序列化 serialize
https://zh.wikipedia.org/wiki/序列化
序列化(serialization)在计算机科学的资料处理中,是指将数据结构或对象状态转换成可取用格式(例如存成文件,存于缓冲,或经由网络中发送),以留待后续在相同或另一台计算机环境中,能恢复原先状态的过程。依照序列化格式重新获取字节的结果时,可以利用它来产生与原始对象相同语义的副本。对于许多对象,像是使用大量引用的复杂对象,这种序列化重建的过程并不容易。面向对象中的对象序列化,并不概括之前原始对象所关系的函数。这种过程也称为对象编组(marshalling)。从一系列字节提取数据结构的反向操作,是反序列化(也称为解编组、deserialization、unmarshalling)。
序列化在计算机科学中通常有以下定义:
- 对同步控制而言,表示强制在同一时间内进行单一访问。
- 在数据储存与发送的部分是指将一个对象存储至一个存储介质,例如文件或是存储器缓冲等,或者透过网络发送资料时进行编码的过程,可以是字节或是XML等格式。而字节的或XML编码格式可以还原完全相等的对象。这程序被应用在不同应用程序之间发送对象,以及服务器将对象存储到文件或数据库。相反的过程又称为反序列化。
用途[编辑]
- 经由电信线路传输资料的方法(通信)。
- 存储资料的方法(在数据库或硬盘)。
- 远程程序调用的方法,例如在SOAP中。
- 在以组件为基础,例如COM,CORBA的软件工程中,是对象的分布式方法。
- 检测随时间资料变动的方法。
为了达成上述功能其一能有效作用,则必须与硬件结构保持独立性。譬如说为了能最大化分布式的使用,在不同硬件运行的计算机,应该能够可靠地重建序列化资料流,而不依赖于字节序。虽然直接复拷存储器中的数据结构更简便又快速,可是对于其它不同硬件的机器,却无法可靠地运作。以独立于硬件之外的格式来序列化数据结构,要避开字节序、存储器布局、或在不同编程语言中数据结构如何表示等等之类的问题。
对于任何序列化方案的本质来说,因为资料编码是根据定义连续串在一起的,提取序列化数据结构中的某一部分,则需要从头到尾读取整个对象并且重新建构。这样的资料线性在许多应用中是有利的,因为它使输出入接口简单而共同,能被用来保持及传递对象的状态。
要求高性能的应用时,花费精力处理更复杂的非线性存储系统是有其必要意义的。即使在单一机器上,原始的指针对象也非常脆弱无法保存,因为它们指向的标地可能重新加载到内存中的不同地址。为了处理这个问题,序列化过程包括一个步骤:将引用的直接指针转换为以名称或位置的间接引用,称之为不挥发(unswizzling)或者指针不挥发。反序列化过程则包括了称为指针旋转(swizzling)的反向步骤。由于序列化和反序列化可从共通代码(例如,微软MFC中的Serialize函数)驱动,所以共通代码可同时进行两次,因此,
- 检测要序列化的对象与其先前副本之间的差异,
- 提供下一次这种检测的输入。因为差异可以被即时检测,所以不必再重新创建先前的副本。该技术称为差异分辨执行。
这技术应用在内容随时间变化的用户界面编程中-依照输入事件来处理图形对象的产生、移除、更改或制作,而无需编写另外的代码执行这些操作。
缺点[编辑]
序列化可能会破解抽象资料类型的封装实现,而使其详细内容曝光。简单的序列化实现可能违反面向对象中私有资料成员需要封装(encapsulation)的原则。商用软件的出版商通常会将应用软件的序列化格式,当作商业秘密,以阻碍竞争对手生产可兼容的产品;有些会蓄意地混淆,或甚至将序列化资料作加密处理。然而,互通可用性的要求应用程序能够理解彼此的序列化格式。因此,像CORBA的远程方法调用架构详细定义了它们的序列化格式。许多机构,例如档案馆和图书馆,尝试将他们的备份文件-特别是数据库抛档(dump),存储成一些相对具可读性的序列化格式中,使备份资料不因信息技术变迁而过时。
序列化格式[编辑]
20世纪80年代初的施乐网络系统快递技术影响了第一个广泛采用的标准。Sun Microsystems在1987年发布了外部数据表示法(XDR)。90年代后期开始推动标准序列化的协议:XML(可扩展标记语言)应用于产生人类可读的文字编码。资料以这样的编码使存续的对象能有效用,无论相对于人是否可阅读与理解,或与编程语言无关地传递给其它信息系统。它缺点是失去了扎实的编码字节流,但截至目前技术上所提供大量的存储和传输容量,使得文件大小的考量,已不同于早期计算机科学的重视程度。
二进制XML被提议作为一种妥协方式,它不能被纯文本编辑器读取,但比一般XML更为扎实。在二十一世纪的Ajax技术网页中,XML经常应用于结构化资料在客端和服务端之间的异步传输。相较于XML,JSON是一种轻量级的纯文字替代,也常用于网页应用中的客端-服务端通信。JSON肇基于JavaScript语法所派生,但也广为其它编程语言所支持。与JSON类似的另一个替代方案是YAML,它包含加强序列化的功能,更“人性化”而且更扎实。这些功能包括标记资料类型,支持非层次结构式数据结构,缩进结构化资料的选项以及多种形式的标量资料引用的概念。
另一种可读的序列化格式是属性列表(property list)。应用在NeXTSTEP、GNUstep和macOS Cocoa环境中。
针对于科学使用的大量资料集合,例如气候,海洋模型和卫星数据,已经开发了特定的二进制序列化标准,例如HDF,netCDF和较旧的GRIB。
Serialization - Wikipedia https://en.wikipedia.org/wiki/Serialization
In computing, serialization (US spelling) or serialisation (UK spelling) is the process of translating a data structure or object state into a format that can be stored (for example, in a file or memory data buffer) or transmitted (for example, over a computer network) and reconstructed later (possibly in a different computer environment).[1] When the resulting series of bits is reread according to the serialization format, it can be used to create a semantically identical clone of the original object. For many complex objects, such as those that make extensive use of references, this process is not straightforward. Serialization of object-oriented objects does not include any of their associated methods with which they were previously linked.
This process of serializing an object is also called marshalling an object in some situations.[2][3][4] The opposite operation, extracting a data structure from a series of bytes, is deserialization, (also called unserialization or unmarshalling).
Uses[edit]
Methods of:
- transferring data through the wires (messaging).
- storing data (in databases, on hard disk drives).
- remote procedure calls, e.g., as in SOAP.
- distributing objects, especially in component-based software engineering such as COM, CORBA, etc.
- detecting changes in time-varying data.
For some of these features to be useful, architecture independence must be maintained. For example, for maximal use of distribution, a computer running on a different hardware architecture should be able to reliably reconstruct a serialized data stream, regardless of endianness. This means that the simpler and faster procedure of directly copying the memory layout of the data structure cannot work reliably for all architectures. Serializing the data structure in an architecture-independent format means preventing the problems of byte ordering, memory layout, or simply different ways of representing data structures in different programming languages.
Inherent to any serialization scheme is that, because the encoding of the data is by definition serial, extracting one part of the serialized data structure requires that the entire object be read from start to end, and reconstructed. In many applications, this linearity is an asset, because it enables simple, common I/O interfaces to be utilized to hold and pass on the state of an object. In applications where higher performance is an issue, it can make sense to expend more effort to deal with a more complex, non-linear storage organization.
Even on a single machine, primitive pointer objects are too fragile to save because the objects to which they point may be reloaded to a different location in memory. To deal with this, the serialization process includes a step called unswizzling or pointer unswizzling, where direct pointer references are converted to references based on name or position. The deserialization process includes an inverse step called pointer swizzling.
Since both serializing and deserializing can be driven from common code (for example, the Serialize function in Microsoft Foundation Classes), it is possible for the common code to do both at the same time, and thus, 1) detect differences between the objects being serialized and their prior copies, and 2) provide the input for the next such detection. It is not necessary to actually build the prior copy because differences can be detected on the fly, a technique called differential execution. This is useful in the programming of user interfaces whose contents are time-varying — graphical objects can be created, removed, altered, or made to handle input events without necessarily having to write separate code to do those things.
Drawbacks[edit]
Serialization breaks the opacity of an abstract data type by potentially exposing private implementation details. Trivial implementations which serialize all data members may violate encapsulation.[5]
To discourage competitors from making compatible products, publishers of proprietary software often keep the details of their programs' serialization formats a trade secret. Some deliberately obfuscate or even encrypt the serialized data. Yet, interoperability requires that applications be able to understand each other's serialization formats. Therefore, remote method call architectures such as CORBA define their serialization formats in detail.
Many institutions, such as archives and libraries, attempt to future proof their backup archives—in particular, database dumps—by storing them in some relatively human-readable serialized format.
Serialization formats[edit]
The Xerox Network Systems Courier technology in the early 1980s influenced the first widely adopted standard. Sun Microsystems published the External Data Representation (XDR) in 1987.[6] XDR is an open format, and standardized as STD 67 (RFC 4506).
In the late 1990s, a push to provide an alternative to the standard serialization protocols started: XML, an SGML subset, was used to produce a human readable text-based encoding. Such an encoding can be useful for persistent objects that may be read and understood by humans, or communicated to other systems regardless of programming language. It has the disadvantage of losing the more compact, byte-stream-based encoding, but by this point larger storage and transmission capacities made file size less of a concern than in the early days of computing. In the 2000s, XML was often used for asynchronous transfer of structured data between client and server in Ajax web applications. XML is an open format, and standardized as a W3C recommendation.
JSON, is a lighter plain-text alternative to XML which is also commonly used for client-server communication in web applications. JSON is based on JavaScript syntax, but is independent of JavaScript and supported in other programming languages as well. JSON is an open format, standardized as STD 90 (RFC 8259), ECMA-404, and ISO/IEC 21778:2017.
YAML, is a strict JSON superset and includes additional features such as a notion of tagging data types, support for non-hierarchical data structures, the option to structure data with indentation, and multiple forms of scalar data quoting. YAML is an open format.
Property lists are used for serialization by NeXTSTEP, GNUstep, macOS, and iOS frameworks. Property list, or p-list for short, doesn't refer to a single serialization format but instead several different variants, some human-readable and one binary.
For large volume scientific datasets, such as satellite data and output of numerical climate, weather, or ocean models, specific binary serialization standards have been developed, e.g. HDF, netCDF and the older GRIB.
Serialization and Deserialization in Java with Example - GeeksforGeeks https://www.geeksforgeeks.org/serialization-in-java/
The byte stream created is platform independent. So, the object serialized on one platform can be deserialized on a different platform.

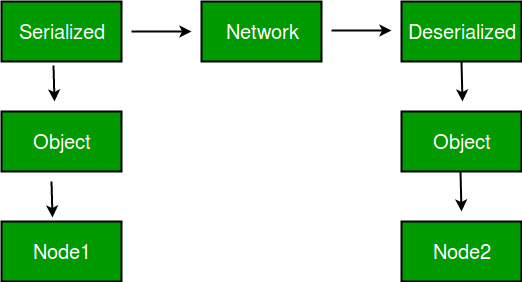
Serialization (C#) | Microsoft Docs https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/concepts/serialization/
Serialization (C#)
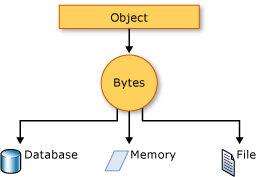
Serialization is the process of converting an object into a stream of bytes to store the object or transmit it to memory, a database, or a file. Its main purpose is to save the state of an object in order to be able to recreate it when needed. The reverse process is called deserialization.
How serialization works
This illustration shows the overall process of serialization:

The object is serialized to a stream that carries the data. The stream may also have information about the object's type, such as its version, culture, and assembly name. From that stream, the object can be stored in a database, a file, or memory.
Uses for serialization
Serialization allows the developer to save the state of an object and re-create it as needed, providing storage of objects as well as data exchange. Through serialization, a developer can perform actions such as:
- Sending the object to a remote application by using a web service
- Passing an object from one domain to another
- Passing an object through a firewall as a JSON or XML string
- Maintaining security or user-specific information across applications
JSON serialization
The System.Text.Json namespace contains classes for JavaScript Object Notation (JSON) serialization and deserialization. JSON is an open standard that is commonly used for sharing data across the web.
JSON serialization serializes the public properties of an object into a string, byte array, or stream that conforms to the RFC 8259 JSON specification. To control the way JsonSerializer serializes or deserializes an instance of the class:
- Use a JsonSerializerOptions object
- Apply attributes from the System.Text.Json.Serialization namespace to classes or properties
- Implement custom converters
Binary and XML serialization
The System.Runtime.Serialization namespace contains classes for binary and XML serialization and deserialization.
Binary serialization uses binary encoding to produce compact serialization for uses such as storage or socket-based network streams. In binary serialization, all members, even members that are read-only, are serialized, and performance is enhanced.
Warning
Binary serialization can be dangerous. For more information, see BinaryFormatter security guide.
XML serialization serializes the public fields and properties of an object, or the parameters and return values of methods, into an XML stream that conforms to a specific XML Schema definition language (XSD) document. XML serialization results in strongly typed classes with public properties and fields that are converted to XML. System.Xml.Serialization contains classes for serializing and deserializing XML. You apply attributes to classes and class members to control the way the XmlSerializer serializes or deserializes an instance of the class.
Making an object serializable
For binary or XML serialization, you need:
- The object to be serialized
- A stream to contain the serialized object
- A System.Runtime.Serialization.Formatter instance
Apply the SerializableAttribute attribute to a type to indicate that instances of the type can be serialized. An exception is thrown if you attempt to serialize but the type doesn't have the SerializableAttribute attribute.
To prevent a field from being serialized, apply the NonSerializedAttribute attribute. If a field of a serializable type contains a pointer, a handle, or some other data structure that is specific to a particular environment, and the field cannot be meaningfully reconstituted in a different environment, then you may want to make it nonserializable.
If a serialized class contains references to objects of other classes that are marked SerializableAttribute, those objects will also be serialized.
Basic and custom serialization
Binary and XML serialization can be performed in two ways, basic and custom.
Basic serialization uses .NET to automatically serialize the object. The only requirement is that the class has the SerializableAttributeattribute applied. The NonSerializedAttribute can be used to keep specific fields from being serialized.
When you use basic serialization, the versioning of objects may create problems. You would use custom serialization when versioning issues are important. Basic serialization is the easiest way to perform serialization, but it does not provide much control over the process.
In custom serialization, you can specify exactly which objects will be serialized and how it will be done. The class must be marked SerializableAttribute and implement the ISerializable interface. If you want your object to be deserialized in a custom manner as well, use a custom constructor.
Designer serialization
Designer serialization is a special form of serialization that involves the kind of object persistence associated with development tools. Designer serialization is the process of converting an object graph into a source file that can later be used to recover the object graph. A source file can contain code, markup, or even SQL table information.
Related Topics and Examples
System.Text.Json overview Shows how to get the System.Text.Json library.
How to serialize and deserialize JSON in .NET. Shows how to read and write object data to and from JSON using the JsonSerializerclass.
Walkthrough: Persisting an Object in Visual Studio (C#)
Demonstrates how serialization can be used to persist an object's data between instances, allowing you to store values and retrieve them the next time the object is instantiated.
How to read object data from an XML file (C#)
Shows how to read object data that was previously written to an XML file using the XmlSerializer class.
How to write object data to an XML file (C#)
Shows how to write the object from a class to an XML file using the XmlSerializer class.
序列化:对象怎么在网络中传输?
https://time.geekbang.org/column/article/202779
03 | 序列化:对象怎么在网络中传输?
网络传输的数据必须是二进制数据,但调用方请求的出入参数都是对象。对象是不能直接在网络中传输的,所以我们需要提前把它转成可传输的二进制,并且要求转换算法是可逆的,这个过程我们一般叫做“序列化”。 这时,服务提供方就可以正确地从二进制数据中分割出不同的请求,同时根据请求类型和序列化类型,把二进制的消息体逆向还原成请求对象,这个过程我们称之为“反序列化”。
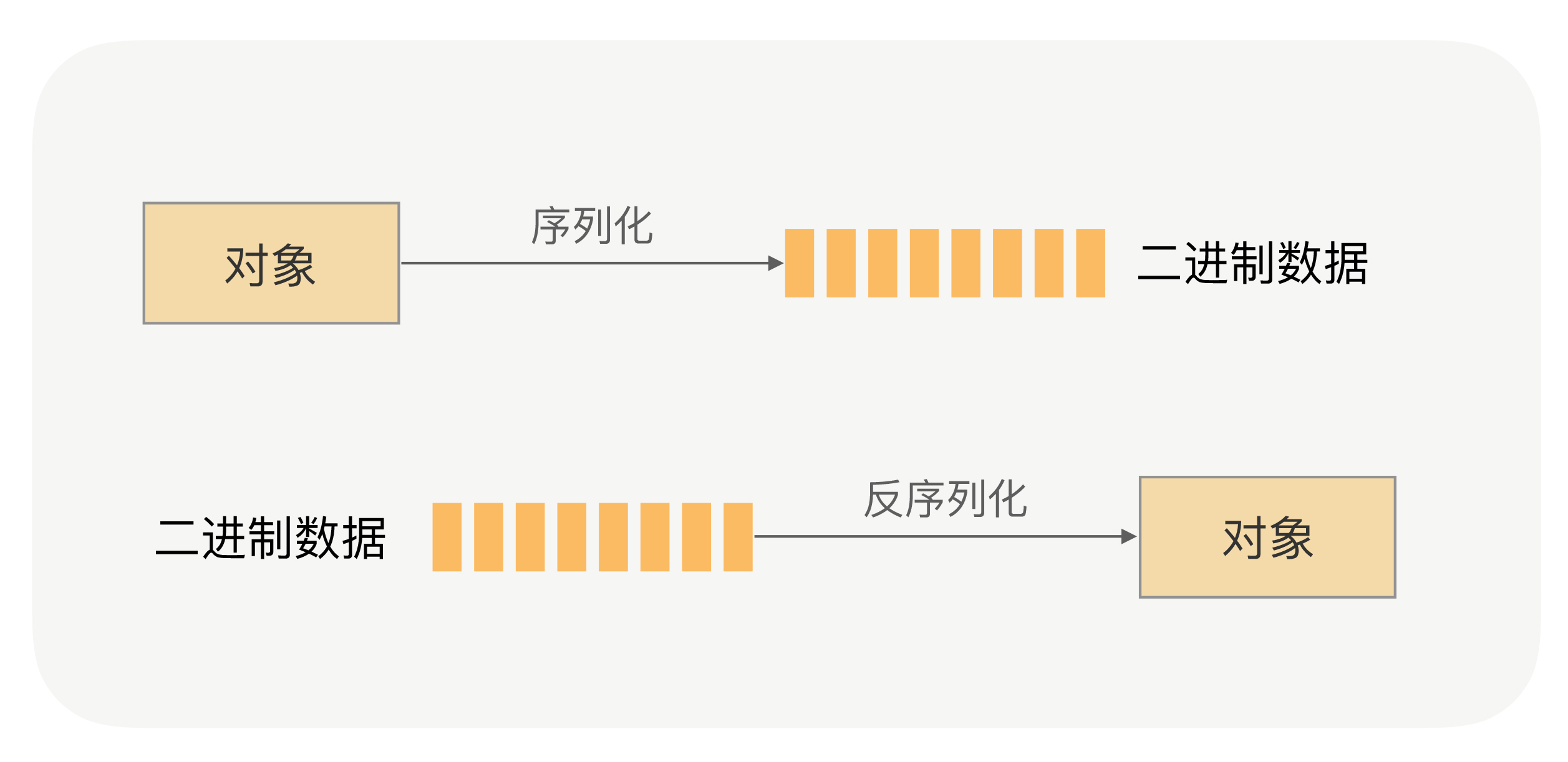
总结来说,序列化就是将对象转换成二进制数据的过程,而反序列就是反过来将二进制转换为对象的过程。那么 RPC 框架为什么需要序列化呢?还是请你回想下 RPC 的通信流程:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号