
倒排索引 获取指定单词的文档集合 使用hash去重单词term 提高数据压缩率的方法
- 中文名
- 倒排索引
- 外文名
- inverted index
- 构建方法
- 使用hash去重单词term
- 特殊要求
- 海量数据
https://baike.baidu.com/item/倒排索引/11001569?fr=aladdin
【获取指定单词的文档集合】
倒排索引
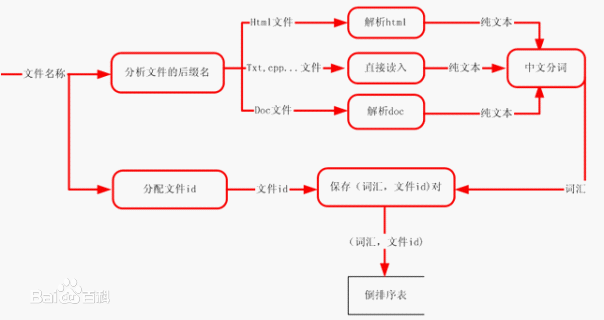
倒排索引(英语:Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
倒排索引
【单词到文档映射】
倒排索引有两种不同的反向索引形式:
一条记录的水平反向索引(或者反向档案索引)包含每个引用单词的文档的列表。
一个单词的水平反向索引(或者完全反向索引)又包含每个单词在一个文档中的位置。
后者的形式提供了更多的兼容性(比如短语搜索),但是需要更多的时间和空间来创建。
现代搜索引擎的索引都是基于倒排索引。相比“签名文件”、“后缀树”等索引结构,“倒排索引”是实现单词到文档映射关系的最佳实现方式和最有效的索引结构。 [2]
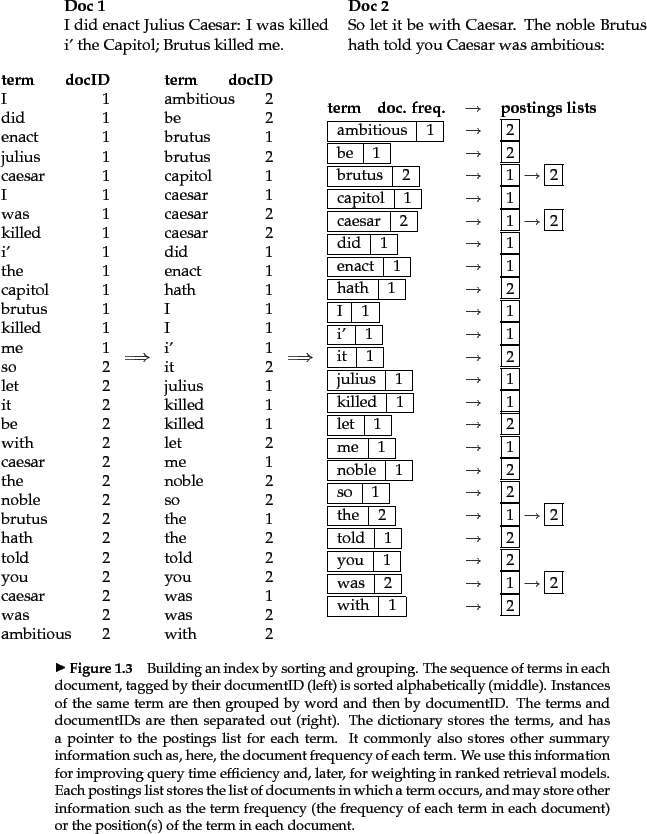
A first take at building an inverted index https://nlp.stanford.edu/IR-book/html/htmledition/a-first-take-at-building-an-inverted-index-1.html

倒排列表概念
之所以要对文档编号进行差值计算,主要原因是为了更好地对数据进行压缩,原始文档编号一般都是大数值,通过差值计算,就有效地将大数值转换为了小数值,而这有助于增加数据的压缩率。
Inverted Index | Elasticsearch: The Definitive Guide [2.x] | Elastic https://www.elastic.co/guide/en/elasticsearch/guide/current/inverted-index.html
Elasticsearch uses a structure called an inverted index, which is designed to allow very fast full-text searches. An inverted index consists of a list of all the unique words that appear in any document, and for each word, a list of the documents in which it appears.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号