ceph
http://ceph.org.cn/2018/06/05/redhat-ceph存储-《面向生产环境的ceph-对象网关指南》/
Ceph:一个 Linux PB 级分布式文件系统 https://www.ibm.com/developerworks/cn/linux/l-ceph/index.html
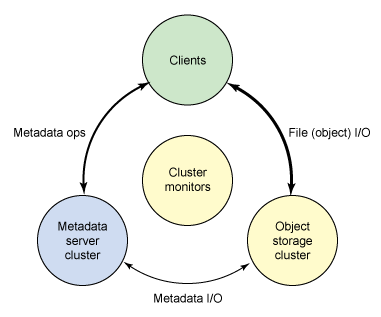
Ceph 生态系统可以大致划分为四部分(见图 1):客户端(数据用户),元数据服务器(缓存和同步分布式元数据),一个对象存储集群(将数据和元数据作为对象存储,执行其他关键职能),以及最后的集群监视器(执行监视功能)。
Ceph 元数据服务器
元数据服务器(cmds)的工作就是管理文件系统的名称空间。虽然元数据和数据两者都存储在对象存储集群,但两者分别管理,支持可扩展性。事实上,元数据在一个元数据服务器集群上被进一步拆分,元数据服务器能够自适应地复制和分配名称空间,避免出现热点。如图 4 所示,元数据服务器管理名称空间部分,可以(为冗余和性能)进行重叠。元数据服务器到名称空间的映射在 Ceph 中使用动态子树逻辑分区执行,它允许 Ceph 对变化的工作负载进行调整(在元数据服务器之间迁移名称空间)同时保留性能的位置。
图 4. 元数据服务器的 Ceph 名称空间的分区
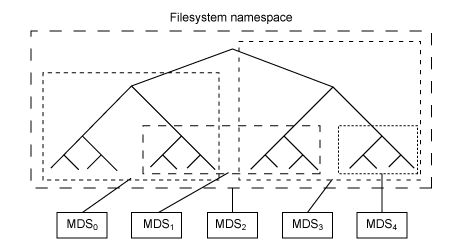
但是因为每个元数据服务器只是简单地管理客户端人口的名称空间,它的主要应用就是一个智能元数据缓存(因为实际的元数据最终存储在对象存储集群中)。进行写操作的元数据被缓存在一个短期的日志中,它最终还是被推入物理存储器中。这个动作允许元数据服务器将最近的元数据回馈给客户(这在元数据操作中很常见)。这个日志对故障恢复也很有用:如果元数据服务器发生故障,它的日志就会被重放,保证元数据安全存储在磁盘上。
元数据服务器管理 inode 空间,将文件名转变为元数据。元数据服务器将文件名转变为索引节点,文件大小,和 Ceph 客户端用于文件 I/O 的分段数据(布局)。
Ceph 监视器
Ceph 包含实施集群映射管理的监视器,但是故障管理的一些要素是在对象存储本身中执行的。当对象存储设备发生故障或者新设备添加时,监视器就检测和维护一个有效的集群映射。这个功能按一种分布的方式执行,这种方式中映射升级可以和当前的流量通信。Ceph 使用 Paxos,它是一系列分布式共识算法。
Ceph 对象存储
和传统的对象存储类似,Ceph 存储节点不仅包括存储,还包括智能。传统的驱动是只响应来自启动者的命令的简单目标。但是对象存储设备是智能设备,它能作为目标和启动者,支持与其他对象存储设备的通信和合作。
从存储角度来看,Ceph 对象存储设备执行从对象到块的映射(在客户端的文件系统层中常常执行的任务)。这个动作允许本地实体以最佳方式决定怎样存储一个对象。Ceph 的早期版本在一个名为 EBOFS 的本地存储器上实现一个自定义低级文件系统。这个系统实现一个到底层存储的非标准接口,这个底层存储已针对对象语义和其他特性(例如对磁盘提交的异步通知)调优。今天,B-tree 文件系统(BTRFS)可以被用于存储节点,它已经实现了部分必要功能(例如嵌入式完整性)。
因为 Ceph 客户实现 CRUSH,而且对磁盘上的文件映射块一无所知,下面的存储设备就能安全地管理对象到块的映射。这允许存储节点复制数据(当发现一个设备出现故障时)。分配故障恢复也允许存储系统扩展,因为故障检测和恢复跨生态系统分配。Ceph 称其为 RADOS(见 图 3)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号