今日头条Go建千亿级微服务的实践
今日头条Go建千亿级微服务的实践_36氪 http://36kr.com/p/5073181.html
今日头条Go建千亿级微服务的实践
编者按:本文来自微信公众号“InfoQ”(ID:infoqchina),作者项超;36氪经授权发布。
今日头条当前后端服务超过80%的流量是跑在 Go 构建的服务上。微服务数量超过100个,高峰 QPS 超过700万,日处理请求量超过3000亿,是业内最大规模的 Go 应用。
Go 构建微服务的历程
在2015年之前,头条的主要编程语言是 Python 以及部分 C++。随着业务和流量的快速增长,服务端的压力越来越大,随之而来问题频出。Python 的解释性语言特性以及其落后的多进程服务模型受到了巨大的挑战。此外,当时的服务端架构是一个典型的单体架构,耦合严重,部分独立功能也急需从单体架构中拆出来。
为什么选择 Go 语言?
Go 语言相对其它语言具有几点天然的优势:
语法简单,上手快
性能高,编译快,开发效率也不低
原生支持并发,协程模型是非常优秀的服务端模型,同时也适合网络调用
部署方便,编译包小,几乎无依赖
当时 Go 的1.4版本已经发布,我曾在 Go 处于1.1版本的时候,开始使用 Go 语言开发后端组件,并且使用 Go 构建过超大流量的后端服务,因此对 Go 语言本身的稳定性比较有信心。再加上头条后端整体服务化的架构改造,所以决定使用 Go 语言构建今日头条后端的微服务架构。
2015年6月,今日头条开始使用 Go 语言重构后端的 Feed 流服务,期间一边重构,一边迭代现有业务,同时还进行服务拆分,直到2016年6月,Feed 流后端服务几乎全部迁移到 Go。由于期间业务增长较快,夹杂服务拆分,因此没有横向对比重构前后的各项指标。但实际上切换到 Go 语言之后,服务整体的稳定性和性能都大幅提高。
微服务架构
对于复杂的服务间调用,我们抽象出五元组的概念:(From, FromCluster, To, ToCluster, Method)。每一个五元组唯一定义了一类的RPC调用。以五元组为单元,我们构建了一整套微服务架构。
我们使用 Go 语言研发了内部的微服务框架 kite,协议上完全兼容 Thrift。以五元组为基础单元,我们在 kite 框架上集成了服务注册和发现,分布式负载均衡,超时和熔断管理,服务降级,Method 级别的指标监控,分布式调用链追踪等功能。目前统一使用 kite 框架开发内部 Go 语言的服务,整体架构支持无限制水平扩展。
关于 kite 框架和微服务架构实现细节后续有机会会专门分享,这里主要分享下我们在使用 Go 构建大规模微服务架构中,Go 语言本身给我们带来了哪些便利以及实践过程中我们取得的经验。内容主要包括并发,性能,监控以及对Go语言使用的一些体会。
并发
Go 作为一门新兴的编程语言,最大特点就在于它是原生支持并发的。和传统基于 OS 线程和进程实现不同,Go 语言的并发是基于用户态的并发,这种并发方式就变得非常轻量,能够轻松运行几万甚至是几十万的并发逻辑。因此使用 Go 开发的服务端应用采用的就是“协程模型”,每一个请求由独立的协程处理完成。
比进程线程模型高出几个数量级的并发能力,而相对基于事件回调的服务端模型,Go 开发思路更加符合人的逻辑处理思维,因此即使使用 Go 开发大型的项目,也很容易维护。
-
并发模型
Go 的并发属于 CSP 并发模型的一种实现,CSP 并发模型的核心概念是:“不要通过共享内存来通信,而应该通过通信来共享内存”。这在 Go 语言中的实现就是 Goroutine 和 Channel。在1978发表的 CSP 论文中有一段使用 CSP 思路解决问题的描述。
“Problem: To print in ascending order all primes less than 10000. Use an array of processes, SIEVE, in which each process inputs a prime from its predecessor and prints it. The process then inputs an ascending stream of numbers from its predecessor and passes them on to its successor, suppressing any that are multiples of the original prime.”
要找出10000以内所有的素数,这里使用的方法是筛法,即从2开始每找到一个素数就标记所有能被该素数整除的所有数。直到没有可标记的数,剩下的就都是素数。下面以找出10以内所有素数为例,借用 CSP 方式解决这个问题。
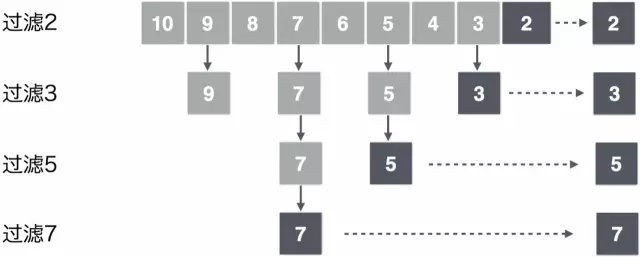 从上图中可以看出,每一行过滤使用独立的并发处理程序,上下相邻的并发处理程序传递数据实现通信。通过4个并发处理程序得出10以内的素数表,对应的 Go 实现代码如下:
从上图中可以看出,每一行过滤使用独立的并发处理程序,上下相邻的并发处理程序传递数据实现通信。通过4个并发处理程序得出10以内的素数表,对应的 Go 实现代码如下:
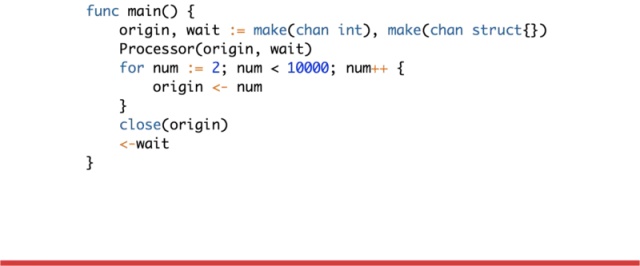
 这个例子体现使用 Go 语言开发的两个特点:
这个例子体现使用 Go 语言开发的两个特点:
Go 语言的并发很简单,并且通过提高并发可以提高处理效率。
协程之间可以通过通信的方式来共享变量。
-
并发控制
当并发成为语言的原生特性之后,在实践过程中就会频繁地使用并发来处理逻辑问题,尤其是涉及到网络I/O的过程,例如 RPC 调用,数据库访问等。下图是一个微服务处理请求的抽象描述:
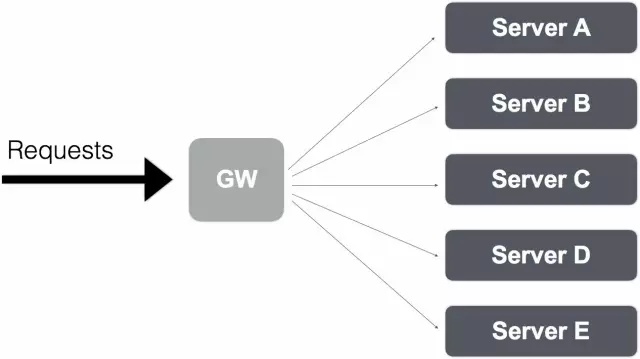 当 Request 到达 GW 之后,GW 需要整合下游5个服务的结果来响应本次的请求,假定对下游5个服务的调用不存在互相的数据依赖问题。那么这里会同时发起5个 RPC 请求,然后等待5个请求的返回结果。为避免长时间的等待,这里会引入等待超时的概念。超时事件发生后,为了避免资源泄漏,会发送事件给正在并发处理的请求。在实践过程中,得出两种抽象的模型。
当 Request 到达 GW 之后,GW 需要整合下游5个服务的结果来响应本次的请求,假定对下游5个服务的调用不存在互相的数据依赖问题。那么这里会同时发起5个 RPC 请求,然后等待5个请求的返回结果。为避免长时间的等待,这里会引入等待超时的概念。超时事件发生后,为了避免资源泄漏,会发送事件给正在并发处理的请求。在实践过程中,得出两种抽象的模型。
Wait
Cancel
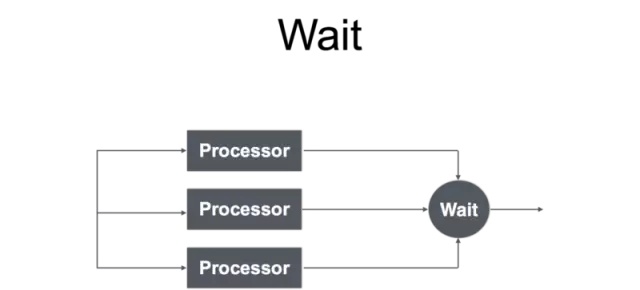
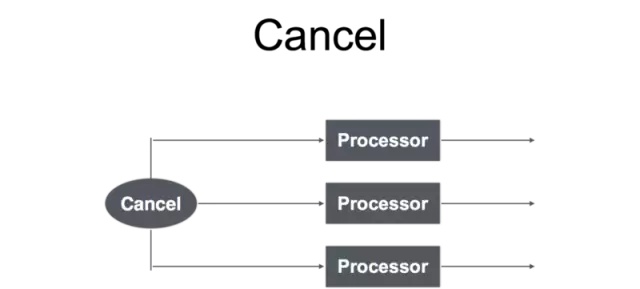 Wait和Cancel两种并发控制方式,在使用 Go 开发服务的时候到处都有体现,只要使用了并发就会用到这两种模式。在上面的例子中,GW 启动5个协程发起5个并行的 RPC 调用之后,主协程就会进入等待状态,需要等待这5次 RPC 调用的返回结果,这就是 Wait 模式。另一中 Cancel 模式,在5次 RPC 调用返回之前,已经到达本次请求处理的总超时时间,这时候就需要 Cancel 所有未完成的 RPC 请求,提前结束协程。Wait 模式使用会比较广泛一些,而对于 Cancel 模式主要体现在超时控制和资源回收。
Wait和Cancel两种并发控制方式,在使用 Go 开发服务的时候到处都有体现,只要使用了并发就会用到这两种模式。在上面的例子中,GW 启动5个协程发起5个并行的 RPC 调用之后,主协程就会进入等待状态,需要等待这5次 RPC 调用的返回结果,这就是 Wait 模式。另一中 Cancel 模式,在5次 RPC 调用返回之前,已经到达本次请求处理的总超时时间,这时候就需要 Cancel 所有未完成的 RPC 请求,提前结束协程。Wait 模式使用会比较广泛一些,而对于 Cancel 模式主要体现在超时控制和资源回收。
在 Go 语言中,分别有 sync.WaitGroup 和 context.Context 来实现这两种模式。


-
超时控制
合理的超时控制在构建可靠的大规模微服务架构显得非常重要,不合理的超时设置或者超时设置失效将会引起整个调用链上的服务雪崩。
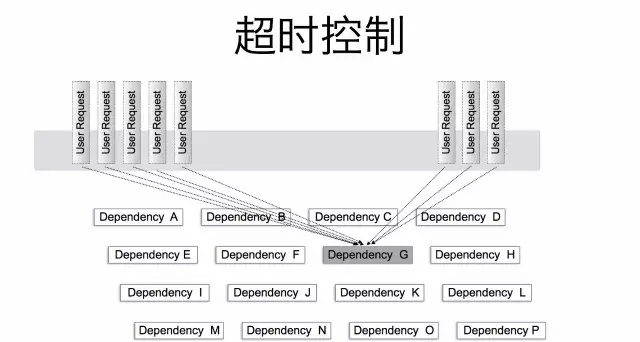 图中被依赖的服务G由于某种原因导致响应比较慢,因此上游服务的请求都会阻塞在服务G的调用上。如果此时上游服务没有合理的超时控制,导致请求阻塞在服务G上无法释放,那么上游服务自身也会受到影响,进一步影响到整个调用链上各个服务。
图中被依赖的服务G由于某种原因导致响应比较慢,因此上游服务的请求都会阻塞在服务G的调用上。如果此时上游服务没有合理的超时控制,导致请求阻塞在服务G上无法释放,那么上游服务自身也会受到影响,进一步影响到整个调用链上各个服务。
在 Go 语言中,Server 的模型是“协程模型”,即一个协程处理一个请求。如果当前请求处理过程因为依赖服务响应慢阻塞,那么很容易会在短时间内堆积起大量的协程。每个协程都会因为处理逻辑的不同而占用不同大小的内存,当协程数据激增,服务进程很快就会消耗大量的内存。
协程暴涨和内存使用激增会加剧 Go 调度器和运行时 GC 的负担,进而再次影响服务的处理能力,这种恶性循环会导致整个服务不可用。在使用 Go 开发微服务的过程中,曾多次出现过类似的问题,我们称之为协程暴涨。
有没有好的办法来解决这个问题呢?通常出现这种问题的原因是网络调用阻塞过长。即使在我们合理设置网络超时之后,偶尔还是会出现超时限制不住的情况,对 Go 语言中如何使用超时控制进行分析,首先我们来看下一次网络调用的过程。
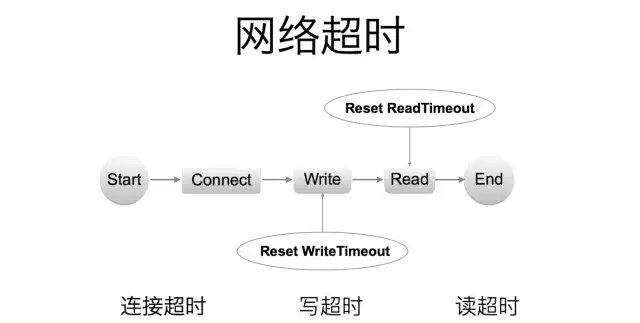 第一步,建立 TCP 连接,通常会设置一个连接超时时间来保证建立连接的过程不会被无限阻塞。
第一步,建立 TCP 连接,通常会设置一个连接超时时间来保证建立连接的过程不会被无限阻塞。
第二步,把序列化后的 Request 数据写入到 Socket 中,为了确保写数据的过程不会一直阻塞,Go 语言提供了 SetWriteDeadline 的方法,控制数据写入 Socket 的超时时间。根据 Request 的数据量大小,可能需要多次写 Socket 的操作,并且为了提高效率会采用边序列化边写入的方式。因此在 Thrift 库的实现中每次写 Socket 之前都会重新 Reset 超时时间。
第三步,从 Socket 中读取返回的结果,和写入一样, Go 语言也提供了 SetReadDeadline 接口,由于读数据也存在读取多次的情况,因此同样会在每次读取数据之前 Reset 超时时间。
分析上面的过程可以发现影响一次 RPC 耗费的总时间的长短由三部分组成:连接超时,写超时,读超时。而且读和写超时可能存在多次,这就导致超时限制不住情况的发生。为了解决这个问题,在 kite 框架中引入了并发超时控制的概念,并将功能集成到 kite 框架的客户端调用库中。
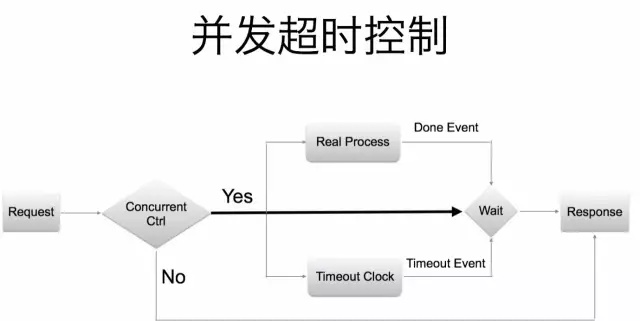
并发超时控制模型如上图所示,在模型中引入了“Concurrent Ctrl”模块,这个模块属于微服务熔断功能的一部分,用于控制客户端能够发起的最大并发请求数。并发超时控制整体流程是这样的
首先,客户端发起 RPC 请求,经过“Concurrent Ctrl”模块判断是否允许当前请求发起。如果被允许发起 RPC 请求,此时启动一个协程并执行 RPC 调用,同时初始化一个超时定时器。然后在主协程中同时监听 RPC 完成事件信号以及定时器信号。如果 RPC 完成事件先到达,则表示本次 RPC 成功,否则,当定时器事件发生,表明本次 RPC 调用超时。这种模型确保了无论何种情况下,一次 RPC 都不会超过预定义的时间,实现精准控制超时。

Go 语言在1.7版本的标准库引入了“context”,这个库几乎成为了并发控制和超时控制的标准做法,随后1.8版本中在多个旧的标准库中增加对“context”的支持,其中包括“database/sql”包。
性能
Go 相对于传统 Web 服务端编程语言已经具备非常大的性能优势。但是很多时候因为使用方式不对,或者服务对延迟要求很高,不得不使用一些性能分析工具去追查问题以及优化服务性能。在 Go 语言工具链中自带了多种性能分析工具,供开发者分析问题。
CPU 使用分析
内部使用分析
查看协程栈
查看 GC 日志
Trace 分析工具
下图是各种分析方法截图
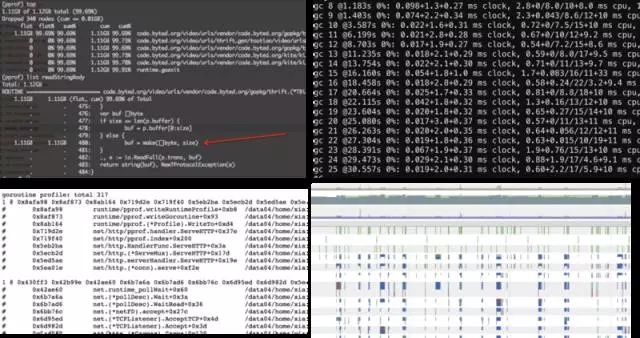
在使用 Go 语言开发的过程中,我们总结了一些写出高性能 Go 服务的方法
注重锁的使用,尽量做到锁变量而不要锁过程
-
可以使用 CAS,则使用 CAS 操作
-
针对热点代码要做针对性优化
-
不要忽略 GC 的影响,尤其是高性能低延迟的服务
-
合理的对象复用可以取得非常好的优化效果
-
尽量避免反射,在高性能服务中杜绝反射的使用
-
有些情况下可以尝试调优“GOGC”参数
-
新版本稳定的前提下,尽量升级新的 Go 版本,因为旧版本永远不会变得更好
下面描述一个真实的线上服务性能优化例子。
这是一个基础存储服务,提供 SetData 和 GetDataByRange 两个方法,分别实现批量存储数据和按照时间区间批量获取数据的功能。为了提高性能,存储的方式是以用户 ID 和一段时间作为 key,时间区间内的所有数据作为 value 存储到 KV 数据库中。因此,当需要增加新的存储数据时候就需要先从数据库中读取数据,拼接到对应的时间区间内再存到数据库中。
 对于读取数据的请求,则会根据请求的时间区间计算对应的 key 列表,然后循环从数据库中读取数据。
对于读取数据的请求,则会根据请求的时间区间计算对应的 key 列表,然后循环从数据库中读取数据。
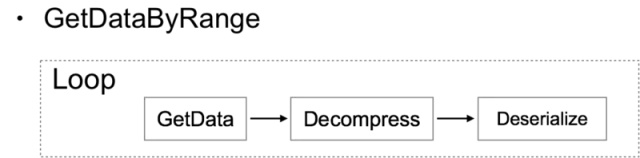 这种情况下,高峰期服务的接口响应时间比较高,严重影响服务的整体性能。通过上述性能分析方法对于高峰期服务进行分析之后,得出如下结论:
这种情况下,高峰期服务的接口响应时间比较高,严重影响服务的整体性能。通过上述性能分析方法对于高峰期服务进行分析之后,得出如下结论:
问题点:
-
GC 压力大,占用 CPU 资源高
-
反序列化过程占用 CPU 较高
优化思路:
-
GC 压力主要是内存的频繁申请和释放,因此决定减少内存和对象的申请
-
序列化当时使用的是 Thrift 序列化方式,通过 Benchmark,我们找到相对高效的 Msgpack 序列化方式。
分析服务接口功能可以发现,数据解压缩,反序列化这个过程是最频繁的,这也符合性能分析得出来的结论。仔细分析解压缩和反序列化的过程,发现对于反序列化操作而言,需要一个”io.Reader”的接口,而对于解压缩,其本身就实现了”io.Reader“接口。在 Go 语言中,“io.Reader”的接口定义如下:
 这个接口定义了 Read 方法,任何实现该接口的对象都可以从中读取一定数量的字节数据。因此只需要一段比较小的内存 Buffer 就可以实现从解压缩到反序列化的过程,而不需要将所有数据解压缩之后再进行反序列化,大量节省了内存的使用。
这个接口定义了 Read 方法,任何实现该接口的对象都可以从中读取一定数量的字节数据。因此只需要一段比较小的内存 Buffer 就可以实现从解压缩到反序列化的过程,而不需要将所有数据解压缩之后再进行反序列化,大量节省了内存的使用。
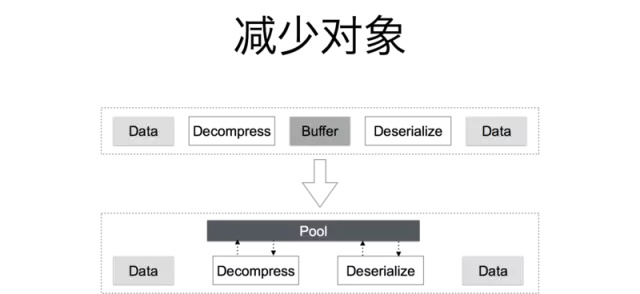
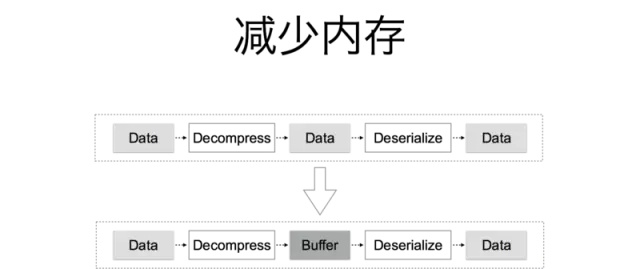 为了避免频繁的 Buffer 申请和释放,使用“sync.Pool”实现了一个对象池,达到对象复用的目的。
为了避免频繁的 Buffer 申请和释放,使用“sync.Pool”实现了一个对象池,达到对象复用的目的。
 此外,对于获取历史数据接口,从原先的循环读取多个 key 的数据,优化为从数据库并发读取各个 key 的数据。经过这些优化之后,服务的高峰 PCT99 从100ms降低到15ms。
此外,对于获取历史数据接口,从原先的循环读取多个 key 的数据,优化为从数据库并发读取各个 key 的数据。经过这些优化之后,服务的高峰 PCT99 从100ms降低到15ms。
上述是一个比较典型的 Go 语言服务优化案例。概括为两点:
-
从业务层面上提高并发
-
减少内存和对象的使用
优化的过程中使用了 pprof 工具发现性能瓶颈点,然后发现“io.Reader”接口具备的 Pipeline 的数据处理方式,进而整体优化了整个服务的性能。
服务监控
Go 语言的 runtime 包提供了多个接口供开发者获取当前进程运行的状态。在 kite 框架中集成了协程数量,协程状态,GC 停顿时间,GC 频率,堆栈内存使用量等监控。实时采集每个当前正在运行的服务的这些指标,分别针对各项指标设置报警阈值,例如针对协程数量和 GC 停顿时间。另一方面,我们也在尝试做一些运行时服务的堆栈和运行状态的快照,方便追查一些无法复现的进程重启的情况。
编程思维和工程性
相对于传统 Web 编程语言,Go 在编程思维上的确带来了许多的改变。每一个 Go 开发服务都是一个独立的进程,任何一个请求处理造成 Panic,都会让整个进程退出,因此当启动一个协程的时候需要考虑是否需要使用 recover 方法,避免影响其它协程。对于 Web 服务端开发,往往希望将一个请求处理的整个过程能够串起来,这就非常依赖于 Thread Local 的变量,而在 Go 语言中并没有这个概念,因此需要在函数调用的时候传递 context。
最后,使用 Go 开发的项目中,并发是一种常态,因此就需要格外注意对共享资源的访问,临界区代码逻辑的处理,会增加更多的心智负担。这些编程思维上的差异,对于习惯了传统 Web 后端开发的开发者,需要一个转变的过程。
关于工程性,也是 Go 语言不太所被提起的点。实际上在 Go 官方网站关于为什么要开发 Go 语言里面就提到,目前大多数语言当代码量变得巨大之后,对代码本身的管理以及依赖分析变得异常苦难,因此代码本身成为了最麻烦的点,很多庞大的项目到最后都变得不敢去动它。而 Go 语言不同,其本身设计语法简单,类C的风格,做一件事情不会有很多种方法,甚至一些代码风格都被定义到 Go 编译器的要求之内。而且,Go 语言标准库自带了源代码的分析包,可以方便地将一个项目的代码转换成一颗 AST 树。
 下面以一张图形象地表达下 Go 语言的工程性:
下面以一张图形象地表达下 Go 语言的工程性:
 同样是拼成一个正方形,Go 只有一种方式,每个单元都是一致。而 Python 拼接的方式可能可以多种多样。
同样是拼成一个正方形,Go 只有一种方式,每个单元都是一致。而 Python 拼接的方式可能可以多种多样。
写在最后
今日头条使用 Go 语言构建了大规模的微服务架构,本文结合 Go 语言特性着重讲解了并发,超时控制,性能等在构建微服务中的实践。事实上,Go 语言不仅在服务性能上表现卓越,而且非常适合容器化部署,我们很大一部分服务已经运行于内部的私有云平台。结合微服务相关组件,我们正朝着 Cloud Native 架构演进。
作者介绍:
项超,今日头条高级研发工程师。2015年加入今日头条,负责服务化改造相关工作,在内部推广Go语言的使用,研发内部微服务框架kite,集成服务治理,负载均衡等多种微服务功能,实现了Go语言构建大规模微服务架构在头条的落地。曾就职于小米。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号