
正则_action
从字符串取出sql中的一个id
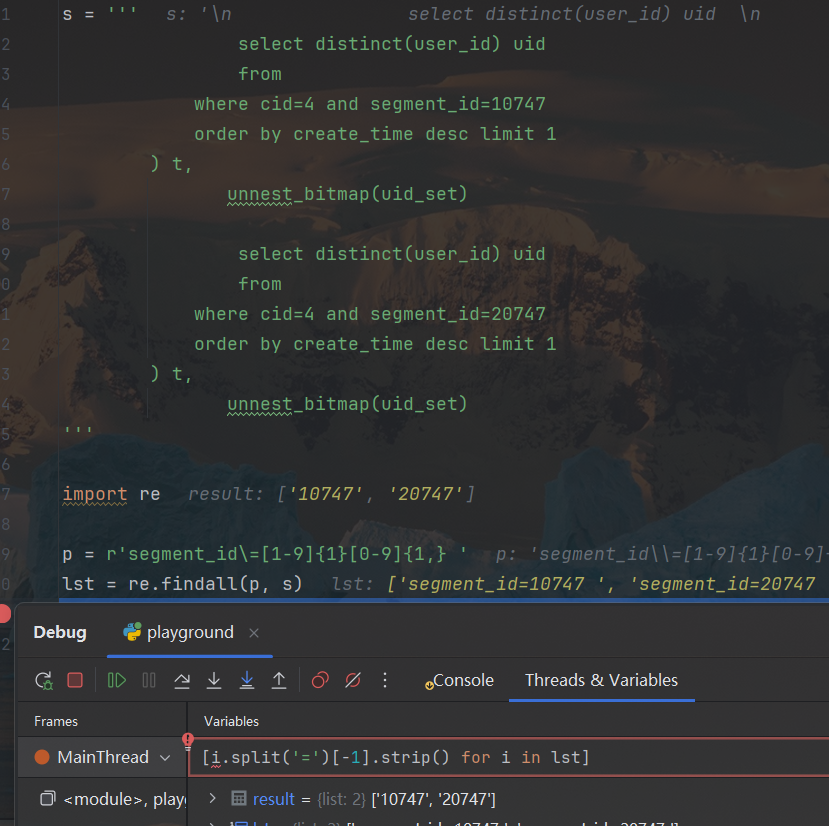
数字
import re
s = ['11.5', '454', '6', '32sdf', '0.65', '0.5', '1.0', '454']
for i in s:
if isinstance(s, float) or isinstance(s, int):
return s
return float(s) if re.match('^[0-9]{1,}\.{0,}[0-9]{1,}$', s) else s
'''
校验入参的时间参数 '2023-05-23 14:00'
'''
import re
# TODO 更精确的正则规则 \s{1}一个空格
pattern = '^[0-9]{4}-[0-9]{2}-[0-9]{2}\s{1}[0-9]{2}:[0-9]{2}$'
return re.match(pattern, s) is not None
\s |
匹配一个空白字符,包括空格、制表符、换页符和换行符。等价于 例如, 经测试,\s不匹配"\u180e",在当前版本 Chrome(v80.0.3987.122) 和 Firefox(76.0.1) 控制台输入/\s/.test("\u180e") 均返回 false。 |
匹配base64编码的png或jpg或jpeg图片
正则与单元测试
func chkIntIdStr(str string) bool {
// 1)1
// 2)12,23
// 2)10,23
r := "^" +
"([1-9]{1,}[0-9]{0,},){0,}[1-9]{1,}[0-9]{0,}" +
"$"
b, err := regexp.MatchString(r, str)
if err != nil {
return false
}
return b
}
func Test_chkIntIdStr(t *testing.T) {
type args struct {
str string
}
tests := []struct {
name string
args args
want bool
}{
{name: "", args: args{str: ""}, want: false},
{name: "", args: args{str: "0"}, want: false},
{name: "", args: args{str: "1"}, want: true},
{name: "", args: args{str: "1,"}, want: false},
{name: "", args: args{str: "1,2"}, want: true},
{name: "", args: args{str: "10,2"}, want: true},
{name: "x", args: args{str: "1,20"}, want: false},
{name: "", args: args{str: "1e2"}, want: false},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
if got := chkIntIdStr(tt.args.str); got != tt.want {
t.Errorf("chkIntIdStr() = %v, want %v", got, tt.want)
}
})
}
}
\internal\data\utils_test.go:29: chkIntIdStr() = true, want false
=== RUN Test_chkIntIdStr/#06
--- FAIL: Test_chkIntIdStr (0.00s)
--- PASS: Test_chkIntIdStr/#00 (0.00s)
--- PASS: Test_chkIntIdStr/#01 (0.00s)
--- PASS: Test_chkIntIdStr/#02 (0.00s)
--- PASS: Test_chkIntIdStr/#03 (0.00s)
--- PASS: Test_chkIntIdStr/#04 (0.00s)
--- PASS: Test_chkIntIdStr/#05 (0.00s)
--- FAIL: Test_chkIntIdStr/x (0.00s)
--- PASS: Test_chkIntIdStr/#06 (0.00s)
FAIL
FAIL WebSvc/internal/data 1.016s
Email邮箱
func ChkEmail(s string) bool {
r := "^[\\w\\-\\.]{1,}@([\\w\\-]{1,}\\.){0,}[0-9a-zA-Z]{1,}$"
b, err := regexp.MatchString(r, s)
if err != nil {
return false
}
return b
}
// TODO: Add test cases.
{name: "1", args: args{s: "a@a.com"}, want: true},
{name: "2", args: args{s: "a@a.b.com"}, want: true},
{name: "3", args: args{s: "1@1.123"}, want: true},
{name: "4", args: args{s: "1A@1.123A"}, want: true},
{name: "5", args: args{s: "1-A@1-1.123A"}, want: true},
{name: "f1", args: args{s: "a@a."}, want: false},
{name: "f2", args: args{s: "a@.b.com"}, want: false},
{name: "f2-2", args: args{s: "a@a..b.com"}, want: false},
{name: "f3", args: args{s: "@1.123"}, want: false},
{name: "f4", args: args{s: "1A1.123A"}, want: false},
function check_email($win)
{
$win = trim($win);
$reg = '/\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*/';
if (preg_match($reg, $win) == 1) return true;
return false;
}
<form action="" method="post" style="text-align: center ">
<input type="text" name="email_1117" placeholder="请输入您的email(必填)" style="margin:1em;" id="winput_email">
<input id="winput_email_check" style="border: 0 ;color: red;">
<input type="submit" name="add" value="追加" id="w_submit">
</form>
<script>
document.getElementById("winput_email").addEventListener("change", wonchange);
function wonchange() {
var w = document.getElementById("winput_email").value;
var reg = /\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*/;
console.log(reg.exec(w) !== null && reg.exec(w).index === 0)
if (reg.exec(w) !== null && reg.exec(w).index === 0) {
document.getElementById("winput_email_check").value = ''
document.getElementById("w_submit").style.display = 'inline';
} else {
winnerhtml = '请输入正确的email';
document.getElementById("winput_email_check").value = winnerhtml;
document.getElementById("w_submit").style.display = 'none';
}
}
</script>
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Guide/Regular_Expressions
\w
匹配一个单字字符(字母、数字或者下划线)。
等价于[A-Za-z0-9_]。
例如, /\w/ 匹配 "apple," 中的 'a',"$5.28,"中的 '5' 和 "3D." 中的 '3'。
+
匹配前面一个表达式1次或者多次。等价于 {1,}。
例如,/a+/匹配了在 "candy" 中的 'a',和在 "caaaaaaandy" 中所有的 'a'。
*
匹配前一个表达式0次或多次。等价于 {0,}。
例如,/bo*/会匹配 "A ghost boooooed" 中的 'booooo' 和 "A bird warbled" 中的 'b',但是在 "A goat grunted" 中将不会匹配任何东西。
http://wiki.ubuntu.org.cn/Python%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F%E6%93%8D%E4%BD%9C%E6%8C%87%E5%8D%97
re.compile('\d+').search('按时打卡的23423') is None
{'words': '大型\t雕铣机\t哪个\t牌子\t好\t?', 'postags': 'b\tn\tr\tn\ta\twp', 'parser': '2:ATT\t4:ATT\t4:ATT\t5:SBV\t0:HED\t5:WP', 'netags': 'O\tO\tO\tO\tO\tO', 'role': [{4: 'A0:(0,3)'}]}
feature ATT SBV HED 相邻
re.compile('ATT\\t\d+:SBV\\t\d+:HED\\t\d+').search( '2:ATT\t4:ATT\t4:ATT\t5:SBV\t0:HED\t5:WP') is None
或 (a|b)
re.compile('HED\\t\d+:VOB\\t\d+:(WP|ADV\\t\d+:CMP)').search('3:ATT\t3:ATT\t4:SBV\t0:HED\t4:VOB\t7:ADV\t4:CMP\t4:WP') is not None
http://wiki.ubuntu.org.cn/index.php?title=Python%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F%E6%93%8D%E4%BD%9C%E6%8C%87%E5%8D%97&variant=zh-cn#match.28.29_vs_search.28.29
re.compile('\d+').search('按时打卡的23423') is None
match() vs search()
match() 函数只检查 RE 是否在字符串开始处匹配,而 search() 则是扫描整个字符串。记住这一区别是重要的。记住,match() 只报告一次成功的匹配,它将从 0 处开始;如果匹配不是从 0 开始的,match() 将不会报告它。
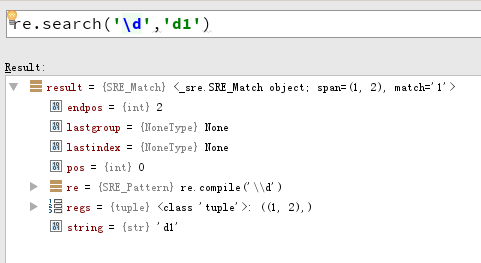
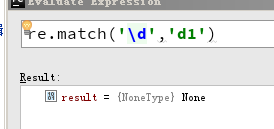
http://www.heze.cn/qiye/
区别
http://www.heze.cn/qiye/.{0}$ 匹配成功
http://www.heze.cn/qiye/
http://www.heze.cn/qiye/.{0}$
结尾字符串
http://www.heze.cn/qiye/htt
http://www.heze.cn/qiye/((.{0}$)|(h.+$))
http://www.heze.cn/qiye/((.{0})|(h.+))$
http://www.heze.cn/qiye/[0-9a-zA-Z]+/show-\d+-\d+.html$
go
reg = regexp.MustCompile("http://www.heze.cn/{0-9a-zA-Z}/(.{0}$)|(list-\\d+-\\d+\\.html$)")
匹配数据 1-99
^[1-9][0-9]{0,1}[^0-9]{0,1}$
^[1-9]{1}[0-9]{0,1}$
http://cn.sonhoo.com/wukong/c0?offset=150&limit=50
^http://cn.sonhoo.com/wukong/c\d+\?offset=\d+\&limit=\d+$
c = colly.NewCollector(
colly.AllowedDomains("cn.sonhoo.com"),
colly.URLFilters(
//请求页面的正则表达式,满足其一即可
regexp.MustCompile("^http://cn.sonhoo.com/wukong/$"),
//regexp.MustCompile("^http://cn.sonhoo.com/wukong/[ac]{1}\\d+$"),
regexp.MustCompile("^http://cn.sonhoo.com/wukong/[c]{1}\\d+$"),
// http://cn.sonhoo.com/wukong/c0?offset=150&limit=50 文章列表页
regexp.MustCompile("^http://cn.sonhoo.com/wukong/c\\d+\\?offset=\\d+\\&limit=\\d+$"),
),
+至少1次
{m,}至少m次
^.+/wukong/u/\d+/index$
^.{0,}/wukong/u/\d+/index$
// http://cn.sonhoo.com/wukong/u/200078/index
reg := regexp.MustCompile("^.{0,}/wukong/u/\\d+/index$")
// 检查href的是否为url
func isUrl(str string) bool {
reg := regexp.MustCompile("^[A-Za-z0-9_\\-\\.\\/\\&\\?\\=]+$")
data := reg.Find([]byte(str))
if (data == nil) {
return false
}
return true
}
[A-Za-z0-9_\-\.\/\&\?\=]
http://www.cnhan.com/pinfo/
http://www.cnhan.com/pinfo/type-22
http://www.cnhan.com/pinfo/type-22-4
^http://www.cnhan.com/pinfo/(.{0}$)|(type-[1-9][0-9]{0,1}(|-[1-9][0-9]{0,1})$)
python
re.match('^http://www.cnhan.com/pinfo/\d+\.html$','http://www.cnhan.com/pinfo/318056a.html') None
SRE_MATCH
go
f := "^http://www.cnhan.com/pinfo/\\d+\\.html$"
reg := regexp.MustCompile(f)
data := reg.Find([]byte(link))
if data != nil {
es
' d d '.replace(/\s/g,'') 去除全部空格
|
\s
|
匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。
|
' d d '.replace(/\s/,'') 去除匹配到的第一个空格
' d d '.trim(' ','') 去除首尾的空格
^\s*$ 匹配任何不可见字符
^[\s\S]*\<script\>[\s\S]*\<\/script\>[\s\S]*$ 匹配script
^(\s*$)|([\s\S]*\<script\>[\s\S]*\<\/script\>[\s\S]*$)
\s 匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。
.点
匹配除“\n”和"\r"之外的任何单个字符。要匹配包括“\n”和"\r"在内的任何字符,请使用像“[\s\S]”的模式。
*
匹配前面的子表达式任意次。例如,zo*能匹配“z”,也能匹配“zo”以及“zoo”。*等价于{0,}。
+
匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。
\<
\>
匹配词(word)的开始(\<)和结束(\>)。例如正则表达式\<the\>能够匹配字符串"for the wise"中的"the",但是不能匹配字符串"otherwise"中的"the"。注意:这个元字符不是所有的软件都支持的。
【new RegExp("test")
var re=new RegExp("test");re.test("test");
true
var re=new RegExp("^\^");re.test("^");
true
var re=new RegExp("^\^");re.test("^");
true
var re=new RegExp("^\\^\\$$");re.test("^$");
true
var re=new RegExp("^\^\$$");re.test("^$");
false
var re=new RegExp("^\\^\\$$");re.test("^$");
true
var re=new RegExp("^\\^/test/\.{1,}\\$$");re.test("^/test/my$");
true
var re=new RegExp("\");re.test("\");
VM911:1 Uncaught SyntaxError: missing ) after argument list
var re=new RegExp("\");re.test("\\");
VM915:1 Uncaught SyntaxError: missing ) after argument list
var re=new RegExp("\\");re.test("\\");
VM920:1 Uncaught SyntaxError: Invalid regular expression: /\/: \ at end of pattern
at new RegExp (<anonymous>)
at <anonymous>:1:8
(anonymous) @ VM920:1
var re=new RegExp("\\a");re.test("\\a");
true
var re=new RegExp("\\\");re.test("\\\");
VM939:1 Uncaught SyntaxError: missing ) after argument list
var re=new RegExp("\\\\");re.test("\\\\");
true
】
匹配iPv4
0.
1.
{n,m}
m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。
https://www.jb51.net/article/162641.htm
\w |
匹配一个单字字符(字母、数字或者下划线)。等价于 例如, |
(小数点)默认匹配除换行符之外的任何单个字符。
例如,/.n/ 将会匹配 "nay, an apple is on the tree" 中的 'an' 和 'on',但是不会匹配 'nay'。
如果 s ("dotAll") 标志位被设为 true,它也会匹配换行符。
* |
匹配前一个表达式 0 次或多次。等价于 例如, |
+ |
匹配前面一个表达式 1 次或者多次。等价于 例如, |
? |
匹配前面一个表达式 0 次或者 1 次。等价于 例如, 如果紧跟在任何量词 *、 +、? 或 {} 的后面,将会使量词变为非贪婪(匹配尽量少的字符),和缺省使用的贪婪模式(匹配尽可能多的字符)正好相反。例如,对 "123abc" 使用 还用于先行断言中,如本表的 |
\s |
Matches a white space character, including space, tab, form feed, line feed. Equivalent to For example, |
\S |
Matches a character other than white space. Equivalent to For example, |
RegExp = '^http://www.abc.com/efgents/60/(warrior|paladin|hunter|shaman|druid|rogue|priest|warlock|mage)/efg/\d{1,128}$
r = re.match(D.RegExp, url)
print(r is not None)
l = ('http://www.abc.com/efgents/60/priest/efg/00000000000000000000000000000000000000000000000',
'http://www.abc.com/efgents/60/mage/efg/0000000000000000000000000000000000000000000000',
'http://www.abc.com/efgents/60/warlock/efg/00000000000000000110000000000000000500000000000000')
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Guide/Regular_Expressions
Character classes - JavaScript | MDN https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Regular_Expressions/Character_Classes
正则表达式匹配数字范围|极客教程 https://geek-docs.com/regexp/regexp-tutorials/regular-expressions-match-numeric-ranges.html
子网掩码
package main
import (
"regexp"
)
func main() {
chk:= func(str string) bool {
// [12]{0,1}[0-9]
// \.
// ([12]{0,1}[0-9]\.) 重复3次 ([12]{0,1}[0-9]\.){3}
// (/(([0-9])|([12][0-9])|(3[012])))可选{0,1}
r := "^" +
"([12]{0,1}[0-9]{0,1}[0-9]{0,1}\\.){3}" +
"([12]{0,1}[0-9]{0,1}[0-9]{0,1})" +
"(/(([0-9])|([12][0-9])|(3[012]))){0,1}" +
"$"
b,err := regexp.MatchString(r,str)
if err!=nil{
panic(err)
}
return b
}
l:=[]string{"12.12.13.0","12.12.13.10","12.12.13.20","12.12.13.0/0","12.12.13.0/10","12.12.13.0/32","12.12.13.20/22","12.12.13.20/33"}
for _,v:=range l{
println(v,chk(v))
}
}
掩码位
在线网络计算器 | TCP/IP子网掩码计算换算 —在线工具 https://www.sojson.com/convert/subnetmask.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号