
伪造TCP重置 长连接 短连接 RST报文 TCP重置攻击
在运行中的进程突然被杀死时,该端发送RST
连接池16个连接
TCP重置攻击指的是使用伪造的TCP重置包干扰用户和网站的连接[1]。这个技术可以在善意的防火墙中应用[2],但也可用于网络审查或是攻击,恶意中断TCP连接,是一种旁观者攻击。
本质上,Internet是用于单个计算机交换电子消息或IP数据包的系统。该系统包括用于承载消息的硬件(例如铜缆和光纤电缆)和用于格式化消息的形式化系统,称为“协议”。互联网上使用的基本协议是IP协议,通常与其他协议(例如TCP[4]或UDP协议)结合使用。TCP/IP是用于电子邮件和Web浏览的协议集。每个协议都有一个信息块,称为包头,包含在每个数据包的开头附近。包头含有关哪台计算机发送了数据包,哪台计算机应接收它,数据包大小等信息。
当两台计算机之间需要双向虚拟连接时,TCP与IP一起使用。(UDP是无连接IP协议。)两台机器上的TCP软件将通过交换数据包流进行通信(例如,装有浏览器的电脑和Web服务器)。使用TCP连接为计算机提供了一种简便的方法来交换对于单个数据包来说太大的数据项,例如视频剪辑,电子邮件附件或音乐文件。尽管某些网页对于单个数据包来说足够小,但为方便起见,它们也是通过TCP连接发送的。
TCP重置
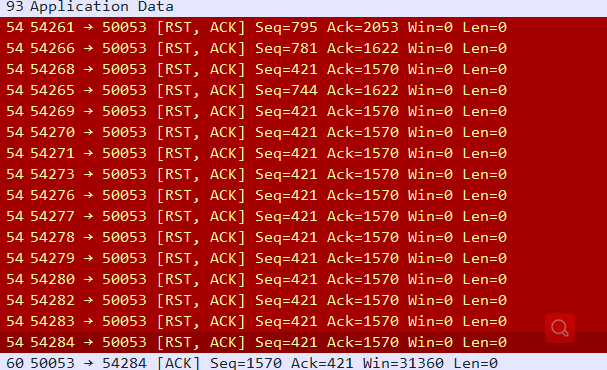
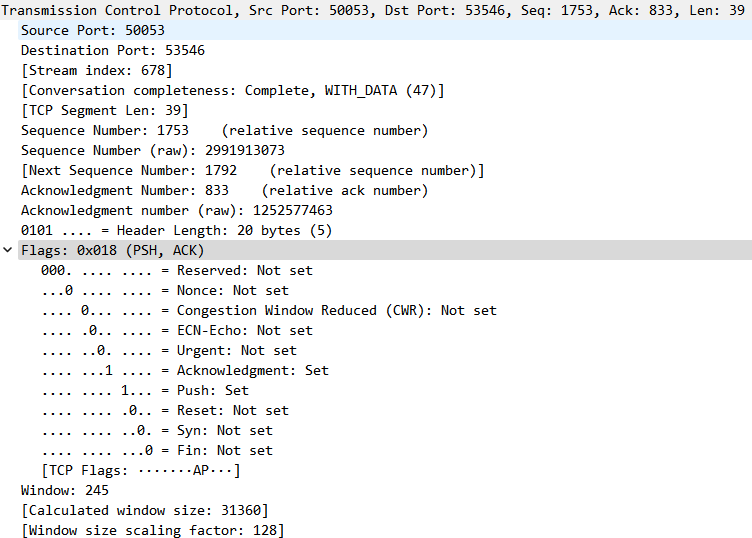
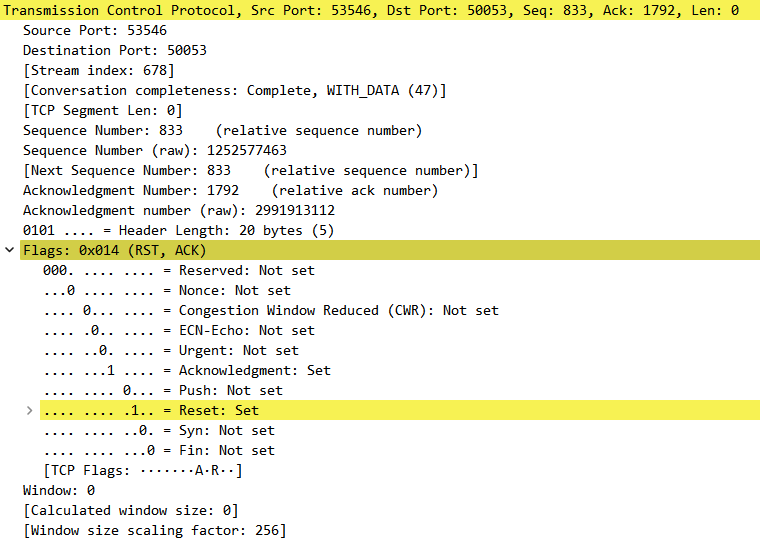
在传输控制协议(TCP)连接的数据包流中,每个数据包都包含一个TCP包头。这些包头中的每一个都包含一个称为“复位”(RST)标志的位。在大多数数据包中,该位设置为0,并且无效;但是,如果此位设置为1,则向接收计算机指示该计算机应立即停止使用TCP连接;它不应使用连接的标识号(端口)发送更多数据包,并丢弃接收到的带有包头的其他数据包,这些包头指示它们属于该连接。TCP重置基本上会立即终止TCP连接。
按照最初的设计,这是一个有用的工具。常见的应用是在进行TCP连接时计算机(计算机A)崩溃的情况。另一端的计算机(计算机B)将继续发送TCP数据包,因为它不知道计算机A已崩溃。重新启动计算机A后,它将从旧的崩溃前连接接收数据包。计算机A没有这些数据包的上下文,也无法知道如何处理这些数据包,因此它可以向计算机B发送TCP重置。此重置使计算机B知道该连接不再起作用。计算机B上的用户现在可以尝试其他连接或采取其他措施。
伪造TCP重置
在上述情况下,TCP重置是由作为连接端点之一的计算机发送的。但操作中,第三台计算机可以监视连接上的TCP数据包,然后将包含TCP重置的“伪造”数据包发送到一个或两个端点。伪造数据包中的报头必须错误地表明它来自端点,而不是伪造者。此信息包括端点IP地址和端口号。IP和TCP包头中的每个字段都必须设置为令人信服的伪造值,以进行伪重置,以欺骗端点关闭TCP连接。正确格式化的伪造TCP重置可能是中断伪造者可以监视的任何TCP连接的非常有效的方法。
合理使用TCP重置注入
伪造的TCP重置的一个明显的应用是在未经拥有端点的两方同意的情况下恶意破坏TCP连接。但是,也有人设计了使用伪造TCP重置来保护网络安全的系统。1995年被演示的一个原型“ Buster”软件包,该软件包会将伪造的重置发送到使用短列表中的端口号的任何TCP连接。Linux志愿者在2000年提出了在Linux防火墙上实现此功能,[5]而开源的Snort早在2003年就使用TCP重置来中断可疑连接。[6]
IETF认为,RFC3360中防火墙,负载平衡器和Web服务器进行的TCP重置是有害的。[7]
https://zh.wikipedia.org/wiki/TCP重置攻击
https://baike.baidu.com/item/短连接
短连接(short connnection)是相对于长连接而言的概念,指的是在数据传送过程中,只在需要发送数据时,才去建立一个连接,数据发送完成后,则断开此连接,即每次连接只完成一项业务的发送。
应用
手机推送原理
tcp长连接和短连接
TCP在真正的读写操作之前,server与client之间必须建立一个连接,
当读写操作完成后,双方不再需要这个连接时它们可以释放这个连接,
连接的建立通过三次握手,释放则需要四次握手,
所以说每个连接的建立都是需要资源消耗和时间消耗的。
1. TCP短连接
模拟一种TCP短连接的情况:
- client 向 server 发起连接请求
- server 接到请求,双方建立连接
- client 向 server 发送消息
- server 回应 client
- 一次读写完成,此时双方任何一个都可以发起 close 操作
在步骤5中,一般都是 client 先发起 close 操作。当然也不排除有特殊的情况。
从上面的描述看,短连接一般只会在 client/server 间传递一次读写操作!
2. TCP长连接
再模拟一种长连接的情况:
- client 向 server 发起连接
- server 接到请求,双方建立连接
- client 向 server 发送消息
- server 回应 client
- 一次读写完成,连接不关闭
- 后续读写操作...
- 长时间操作之后client发起关闭请求
3. TCP长/短连接操作过程
3.1 短连接的操作步骤是:
建立连接——数据传输——关闭连接...建立连接——数据传输——关闭连接
3.2 长连接的操作步骤是:
建立连接——数据传输...(保持连接)...数据传输——关闭连接
4. TCP长/短连接的优点和缺点
-
长连接可以省去较多的TCP建立和关闭的操作,减少浪费,节约时间。
对于频繁请求资源的客户来说,较适用长连接。
-
client与server之间的连接如果一直不关闭的话,会存在一个问题,
随着客户端连接越来越多,server早晚有扛不住的时候,这时候server端需要采取一些策略,
如关闭一些长时间没有读写事件发生的连接,这样可以避免一些恶意连接导致server端服务受损;
如果条件再允许就可以以客户端机器为颗粒度,限制每个客户端的最大长连接数,
这样可以完全避免某个蛋疼的客户端连累后端服务。
- 短连接对于服务器来说管理较为简单,存在的连接都是有用的连接,不需要额外的控制手段。
- 但如果客户请求频繁,将在TCP的建立和关闭操作上浪费时间和带宽。
5. TCP长/短连接的应用场景
-
长连接多用于操作频繁,点对点的通讯,而且连接数不能太多情况。
每个TCP连接都需要三次握手,这需要时间,如果每个操作都是先连接,
再操作的话那么处理速度会降低很多,所以每个操作完后都不断开,
再次处理时直接发送数据包就OK了,不用建立TCP连接。
例如:数据库的连接用长连接,如果用短连接频繁的通信会造成socket错误,
而且频繁的socket 创建也是对资源的浪费。
-
而像WEB网站的http服务一般都用短链接,因为长连接对于服务端来说会耗费一定的资源,
而像WEB网站这么频繁的成千上万甚至上亿客户端的连接用短连接会更省一些资源,
如果用长连接,而且同时有成千上万的用户,如果每个用户都占用一个连接的话,
那可想而知吧。所以并发量大,但每个用户无需频繁操作情况下需用短连好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号