解决视频库 加载问题
import imageio
imageio.plugins.ffmpeg.download()
Imageio: 'ffmpeg.win32.exe' was not found on your computer; downloading it now. Try 1. Download from https://github.com/imageio/imageio-binaries/raw/master/ffmpeg/ffmpeg.win32.exe (27.4 MB) Downloading: 8192/28781056 bytes (0.0%) 24576/28781056 bytes (0.1%) 32768/28781056 bytes (0.1%)
目的是拿到播放时间长
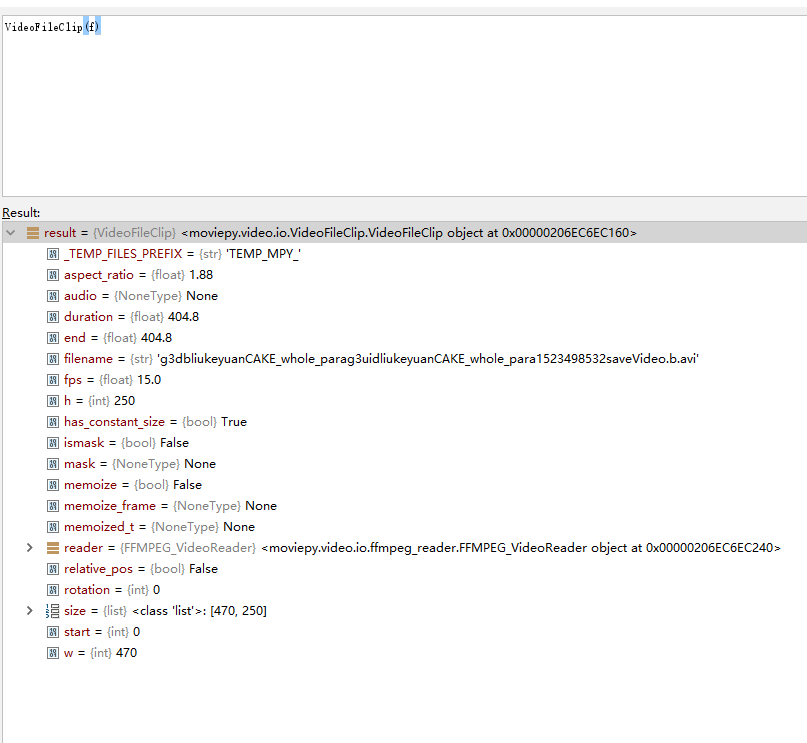
import imageio imageio.plugins.ffmpeg.download() from moviepy.editor import VideoFileClip f='g3dbliukeyuanCAKE_whole_parag3uidliukeyuanCAKE_whole_para1523498532saveVideo.b.avi' clip = VideoFileClip(f) print( clip.duration ) # seconds
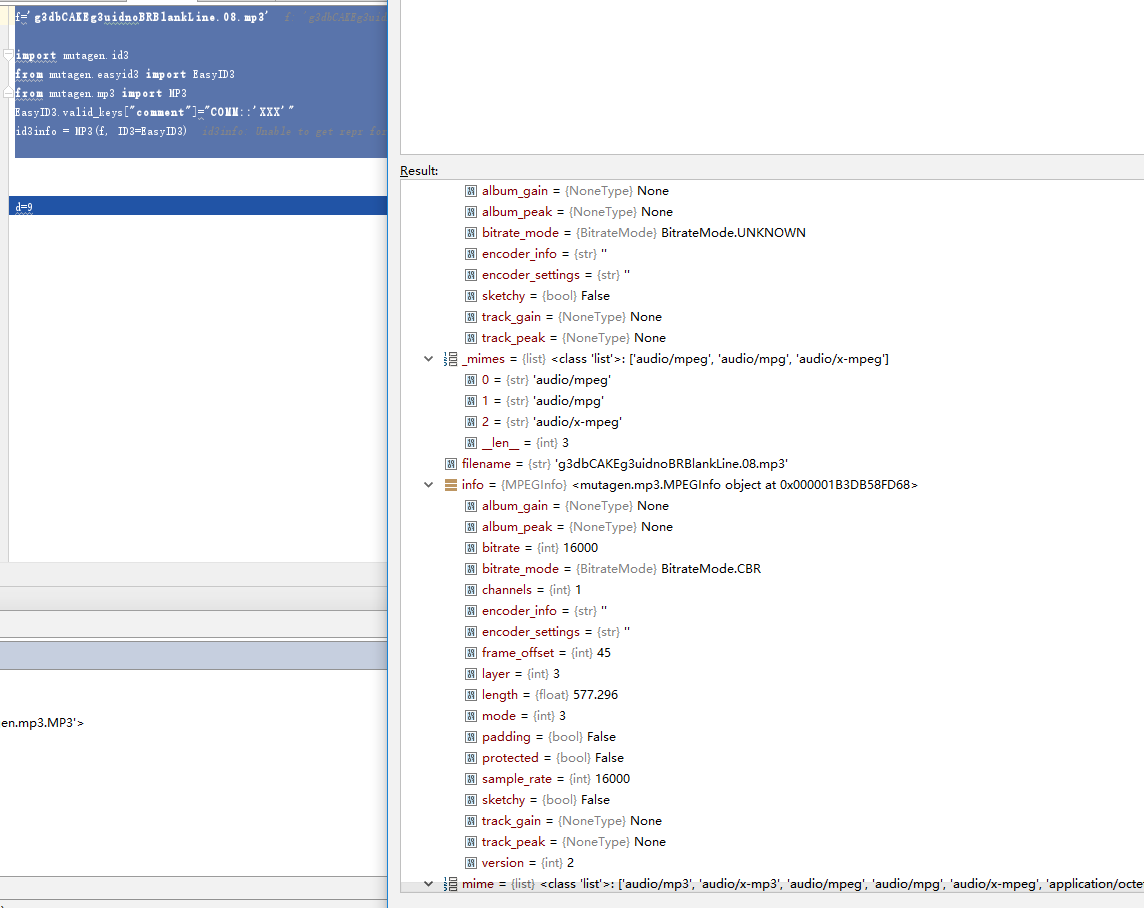
f='g3dbCAKEg3uidnoBRBlankLine.08.mp3' import mutagen.id3 from mutagen.easyid3 import EasyID3 from mutagen.mp3 import MP3 EasyID3.valid_keys["comment"]="COMM::'XXX'" id3info = MP3(f, ID3=EasyID3)
视频 音频 文件信息
# 设置分句的标志符号;可以根据实际需要进行修改
# cutlist = "。!?".decode('utf-8')
cutlist = ['\n', '\t', '。', ';', '?', '.', ';', '?', '...', '、、、', ':']
# cutlist = [ '。', ';', '?', '.', ';', '?', '...', '、、、',':',':',',']
# cutlist = [ '。', ';', '?', '.', ';', '?', '...', '、、、',':',',','、']
# 检查某字符是否分句标志符号的函数;如果是,返回True,否则返回False
def FindToken(cutlist, char):
if char in cutlist:
return True
else:
return False
# 进行分句的核心函数
def Cut(cutlist, lines): # 参数1:引用分句标志符;参数2:被分句的文本,为一行中文字符
l = [] # 句子列表,用于存储单个分句成功后的整句内容,为函数的返回值
line = [] # 临时列表,用于存储捕获到分句标志符之前的每个字符,一旦发现分句符号后,就会将其内容全部赋给l,然后就会被清空
for i in lines: # 对函数参数2中的每一字符逐个进行检查 (本函数中,如果将if和else对换一下位置,会更好懂)
if FindToken(cutlist, i): # 如果当前字符是分句符号
line.append(i) # 将此字符放入临时列表中
l.append(''.join(line)) # 并把当前临时列表的内容加入到句子列表中
line = [] # 将符号列表清空,以便下次分句使用
else: # 如果当前字符不是分句符号,则将该字符直接放入临时列表中
line.append(i)
return l
r_s = []
# 以下为调用上述函数实现从文本文件中读取内容并进行分句。
# with open('mybaidu.parp.b.txt','r',encoding='utf-8') as fr :
# for lines in fr:
# l = Cut(list(cutlist), list(lines))
# for line in l:
# if len(line.replace(' ', '')) == 0:
# continue
# if line.strip() != "":
# line=line.strip()
# r_s.append(line)
#
# # li = line.strip().split()
# # for sentence in li:
# # r_s.append(sentence)
str_ = ''
# cutlist = [ '。', ';', '?', '.', ';', '?', '...', '、、、',':',':',',','\n']
with open('mybaidu.parp.b.txt', 'r', encoding='utf-8') as fr:
for lines in fr:
if len(lines.replace(' ', '')) == 0:
continue
# str_='{}{}'.format(str_,lines.replace('\n',''))
# if len(lines.replace(' ','').replace('\n',''))==0:
# continue
str_ = '{}{}'.format(str_, lines)
# l = Cut(list(cutlist), list(lines))
# for line in l:
# if line.strip() != "":
# line=line.strip()
from aip import AipSpeech
bd_k_l = ['11059852', '5Kk01GtG2fjCwpzEkwdn0mjw', 'bp6Wyx377Elq7RsCQZzTBgGUFzLm8G2A']
APP_ID, API_KEY, SECRET_KEY = bd_k_l
mp3_dir = 'C:\\Users\\sas\\PycharmProjects\\produce_video\\result_liukeyun\\'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# result = client.synthesis(str_, 'zh', 1, {
# 'vol': 5,
# })
uid = 'liukeyuanCAKE_whole_para'
# 识别正确返回语音二进制 错误则返回dict 参照下面错误码
f_w = '{}{}{}{}{}'.format(mp3_dir, 'g3db', uid, 'g3uid', '.mp3')
#
# if not isinstance(result, dict):
# # f_w = '{}{}{}{}'.format(mp3_dir, 'g3uid', uid, '.mp3')
# f_w = '{}{}{}{}{}'.format(mp3_dir, 'g3db', uid, 'g3uid', '.mp3')
# # ,'g3db',uid,'g3uid'
# # with open('auido.b.mp3', 'wb') as f:
# with open(f_w, 'wb') as f:
# f.write(result)
sentence_l, sentence_l_chk = Cut(list(cutlist), list(str_)), []
for i in sentence_l:
chk_br = i.replace('\n', '')
# del sentence_l[sentence_l.index(i)]
if len(chk_br) > 0:
sentence_l_chk.append(chk_br)
sentence_l_chk = [i.replace(' ', '') for i in sentence_l_chk]
import os
import os, time, glob
import cv2
os_sep = os.sep
this_file_abspath = os.path.abspath(__file__)
this_file_dirname, this_file_name = os.path.dirname(this_file_abspath), os.path.abspath(__file__).split(os_sep)[
-1]
f_img_d = '{}{}{}{}{}'.format(this_file_dirname, os_sep, 'mypng', os_sep, '*.jpg')
imgs, img_size_d = glob.glob(f_img_d), {}
for i in imgs:
img = cv2.imread(i)
w_h_s = '{},{}'.format(img.shape[1], img.shape[0])
if w_h_s not in img_size_d:
img_size_d[w_h_s] = 1
else:
img_size_d[w_h_s] += 1
mode_img_size_wh = [int(i) for i in
sorted(img_size_d.items(), key=lambda mytuple: mytuple[1], reverse=True)[0][0].split(',')]
import os
os_sep = os.sep
this_file_abspath = os.path.abspath(__file__)
this_file_dirname, this_file_name = os.path.dirname(this_file_abspath), os.path.abspath(__file__).split(os_sep)[-1]
f_mp3 = '{}{}{}'.format(this_file_dirname, os_sep, 'auido.mp3')
from playsound import playsound
import time
import math
this_time = time.time()
f_mp3 = f_w
# # playsound(f_mp3)
#
# # t_spend = time.time() - this_time
# # t_spend = 58.777058839797974
# # 音频的秒数
# # t_spend = 115.18474054336548
# # t_spend = 420.18474054336548
# # t_spend = 337.18474054336548
# t_spend = 362.5
# t_spend = 335.5
# #937
# t_spend = 577
# t_spend = math.ceil(t_spend)
f_mp3 = 'g3dbCAKEg3uidnoBRBlankLine.08.mp3'
import mutagen.id3
from mutagen.easyid3 import EasyID3
from mutagen.mp3 import MP3
EasyID3.valid_keys["comment"] = "COMM::'XXX'"
id3info = MP3(f_mp3, ID3=EasyID3)
t_spend = id3info.info.length
import cv2
import glob
'''
python+opencv视频图像相互转换 - CSDN博客 https://blog.csdn.net/m0_37733057/article/details/79023693
链接:https://www.zhihu.com/question/49558804/answer/343058915
OpenCV: Drawing Functions in OpenCV https://docs.opencv.org/3.1.0/dc/da5/tutorial_py_drawing_functions.html
'''
# 每秒传输帧数(Frames Per Second)
fps = 100 # 保存视频的FPS,可以适当调整 FPS是图像领域中的定义,是指画面每秒传输帧数,通俗来讲就是指动画或视频的画面数。FPS是测量用于保存、显示动态视频的信息数量。每秒钟帧数愈多,所显示的动作就会愈流畅。通常,要避免动作不流畅的最低是30。某些计算机视频格式,每秒只能提供15帧。
f_img_d = '{}{}{}{}{}'.format(this_file_dirname, os_sep, 'mypng', os_sep, '*.jpg')
imgs = glob.glob(f_img_d)
"""
用图片总数均分音频时间
"""
f, l = 'mybaidu.parp.b.txt', []
with open(f, 'r', encoding='utf-8') as fr:
for i in fr:
ii = i.replace('\n', '')
l.append(ii)
char_loop_l = []
for i in l:
mystr, le = '', len(i)
for ii in range(le):
iii = i[ii]
# print('-----', iii)
mystr = '{}{}'.format(mystr, iii)
# print(mystr)
char_loop_l.append(iii)
#
# from fontTools.ttLib import TTFont
# myfont = TTFont('simhei.ttf')
def resize_rescale_pilimg(img_f, w_h_tuple=(mode_img_size_wh[0], mode_img_size_wh[1]), mid_factor=1):
# print(img_f)
img_n, img_type = img_f.split('.')[-2], img_f.split('.')[-1]
# print(img_n)
img_n_resize_rescale_pilimg_dir = '{}{}{}'.format(os_sep.join(img_n.split(os_sep)[:-1]), 'resize_rescale_pilimg',
os_sep, img_n.split(os_sep)[-1], os_sep)
img_n_resize_rescale_pilimg = '{}{}{}'.format(img_n_resize_rescale_pilimg_dir, img_n.split(os_sep)[-1], '.PNG')
# print(img_n_resize_rescale_pilimg)
img_type = 'PNG'
# img_f_new = '{}{}{}{}'.format(img_n, int(time.time()), 'resize_rescale.', img_type)
img_f_new = img_n_resize_rescale_pilimg
mid_icon = Image.open(img_f)
mid_icon_w, mid_icon_h = w_h_tuple[0] * mid_factor, w_h_tuple[1] * mid_factor
mid_icon = mid_icon.resize((mid_icon_w, mid_icon_h), Image.ANTIALIAS)
mid_icon.save(img_n_resize_rescale_pilimg, img_type)
return img_f_new
def compute_video_playtime(f):
# Create a VideoCapture object and read from input file
# If the input is the camera, pass 0 instead of the video file name
cap = cv2.VideoCapture(f)
# Check if camera opened successfully
if (cap.isOpened() == False):
print("Error opening video stream or file")
# Read until video is completed
while (cap.isOpened()):
# Capture frame-by-frame
ret, frame = cap.read()
if ret == True:
# Display the resulting frame
cv2.imshow('Frame', frame)
# Press Q on keyboard to exit
if cv2.waitKey(25) & 0xFF == ord('q'):
break
# Break the loop
else:
break
# When everything done, release the video capture object
cap.release()
# Closes all the frames
cv2.destroyAllWindows()
return time.time() - this_time
from PIL import Image, ImageDraw, ImageFont
# myfont = ImageFont.truetype("simhei.ttf", 50, encoding="utf-8")
myfont = ImageFont.truetype("simhei.ttf", encoding="utf-8")
import cv2
import numpy as np
l = sentence_l_chk
char_loop_l = sentence_l_chk
# 2个空格有别于1个空格
# char_loop_l_len = len(''.join(sentence_l_chk).replace(' ', '')) + 2*len(char_loop_l)
# char_loop_l_len = 3*len(char_loop_l)
char_loop_l_len = len(char_loop_l)
char_loop_l_len = len(''.join(sentence_l_chk))
char_loop_l_len = len(''.join(sentence_l_chk).replace(' ', ''))
# char_loop_l_len=len(char_loop_l)
'''
'''
# l=sentence_l_chk
# char_loop_l=sentence_l_chk
# #2个空格有别于1个空格
# char_loop_l_len=len(char_loop_l)
#
#
import imageio
imageio.plugins.ffmpeg.download()
from moviepy.editor import VideoFileClip
# f='g3dbliukeyuanCAKE_whole_parag3uidliukeyuanCAKE_whole_para1523498532saveVideo.b.avi'
#
# clip = VideoFileClip(f)
def gen_video(os_delay_factor=0.245, mystep=0.01, bear_error_second=1, audio_spend=t_spend, step_para=1):
f_v = '{}{}'.format(int(time.time()), 'saveVideo.b.avi')
f_v = '{}{}{}{}{}{}{}'.format('D:\\myv\\', 'g3db', uid, 'g3uid', uid, int(time.time()), 'saveVideo.b.avi')
fps, fourcc = 15, cv2.VideoWriter_fourcc('M', 'J', 'P', 'G')
# fourcc = cv2.VideoWriter_fourcc('M', 'J', 'P', 'G') # opencv3.0
videoWriter = cv2.VideoWriter(f_v, fourcc, fps, (mode_img_size_wh[0], mode_img_size_wh[1]))
# f_v = '{}{}'.format(int(time.time()), 'saveVideo.b.avi')
for i in l:
myinterval = t_spend / (char_loop_l_len * 1) * os_delay_factor
i_index = l.index(i)
img_index = i_index % len(imgs)
imgname = imgs[img_index]
mystr = ''
le = len(i)
br_step = 34
br_times = math.ceil(le / br_step)
l_tmp = []
for i_br_loop in range(br_times):
i_br = i[i_br_loop * br_step:i_br_loop * br_step + br_step]
l_tmp.append(i_br)
mystr = '\n'.join(l_tmp)
print(mystr)
this_time = time.time()
'''
!!!!!!!!!!!!!!!!
'''
# myinterval*=le
myinterval *= len(mystr.replace(' ', '').replace('\n', ''))
while time.time() - this_time < myinterval:
frame = cv2.imread(imgname)
del_f = False
if (frame.shape[1], frame.shape[0]) != (mode_img_size_wh[0], mode_img_size_wh[1]):
imgname = resize_rescale_pilimg(imgname)
frame = cv2.imread(imgname)
del_f = True
else:
pass
frame_cv2 = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame_pil = Image.fromarray(frame_cv2) # 转为PIL的图片格式
# font = ImageFont.truetype("simhei.ttf", 50, encoding="utf-8")
font = ImageFont.truetype("simhei.ttf", encoding="utf-8")
ImageDraw.Draw(frame_pil).text((100, 20), mystr, (0, 0, 255), font)
frame_cv2 = cv2.cvtColor(np.array(frame_pil), cv2.COLOR_RGB2BGR)
img = frame_cv2
videoWriter.write(img)
# 换图 延迟
# videoWriter.write(img)
# if del_f:
# if os.path.exists(imgname):
# print(imgname)
# print('del')
# # 删除文件,可使用以下两种方法。
# os.remove(imgname)
# # os.unlink(my_file)
# else:
# pass
videoWriter.release()
time.sleep(1)
# video_playtime = compute_video_playtime(f_v)
# f = 'g3dbliukeyuanCAKE_whole_parag3uidliukeyuanCAKE_whole_para1523498532saveVideo.b.avi'
video_playtime = VideoFileClip(f_v).duration
if video_playtime - audio_spend > bear_error_second:
# os_delay_factor -= mystep
os_delay_factor *= t_spend / video_playtime
gen_video(os_delay_factor=os_delay_factor, mystep=0.005, audio_spend=t_spend)
elif audio_spend - video_playtime > bear_error_second:
# os_delay_factor += mystep
os_delay_factor *= t_spend / video_playtime
gen_video(os_delay_factor=os_delay_factor, mystep=0.005, audio_spend=t_spend)
else:
os._exit(123)
mycom = 0.19928228783504076 * 577 / 615
# gen_video(os_delay_factor=1, mystep=0.003, bear_error_second=0.5, audio_spend=t_spend)
mycom = 577 / 1030 * 0.3
mycom = 577 / 1025 * 0.17858123692538752
mycom = 577 / 328 * 0.10052816946921814
gen_video(os_delay_factor=mycom, mystep=0.003, bear_error_second=0.5, audio_spend=t_spend)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号