worker 启动时向 etcd 注册自己的信息,并设置一个带 TTL 的租约,每隔一段时间更新这个 TTL,如果该 worker 挂掉了,这个 TTL 就会 expire 并删除相应的 key。
1、通过etcd中的选主机制,我们实现了服务的高可用。同时利用systemd对etcd本身进行了保活,只要etcd服务所在的机器没有宕机,进程就具备了容灾性。
【实践】
https://github.com/etcd-io/etcd/blob/master/Documentation/op-guide/gateway.md
etcd gateway is a simple TCP proxy that forwards network data to the etcd cluster. The gateway is stateless and transparent;
When to use etcd gateway
Every application that accesses etcd must first have the address of an etcd cluster client endpoint. If multiple applications on the same server access the same etcd cluster, every application still needs to know the advertised client endpoints of the etcd cluster. If the etcd cluster is reconfigured to have different endpoints, every application may also need to update its endpoint list. This wide-scale reconfiguration is both tedious and error prone.
etcd gateway solves this problem by serving as a stable local endpoint. A typical etcd gateway configuration has each machine running a gateway listening on a local address and every etcd application connecting to its local gateway. The upshot is only the gateway needs to update its endpoints instead of updating each and every application.
In summary, to automatically propagate cluster endpoint changes, the etcd gateway runs on every machine serving multiple applications accessing the same etcd cluster.

你可以看到,按照分层模型,etcd 可分为 Client 层、API 网络层、Raft 算法层、逻辑层和存储层。这些层的功能如下:
Client 层:Client 层包括 client v2 和 v3 两个大版本 API 客户端库,提供了简洁易用的 API,同时支持负载均衡、节点间故障自动转移,可极大降低业务使用 etcd 复杂度,提升开发效率、服务可用性。
API 网络层:API 网络层主要包括 client 访问 server 和 server 节点之间的通信协议。一方面,client 访问 etcd server 的 API 分为 v2 和 v3 两个大版本。v2 API 使用 HTTP/1.x 协议,v3 API 使用 gRPC 协议。同时 v3 通过 etcd grpc-gateway 组件也支持 HTTP/1.x 协议,便于各种语言的服务调用。另一方面,server 之间通信协议,是指节点间通过 Raft 算法实现数据复制和 Leader 选举等功能时使用的 HTTP 协议。
Raft 算法层:Raft 算法层实现了 Leader 选举、日志复制、ReadIndex 等核心算法特性,用于保障 etcd 多个节点间的数据一致性、提升服务可用性等,是 etcd 的基石和亮点。
功能逻辑层:etcd 核心特性实现层,如典型的 KVServer 模块、MVCC 模块、Auth 鉴权模块、Lease 租约模块、Compactor 压缩模块等,其中 MVCC 模块主要由 treeIndex 模块和 boltdb 模块组成。
存储层:存储层包含预写日志 (WAL) 模块、快照 (Snapshot) 模块、boltdb 模块。其中 WAL 可保障 etcd crash 后数据不丢失,boltdb 则保存了集群元数据和用户写入的数据
https://mp.weixin.qq.com/s/IQEoXyewwXDc-BFl-ZpP5Q
Etcd集群的介绍和选主应用
1
背景介绍
在实际生产环境中,有很多应用在同一时刻只能启动一个实例,例如更新数据库的操作,多个实例同时更新不仅会降低系统性能,还可能导致数据的不一致。但是单点部署也使得系统的容灾性减弱,比如进程异常退出。目前进程保活,也有很多方案,如supervisor和systemd。但是,如果宿主机down掉呢?所有的进程保活方法都会无济于事。本文基于etcd自带的leader选举机制,轻松的使服务具备了高可用性。
2
Etcd简介
Etcd是一个开源的、高度一致的分布式key-value存储系统。由Go语言实现,具有很好的跨平台性。主要用于配置共享和服务发现。通过raft算法维护集群中各个节点的通信和数据一致性,节点之间是对等的关系,即使leader节点故障,会很快选举出新的leader,保证系统的正常运行。目前已广泛应用在kubernetes、ROOK、CoreDNS、M3、openstack等领域。
特性:
- 接口操作简单,提供了http+json和grpc接口。
- 可选的ssl客户端认证,支持https访问。
- 每个实例支持1000的QPS,适用于存储数据量小但更新和访问频繁的数据。
- 数据按照文件系统的方式,分层存储,数据持久化。
- 监视特定的键或目录的变化,并对值的更改做出响应,适用于消息的发布和订阅。
3
Etcd架构及工作原理
架构
Etcd的架构如下图所示,主要分为四部分。HTTP server、Store、Raft和WAL。
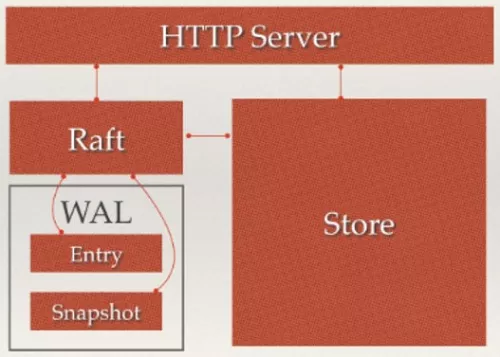
- HTTP server:为用户提供的Api请求。
- Store:用于处理 etcd 支持的各类功能的事务,包括数据索引、节点状态变更、监控与反馈、事件处理与执行等等。
- Raft:利用raft算法,保证节点之间数据的强一致性。
- WAL:数据存储方式。通过 WAL 进行数据持久化存储。Snapshot 存储数据的状态快照;Entry 表示存储的具体日志内容。
工作原理
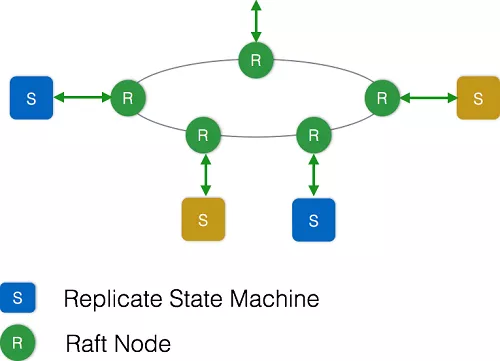
ETCD集群是一个分布式系统,每个ETCD节点都维护了一个状态机,并且存储了完整的数据,任意时刻至多存在一个有效的主节点。主节点处理所有来自客户端的读写操作。其中状态机的状态转换规则如下:

ETCD中每个节点的状态集合为(Follower、Candidate、Leader),集群初始化时候,每个节点都是Follower角色,当Follower在一定时间内没有收到来自主节点的心跳,会将自己角色改变为Candidate,并发起一次选主投票;当收到包括自己在内超过半数节点赞成后,选举成功;当收到票数不足半数选举失败,或者选举超时。若本轮未选出主节点,将进行下一轮选举。当某个Candidate节点成为Leader后,Leader节点会通过心跳与其他节点同步数据,同时参与竞选的Candidate节点进入Follower角色。
4
Etcd集群搭建及基本应用
部署环境
三台系统为centos7的虚机,IP地址如下:10.143.74.10810.202.252.14710.202.254.213下来以10.143.74.108为例,介绍安装与配置步骤。
一键安装etcd
1、创建安装脚本build.sh。
ETCD_VER=v3.4.7# choose either URLGOOGLE_URL=https://storage.googleapis.com/etcdGITHUB_URL=https://github.com/etcd-io/etcd/releases/downloadDOWNLOAD_URL=${GITHUB_URL}rm -f /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gzrm -rf /tmp/etcd-download-test && mkdir -p /tmp/etcd-download-testcurl -L ${DOWNLOAD_URL}/${ETCD_VER}/etcd-${ETCD_VER}-linux-amd64.tar.gz -o /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gztar xzvf /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz -C /tmp/etcd-download-test --strip-components=1rm -f /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gzcp /tmp/etcd-download-test/etcd /usr/binetcd --versioncp /tmp/etcd-download-test/etcdctl /usr/binetcdctl version
2、或者执行以下命令,脚本已上传到公网S3存储。
wget -qO- http://pub-shbt.s3.360.cn/v2s3/build-20200419214912.sh | bashetcd配置和systemd保活
1、 创建etcd配置文件/etc/etcd/etcd.conf。
ETCD_NAME=instance01ETCD_DATA_DIR="/usr/local/etcd/data"ETCD_LISTEN_CLIENT_URLS="http://10.143.74.108:2379,http://127.0.0.1:2379"ETCD_ADVERTISE_CLIENT_URLS="http://10.143.74.108:2379"ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.143.74.108:2380"ETCD_LISTEN_PEER_URLS="http://10.143.74.108:2380"ETCD_INITIAL_CLUSTER="instance01=http://10.143.74.108:2380,instance02=http://10.202.253.147:2380,instance03=http://10.202.254.213:2380"ETCD_INITIAL_CLUSTER_STATE=new
注释:
- ETCD_NAME:本member的名称;
- ETCD_DATA_DIR:存储数据的目录;
- ETCD_LISTEN_CLIENT_URLS:用于监听客户端etcdctl或者curl连接;
- ETCD_ADVERTISE_CLIENT_URLS: 本机地址, 用于通知客户端,客户端通过此IPs与集群通信;
- ETCD_INITIAL_ADVERTISE_PEER_URLS:本机地址,用于通知集群member,与member通信;
- ETCD_LISTEN_PEER_URLS:用于监听集群中其它member的连接;
- ETCD_INITIAL_CLUSTER:描述集群中所有节点的信息,本member根据此信息去联系其他member;
- ETCD_INITIAL_CLUSTER_STATE:集群状态,新建集群时候设置为new,若是想加入某个已经存在的集群设置为existing。
2、 创建etcd的systemd配置文件 /usr/lib/systemd/system/etcd.service。
[Unit]Description=Etcd ServerAfter=network.target[Service]Type=simpleWorkingDirectory=/var/lib/etcd/EnvironmentFile=-/etc/etcd/etcd.confExecStart=/usr/bin/etcdKillMode=processRestart=alwaysRestartSec=3LimitNOFILE=655350LimitNPROC=655350PrivateTmp=falseSuccessExitStatus=143[Install]WantedBy=multi-user.target
3、 启动etcd。
systemctl daemon-reloadsystemctl enable etcd.servicesystemctl start etcd.service
4、 查看etcd集群状态。
HOST_1=10.143.74.108HOST_2=10.202.253.147HOST_3=10.202.254.213ENDPOINTS=$HOST_1:2379,$HOST_2:2379,$HOST_3:2379etcdctl -w table --endpoints=$ENDPOINTS endpoint status
5
Etcd选主在Go中的实践
什么是选主机制呢?举个例子,在军事演习中,我们总会发现某架预警机周围分布着多架战斗机和歼击机,他们统一听从预警机的调度,有序的完成消灭敌军的任务。那么在这个集群中,预警机就类似于我们选主中的master,某个集群有且只有一个master,完成任务的分发等工作,其他节点配合行动,当这个master节点挂掉之后,要能够立刻选出新的节点作为master。下来我们一起看下项目中如何利用etcd的选主机制来实现应用的高可用吧。1、安装clientv3。
go get "github.com/coreos/etcd/clientv3"2、添加常量。
const prefix = "/nanoPing"const prop = "local"var leaderFlag bool
3、编写client节点竞选函数campaign。
func campaign(c *clientv3.Client, election string, prop string) {for {//gets the leased session for a clients, err := concurrency.NewSession(c, concurrency.WithTTL(15))if err != nil {log.Println(err)continue}//returns a new election on a given key prefixe := concurrency.NewElection(s, election)ctx := context.TODO()//Campaign puts a value as eligible for the election on the prefix key.//Multiple sessions can participate in the election for the same prefix,//but only one can be the leader at a timeif err = e.Campaign(ctx, prop); err != nil {log.Println(err)continue}log.Println("elect: success")leaderFlag = trueselect {case <-s.Done():leaderFlag = falselog.Println("elect: expired")}}}
4、添加竞选成功后执行的动作run。
func run() {log.Println("[info] Service master")log.Println("[info] Task start.")}
5、编写入口函数,创建client节点,参与竞选master,竞选成功,执行任务。
func Start() {donec := make(chan struct{})//create a clientcli, err := clientv3.New(clientv3.Config{Endpoints: g.Config().Etcd.Addr,Username:g.Config().Etcd.User,Password:g.Config().Etcd.Password})if err != nil {log.Fatal(err)}defer cli.Close()go campaign(cli, prefix, prop)go func() {ticker := time.NewTicker(time.Duration(10) * time.Second)for {select {case <-ticker.C:{if leaderFlag == true{run()return}else{log.Println("[info] Service is not master")}}}}}()<-donec}
6、 测试运行结果。选主成功的节点输出:
选主失败的节点输出:
Master节点进程退出后,之前的非master节点,自动竞选为master节点。
6
总结
通过etcd中的选主机制,我们实现了服务的高可用。同时利用systemd对etcd本身进行了保活,只要etcd服务所在的机器没有宕机,进程就具备了容灾性。当然,一个etcd集群,不仅仅可以对一个服务提供高可用,我们可以将多个服务注册在一个etcd集群中,同时利用etcd所提供的共享配置和服务发现,此外,etcd还有很多值得深入研究的技术,比如raft一致性算法等等,希望和大家能够一起深入交流。
相关文章
https://etcd.io/docs/v3.4.0/demo/
https://www.ipcpu.com/2017/09/etcd-start/
https://www.cnblogs.com/itzgr/p/9920910.html
etcd 快速入门 - 知乎 https://zhuanlan.zhihu.com/p/96428375
一、认识etcd
1.1 etcd 概念
从哪里说起呢?官网第一个页面,有那么一句话:
"A distributed, reliable key-value store for the most critical data of a distributed system"即 etcd 是一个分布式、可靠 key-value 存储的分布式系统。当然,它不仅仅用于存储,还提供共享配置及服务发现。
1.2 etcd vs Zookeeper
提供配置共享和服务发现的系统比较多,其中最为大家熟知的是 Zookeeper,而 etcd 可以算得上是后起之秀了。在项目实现、一致性协议易理解性、运维、安全等多个维度上,etcd 相比 zookeeper 都占据优势。
本文选取 Zookeeper 作为典型代表与 etcd 进行比较,而不考虑 Consul 项目作为比较对象,原因为 Consul 的可靠性和稳定性还需要时间来验证(项目发起方自身服务并未使用Consul,自己都不用)。
- 一致性协议: etcd 使用 Raft 协议,Zookeeper 使用 ZAB(类PAXOS协议),前者容易理解,方便工程实现;
- 运维方面:etcd 方便运维,Zookeeper 难以运维;
- 数据存储:etcd 多版本并发控制(MVCC)数据模型 , 支持查询先前版本的键值对
- 项目活跃度:etcd 社区与开发活跃,Zookeeper 感觉已经快死了;
- API:etcd 提供 HTTP+JSON, gRPC 接口,跨平台跨语言,Zookeeper 需要使用其客户端;
- 访问安全方面:etcd 支持 HTTPS 访问,Zookeeper 在这方面缺失;
...
1.3 etcd 应用场景
etcd 比较多的应用场景是用于服务发现,服务发现 (Service Discovery) 要解决的是分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务如何才能找到对方并建立连接。和 Zookeeper 类似,etcd 有很多使用场景,包括:
- 配置管理
- 服务注册发现
- 选主
- 应用调度
- 分布式队列
- 分布式锁
1.4 etcd 工作原理
1.4.1 如何保证一致性
etcd 使用 raft 协议来维护集群内各个节点状态的一致性。简单说,etcd 集群是一个分布式系统,由多个节点相互通信构成整体对外服务,每个节点都存储了完整的数据,并且通过 Raft 协议保证每个节点维护的数据是一致的。
每个 etcd 节点都维护了一个状态机,并且,任意时刻至多存在一个有效的主节点。主节点处理所有来自客户端写操作,通过 Raft 协议保证写操作对状态机的改动会可靠的同步到其他节点。
1.4.2 数据模型
etcd 的设计目标是用来存放非频繁更新的数据,提供可靠的 Watch插件,它暴露了键值对的历史版本,以支持低成本的快照、监控历史事件。这些设计目标要求它使用一个持久化的、多版本的、支持并发的数据数据模型。
当 etcd 键值对的新版本保存后,先前的版本依然存在。从效果上来说,键值对是不可变的,etcd 不会对其进行 in-place 的更新操作,而总是生成一个新的数据结构。为了防止历史版本无限增加,etcd 的存储支持压缩(Compact)以及删除老旧版本。
逻辑视图
从逻辑角度看,etcd 的存储是一个扁平的二进制键空间,键空间有一个针对键(字节字符串)的词典序索引,因此范围查询的成本较低。
键空间维护了多个修订版本(Revisions),每一个原子变动操作(一个事务可由多个子操作组成)都会产生一个新的修订版本。在集群的整个生命周期中,修订版都是单调递增的。修订版同样支持索引,因此基于修订版的范围扫描也是高效的。压缩操作需要指定一个修订版本号,小于它的修订版会被移除。
一个键的一次生命周期(从创建到删除)叫做 “代 (Generation)”,每个键可以有多个代。创建一个键时会增加键的版本(version),如果在当前修订版中键不存在则版本设置为1。删除一个键会创建一个墓碑(Tombstone),将版本设置为0,结束当前代。每次对键的值进行修改都会增加其版本号 — 在同一代中版本号是单调递增的。
当压缩时,任何在压缩修订版之前结束的代,都会被移除。值在修订版之前的修改记录(仅仅保留最后一个)都会被移除。
物理视图
etcd 将数据存放在一个持久化的 B+ 树中,处于效率的考虑,每个修订版仅仅存储相对前一个修订版的数据状态变化(Delta)。单个修订版中可能包含了 B+ 树中的多个键。
键值对的键,是三元组(major,sub,type):
- major:存储键值的修订版
- sub:用于区分相同修订版中的不同键
- type:用于特殊值的可选后缀,例如 t 表示值包含墓碑
键值对的值,包含从上一个修订版的 Delta。B+ 树 —— 键的词法字节序排列,基于修订版的范围扫描速度快,可以方便的从一个修改版到另外一个的值变更情况查找。
etcd 同时在内存中维护了一个 B 树索引,用于加速针对键的范围扫描。索引的键是物理存储的键面向用户的映射,索引的值则是指向 B+ 树修该点的指针。
1.5 etcd 读写性能
按照官网给出的数据, 在 2CPU,1.8G 内存,SSD 磁盘这样的配置下,单节点的写性能可以达到 16K QPS, 而先写后读也能达到12K QPS。这个性能还是相当可观。
1.6 etcd 术语

二、安装和运行
构建
需要Go 1.9以上版本:
cd $GOPATH/src
mkdir go.etcd.io && cd go.etcd.io
git clone https://github.com/etcd-io/etcd.git
cd etcd
./build使用 build 脚本构建会在当前项目的 bin 目录生产 etcd 和 etcdctl 可执行程序。etcd 就是 etcd server 了,etcdctl 主要为 etcd server 提供了命令行操作。
静态集群
如果Etcd集群成员是已知的,具有固定的IP地址,则可以静态的初始化一个集群。
每个节点都可以使用如下环境变量:
ETCD_INITIAL_CLUSTER="radon=http://10.0.2.1:2380,neon=http://10.0.3.1:2380"
ETCD_INITIAL_CLUSTER_STATE=new或者如下命令行参数
--initial-cluster radon=http://10.0.2.1:2380,neon=http://10.0.3.1:2380
--initial-cluster-state new来指定集群成员。
初始化集群
完整的命令行示例:
etcd --name radon --initial-advertise-peer-urls http://10.0.2.1:2380
--listen-peer-urls http://10.0.2.1:2380
--listen-client-urls http://10.0.2.1:2379,http://127.0.0.1:2379
--advertise-client-urls http://10.0.2.1:2380
# 所有以-initial-cluster开头的选项,在第一次运行(Bootstrap)后都被忽略
--initial-cluster-token etcd.gmem.cc
--initial-cluster radon=http://10.0.2.1:2380,neon=http://10.0.3.1:2380
--initial-cluster-state new使用TLS
Etcd支持基于TLS加密的集群内部、客户端-集群通信。每个集群节点都应该拥有被共享CA签名的证书:
# 密钥对、证书签名请求
openssl genrsa -out radon.key 2048
export SAN_CFG=$(printf "\n[SAN]\nsubjectAltName=IP:127.0.0.1,IP:10.0.2.1,DNS:radon.gmem.cc")
openssl req -new -sha256 -key radon.key -out radon.csr \
-subj "/C=CN/ST=BeiJing/O=Gmem Studio/CN=Server Radon" \
-reqexts SAN -config <(cat /etc/ssl/openssl.cnf <(echo $SAN_CFG))
# 执行签名
openssl x509 -req -sha256 -in radon.csr -out radon.crt -CA ../ca.crt -CAkey ../ca.key -CAcreateserial -days 3650 \
-extensions SAN -extfile <(echo "${SAN_CFG}")初始化集群命令需要修改为:
etcd --name radon --initial-advertise-peer-urls https://10.0.2.1:2380
--listen-peer-urls https://10.0.2.1:2380
--listen-client-urls https://10.0.2.1:2379,https://127.0.0.1:2379
--advertise-client-urls https://10.0.2.1:2380
# 所有以-initial-cluster开头的选项,在第一次运行(Bootstrap)后都被忽略
--initial-cluster-token etcd.gmem.cc
--initial-cluster radon=https://10.0.2.1:2380,neon=https://10.0.3.1:2380 # 指定集群成员列表
--initial-cluster-state new # 初始化新集群时使用
--initial-cluster-state existing # 加入已有集群时使用
# 客户端TLS相关参数
--client-cert-auth
--trusted-ca-file=/usr/share/ca-certificates/GmemCA.crt
--cert-file=/opt/etcd/cert/radon.crt
--key-file=/opt/etcd/cert/radon.key
# 集群内部TLS相关参数
--peer-client-cert-auth
--peer-trusted-ca-file=/usr/share/ca-certificates/GmemCA.crt
--peer-cert-file=/opt/etcd/cert/radon.crt
--peer-key-file=/opt/etcd/cert/radon.key三、与 etcd 交互
etcd 提供了 etcdctl 命令行工具 和 HTTP API 两种交互方法。etcdctl命令行工具用 go 语言编写,也是对 HTTP API 的封装,日常使用起来也更容易。所以这里我们主要使用 etcdctl 命令行工具演示。
put
应用程序通过 put 将 key 和 value 存储到 etcd 集群中。每个存储的密钥都通过 Raft 协议复制到所有 etcd 集群成员,以实现一致性和可靠性。
这里是设置键的值的命令 foo 到 bar:
$ etcdctl put foo bar
OKget
应用程序可以从一个 etcd 集群中读取 key 的值。
假设 etcd 集群已经存储了以下密钥:
foo = bar
foo1 = bar1
foo2 = bar2
foo3 = bar3
a = 123
b = 456
z = 789- 读取键为
foo的命令:
$ etcdctl get foo
foo // key
bar // value- 上面同时返回了 key 和 value,怎么只读取 key 对应的值呢:
$ etcdctl get foo --print-value-only
bar- 以十六进制格式读取键为
foo的命令:
$ etcdctl get foo --hex
\x66\x6f\x6f
\x62\x61\x72- 查询可以读取单个key,也可以读取一系列key:
$ etcdctl get foo foo3
foo
bar
foo1
bar1
foo2
bar2请注意,foo3由于范围超过了半开放时间间隔[foo, foo3),因此不包括在内foo3。
- 按前缀读取:
$ etcdctl get --prefix foo
foo
bar
foo1
bar1
foo2
bar2
foo3
bar3- 按结果数量限制读取
$ etcdctl get --limit=2 --prefix foo
foo
bar
foo1
bar1- 读取大于或等于指定键的字节值的键:
$ etcdctl get --from-key b
b
456
z
789应用程序可能希望通过访问早期版本的 key 来回滚到旧配置。由于对 etcd 集群键值存储区的每次修改都会增加一个 etcd 集群的全局修订版本,因此应用程序可以通过提供旧的 etcd 修订版来读取被取代的键。
假设一个 etcd 集群已经有以下 key:
foo = bar # revision = 2
foo1 = bar1 # revision = 3
foo = bar_new # revision = 4
foo1 = bar1_new # revision = 5以下是访问以前版本 key 的示例:
$ etcdctl get --prefix foo # 访问最新版本的key
foo
bar_new
foo1
bar1_new
$ etcdctl get --prefix --rev=4 foo # 访问第4个版本的key
foo
bar_new
foo1
bar1
$ etcdctl get --prefix --rev=3 foo # 访问第3个版本的key
foo
bar
foo1
bar1
$ etcdctl get --prefix --rev=2 foo # 访问第3个版本的key
foo
bar
$ etcdctl get --prefix --rev=1 foo # 访问第1个版本的keydel
应用程序可以从一个 etcd 集群中删除一个 key 或一系列 key。
假设一个 etcd 集群已经有以下key:
foo = bar
foo1 = bar1
foo3 = bar3
zoo = val
zoo1 = val1
zoo2 = val2
a = 123
b = 456
z = 789- 删除 key 为
foo的命令:
$ etcdctl del foo
1- 删除键值对的命令:
$ etcdctl del --prev-kv zoo
1
zoo
val- 删除从
foo到foo9的命令:
$ etcdctl del foo foo9
2- 删除具有前缀的键的命令:
$ etcdctl del --prefix zoo
2- 删除大于或等于键的字节值的键的命令:
$ etcdctl del --from-key b
2watch
应用程序可以使用watch观察一个键或一系列键来监视任何更新。
打开第一个终端,监听 foo的变化,我们输入如下命令:
$ etcdctl watch foo再打开另外一个终端来对 foo 进行操作:
$ etcdctl put foo 123
OK
$ etcdctl put foo 456
OK
$ ./etcdctl del foo
1第一个终端结果如下:
$ etcdctl watch foo
PUT
foo
123
PUT
foo
456
DELETE
foo除了以上基本操作,watch 也可以像 get、del 操作那样使用 prefix、rev、 hex等参数,这里就不一一列举了。
lock
Distributed locks: 分布式锁,一个人操作的时候,另外一个人只能看,不能操作
lock 可以通过指定的名字加锁。注意,只有当正常退出且释放锁后,lock命令的退出码是0,否则这个锁会一直被占用直到过期(默认60秒)
在第一个终端输入如下命令:
$ etcdctl lock mutex1
mutex1/326963a02758b52d在第二个终端输入同样的命令:
$ etcdctl lock mutex1从上可以发现第二个终端发生了阻塞,并未返回像 mutex1/326963a02758b52d 的字样。此时我们需要结束第一个终端的 lock ,可以使用 Ctrl+C 正常退出lock命令。第一个终端 lock 退出后,第二个终端的显示如下:
$ etcdctl lock mutex1
mutex1/694d6ee9ac069436txn
txn 从标准输入中读取多个请求,将它们看做一个原子性的事务执行。事务是由条件列表,条件判断成功时的执行列表(条件列表中全部条件为真表示成功)和条件判断失败时的执行列表(条件列表中有一个为假即为失败)组成的。
$ etcdctl put user frank
OK
$ ./etcdctl txn -i
compares:
value("user") = "frank"
success requests (get, put, del):
put result ok
failure requests (get, put, del):
put result failed
SUCCESS
OK
$ etcdctl get result
result
ok解释如下:
- 先使用 etcdctl put user frank 设置 user 为 frank
- etcdctl txn -i 开启事务(-i表示交互模式)
- 第2步输入命令后回车,终端显示出 compares:
- 输入 value("user") = "frank",此命令是比较 user 的值与 frank 是否相等
- 第 4 步完成后输入回车,终端会换行显示,此时可以继续输入判断条件(前面说过事务由条件列表组成),再次输入回车表示判断条件输入完毕
- 第 5 步连续输入两个回车后,终端显示出 success requests (get, put, delete):,表示下面输入判断条件为真时要执行的命令
- 与输入判断条件相同,连续两个回车表示成功时的执行列表输入完成
- 终端显示 failure requests (get, put, delete):后输入条件判断失败时的执行列表
- 为了看起来简洁,此实例中条件列表和执行列表只写了一行命令,实际可以输入多行
- 总结上面的事务,要做的事情就是 user 为 frank 时设置 result 为 ok,否则设置 result 为 failed
- 事务执行完成后查看 result 值为 ok
compact
正如我们所提到的,etcd保持修改,以便应用程序可以读取以前版本的 key。但是,为了避免累积无限的历史,重要的是要压缩过去的修订版本。压缩后,etcd删除历史版本,释放资源供将来使用。在压缩版本之前所有被修改的数据都将不可用。
$ etcdctl compact 5
compacted revision 5
$ etcdctl get --rev=4 foo
Error: etcdserver: mvcc: required revision has been compactedlease 与 TTL
etcd 也能为 key 设置超时时间,但与 redis 不同,etcd 需要先创建 lease,然后 put 命令加上参数 –lease= 来设置。lease 又由生存时间(TTL)管理,每个租约都有一个在授予时间由应用程序指定的最小生存时间(TTL)值。
以下是授予租约的命令:
$ etcdctl lease grant 30
lease 694d6ee9ac06945d granted with TTL(30s)
$ etcdctl put --lease=694d6ee9ac06945d foo bar
OK以下是撤销同一租约的命令:
$ etcdctl lease revoke 694d6ee9ac06945d
lease 694d6ee9ac06945d revoked
$ etcdctl get foo应用程序可以通过刷新其TTL来保持租约活着,因此不会过期。
假设我们完成了以下一系列操作:
$ etcdctl lease grant 10
lease 32695410dcc0ca06 granted with TTL(10s)以下是保持同一租约有效的命令:
$ etcdctl lease keep-alive 32695410dcc0ca06
lease 32695410dcc0ca06 keepalived with TTL(10)
lease 32695410dcc0ca06 keepalived with TTL(10)
lease 32695410dcc0ca06 keepalived with TTL(10)
...应用程序可能想要了解租赁信息,以便它们可以续订或检查租赁是否仍然存在或已过期。应用程序也可能想知道特定租约所附的 key。
假设我们完成了以下一系列操作:
$ etcdctl lease grant 200
lease 694d6ee9ac06946a granted with TTL(200s)
$ etcdctl put demo1 val1 --lease=694d6ee9ac06946a
OK
$ etcdctl put demo2 val2 --lease=694d6ee9ac06946a
OK以下是获取有关租赁信息的命令:
$ etcdctl lease timetolive 694d6ee9ac06946a
lease 694d6ee9ac06946a granted with TTL(200s), remaining(178s)以下是获取哪些 key 使用了租赁信息的命令:
$ etcdctl lease timetolive --keys 694d6ee9ac06946a
lease 694d6ee9ac06946a granted with TTL(200s), remaining(129s), attached keys([demo1 demo2])四、服务发现实战
如果有一个让系统可以动态调整集群大小的需求,那么首先就要支持服务发现。就是说当一个新的节点启动时,可以将自己的信息注册到 master,让 master 把它加入到集群里,关闭之后也可以把自己从集群中删除。这个情况,其实就是一个 membership protocol,用来维护集群成员的信息。
整个代码的逻辑很简单,worker 启动时向 etcd 注册自己的信息,并设置一个带 TTL 的租约,每隔一段时间更新这个 TTL,如果该 worker 挂掉了,这个 TTL 就会 expire 并删除相应的 key。发现服务监听 workers/ 这个 etcd directory,根据检测到的不同 action 来增加,更新,或删除 worker。
首先我们要建立一个 etcd client:
func NewMaster(endpoints []string) *Master {
// etcd 配置
cfg := client.Config{
Endpoints: endpoints,
DialTimeout: 5 * time.Second,
}
// 创建 etcd 客户端
etcdClient, err := client.New(cfg)
if err != nil {
log.Fatal("Error: cannot connect to etcd: ", err)
}
// 创建 master
master := &Master{
members: make(map[string]*Member),
API: etcdClient,
}
return master
}
这里我们先建立一个 etcd client,然后把它的 key API 放进 master 里面,这样我们以后只需要通过这个 API 来跟 etcd 进行交互。Endpoints 是指 etcd 服务器们的地址,如 ”http://127.0.0.1:2379“ 等。go master.WatchWorkers() 这一行启动一个 Goroutine 来监控节点的情况。下面是 WatchWorkers 的代码:
func (master *Master) WatchWorkers() {
// 创建 watcher channel
watcherCh := master.API.Watch(context.TODO(), "workers", client.WithPrefix())
// 从 chanel 取数据
for wresp := range watcherCh {
for _, ev := range wresp.Events {
key := string(ev.Kv.Key)
if ev.Type.String() == "PUT" { // put 方法
info := NodeToWorkerInfo(ev.Kv.Value)
if _, ok := master.members[key]; ok {
log.Println("Update worker ", info.Name)
master.UpdateWorker(key,info)
} else {
log.Println("Add worker ", info.Name)
master.AddWorker(key, info)
}
} else if ev.Type.String() == "DELETE" { // del 方法
log.Println("Delete worker ", key)
delete(master.members, key)
}
}
}
}
worker 这边也跟 master 类似,保存一个 etcd KeysAPI,通过它与 etcd 交互,然后用 heartbeat 来保持自己的状态,在 heartbeat 定时创建租约,如果租用失效,master 将会收到 delete 事件。代码如下:
func NewWorker(name, IP string, endpoints []string) *Worker {
// etcd 配置
cfg := client.Config {
Endpoints: endpoints,
DialTimeout: 5 * time.Second,
}
// 创建 etcd 客户端
etcdClient, err := client.New(cfg)
if err != nil {
log.Fatal("Error: cannot connect to etcd: ", err)
}
// 创建 worker
worker := &Worker {
Name: name,
IP: IP,
API: etcdClient,
}
return worker
}
func (worker *Worker) HeartBeat() {
for {
// worker info
info := &WorkerInfo{
Name: worker.Name,
IP: worker.IP,
CPU: runtime.NumCPU(),
}
key := "workers/" + worker.Name
value, _ := json.Marshal(info)
// 创建 lease
leaseResp, err := worker.API.Lease.Grant(context.TODO(), 10)
if err != nil {
log.Fatalf("设置租约时间失败:%s\n", err.Error())
}
// 创建 watcher channel
_, err = worker.API.Put(context.TODO(), key, string(value), client.WithLease(leaseResp.ID))
if err != nil {
log.Println("Error update workerInfo:", err)
}
time.Sleep(time.Second * 3)
}
}
启动的时候需要有多个 worker 节点(至少一个)和一个 master 节点,所以我们在启动程序的时候,可以传递一个 “role” 参数。代码如下:
var role = flag.String("role", "", "master | worker")
flag.Parse()
endpoints := []string{"http://127.0.0.1:2379"}
if *role == "master" {
master := discovery.NewMaster(endpoints)
master.WatchWorkers()
} else if *role == "worker" {
worker := discovery.NewWorker("localhost", "127.0.0.1", endpoints)
worker.HeartBeat()
} else {
...
}
项目地址: https://github.com/chapin666/etcd-service-discovery
五、总结
- etcd 默认只保存 1000 个历史事件,所以不适合有大量更新操作的场景,这样会导致数据的丢失。
- etcd 典型的应用场景是配置管理和服务发现,这些场景都是读多写少的。
- 相比于 zookeeper,etcd 使用起来要简单很多。不过要实现真正的服务发现功能,etcd 还需要和其他工具(比如 registrator、confd 等)一起使用来实现服务的自动注册和更新。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号