
memory barrier 内存屏障 编译器导致的乱序 内存栅栏 内存栅障 屏障指令 membar memory fence fence instruction
小结:
1、
很多时候,编译器和 CPU 引起内存乱序访问不会带来什么问题,但一些特殊情况下,程序逻辑的正确性依赖于内存访问顺序,这时候内存乱序访问会带来逻辑上的错误,
2、
https://zh.wikipedia.org/wiki/内存屏障
https://en.wikipedia.org/wiki/Memory_barrier
a memory barrier, also known as a membar, memory fence or fence instruction, is a type of barrier instruction
内存屏障(英语:Memory barrier),也称内存栅栏,内存栅障,屏障指令等,是一类同步屏障指令,它使得 CPU 或编译器在对内存进行操作的时候, 严格按照一定的顺序来执行, 也就是说在内存屏障之前的指令和之后的指令不会由于系统优化等原因而导致乱序。
大多数现代计算机为了提高性能而采取乱序执行,这使得内存屏障成为必须。
语义上,内存屏障之前的所有写操作都要写入内存;内存屏障之后的读操作都可以获得同步屏障之前的写操作的结果。因此,对于敏感的程序块,写操作之后、读操作之前可以插入内存屏障。
举例
当驱动程序执行下列动作时,如果处理器的写入指令 out-of-order,使得资料还没有写入存储器,硬件模块就被触发开始动作,就会产生错误的行为。
寫資料到記憶體, 稍後硬體模塊會存取這一筆資料
// 此處需要內存屏障
觸發硬體模塊開始處理資料
底层体系结构相关的原语
大多数处理器提供了内存屏障指令:
- 完全内存屏障(full memory barrier)保障了早于屏障的内存读写操作的结果提交到内存之后,再执行晚于屏障的读写操作。
- 内存读屏障(read memory barrier)仅确保了内存读操作;
- 内存写屏障(write memory barrier)仅保证了内存写操作。
内存屏障是底层原语,是内存排序的一部分,在不同体系结构下变化很大而不适合推广。需要认真研读硬件的手册以确定内存屏障的办法。x86指令集中的内存屏障指令是:
lfence (asm), void _mm_lfence (void) 读操作屏障 sfence (asm), void _mm_sfence (void)
写操作屏障 mfence (asm), void _mm_mfence (void)
读写操作屏障
常见的x86/x64,通常使用lock指令前缀加上一个空操作来实现,注意当然不能真的是nop指令,但是可以用来实现空操作的指令其实是很多的,比如Linux中采用的
addl $0, 0 (%esp)
存储器也提供了另一套语义[3]的内存屏障指令:
- acquire semantics: 该操作结果可利用要早于代码中后续的所有操作的结果。
- release semantics: 该操作结果可利用要晚于代码中之前的所有操作的结果。
- fence semantics: acquire与release两种语义的共同有效。即该操作结果可利用要晚于代码中之前的所有操作的结果,且该操作结果可利用要早于代码中后续的所有操作的结果。
Intel Itanium处理器,具有内存屏障mf的指令,具有下述modifiers:
- acq (acquire)
- rel (release).
Windows API的内存屏障实现
下述同步函数使用适当的屏障来确保内存有序:
- 进出临界区(critical section)的函数
- 触发(signaled)同步对象的函数
- 等待函数(Wait function)
- 互锁函数(Interlocked function)
多线程编程与内存可见性
多线程程序通常使用高层程序设计语言中的同步原语,如Java与.NET Framework,或者API如pthread或Windows API。因此一般不需要明确使用内存屏障。
内存可见性问题,主要是高速缓存与内存的一致性问题。一个处理器上的线程修改了某数据,而在另一处理器上的线程可能仍然使用着该数据在专用cache中的老值,这就是可见性出了问题。解决办法是令该数据为volatile属性,或者读该数据之前执行内存屏障。
乱序执行与编译器重排序优化的比较
C与C++语言中,volatile关键字意图允许内存映射的I/O操作。这要求编译器对此的数据读写按照程序中的先后顺序执行,不能对volatile内存的读写重排序。因此关键字volatile并不保证是一个内存屏障。[4]
对于Visual Studio 2003,编译器保证对volatile的操作是有序的,但是不能保证处理器的乱序执行。因此,可以使用InterlockedCompareExchange或InterlockedExchange函数。
对于Visual Studio 2005及以后版本,编译器对volatile变量的读操作使用acquire semantics,对写操作使用release semantics。
编译器内存屏障
编译器会对生成的可执行代码做一定优化,造成乱序执行甚至省略(不执行)。gcc编译器在遇到内嵌汇编语句:
asm volatile("" ::: "memory");
将以此作为一条内存屏障,重排序内存操作。即此语句之前的各种编译优化将不会持续到此语句之后。也可用内建的__sync_synchronize
Microsoft Visual C++的编译器内存屏障为:
_ReadWriteBarrier() MemoryBarrier()
Intel C++编译器的内存屏障为:
__memory_barrier()
https://github.com/torvalds/linux/blob/master/Documentation/memory-barriers.txt#L111
============================ ABSTRACT MEMORY ACCESS MODEL ============================ Consider the following abstract model of the system: : : : : : : +-------+ : +--------+ : +-------+ | | : | | : | | | | : | | : | | | CPU 1 |<----->| Memory |<----->| CPU 2 | | | : | | : | | | | : | | : | | +-------+ : +--------+ : +-------+ ^ : ^ : ^ | : | : | | : | : | | : v : | | : +--------+ : | | : | | : | | : | | : | +---------->| Device |<----------+ : | | : : | | : : +--------+ : : :
Each CPU executes a program that generates memory access operations. In the
abstract CPU, memory operation ordering is very relaxed, and a CPU may actually
perform the memory operations in any order it likes, provided program causality
appears to be maintained. Similarly, the compiler may also arrange the
instructions it emits in any order it likes, provided it doesn't affect the
apparent operation of the program.
So in the above diagram, the effects of the memory operations performed by a
CPU are perceived by the rest of the system as the operations cross the
interface between the CPU and rest of the system (the dotted lines).
For example, consider the following sequence of events:
CPU 1 CPU 2
=============== ===============
{ A == 1; B == 2 }
A = 3; x = B;
B = 4; y = A;
The set of accesses as seen by the memory system in the middle can be arranged
in 24 different combinations:
STORE A=3, STORE B=4, y=LOAD A->3, x=LOAD B->4
STORE A=3, STORE B=4, x=LOAD B->4, y=LOAD A->3
STORE A=3, y=LOAD A->3, STORE B=4, x=LOAD B->4
STORE A=3, y=LOAD A->3, x=LOAD B->2, STORE B=4
STORE A=3, x=LOAD B->2, STORE B=4, y=LOAD A->3
STORE A=3, x=LOAD B->2, y=LOAD A->3, STORE B=4
STORE B=4, STORE A=3, y=LOAD A->3, x=LOAD B->4
STORE B=4, ...
...
and can thus result in four different combinations of values:
x == 2, y == 1
x == 2, y == 3
x == 4, y == 1
x == 4, y == 3
Furthermore, the stores committed by a CPU to the memory system may not be
perceived by the loads made by another CPU in the same order as the stores were
committed.
As a further example, consider this sequence of events:
CPU 1 CPU 2
=============== ===============
{ A == 1, B == 2, C == 3, P == &A, Q == &C }
B = 4; Q = P;
P = &B; D = *Q;
There is an obvious data dependency here, as the value loaded into D depends on
the address retrieved from P by CPU 2. At the end of the sequence, any of the
following results are possible:
(Q == &A) and (D == 1)
(Q == &B) and (D == 2)
(Q == &B) and (D == 4)
Note that CPU 2 will never try and load C into D because the CPU will load P
into Q before issuing the load of *Q.
golang-notes/memory_barrier.md at master · cch123/golang-notes https://github.com/cch123/golang-notes/blob/master/memory_barrier.md
理解 Memory barrier(内存屏障)_上善若水-CSDN博客 https://blog.csdn.net/zhangxiao93/article/details/42966279
memory barrier
There are only two hard things in Computer Science: cache invalidation and naming things.
-- Phil Karlton
https://martinfowler.com/bliki/TwoHardThings.html
memory barrier 也称为 memory fence。
CPU 架构
┌─────────────┐ ┌─────────────┐
│ CPU 0 │ │ CPU 1 │
└───────────┬─┘ └───────────┬─┘
▲ │ ▲ │
│ │ │ │
│ │ │ │
│ │ │ │
│ ▼ │ ▼
│ ┌────────┐ │ ┌────────┐
│◀───┤ Store │ │◀───┤ Store │
├───▶│ Buffer │ ├───▶│ Buffer │
│ └────┬───┘ │ └───┬────┘
│ │ │ │
│ │ │ │
│ │ │ │
│ │ │ │
│ ▼ │ ▼
┌──┴────────────┐ ┌──┴────────────┐
│ │ │ │
│ Cache │ │ Cache │
│ │ │ │
└───────┬───────┘ └───────┬───────┘
│ │
│ │
│ │
┌──────┴──────┐ ┌──────┴──────┐
│ Invalidate │ │ Invalidate │
│ Queue │ │ Queue │
└──────┬──────┘ └──────┬──────┘
│ │
│ Interconnect │
└───────────────┬───────────────┘
│
│
│
│
┌───────┴───────┐
│ │
│ Memory │
│ │
└───────────────┘
CPU 和内存间是个多层的架构,有些资料上会把 L1/L2/L3 都叫作内存,并把这个整体称为内存分层: memory hierachy。
CPU 的 cache 层需要保证其本身能保证一定的一致性,一般叫 cache coherence,这是通过 MESI 协议来保证的。
但是 MESI 协议中,如果要写入,需要把其它 cache 中的数据 invalidate 掉。这会导致 CPU 需要等待本地的 cacheline 变为 E(Exclusive)状态才能写入,也就是会带来等待,为了优化这种等待,最好是攒一波写,统一进行触发,所以积攒这些写入操作的地方就是 store buffer。
如果 CPU 收到了其它核心发来的 invalidate 消息(BusRdX),这时候 CPU 需要将本地的 cache invalidate 掉,又涉及了 cacheline 的修改和 store buffer 的处理,需要等待。为了消除这个等待,CPU 会把这些 invalidate 消息放在 invalidate queue 中,只要保证该消息之后一定会被处理后才对相应的 cache line 进行处理,那么就可以立即对其它核心发来的 invalidate 消息进行响应,以避免阻塞其它核心的流程处理。
这样的多层结构在我们编写程序的时候,也给我们带来了一些困扰。
不过我们先来看看 cache 层怎么保证多核心间数据的一致性,即 mesi 协议。
mesi 协议
| p0 | p1 | p2 | p3 | |
|---|---|---|---|---|
| initial state | I | I | I | I |
| p0 reads X | E | I | I | I |
| p1 reads X | S | S | I | I |
| p2 reads X | S | S | S | I |
| p3 writes X | I | I | I | M |
| p0 readx X | S | I | I | S |
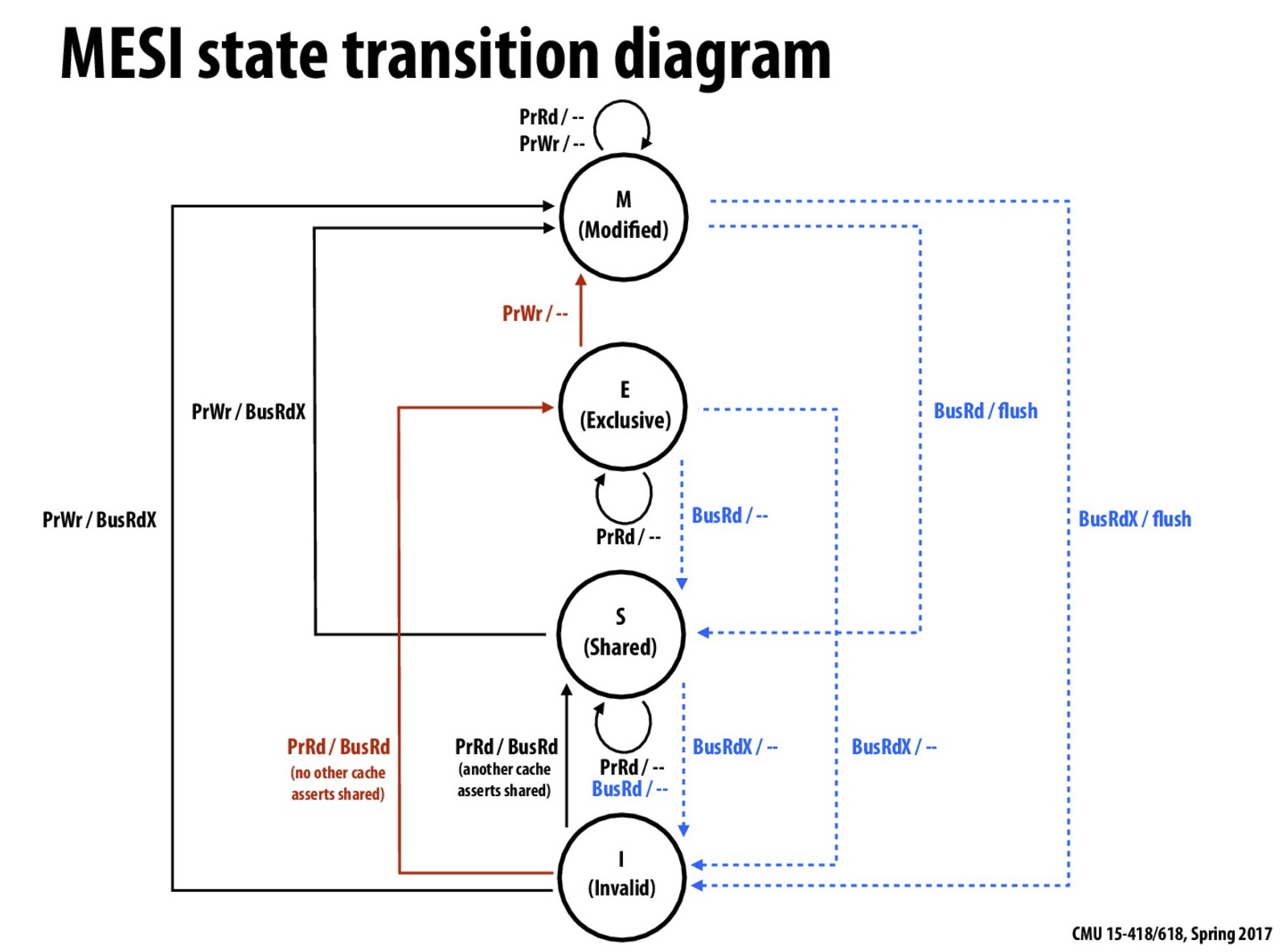
下面是不同类型的处理器请求和总线侧的请求:
处理器向 Cache 发请求包括下面这些操作:
PrRd: 处理器请求读取一个 Cache block PrWr: 处理器请求写入一个 Cache block
总线侧的请求包含:
BusRd: 监听到请求,表示当前有其它处理器正在发起对某个 Cache block 的读请求
BusRdX: 监听到请求,表示当前有其它处理器正在发起对某个其未拥有的 Cache block 的写请求
BusUpgr: 监听到请求,表示有另一个处理器正在发起对某 Cache block 的写请求,该处理器已经持有此 Cache block 块
Flush: 监听到请求,表示整个 cache 块已被另一个处理器写入到主存中
FlushOpt: 监听到请求,表示一个完整的 cache 块已经被发送到总线,以提供给另一个处理器使用(Cache 到 Cache 传数)
Cache 到 Cache 的传送可以降低 read miss 导致的延迟,如果不这样做,需要先将该 block 写回到主存,再读取,延迟会大大增加,在基于总线的系统中,这个结论是正确的。但在多核架构中,coherence 是在 L2 caches 这一级保证的,从 L3 中取可能要比从另一个 L2 中取还要快。
mesi 协议解决了多核环境下,内存多层级带来的问题。使得 cache 层对于 CPU 来说可以认为是透明的,不存在的。单一地址的变量的写入,可以以线性的逻辑进行理解。
但 mesi 协议有两个问题没有解决,一种是 RMW 操作,或者叫 CAS;一种是 ADD 操作。因为这两种操作都需要先读到原始值,进行修改,然后再写回到内存中。
同时,在 CPU 架构中我们看到 CPU 除了 cache 这一层之外,还存在 store buffer,而 store buffer 导致的内存乱序问题,mesi 协议是解决不了的,这是 memory consistency 范畴讨论的问题。
下面一节是 wikipedia 上对于 store buffer 和 invalidate queue 的描述,可能比我开头写的要权威一些。
store buffer 和 invalidate queue
Store Buffer:
当写入到一行 invalidate 状态的 cache line 时便会使用到 store buffer。写如果要继续执行,CPU 需要先发出一条 read-invalid 消息(因为需要确保所有其它缓存了当前内存地址的 CPU 的 cache line 都被 invalidate 掉),然后将写推入到 store buffer 中,当最终 cache line 达到当前 CPU 时再执行这个写操作。
CPU 存在 store buffer 的直接影响是,当 CPU 提交一个写操作时,这个写操作不会立即写入到 cache 中。因而,无论什么时候 CPU 需要从 cache line 中读取,都需要先扫描它自己的 store buffer 来确认是否存在相同的 line,因为有可能当前 CPU 在这次操作之前曾经写入过 cache,但该数据还没有被刷入过 cache(之前的写操作还在 store buffer 中等待)。需要注意的是,虽然 CPU 可以读取其之前写入到 store buffer 中的值,但其它 CPU 并不能在该 CPU 将 store buffer 中的内容 flush 到 cache 之前看到这些值。即 store buffer 是不能跨核心访问的,CPU 核心看不到其它核心的 store buffer。
Invalidate Queues:
为了处理 invalidation 消息,CPU 实现了 invalidate queue,借以处理新达到的 invalidate 请求,在这些请求到达时,可以马上进行响应,但可以不马上处理。取而代之的,invalidation 消息只是会被推进一个 invalidation 队列,并在之后尽快处理(但不是马上)。因此,CPU 可能并不知道在它 cache 里的某个 cache line 是 invalid 状态的,因为 invalidation 队列包含有收到但还没有处理的 invalidation 消息,这是因为 CPU 和 invalidation 队列从物理上来讲是位于 cache 的两侧的。
从结果上来讲,memory barrier 是必须的。一个 store barrier 会把 store buffer flush 掉,确保所有的写操作都被应用到 CPU 的 cache。一个 read barrier 会把 invalidation queue flush 掉,也就确保了其它 CPU 的写入对执行 flush 操作的当前这个 CPU 可见。再进一步,MMU 没有办法扫描 store buffer,会导致类似的问题。这种效果对于单线程处理器来说已经是会发生的了。
因为前面提到的 store buffer 的存在,会导致多核心运行用户代码时,读和写以非程序顺序的顺序完成。下面我们用工具来对这种乱序进行一些观察。
CPU 导致乱序
使用 litmus 进行形式化验证:
cat sb.litmus
X86 SB
{ x=0; y=0; }
P0 | P1 ;
MOV [x],$1 | MOV [y],$1 ;
MOV EAX,[y] | MOV EAX,[x] ;
locations [x;y;]
exists (0:EAX=0 /\ 1:EAX=0)
~ ❯❯❯ bin/litmus7 ./sb.litmus
%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Results for ./sb.litmus %
%%%%%%%%%%%%%%%%%%%%%%%%%%%
X86 SB
{x=0; y=0;}
P0 | P1 ;
MOV [x],$1 | MOV [y],$1 ;
MOV EAX,[y] | MOV EAX,[x] ;
locations [x; y;]
exists (0:EAX=0 /\ 1:EAX=0)
Generated assembler
##START _litmus_P0
movl $1, -4(%rbx,%rcx,4)
movl -4(%rsi,%rcx,4), %eax
##START _litmus_P1
movl $1, -4(%rsi,%rcx,4)
movl -4(%rbx,%rcx,4), %eax
Test SB Allowed
Histogram (4 states)
96 *>0:EAX=0; 1:EAX=0; x=1; y=1;
499878:>0:EAX=1; 1:EAX=0; x=1; y=1;
499862:>0:EAX=0; 1:EAX=1; x=1; y=1;
164 :>0:EAX=1; 1:EAX=1; x=1; y=1;
Ok
Witnesses
Positive: 96, Negative: 999904
Condition exists (0:EAX=0 /\ 1:EAX=0) is validated
Hash=2d53e83cd627ba17ab11c875525e078b
Observation SB Sometimes 96 999904
Time SB 0.11
在两个核心上运行汇编指令,意料之外的情况 100w 次中出现了 96 次。虽然很少,但确实是客观存在的情况。
barrier
从功能上来讲,barrier 有四种:
| #LoadLoad | #LoadStore |
|---|---|
| #StoreLoad | #StoreStore |
具体说明:
| barrier name | desc |
|---|---|
| #LoadLoad | 阻止不相关的 Load 操作发生重排 |
| #LoadStore | 阻止 Store 被重排到 Load 之前 |
| #StoreLoad | 阻止 Load 被重排到 Store 之前 |
| #StoreStore | 阻止 Store 被重排到 Store 之前 |
需要注意的是,这里所说的重排都是内存一致性范畴,即全局视角的不同变量操作。如果是同一个变量的读写的话,显然是不会发生重排的,因为不按照 program order 来执行程序的话,相当于对用户的程序发生了破坏行为。
lfence, sfence, mfence
Intel x86/x64 平台,total store ordering(但未来不一定还是 TSO):
mm_lfence("load fence": wait for all loads to complete)
不保证在 lfence 之前的写全局可见(globally visible)。并不是把读操作都序列化。只是保证这些读操作和 lfence 之间的先后关系。
mm_sfence("store fence": wait for all stores to complete)
The Semantics of a Store Fence On all Intel and AMD processors, a store fence has two effects:
Serializes all memory stores. All stores that precede the store fence in program order will become globally observable before any stores that succeed the store fence in program order become globally observable. Note that a store fence is ordered, by definition, with other store fences. In the cycle that follows the cycle when the store fence instruction retires, all stores that precede the store fence in program order are guaranteed to be globally observable. Any store that succeeds the store fence in program order may or may not be globally observable immediately after retiring the store fence. See Section 7.4 of the Intel optimization manual and Section 7.5 of the Intel developer manual Volume 2. Global observability will be discussed in the next section. However, that “SFENCE operation” is not actually a fully store serializing operation even though there is the word SFENCE in its name. This is clarified by the emphasized part. I think there is a typo here; it should read “store fence” not “store, fence.” The manual specifies that while clearing IA32_RTIT_CTL.TraceEn serializes all previous stores with respect to all later stores, it does not by itself ensure global observability of previous stores. It is exactly for this reason why the Linux kernel uses a full store fence (called wmb, which is basically SFENCE) after clearing TraceEn.
mm_mfence("mem fence": wait for all memory operations to complete)
mfence 会等待当前核心中的 store buffer 排空之后再执行后续指令。
直接考虑硬件的 fence 指令太复杂了,因为硬件提供的 fence 指令和我们前面说的 RW RR WW WR barrier 逻辑并不是严格对应的。
我们在写程序的时候的思考过程应该是,先从程序逻辑出发,然后考虑需要使用哪种 barrier/fence(LL LS SS SL),然后再找对应硬件平台上对应的 fence 指令。
acquire/release 语义

https://preshing.com/20130922/acquire-and-release-fences/
在 x86/64 平台上,只有 StoreLoad 乱序,所以你使用 acquire release 时,实际上生成的 fence 是 NOP。
在 Go 语言中也不需要操心这个问题,Go 语言的 atomic 默认是最强的内存序保证,即 sequential consistency。该一致性保证由 Go 保证,在所有运行 Go 的硬件平台上都是一致的。当然,这里说的只是 sync/atomic 暴露出来的接口。Go 在 runtime 层有较弱内存序的相关接口,位置在: runtime/internal/atomic。
memory order 参数
硬件会提供其 memory order,而语言本身可能也会有自己的 memory order,在 C/C++ 语言中会根据传给 atomic 的参数来决定其使用的 memory order,从而进行一些重排,这里的重排不但有硬件重排,还有编译器级别的重排。
下面是 C++ 中对 memory_order 参数的描述:
std::memory_order specifies how memory accesses, including regular, non-atomic memory accesses, are to be ordered around an atomic operation. Absent any constraints on a multi-core system, when multiple threads simultaneously read and write to several variables, one thread can observe the values change in an order different from the order another thread wrote them. Indeed, the apparent order of changes can even differ among multiple reader threads. Some similar effects can occur even on uniprocessor systems due to compiler transformations allowed by the memory model.
The default behavior of all atomic operations in the library provides for sequentially consistent ordering (see discussion below). That default can hurt performance, but the library's atomic operations can be given an additional std::memory_order argument to specify the exact constraints, beyond atomicity, that the compiler and processor must enforce for that operation.
这也是一个 Go 不需要操心的问题。
sequential consistency
Sequential consistency is a strong safety property for concurrent systems. Informally, sequential consistency implies that operations appear to take place in some total order, and that that order is consistent with the order of operations on each individual process.
可以理解为,同一块内存每次一定只有一个核心能执行。是最符合人的直觉的多线程执行顺序,可以用顺序的逻辑来理解程序执行结果。可以理解为完全没有读写重排。
其执行流程类似下图:
┌──────────────┐ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ Processor 1 │ │ Processor 2 │ │ Processor 3 │ │ Processor 4 │
└──────────────┘ └──────────────┘ └──────────────┘ └──────────────┘
▲
│
│
│
│
│
│
└──────────────────────────┐
│
│
│
│
│
│
│
┌──────────────────┐
│ │
│ Memory │
│ │
└──────────────────┘
内存上有一个开关,可以拨到任意一个 Processor 上,拨动到位后 Processor 即开始访问和修改内存。
保证 Sequential Consistency 的话,性能会非常差。体现不了多核心的优势。Intel 的 TSO 虽然是较强的 Memory Model,但也会有 WR 的重排。
cache coherency vs memory consistency
MESI 协议使 cache 层对 CPU 透明。多线程程序不需要担心某个核心读到过期数据,或者多个核心同时写入到一行 cache line 的不同部分,而导致 half write 的 cache line 被同步到主存中。
然而这种一致性机制没有办法解决 read-modify-write 操作的问题,比如 increment 操作,compare and swap 等操作。MESI 协议并不会阻止两个核心读到相同的内存内容,然后每个核心分别对其加一,再将新的相同的值写回到内存中,相当于将两次加一操作合并成了一次。
在现代 CPU 上,Lock 前缀会将 cache line 上锁,从而使 read-modify-write 操作在逻辑上具备原子性。下面的说明进行了简化,不过应该可以说明问题。
Unlocked increment:
- Acquire cache line, shareable is fine. Read the value.
- Add one to the read value.
- Acquire cache line exclusive (if not already E or M) and lock it.
- Write the new value to the cache line.
- Change the cache line to modified and unlock it.
Locked increment:
- Acquire cache line exclusive (if not already E or M) and lock it.
- Read value.
- Add one to it.
- Write the new value to the cache line.
- Change the cache line to modified and unlock it.
在 unlocked increment 操作中,cache line 只在写内存操作时被锁住,和所有类型的写一样。在 locked increment 中,cache line 在整个指令阶段都被持有,从读一直到最后的写操作。
某些 CPU 除了 cache 之外,还有其它的组件会影响内存的可见性。比如一些 CPU 有一个 read prefetcher(预取器)或者 write buffer,会导致内存操作执行乱序。不管有什么组件,LOCK 前缀(或其它 CPU 上的等价方式)可以避免一些内存操作上的顺序问题。
https://stackoverflow.com/questions/29880015/lock-prefix-vs-mesi-protocol
总结一下,cache coherence 解决的是单一地址的写问题,可以使多核心对同一地址的写入序列化。而 memory consistency 说的是不同地址的读写的顺序问题。即全局视角对读写的观测顺序问题。解决 cache coherence 的协议(MESI)并不能解决 CAS 类的问题。同时也解决不了 memory consistency,即不同内存地址读写的可见性问题,要解决 memory consistency 的问题,需要使用 memory barrier 之类的工具。
编译器导致乱序
snippet 1
X = 0
for i in range(100):
X = 1
print X
snippet 2
X = 1
for i in range(100):
print X
snippet 1 和 snippet 2 从逻辑上等价的。
如果这时候,假设有 Processor 2 同时在执行一条指令:
X = 0
P2 中的指令和 snippet 1 交错执行时,可能产生的结果是:111101111..
P2 中的指令和 snippet 2 交错执行时,可能产生的结果是:11100000…
多核心下,编译器对代码的优化也可能导致内存读写的重排。
有人说这个例子不够有说服力,我们看看参考资料中的另一个例子:
int a, b;
int foo()
{
a = b + 1;
b = 0;
return 1;
}
输出汇编:
mov eax, DWORD PTR b[rip]
add eax, 1
mov DWORD PTR a[rip], eax // --> store to a
mov DWORD PTR b[rip], 0 // --> store to b
开启 O2 优化后,输出汇编:
mov eax, DWORD PTR b[rip]
mov DWORD PTR b[rip], 0 // --> store to b
add eax, 1
mov DWORD PTR a[rip], eax // --> store to a
可见 compiler 也是可能会修改赋值的顺序的。
atomic/lock 操作成本 in Go
package main
import (
"sync/atomic"
"testing"
)
var a int64
func BenchmarkAtomic(b *testing.B) {
for i := 0; i < b.N; i++ {
atomic.StoreInt64(&a, int64(i))
}
}
func BenchmarkNormal(b *testing.B) {
for i := 0; i < b.N; i++ {
a = 1
}
}
func BenchmarkAtomicParallel(b *testing.B) {
b.SetParallelism(100)
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
atomic.StoreInt64(&a, int64(0))
}
})
}
结果:
goos: darwin
goarch: amd64
BenchmarkAtomic-4 200000000 7.01 ns/op
BenchmarkNormal-4 2000000000 0.63 ns/op
BenchmarkAtomicParallel-4 100000000 15.8 ns/op
PASS
ok _/Users/didi/test/go/atomic_bench 5.051s
可见,atomic 耗时比普通赋值操作要高一个数量级,在有竞争的情况下会更加慢。
false sharing / true sharing
true sharing 的概念比较好理解,在对全局变量或局部变量进行多线程修改时,就是一种形式的共享,而且非常字面意思,就是 true sharing。true sharing 带来的明显的问题,例如 RWMutex scales poorly 的官方 issue,即 RWMutex 的 RLock 会对 RWMutex 这个对象的 readerCount 原子加一。本质上就是一种 true sharing。
false sharing 指的是那些意料之外的共享。我们知道 CPU 是以 cacheline 为单位进行内存加载的,L1 的 cache line 大小一般是 64 bytes,如果两个变量,或者两个结构体在内存上相邻,那么在 CPU 加载并修改前一个变量的时候,会把第二个变量也加载到 cache line 中,这时候如果恰好另一个核心在使用第二个变量,那么在 P1 修改掉第一个变量的时候,会把整个 cache line invalidate 掉,这时候 P2 要修改第二个变量的话,就需要再重新加载该 cache line。导致了无谓的加载。
在 Go 的 runtime 中有不少例子,特别是那些 per-P 的结构,大多都有针对 false sharing 的优化:
runtime/time.go
var timers [timersLen]struct {
timersBucket
// The padding should eliminate false sharing
// between timersBucket values.
pad [cpu.CacheLinePadSize - unsafe.Sizeof(timersBucket{})%cpu.CacheLinePadSize]byte
}
runtime/sema.go
var semtable [semTabSize]struct {
root semaRoot
pad [cpu.CacheLinePadSize - unsafe.Sizeof(semaRoot{})]byte
}
用户态的代码对 false sharing 其实关注的比较少。
runtime 中的 publicationBarrier
TODO
https://github.com/golang/go/issues/35541
参考资料:
https://homes.cs.washington.edu/~bornholt/post/memory-models.html
https://people.eecs.berkeley.edu/~rcs/research/interactive_latency.html
https://blog.csdn.net/zhangxiao93/article/details/42966279
http://kaiyuan.me/2017/09/22/memory-barrier/
https://blog.csdn.net/dd864140130/article/details/56494925
https://preshing.com/20120515/memory-reordering-caught-in-the-act/
https://preshing.com/20120710/memory-barriers-are-like-source-control-operations/
https://preshing.com/20120625/memory-ordering-at-compile-time/
https://preshing.com/20120612/an-introduction-to-lock-free-programming/
https://preshing.com/20130922/acquire-and-release-fences/
https://webcourse.cs.technion.ac.il/234267/Spring2016/ho/WCFiles/tirgul%205%20mesi.pdf
https://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESIHelp.htm
http://15418.courses.cs.cmu.edu/spring2017/lectures
https://software.intel.com/en-us/articles/how-memory-is-accessed
https://stackoverflow.com/questions/29880015/lock-prefix-vs-mesi-protocol
https://github.com/torvalds/linux/blob/master/Documentation/memory-barriers.txt
参考文献列表:
http://en.wikipedia.org/wiki/Memory_barrier
http://en.wikipedia.org/wiki/Out-of-order_execution
https://www.kernel.org/doc/Documentation/memory-barriers.txt
本文例子均在 Linux(g++)下验证通过,CPU 为 X86-64 处理器架构。所有罗列的 Linux 内核代码也均在(或只在)X86-64 下有效。
本文首先通过范例(以及内核代码)来解释 Memory barrier,然后介绍一个利用 Memory barrier 实现的无锁环形缓冲区。
Memory barrier 简介
程序在运行时内存实际的访问顺序和程序代码编写的访问顺序不一定一致,这就是内存乱序访问。内存乱序访问行为出现的理由是为了提升程序运行时的性能。内存乱序访问主要发生在两个阶段:
- 编译时,编译器优化导致内存乱序访问(指令重排)
- 运行时,多 CPU 间交互引起内存乱序访问
Memory barrier 能够让 CPU 或编译器在内存访问上有序。一个 Memory barrier 之前的内存访问操作必定先于其之后的完成。Memory barrier 包括两类:
- 编译器 barrier
- CPU Memory barrier
很多时候,编译器和 CPU 引起内存乱序访问不会带来什么问题,但一些特殊情况下,程序逻辑的正确性依赖于内存访问顺序,这时候内存乱序访问会带来逻辑上的错误,例如:
- // thread 1
- while (!ok);
- do(x);
- // thread 2
- x = 42;
- ok = 1;
此段代码中,ok 初始化为 0,线程 1 等待 ok 被设置为 1 后执行 do 函数。假如说,线程 2 对内存的写操作乱序执行,也就是 x 赋值后于 ok 赋值完成,那么 do 函数接受的实参就很可能出乎程序员的意料,不为 42。
编译时内存乱序访问
在编译时,编译器对代码做出优化时可能改变实际执行指令的顺序(例如 gcc 下 O2 或 O3 都会改变实际执行指令的顺序):
- // test.cpp
- int x, y, r;
- void f()
- {
- x = r;
- y = 1;
- }
编译器优化的结果可能导致 y = 1 在 x = r 之前执行完成。首先直接编译此源文件:
- g++ -S test.cpp
得到相关的汇编代码如下:
- movl r(%rip), %eax
- movl %eax, x(%rip)
- movl $1, y(%rip)
这里我们看到,x = r 和 y = 1 并没有乱序。现使用优化选项 O2(或 O3)编译上面的代码(g++ -O2 -S test.cpp),生成汇编代码如下:
- movl r(%rip), %eax
- movl $1, y(%rip)
- movl %eax, x(%rip)
我们可以清楚的看到经过编译器优化之后 movl $1, y(%rip) 先于 movl %eax, x(%rip) 执行。避免编译时内存乱序访问的办法就是使用编译器 barrier(又叫优化 barrier)。Linux 内核提供函数 barrier() 用于让编译器保证其之前的内存访问先于其之后的完成。内核实现 barrier() 如下(X86-64 架构):
- #define barrier() __asm__ __volatile__("" ::: "memory")
现在把此编译器 barrier 加入代码中:
- int x, y, r;
- void f()
- {
- x = r;
- __asm__ __volatile__("" ::: "memory");
- y = 1;
- }
这样就避免了编译器优化带来的内存乱序访问的问题了(如果有兴趣可以再看看编译之后的汇编代码)。本例中,我们还可以使用 volatile 这个关键字来避免编译时内存乱序访问(而无法避免后面要说的运行时内存乱序访问)。volatile 关键字能够让相关的变量之间在内存访问上避免乱序,这里可以修改 x 和 y 的定义来解决问题:
- volatile int x, y;
- int r;
- void f()
- {
- x = r;
- y = 1;
- }
现加上了 volatile 关键字,这使得 x 相对于 y、y 相对于 x 在内存访问上有序。在 Linux 内核中,提供了一个宏 ACCESS_ONCE 来避免编译器对于连续的 ACCESS_ONCE 实例进行指令重排。其实 ACCESS_ONCE 实现源码如下:
- #define ACCESS_ONCE(x) (*(volatile typeof(x) *)&(x))
此代码只是将变量 x 转换为 volatile 的而已。现在我们就有了第三个修改方案:
- int x, y, r;
- void f()
- {
- ACCESS_ONCE(x) = r;
- ACCESS_ONCE(y) = 1;
- }
到此基本上就阐述完了我们的编译时内存乱序访问的问题。下面开始介绍运行时内存乱序访问。
运行时内存乱序访问
在运行时,CPU 虽然会乱序执行指令,但是在单个 CPU 的上,硬件能够保证程序执行时所有的内存访问操作看起来像是按程序代码编写的顺序执行的,这时候 Memory barrier 没有必要使用(不考虑编译器优化的情况下)。这里我们了解一下 CPU 乱序执行的行为。在乱序执行时,一个处理器真正执行指令的顺序由可用的输入数据决定,而非程序员编写的顺序。
早期的处理器为有序处理器(In-order processors),有序处理器处理指令通常有以下几步:
- 指令获取
- 如果指令的输入操作对象(input operands)可用(例如已经在寄存器中了),则将此指令分发到适当的功能单元中。如果一个或者多个操作对象不可用(通常是由于需要从内存中获取),则处理器会等待直到它们可用
- 指令被适当的功能单元执行
- 功能单元将结果写回寄存器堆(Register file,一个 CPU 中的一组寄存器)
相比之下,乱序处理器(Out-of-order processors)处理指令通常有以下几步:
- 指令获取
- 指令被分发到指令队列
- 指令在指令队列中等待,直到输入操作对象可用(一旦输入操作对象可用,指令就可以离开队列,即便更早的指令未被执行)
- 指令被分配到适当的功能单元并执行
- 执行结果被放入队列(而不立即写入寄存器堆)
- 只有所有更早请求执行的指令的执行结果被写入寄存器堆后,指令执行的结果才被写入寄存器堆(执行结果重排序,让执行看起来是有序的)
从上面的执行过程可以看出,乱序执行相比有序执行能够避免等待不可用的操作对象(有序执行的第二步)从而提高了效率。现代的机器上,处理器运行的速度比内存快很多,有序处理器花在等待可用数据的时间里已经可以处理大量指令了。
现在思考一下乱序处理器处理指令的过程,我们能得到几个结论:
- 对于单个 CPU 指令获取是有序的(通过队列实现)
- 对于单个 CPU 指令执行结果也是有序返回寄存器堆的(通过队列实现)
由此可知,在单 CPU 上,不考虑编译器优化导致乱序的前提下,多线程执行不存在内存乱序访问的问题。我们从内核源码也可以得到类似的结论(代码不完全的摘录):
- #ifdef CONFIG_SMP
- #define smp_mb() mb()
- #else
- #define smp_mb() barrier()
- #endif
这里可以看到,如果是 SMP 则使用 mb,mb 被定义为 CPU Memory barrier(后面会讲到),而非 SMP 时,直接使用编译器 barrier。
在多 CPU 的机器上,问题又不一样了。每个 CPU 都存在 cache(cache 主要是为了弥补 CPU 和内存之间较慢的访问速度),当一个特定数据第一次被特定一个 CPU 获取时,此数据显然不在 CPU 的 cache 中(这就是 cache miss)。此 cache miss 意味着 CPU 需要从内存中获取数据(这个过程需要 CPU 等待数百个周期),此数据将被加载到 CPU 的 cache 中,这样后续就能直接从 cache 上快速访问。当某个 CPU 进行写操作时,它必须确保其他的 CPU 已经将此数据从它们的 cache 中移除(以便保证一致性),只有在移除操作完成后此 CPU 才能安全的修改数据。显然,存在多个 cache 时,我们必须通过一个 cache 一致性协议来避免数据不一致的问题,而这个通讯的过程就可能导致乱序访问的出现,也就是这里说的运行时内存乱序访问。这里不再深入讨论整个细节,这是一个比较复杂的问题,有兴趣可以研究http://www.rdrop.com/users/paulmck/scalability/paper/whymb.2010.06.07c.pdf 一文,其详细的分析了整个过程。
现在通过一个例子来说明多 CPU 下内存乱序访问:
- // test2.cpp
- #include <pthread.h>
- #include <assert.h>
- // -------------------
- int cpu_thread1 = 0;
- int cpu_thread2 = 1;
- volatile int x, y, r1, r2;
- void start()
- {
- x = y = r1 = r2 = 0;
- }
- void end()
- {
- assert(!(r1 == 0 && r2 == 0));
- }
- void run1()
- {
- x = 1;
- r1 = y;
- }
- void run2()
- {
- y = 1;
- r2 = x;
- }
- // -------------------
- static pthread_barrier_t barrier_start;
- static pthread_barrier_t barrier_end;
- static void* thread1(void*)
- {
- while (1) {
- pthread_barrier_wait(&barrier_start);
- run1();
- pthread_barrier_wait(&barrier_end);
- }
- return NULL;
- }
- static void* thread2(void*)
- {
- while (1) {
- pthread_barrier_wait(&barrier_start);
- run2();
- pthread_barrier_wait(&barrier_end);
- }
- return NULL;
- }
- int main()
- {
- assert(pthread_barrier_init(&barrier_start, NULL, 3) == 0);
- assert(pthread_barrier_init(&barrier_end, NULL, 3) == 0);
- pthread_t t1;
- pthread_t t2;
- assert(pthread_create(&t1, NULL, thread1, NULL) == 0);
- assert(pthread_create(&t2, NULL, thread2, NULL) == 0);
- cpu_set_t cs;
- CPU_ZERO(&cs);
- CPU_SET(cpu_thread1, &cs);
- assert(pthread_setaffinity_np(t1, sizeof(cs), &cs) == 0);
- CPU_ZERO(&cs);
- CPU_SET(cpu_thread2, &cs);
- assert(pthread_setaffinity_np(t2, sizeof(cs), &cs) == 0);
- while (1) {
- start();
- pthread_barrier_wait(&barrier_start);
- pthread_barrier_wait(&barrier_end);
- end();
- }
- return 0;
- }
这里创建了两个线程来运行测试代码(需要测试的代码将放置在 run 函数中)。我使用了 pthread barrier(区别于本文讨论的 Memory barrier)主要为了让两个子线程能够同时运行它们的 run 函数。此段代码不停的尝试同时运行两个线程的 run 函数,以便得出我们期望的结果。在每次运行 run 函数前会调用一次 start 函数(进行数据初始化),run 运行后会调用一次 end 函数(进行结果检查)。run1 和 run2 两个函数运行在哪个 CPU 上则通过 cpu_thread1 和 cpu_thread2 两个变量控制。
先编译此程序:g++ -lpthread -o test2 test2.cpp(这里未优化,目的是为了避免编译器优化的干扰)。需要注意的是,两个线程运行在两个不同的 CPU 上(CPU 0 和 CPU 1)。只要内存不出现乱序访问,那么 r1 和 r2 不可能同时为 0,因此断言失败表示存在内存乱序访问。编译之后运行此程序,会发现存在一定概率导致断言失败。为了进一步说明问题,我们把 cpu_thread2 的值改为 0,换而言之就是让两个线程跑在同一个 CPU 下,再运行程序发现断言不再失败。
最后,我们使用 CPU Memory barrier 来解决内存乱序访问的问题(X86-64 架构下):
- int cpu_thread1 = 0;
- int cpu_thread2 = 1;
- void run1()
- {
- x = 1;
- __asm__ __volatile__("mfence" ::: "memory");
- r1 = y;
- }
- void run2()
- {
- y = 1;
- __asm__ __volatile__("mfence" ::: "memory");
- r2 = x;
- }
准备使用 Memory barrier
Memory barrier 常用场合包括:
- 实现同步原语(synchronization primitives)
- 实现无锁数据结构(lock-free data structures)
- 驱动程序
实际的应用程序开发中,开发者可能完全不知道 Memory barrier 就可以开发正确的多线程程序,这主要是因为各种同步机制中已经隐含了 Memory barrier(但和实际的 Memory barrier 有细微差别),这就使得不直接使用 Memory barrier 不会存在任何问题。但是如果你希望编写诸如无锁数据结构,那么 Memory barrier 还是很有用的。
通常来说,在单个 CPU 上,存在依赖的内存访问有序:
- Q = P;
- D = *Q;
这里内存操作有序。然而在 Alpha CPU 上,存在依赖的内存读取操作不一定有序,需要使用数据依赖 barrier(由于 Alpha 不常见,这里就不详细解释了)。
在 Linux 内核中,除了前面说到的编译器 barrier — barrier() 和 ACCESS_ONCE(),还有 CPU Memory barrier:
- 通用 barrier,保证读写操作有序的,mb() 和 smp_mb()
- 写操作 barrier,仅保证写操作有序的,wmb() 和 smp_wmb()
- 读操作 barrier,仅保证读操作有序的,rmb() 和 smp_rmb()
注意,所有的 CPU Memory barrier(除了数据依赖 barrier 之外)都隐含了编译器 barrier。这里的 smp 开头的 Memory barrier 会根据配置在单处理器上直接使用编译器 barrier,而在 SMP 上才使用 CPU Memory barrier(也就是 mb()、wmb()、rmb(),回忆上面相关内核代码)。
最后需要注意一点的是,CPU Memory barrier 中某些类型的 Memory barrier 需要成对使用,否则会出错,详细来说就是:一个写操作 barrier 需要和读操作(或数据依赖)barrier 一起使用(当然,通用 barrier 也是可以的),反之依然。
Memory barrier 的范例
读内核代码进一步学习 Memory barrier 的使用。
Linux 内核实现的无锁(只有一个读线程和一个写线程时)环形缓冲区 kfifo 就使用到了 Memory barrier,实现源码如下:
- /*
- * A simple kernel FIFO implementation.
- *
- * Copyright (C) 2004 Stelian Pop <stelian@popies.net>
- *
- * This program is free software; you can redistribute it and/or modify
- * it under the terms of the GNU General Public License as published by
- * the Free Software Foundation; either version 2 of the License, or
- * (at your option) any later version.
- *
- * This program is distributed in the hope that it will be useful,
- * but WITHOUT ANY WARRANTY; without even the implied warranty of
- * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
- * GNU General Public License for more details.
- *
- * You should have received a copy of the GNU General Public License
- * along with this program; if not, write to the Free Software
- * Foundation, Inc., 675 Mass Ave, Cambridge, MA 02139, USA.
- *
- */
- #include <linux/kernel.h>
- #include <linux/module.h>
- #include <linux/slab.h>
- #include <linux/err.h>
- #include <linux/kfifo.h>
- #include <linux/log2.h>
- /**
- * kfifo_init - allocates a new FIFO using a preallocated buffer
- * @buffer: the preallocated buffer to be used.
- * @size: the size of the internal buffer, this have to be a power of 2.
- * @gfp_mask: get_free_pages mask, passed to kmalloc()
- * @lock: the lock to be used to protect the fifo buffer
- *
- * Do NOT pass the kfifo to kfifo_free() after use! Simply free the
- * &struct kfifo with kfree().
- */
- struct kfifo *kfifo_init(unsigned char *buffer, unsigned int size,
- gfp_t gfp_mask, spinlock_t *lock)
- {
- struct kfifo *fifo;
- /* size must be a power of 2 */
- BUG_ON(!is_power_of_2(size));
- fifo = kmalloc(sizeof(struct kfifo), gfp_mask);
- if (!fifo)
- return ERR_PTR(-ENOMEM);
- fifo->buffer = buffer;
- fifo->size = size;
- fifo->in = fifo->out = 0;
- fifo->lock = lock;
- return fifo;
- }
- EXPORT_SYMBOL(kfifo_init);
- /**
- * kfifo_alloc - allocates a new FIFO and its internal buffer
- * @size: the size of the internal buffer to be allocated.
- * @gfp_mask: get_free_pages mask, passed to kmalloc()
- * @lock: the lock to be used to protect the fifo buffer
- *
- * The size will be rounded-up to a power of 2.
- */
- struct kfifo *kfifo_alloc(unsigned int size, gfp_t gfp_mask, spinlock_t *lock)
- {
- unsigned char *buffer;
- struct kfifo *ret;
- /*
- * round up to the next power of 2, since our 'let the indices
- * wrap' technique works only in this case.
- */
- if (!is_power_of_2(size)) {
- BUG_ON(size > 0x80000000);
- size = roundup_pow_of_two(size);
- }
- buffer = kmalloc(size, gfp_mask);
- if (!buffer)
- return ERR_PTR(-ENOMEM);
- ret = kfifo_init(buffer, size, gfp_mask, lock);
- if (IS_ERR(ret))
- kfree(buffer);
- return ret;
- }
- EXPORT_SYMBOL(kfifo_alloc);
- /**
- * kfifo_free - frees the FIFO
- * @fifo: the fifo to be freed.
- */
- void kfifo_free(struct kfifo *fifo)
- {
- kfree(fifo->buffer);
- kfree(fifo);
- }
- EXPORT_SYMBOL(kfifo_free);
- /**
- * __kfifo_put - puts some data into the FIFO, no locking version
- * @fifo: the fifo to be used.
- * @buffer: the data to be added.
- * @len: the length of the data to be added.
- *
- * This function copies at most @len bytes from the @buffer into
- * the FIFO depending on the free space, and returns the number of
- * bytes copied.
- *
- * Note that with only one concurrent reader and one concurrent
- * writer, you don't need extra locking to use these functions.
- */
- unsigned int __kfifo_put(struct kfifo *fifo,
- const unsigned char *buffer, unsigned int len)
- {
- unsigned int l;
- len = min(len, fifo->size - fifo->in + fifo->out);
- /*
- * Ensure that we sample the fifo->out index -before- we
- * start putting bytes into the kfifo.
- */
- smp_mb();
- /* first put the data starting from fifo->in to buffer end */
- l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
- memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
- /* then put the rest (if any) at the beginning of the buffer */
- memcpy(fifo->buffer, buffer + l, len - l);
- /*
- * Ensure that we add the bytes to the kfifo -before-
- * we update the fifo->in index.
- */
- smp_wmb();
- fifo->in += len;
- return len;
- }
- EXPORT_SYMBOL(__kfifo_put);
- /**
- * __kfifo_get - gets some data from the FIFO, no locking version
- * @fifo: the fifo to be used.
- * @buffer: where the data must be copied.
- * @len: the size of the destination buffer.
- *
- * This function copies at most @len bytes from the FIFO into the
- * @buffer and returns the number of copied bytes.
- *
- * Note that with only one concurrent reader and one concurrent
- * writer, you don't need extra locking to use these functions.
- */
- unsigned int __kfifo_get(struct kfifo *fifo,
- unsigned char *buffer, unsigned int len)
- {
- unsigned int l;
- len = min(len, fifo->in - fifo->out);
- /*
- * Ensure that we sample the fifo->in index -before- we
- * start removing bytes from the kfifo.
- */
- smp_rmb();
- /* first get the data from fifo->out until the end of the buffer */
- l = min(len, fifo->size - (fifo->out & (fifo->size - 1)));
- memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);
- /* then get the rest (if any) from the beginning of the buffer */
- memcpy(buffer + l, fifo->buffer, len - l);
- /*
- * Ensure that we remove the bytes from the kfifo -before-
- * we update the fifo->out index.
- */
- smp_mb();
- fifo->out += len;
- return len;
- }
- EXPORT_SYMBOL(__kfifo_get);
为了更好的理解上面的源码,这里顺带说一下此实现使用到的一些和本文主题无关的技巧:
- 使用与操作来求取环形缓冲区的下标,相比取余操作来求取下标的做法效率要高不少。使用与操作求取下标的前提是环形缓冲区的大小必须是 2 的 N 次方,换而言之就是说环形缓冲区的大小为一个仅有一个 1 的二进制数,那么 index & (size – 1) 则为求取的下标(这不难理解)
- 使用了 in 和 out 两个索引且 in 和 out 是一直递增的(此做法比较巧妙),这样能够避免一些复杂的条件判断(某些实现下,in == out 时还无法区分缓冲区是空还是满)
这里,索引 in 和 out 被两个线程访问。in 和 out 指明了缓冲区中实际数据的边界,也就是 in 和 out 同缓冲区数据存在访问上的顺序关系,由于未使用同步机制,那么保证顺序关系就需要使用到 Memory barrier 了。索引 in 和 out 都分别只被一个线程修改,而被两个线程读取。__kfifo_put 先通过 in 和 out 来确定可以向缓冲区中写入数据量的多少,这时,out 索引应该先被读取后才能真正的将用户 buffer 中的数据写入缓冲区,因此这里使用到了 smp_mb(),对应的,__kfifo_get 也使用 smp_mb() 来确保修改 out 索引之前缓冲区中数据已经被成功读取并写入用户 buffer 中了。对于 in 索引,在 __kfifo_put 中,通过 smp_wmb() 保证先向缓冲区写入数据后才修改 in 索引,由于这里只需要保证写入操作有序,故选用写操作 barrier,在 __kfifo_get 中,通过 smp_rmb() 保证先读取了 in 索引(这时候 in 索引用于确定缓冲区中实际存在多少可读数据)才开始读取缓冲区中数据(并写入用户 buffer 中),由于这里只需要保证读取操作有序,故选用读操作 barrier。

