lock.release() print('%s放下叉子了' % name) lst = ['唐僧','大师兄','我','沙师弟'] Thread(target=eat1,args=(lst[0],noodle_lock,fork_lock)).start() Thread(target=eat2,args=(lst[1],noodle_lock,fork_lock)).start() Thread(target=eat1,args=(lst[2],noodle_lock,fork_lock)).start() Thread(target=eat2,args=(lst[3],noodle_lock,fork_lock)).start()
11.单例模式
import time from threading import Lock class A: __instance = None lock = Lock() def __new__(cls, *args, **kwargs): with cls.lock: if not cls.__instance: time.sleep(0.1) cls.__instance = super().__new__(cls) return cls.__instance def __init__(self,name,age): self.name = name self.age = age def func(): a = A('alex', 84) print(a) from threading import Thread for i in range(10): t = Thread(target=func) t.start()
12.线程队列
#先进先出 from queue import Queue q = Queue() q.put(0) q.put(1) print(q.get()) print(q.get()) #后进先出 from queue import LifoQueue lfq = LifoQueue(4) lfq.put(1) lfq.put(2) print(lfq.get()) print(lfq.get()) #2,1
2.6 进程池和线程池
1.定义:预先的开启固定个数的进程或线程数,当任务进来的时候,直接提交给已经开好的进程或线程
让这个进程或线程去执行,节省了进程和线程的开启,关闭,切换的时间,并减轻了操作系统调度的负担
#进程池 import os import time import random from concurrent.futures import ProcessPoolExecutor #ProcessPoolExecutor(5) #创建进程池(5个进程) def func() print('start',os.get.pid()) time.sleep(random.randint(1,3)) print('end',os.getpid()) return '%s*%s'%(i,os.getpid)) if __name__=='__main__': p = ProcessPoolExecutor(5) ret_l = [] for i in range(10): ret = p.submit(func) #submit后面直接加函数名就好#需要传参直接逗号隔开 ret_l.append(ret) for ret in ret_l: print('ret-->',ret.result()) #ret.result可以获得函数的返回值 p.shutdown() #关闭池之后就不能继续提交任务了,并且会阻塞,直到已经提交的任务完成 print('main',os.getpid()) #缺点:进程只能开和CPU相同的内核数,限制了我们程序的并发个数 #线程池 from concurrent.futrres import ThreadPoolExecutor tp = threadPoolExecutor(20) #线程池一般开CPU的4~5倍 def func(i): print('start') time.sleep(random.randint(1,3)) print('end') retnrn i ret_l = [] for i in range(100): ret = tp.submit(func,i) ret_l.append(ret) tp.shutdown() print('main') for ret in ret_l: print('--->',ret.result())
2.回调函数
多线程同时执行时,谁先执行成功,谁再执行下一个函数
#回调函数 from concurrent.future import ThreadPoolExecutor def get_pahe(url): res = requests.get(url) return {'url':url,'content':res.text} def parserpage(ret): dic = ret.result() print(dic['url']) tp = ThreadPoolExecutor(5) url_lst = [ 'http://www.baidu.com' 'http://www.cnblogs.com' 'http://www.tencent.com' 'http://www.cnblogs.com' ] for url in url_lst: ret = tp.submit(get_page,url)) #爬完网页结束 ret.add_done_callback(parserpage) #谁先结束,谁先执行parserpage
2.7 协程
1.铺垫:线程由操作系统调度,一个线程中的阻塞都被其他的各种任务沾满了
让操作系统认为这个线程一直在执行,尽量减少这个线程进入阻塞的状态,提高CPU的利用率
多个任务在同一个线程中执行,也达到了一个并发的效果,规避了每一个任务的IO操作
减少了现成的个数,减轻了操作系统的负担
2.定义:能够在一个线程下的多个任务之间来回切换,那么这个任务都是一个协程
模块操作是用户级别的,由我们自己写的python代码来控制切换
在cpython中由于多线程本身就不能利用多核,所以开启了多个线程也只能轮流在一个CPU上执行
意味着协程就可以做到提高CPU的利用率
3.对比:线程切换需要操作系统,开销比协程大,操作系统不可控,并且诶系统的压力大,但是操作系统对IO操作更加灵敏
协程切换需要python代码,开销比线程小,用户操作可控,完全不会增加系统压力,但是用户级别对IO操作的感知低
4.切换方式
#greenlet from greenlet import greenlet import time def eat(): print('Parallel is eating') time.sleep(0.5) g2.switch() #切到g2 print('Parallel finished eat') def sleep(): print('World is sleeping') time.sleep(0.5) print('World finished sleep') g1.switch() #切回g1 g1 = greenlet(eat) g2 = greenlet(sleep) g1.switch() #开始 #gevent 第三方模块 import time import gevent from gevent import monkey monkey.patch_all() def eat(): print('wusir is eating') time.sleep(0.5) print('wusir finished eat') def sleep(): print('小马哥 is sleeping') time.sleep(0.5) print('小马哥 finished sleep') g1 = gevent.spawn(eat)#创建一个协程任务,遇见IO才会切 #g1.join()阻塞,直到1任务完成 #g2.join()阻塞,直到2任务完成 gevent.joinall([g1,g2]) #等价于前两个 g_l = [] for i in range(10): g = gevent.spawn(eat) g_l.append(g) gevent.joinall(g_l)
5.协程实现socket通信
#server import gevent from gevent import monkey monkey.pathch_all() import socket def chat(conn): while True: msg = conn.recv(1024).decode('utf-8') conn.send(msg.Upper().encode('utf-8') sk = socket.socket() sk.bind(('127.0.0.1',9000)) sk.listen() while True: conn,_ = sk.accept() #在请求和recv处不停的切换 gevent.spawn(chat,conn) #client import time import socket def client(i): sk = socket.socket() sk.connect(('127.0.0.1',9000)) while True: sk.send('hello'.encode('utf-8')) print(i*'*',sk.recv(1024)) time.sleep(0.5) from threading import Thread for i in range(500): Thread(target=client,args=(i,)).start()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号