
Routine Subroutine Coroutine 子程序 协程 子例程
真实世界的并发编程 https://jyywiki.cn/OS/2022/slides/7.slides#/2/3
高性能计算程序:特点
“A technology that harnesses the power of supercomputers or computer clusters to solve complex problems requiring massive computation.” (IBM)
以计算为中心
- 系统模拟:天气预报、能源、分子生物学
- 人工智能:神经网络训练
- 矿厂:纯粹的 hash 计算
高性能计算:主要挑战
计算任务如何分解
- 计算图需要容易并行化
- 机器-线程两级任务分解
- 生产者-消费者解决一切
- Parallel and Distributed Computation: Numerical Methods
线程间如何通信
- 通信不仅发生在节点/线程之间,还发生在任何共享内存访问
- 还记得被 mem-ordering.c 支配的恐惧吗?
- 协程 (coroutines)
- 多个可以保存/恢复的执行流 (M2 - libco)
- 比线程更轻量 (完全没有系统调用,也就没有操作系统状态)
数据中心程序:特点
“A network of computing and storage resources that enable the delivery of shared applications and data.” (CISCO)
以数据 (存储) 为中心
- 从互联网搜索 (Google)、社交网络 (Facebook/Twitter) 起家
- 支撑各类互联网应用:微信/QQ/支付宝/游戏/网盘/……
算法/系统对 HPC 和数据中心的意义
- 你有 1,000,000 台服务器
- 如果一个算法/实现能快 1%,就能省 10,000 台服务器
- 参考:对面一套房 ≈ 50 台服务器 (不计运维成本)
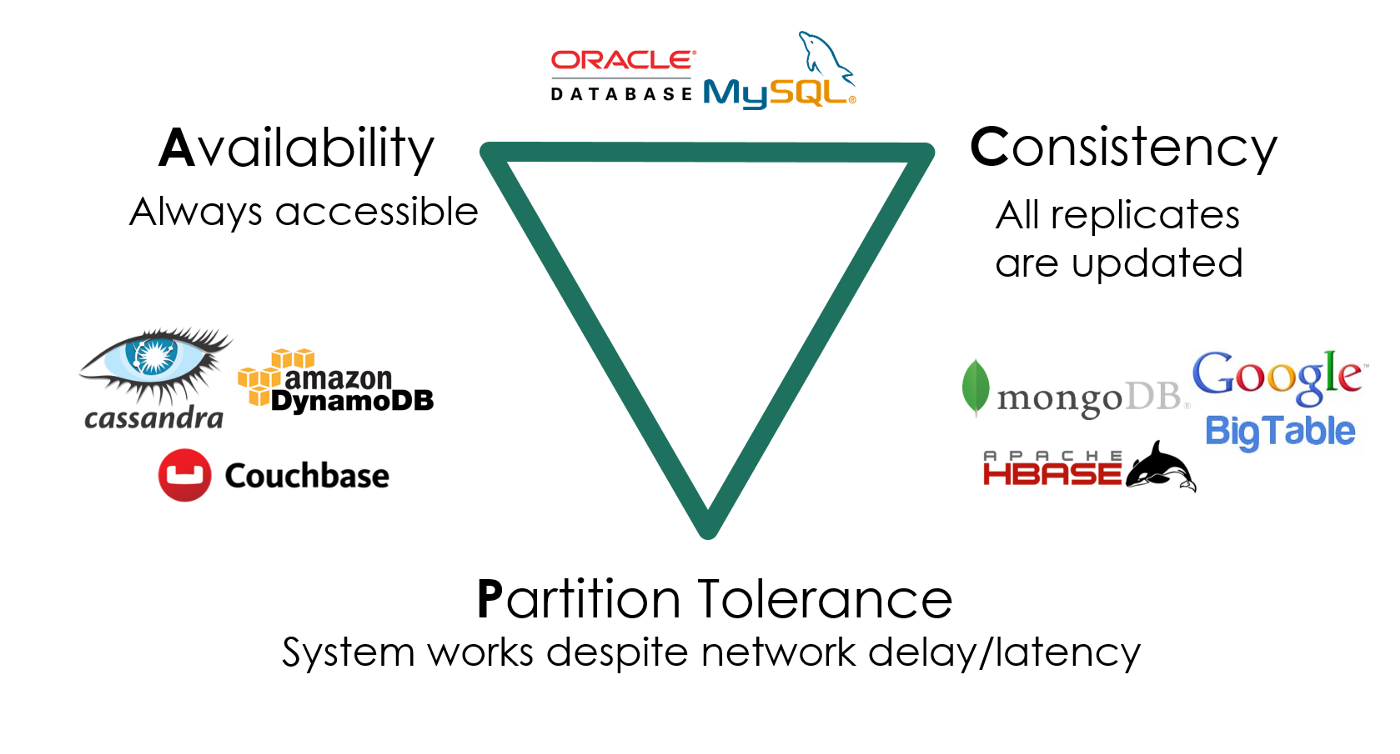
数据中心:主要挑战
多副本情况下的高可靠、低延迟数据访问
- 在服务海量地理分布请求的前提下
- 数据要保持一致 (Consistency)
- 服务时刻保持可用 (Availability)
- 容忍机器离线 (Partition tolerance)
这门课的问题:如何用好一台计算机?
如何用一台 (可靠的) 计算机尽可能多地服务并行的请求
- 关键指标:QPS, tail latency, ...
我们有的工具
- 线程 (threads)
thread(start = true) {
println("${Thread.currentThread()} has run.")
}
- 协程 (coroutines)
- 多个可以保存/恢复的执行流 (M2 - libco)
- 比线程更轻量 (完全没有系统调用,也就没有操作系统状态)
数据中心:协程和线程
数据中心
- 同一时间有数千/数万个请求到达服务器
- 计算部分
- 需要利用好多处理器
- 线程 → 这就是我擅长的 (Mandelbrot Set)
- 协程 → 一人出力,他人摸鱼
- 需要利用好多处理器
- I/O 部分
- 会在系统调用上 block (例如请求另一个服务或读磁盘)
- 协程 → 一人干等,他人围观
- 线程 → 每个线程都占用可观的操作系统资源
- 会在系统调用上 block (例如请求另一个服务或读磁盘)
- (这个问题比你想象的复杂,例如虚拟机)
Go 和 Goroutine
Go: 小孩子才做选择,多处理器并行和轻量级并发我全都要!
Goroutine: 概念上是线程,实际是线程和协程的混合体
- 每个 CPU 上有一个 Go Worker,自由调度 goroutines
- 执行到 blocking API 时 (例如 sleep, read)
- Go Worker 偷偷改成 non-blocking 的版本
- 成功 → 立即继续执行
- 失败 → 立即 yield 到另一个需要 CPU 的 goroutine
- 太巧妙了!CPU 和操作系统全部用到 100%
- Go Worker 偷偷改成 non-blocking 的版本
例子
现代编程语言上的系统编程
Do not communicate by sharing memory; instead, share memory by communicating. ——Effective Go
共享内存 = 万恶之源
- 在奇怪调度下发生的各种并发 bugs
- 条件变量:broadcast 性能低,不 broadcast 容易错
- 信号量:在管理多种资源时就没那么好用了
既然生产者-消费者能解决绝大部分问题,提供一个 API 不就好了?
- producer-consumer.go
- 缓存为 0 的 channel 可以用来同步 (先到者等待)
Web 2.0 时代 (1999)
人与人之间联系更加紧密的互联网
- “Users were encouraged to provide content, rather than just viewing it.”
- 你甚至可以找到一些 “Web 3.0”/Metaverse 的线索
是什么成就了今天的 Web 2.0?
- 浏览器中的并发编程:Ajax (Asynchronous JavaScript + XML)
- HTML (DOM Tree) + CSS 代表了你能看见的一切
- 通过 JavaScript 可以改变它
- 通过 JavaScript 可以建立连接本地和服务器
- 你就拥有了全世界!
人机交互程序:特点和主要挑战
特点:不太复杂
- 既没有太多计算
- DOM Tree 也不至于太大 (大了人也看不过来)
- DOM Tree 怎么画浏览器全帮我们搞定了
- 也没有太多 I/O
- 就是一些网络请求
挑战:程序员多
- 零基础的人你让他整共享内存上的多线程
- 恐怕我们现在用的到处都是 bug 吧???
单线程 + 事件模型
尽可能少但又足够的并发
- 一个线程、全局的事件队列、按序执行 (run-to-complete)
- 耗时的 API (Timer, Ajax, ...) 调用会立即返回
- 条件满足时向队列里增加一个事件
$.ajax( { url: 'https://xxx.yyy.zzz/login',
success: function(resp) {
$.ajax( { url: 'https://xxx.yyy.zzz/cart',
success: function(resp) {
// do something
},
error: function(req, status, err) { ... }
}
},
error: function(req, status, err) { ... }
);
Go 和 Goroutine
Go: 小孩子才做选择,多处理器并行和轻量级并发我全都要!
Goroutine: 概念上是线程,实际是线程和协程的混合体
- 每个 CPU 上有一个 Go Worker,自由调度 goroutines
- 执行到 blocking API 时 (例如 sleep, read)
- Go Worker 偷偷改成 non-blocking 的版本
- 成功 → 立即继续执行
- 失败 → 立即 yield 到另一个需要 CPU 的 goroutine
- 太巧妙了!CPU 和操作系统全部用到 100%
- Go Worker 偷偷改成 non-blocking 的版本
例子
现代编程语言上的系统编程
Do not communicate by sharing memory; instead, share memory by communicating. ——Effective Go
共享内存 = 万恶之源
- 在奇怪调度下发生的各种并发 bugs
- 条件变量:broadcast 性能低,不 broadcast 容易错
- 信号量:在管理多种资源时就没那么好用了
既然生产者-消费者能解决绝大部分问题,提供一个 API 不就好了?
- producer-consumer.go
- 缓存为 0 的 channel 可以用来同步 (先到者等待)
人机交互程序:特点和主要挑战
特点:不太复杂
- 既没有太多计算
- DOM Tree 也不至于太大 (大了人也看不过来)
- DOM Tree 怎么画浏览器全帮我们搞定了
- 也没有太多 I/O
- 就是一些网络请求
挑战:程序员多
- 零基础的人你让他整共享内存上的多线程
- 恐怕我们现在用的到处都是 bug 吧???
单线程 + 事件模型
尽可能少但又足够的并发
- 一个线程、全局的事件队列、按序执行 (run-to-complete)
- 耗时的 API (Timer, Ajax, ...) 调用会立即返回
- 条件满足时向队列里增加一个事件
$.ajax( { url: 'https://xxx.yyy.zzz/login',
success: function(resp) {
$.ajax( { url: 'https://xxx.yyy.zzz/cart',
success: function(resp) {
// do something
},
error: function(req, status, err) { ... }
}
},
error: function(req, status, err) { ... }
);
异步事件模型
好处
- 并发模型简单了很多
- 函数的执行是原子的 (不能并行,减少了并发 bug 的可能性)
- API 依然可以并行
- 适合网页这种 “大部分时间花在渲染和网络请求” 的场景
- JavaScript 代码只负责 “描述” DOM Tree
- 适合网页这种 “大部分时间花在渲染和网络请求” 的场景
坏处
- Callback hell (祖传屎山)
- 刚才的代码嵌套 5 层,可维护性已经接近于零了
异步编程:Promise
导致 callback hell 的本质:人类脑袋里想的是 “流程图”,看到的是 “回调”。
The Promise object represents the eventual completion (or failure) of an asynchronous operation and its resulting value.
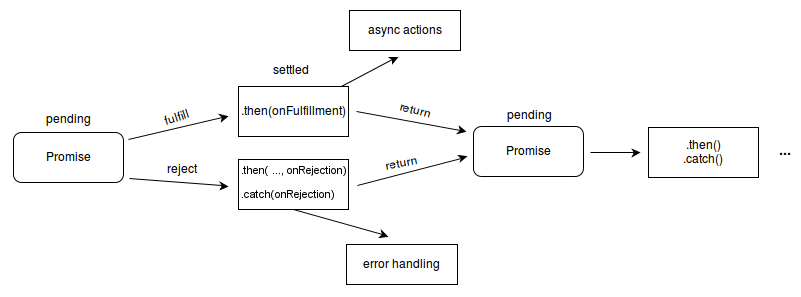
Promise: 描述 Workflow 的 “嵌入式语言”
Chaining
loadScript("/article/promise-chaining/one.js")
.then( script => loadScript("/article/promise-chaining/two.js") )
.then( script => loadScript("/article/promise-chaining/three.js") )
.then( script => {
// scripts are loaded, we can use functions declared there
})
.catch(err => { ... } );
Fork-join
a = new Promise( (resolve, reject) => { resolve('A') } )
b = new Promise( (resolve, reject) => { resolve('B') } )
c = new Promise( (resolve, reject) => { resolve('C') } )
Promise.all([a, b, c]).then( res => { console.log(res) } )Async-Await: Even Better
async function
- 总是返回一个
Promiseobject async_func()- fork
await promise
await promise- join
A = async () => await $.ajax('/hello/a')
B = async () => await $.ajax('/hello/b')
C = async () => await $.ajax('/hello/c')
hello = async () => await Promise.all([A(), B(), C()])
hello()
.then(window.alert)
.catch(res => { console.log('fetch failed!') } )
总结
本次课回答的问题
- Q: 什么样的任务是需要并行/并发的?它们应该如何实现?
Take-away message
- 并发编程的真实应用场景
- 高性能计算 (注重任务分解): 生产者-消费者 (MPI/OpenMP)
- 数据中心 (注重系统调用): 线程-协程 (Goroutine)
- 人机交互 (注重易用性): 事件-流图 (Promise)
- 编程工具的发展突飞猛进
- 自 Web 2.0 以来,开源社区改变了计算机科学的学习方式
- 希望每个同学都有一个 “主力现代编程语言”
- Modern C++, Rust, Javascript, ...
M2: 协程库 (libco) https://jyywiki.cn/OS/2022/labs/M2
M2: 协程库 (libco)
⏰ 截止日期
Soft Deadline: 2022 年 3 月 20 日 23:59:59。
你需要首先阅读实验须知。
在命令行中
git pull origin M2下载框架代码。
⚠️ 难度警告
在这个实验中,需要冷静下来调试你的代码——“看起来大概正确” 的代码很可能不能正常工作。如果发生奇怪的错误,不用着急,想一想上课介绍过的调试工具,想一想 “程序就是状态机”,然后开始理解出错的过程。请你相信你自己的能力,并且尽最大可能遵守学术诚信,独立地设计测试用例、解决你遇到的问题,这会使你的编程能力更上一个台阶。
1. 背景
我们在《操作系统》课程中学习了线程,学会了使用 thread.h (和 pthreads 线程库) 创建和管理线程。线程的创建需要操作系统的支持:我们允许在线程里编写 while (1); 这样的死循环,但操作系统却可以 “打断” 它的执行,或是把多个线程调度到多个处理器上。
❓ 本实验解决的问题
我们有没有可能在不借助操作系统 API (也不解释执行代码) 的前提下,用一个进程 (状态机) 去模拟多个共享内存的执行流 (状态机)?
“多线程程序” 的语义是 “同时维护多个线程的栈帧和 PC 指针,每次选择一个线程执行一步”。有些语言允许我们这么做,例如我们 model checker 的实现借助了 generator object:
def positive_integers():
i = 0
while i := i + 1:
yield i # "return" i, 但函数可以继续执行
调用 generator function 会创建一个闭包 (closure),闭包的内部会存储所有局部变量和执行流的位置,遇到 yield 时执行流返回,但闭包仍然可以继续使用,例如:
def is_prime(i):
return i >= 2 and \
True not in (i % j == 0 for j in range(2, i))
primes = (i for i in positive_integers() if is_prime(i)) # 所有素数的顺序集合
# primes: <generator object <genexpr> at 0x7f142c14c9e8>
从 C 语言形式语义的角度,这部分代码显得有些难以置信,因为函数调用就是创建栈帧、函数返回就是弹出栈帧,除此之外没有操作可以再改变栈帧链的结构。从二进制代码的角度,函数结束后,访问局部变量的行为就是 undefined behavior (你应该为此吃过苦头)。
2. 实验描述
在这个实验中,我们实现轻量级的用户态携谐协程 (coroutine,“协同程序”),也称为 green threads、user-level threads,可以在一个不支持线程的操作系统上实现共享内存多任务并发。即我们希望实现 C 语言的 “函数”,它能够:
- 被
start()调用,从头开始运行; - 在运行到中途时,调用
yield()被 “切换” 出去; - 稍后有其他协程调用
yield()后,选择一个先前被切换的协程继续执行。
协程这一概念最早出现在 Melvin Conway 1963 年的论文 "Design of a separable transition-diagram compiler",它实现了 “可以暂停和恢复执行” 的函数。
2.1. 实验要求
实现协程库 co.h 中定义的 API:
struct co *co_start(const char *name, void (*func)(void *), void *arg);
void co_yield();
void co_wait(struct co *co);
协程库的使用和线程库非常类似:
co_start(name, func, arg)创建一个新的协程,并返回一个指向struct co的指针 (类似于pthread_create)。- 新创建的协程从函数
func开始执行,并传入参数arg。新创建的协程不会立即执行,而是调用co_start的协程继续执行。 - 使用协程的应用程序不需要知道
struct co的具体定义,因此请把这个定义留在co.c中;框架代码中并没有限定struct co结构体的设计,所以你可以自由发挥。 co_start返回的struct co指针需要分配内存。我们推荐使用malloc()分配。
- 新创建的协程从函数
co_wait(co)表示当前协程需要等待,直到co协程的执行完成才能继续执行 (类似于pthread_join)。- 在被等待的协程结束后、
co_wait()返回前,co_start分配的struct co需要被释放。如果你使用malloc(),使用free()释放即可。 - 因此,每个协程只能被
co_wait一次 (使用协程库的程序应当保证除了初始协程外,其他协程都必须被co_wait恰好一次,否则会造成内存泄漏)。
- 在被等待的协程结束后、
co_yield()实现协程的切换。协程运行后一直在 CPU 上执行,直到func函数返回或调用co_yield使当前运行的协程暂时放弃执行。co_yield时若系统中有多个可运行的协程时 (包括当前协程),你应当随机选择下一个系统中可运行的协程。main函数的执行也是一个协程,因此可以在main中调用co_yield或co_wait。main函数返回后,无论有多少协程,进程都将直接终止。
2.2. 协程的使用
下面是协程库使用的一个例子,创建两个 (永不结束的) 协程,分别打印 a 和 b。由于 co_yield() 之后切换到的协程是随机的 (可能切换到它自己),因此你将会看到随机的 ab 交替出现的序列,例如 ababbabaaaabbaa...
#include <stdio.h>
#include "co.h"
void entry(void *arg) {
while (1) {
printf("%s", (const char *)arg);
co_yield();
}
}
int main() {
struct co *co1 = co_start("co1", entry, "a");
struct co *co2 = co_start("co2", entry, "b");
co_wait(co1); // never returns
co_wait(co2);
}
当然,协程有可能会返回,例如在下面的例子 (测试程序) 中,两个协程会交替执行,共享 counter 变量:
#include <stdio.h>
#include "co.h"
int count = 1; // 协程之间共享
void entry(void *arg) {
for (int i = 0; i < 5; i++) {
printf("%s[%d] ", (const char *)arg, count++);
co_yield();
}
}
int main() {
struct co *co1 = co_start("co1", entry, "a");
struct co *co2 = co_start("co2", entry, "b");
co_wait(co1);
co_wait(co2);
printf("Done\n");
}
正确的协程实现应该输出类似于以下的结果:字母是随机的 (a 或 b),数字则从 1 到 10 递增。
b[1] a[2] b[3] b[4] a[5] b[6] b[7] a[8] a[9] a[10] Done
从 “程序是状态机” 的角度,协程的行为理解起来会稍稍容易一些。首先,所有的协程是共享内存的——就是协程所在进程的地址空间。此外,每个协程想要执行,就需要拥有独立的堆栈和寄存器 (这一点与线程相同)。一个协程的寄存器、堆栈、共享内存就构成了当且协程的状态机执行,然后:
co_start会在共享内存中创建一个新的状态机 (堆栈和寄存器也保存在共享内存中),仅此而已。新状态机的%rsp寄存器应该指向它独立的堆栈,%rip寄存器应该指向co_start传递的func参数。根据 32/64-bit,参数也应该被保存在正确的位置 (x86-64 参数在%rdi寄存器,而 x86 参数在堆栈中)。main天然是个状态机,就对应了一个协程;co_yield会将当前运行协程的寄存器保存到共享内存中,然后选择一个另一个协程,将寄存器加载到 CPU 上,就完成了 “状态机的切换”;co_wait会等待状态机进入结束状态,即func()的返回。
2.3. 协程和线程
协程和线程的 API 非常相似。例如 threads.h 中提供的
void create(void (*func)(void *));
void join();
刚好对应了 co_start 和 co_wait (join 会在 main 返回后,对每个创建的线程调用 pthread_join,依次等待它们结束,但我们的协程库中 main 返回后将立即终止)。唯一不同的是,线程的调度不是由线程决定的 (由操作系统和硬件决定),但协程除非执行 co_yield() 主动切换到另一个协程运行,当前的代码就会一直执行下去。
协程会在执行 co_yield() 时主动让出处理器,调度到另一个协程执行。因此,如果能保证 co_yield() 的定时执行,我们甚至可以在进程里实现线程。这就有了操作系统教科书上所讲的 “用户态线程”——线程可以看成是每一条语句后都 “插入” 了 co_yield() 的协程。这个 “插入” 操作是由两方实现的:操作系统在中断后可能引发上下文切换,调度另一个线程执行;在多处理器上,两个线程则是真正并行执行的。
协程与线程的区别在于协程是完全在应用程序内 (低特权运行级) 实现的,不需要操作系统的支持,占用的资源通常也比操作系统线程更小一些。协程可以随时切换执行流的特性,用于实现状态机、actor model, goroutine 等。在实验材料最前面提到的 Python/Javascript 等语言里的 generator 也是一种特殊的协程,它每次 co_yield 都将控制流返回到它的调用者,而不是像本实验一样随机选择一个可运行的协程。
3. 正确性标准
⚠️ 代码实现要求
请将你所有的代码实现在
co.c中不要修改
co.h。Online Judge 在评测时仅拷贝你的co.c文件。
首先,我们预期你提交的代码能通过附带的测试用例,测试用例有两组:
- (Easy) 创建两个协程,每个协程会循环 100 次,然后打印当前协程的名字和全局计数器
g_count的数值,然后执行g_count++。 - (Hard) 创建两个生产者、两个消费者。每个生产者每次会向队列中插入一个数据,然后执行
co_yield()让其他 (随机的) 协程执行;每个消费者会检查队列是否为空,如果非空会从队列中取出头部的元素。无论队列是否为空,之后都会调用co_yield()让其他 (随机的) 协程执行
执行 make test 会在 x86-64 和 x86-32 两个环境下运行你的代码——如果你看到第一个测试用例打印出数字 X/Y-0 到 X/Y-199、第二个测试用例打印出 libco-200 到 libco-399,说明你的实现基本正确;否则请调试你的代码。
Online Judge 上会运行类似的测试 (也会在 x86-64 和 x86-32 两个平台上运行),但规模可能稍大一些。你可以假设:
- 每个协程的堆栈使用不超过 64 KiB;
- 任意时刻系统中的协程数量不会超过 128 个 (包括
main对应的协程)。协程wait返回后协程的资源应当被回收——我们可能会创建大量的协程执行-等待-销毁、执行-等待-销毁。因此如果你的资源没有及时回收,可能会发生 Memory Limit Exceeded 问题。
还需要注意的是,提交的代码不要有任何多余的输出,否则可能会被 Online Judge 判错。如果你希望在本地运行时保留调试信息并且不想在提交到 Online Judge 时费力地删除散落在程序中的调试信息,你可以尝试用一个你本地的宏来控制输出的行为,例如
#ifdef LOCAL_MACHINE
#define debug(...) printf(__VA_ARGS__)
#else
#define debug()
#endif
然后通过增加 -DLOCAL_MACHINE 的编译选项来实现输出控制——在 Online Judge 上,所有的调试输出都会消失。
ℹ️ 克服你的惰性
在新手阶段,你很容易觉得做上面两件事会比较受挫:首先,你可以用注释代码的办法立即搞定,所以你的本能驱使你不去考虑更好的办法。但当你来回浪费几次时间之后,你应该回来试着优化你的基础设施。可能你会需要一些时间阅读文档或调试你的 Makefile,但它们的收获都是值得的。
4. 实验指南
不要慌
虽然这个实验有点难
以前的实验都是有明确目标的,比如 OJ 题给定输入和输出。但这次不一样,我们要 hack C 语言运行时的行为——写一个函数 “切换” 到另一个函数执行。听起来就无从下手。
但是依然不要慌:程序就是状态机,总有办法的。让我们一起分析这个问题。
4.1. 编译和运行
我们的框架代码的 co.c 中没有 main 函数——它并不会被编译成一个能直接在 Linux 上执行的二进制文件。编译脚本会生成共享库 (shared object, 动态链接库) libco-32.so 和 libco-64.so:
$ file libco-64.so
libco-64.so: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), ...
共享库可以有自己的代码、数据,甚至可以调用其他共享库 (例如 libc, libpthread 等)。共享库中全局的符号将能被加载它的应用程序调用。共享库中不需要入口 (main 函数)。我们的 Makefile 里已经写明了如何编译共享库:
$(NAME)-64.so: $(DEPS) # 64bit shared library
gcc -fPIC -shared -m64 $(CFLAGS) $(SRCS) -o $@ $(LDFLAGS)
其中 -fPIC -fshared 就代表编译成位置无关代码的共享库。除此之外,共享库和普通的二进制文件没有特别的区别。虽然这个文件有 +x 属性并且可以执行,但会立即得到 Segmentation Fault (可以试着用 gdb 调试它)。
❓ 奇怪的知识增加了
能不能得到既可以运行又可以动态加载的库文件?
是否可以让共享库同时作为命令行工具和动态链接库?这并不是一个 “标准” 的操作系统——可执行文件和共享库有着不同的假设。但这件事的确可以办到!一个典型的例子是进程执行的第一条指令所在的
/lib64/ld-linux-x86-64.so.2:$ /lib64/ld-linux-x86-64.so.2 Usage: ld.so [OPTION]... EXECUTABLE-FILE [ARGS-FOR-PROGRAM...] You have invoked `ld.so', the helper program for shared library executables. This program usually lives in the file `/lib/ld.so', and special directives in executable files using ELF shared libraries tell the system's program loader to load the helper program from this file. This helper program loads the shared libraries needed by the program executable, prepares the program to run, and runs it...有兴趣的同学可以 STFW 这是如何做到的。
4.2. 使用协程库
为了降低大家 STFW/RTFM 的难度,我们提供了一组协程库的测试用例 (tests/ 目录下),包含了编译和运行所需的脚本,其中编译的编译选项是
gcc -I.. -L.. -m64 main.c -o libco-test-64 -lco-64
gcc -I.. -L.. -m32 main.c -o libco-test-32 -lco-32
注意到 -I 和 -L 选项的使用:
-I选项代表 include path,使我们可以#include <co.h>。你可以使用gcc --verbose编译看到编译器使用的 include paths。-L选项代表增加 link search path。-l选项代表链接某个库,链接时会自动加上lib的前缀,即-lco-64会依次在库函数的搜索路径中查找libco-64.so和libco-64.a,直到找到为止。如果你将libco-64.so删除后用 strace 工具查看 gcc 运行时使用的系统调用,就能清晰地看到库函数解析的流程;
在运行时,使用 make test 直接运行,它执行的命令是:
LD_LIBRARY_PATH=.. ./libco-test-64
如果不设置 LD_LIBRARY_PATH 环境变量,你将会遇到 “error while loading shared libraries: libco-xx.so: cannot open shared object file: No such file or directory” 的错误。请 STFW 理解这个环境变量的含义。
至此,我们已经完成了共享库的编译,以及让一个 C 程序动态链接共享库执行。
小技巧:调试你的代码
直接运行
./libco-test-64会遇到 No such file or directory 的问题;当然,只需要用make test就可以解决这个问题了。但如果想要调试代码?gdb libco-test-64同样也会遇到共享库查找失败的问题。大家可以在终端中使用export将当前 shell 进程的LD_LIBRARY_PATH设置好,这样就可以无障碍地运行./libco-test-64了。
4.3. 实现协程:分析
下面我们先假设协程已经创建好,我们分析 co_yield() 应该如何实现。
首先,co_yield 函数不能正常返回 (return;对应了 ret 指令),否则 co_yield 函数的调用栈帧 (stack frame) 会被摧毁,我们的 yield 切换到其他协程的想法就 “失败” 了。如果没有思路,你至少可以做的一件事情是理解 co_yield 发生的时候,我们的程序到底处于什么状态。而这 (状态机的视角) 恰恰是解开所有问题的答案。
不妨让我们先写一小段协程的测试程序:
void foo() {
int i;
for (int i = 0; i < 1000; i++) {
printf("%d\n", i);
co_yield();
}
}
这个程序在 co_yield() 之后可能会切换到其他协程执行,但最终它依然会完成 1, 2, 3, ... 1000 的打印。我们不妨先看一下这段代码编译后的汇编指令序列 (objdump):
push %rbp
push %rbx
lea <stdout>, %rbp
xor %ebx, %ebx
sub $0x8, %rsp
mov %ebx, %esi
mov %rbp, %rdi
xor %eax, %eax
callq <printf@plt>
inc %ebx
xor %eax, %eax
callq <co_yield> // <- 切换到其他协程
cmp $0x3e8, %ebx
jne 669 <foo+0xf>
pop %rax
pop %rbx
pop %rbp
retq
首先,co_yield 还是一个函数调用。函数调用就遵循 x86-64 的 calling conventions (System V ABI):
- 前 6 个参数分别保存在 rdi, rsi, rdx, rcx, r8, r9。当然,
co_yield没有参数,这些寄存器里的数值也没有意义。 co_yield可以任意改写上面的 6 个寄存器的值以及 rax (返回值), r10, r11,返回后foo仍然能够正确执行。co_yield返回时,必须保证 rbx, rsp, rbp, r12, r13, r14, r15 的值和调用时保持一致 (这些寄存器称为 callee saved/non-volatile registers/call preserved, 和 caller saved/volatile/call-clobbered 相反)。
换句话说,我们已经有答案了:co_yield 要做的就是把 yield 瞬间的 call preserved registers “封存” 下来 (其他寄存器按照 ABI 约定,co_yield 既然是函数,就可以随意摧毁),然后执行堆栈 (rsp) 和执行流 (rip) 的切换:
mov (next_rsp), $rsp
jmp *(next_rip)
因此,为了实现 co_yield,我们需要做的事情其实是:
- 为每一个协程分配独立的堆栈;堆栈顶的指针由
%rsp寄存器确定; - 在
co_yield发生时,将寄存器保存到属于该协程的struct co中 (包括%rsp); - 切换到另一个协程执行,找到系统中的另一个协程,然后恢复它
struct co中的寄存器现场 (包括%rsp)。
4.4. 实现协程:数据结构
例如,参考实现的 struct co 是这样定义的:
enum co_status {
CO_NEW = 1, // 新创建,还未执行过
CO_RUNNING, // 已经执行过
CO_WAITING, // 在 co_wait 上等待
CO_DEAD, // 已经结束,但还未释放资源
};
struct co {
char *name;
void (*func)(void *); // co_start 指定的入口地址和参数
void *arg;
enum co_status status; // 协程的状态
struct co * waiter; // 是否有其他协程在等待当前协程
jmp_buf context; // 寄存器现场 (setjmp.h)
uint8_t stack[STACK_SIZE]; // 协程的堆栈
};
看起来就像是在《计算机系统基础》中实现的上下文切换!我们推荐大家使用 C 语言标准库中的 setjmp/longjmp 函数来实现寄存器现场的保存和恢复。在《计算机系统基础》实验中,我们已经用汇编代码实现了这两个函数。没有好好做实验的同学,要加油补上啦!
4.5. 实现寄存器现现场切换
分配堆栈是容易的:堆栈直接嵌入在 struct co 中即可,在 co_start 时初始化即可。但麻烦的是如何让 co_start 创建的协程,切换到指定的堆栈执行。AbstractMachine 的实现中有一个精巧的 stack_switch_call (x86.h),可以用于切换堆栈后并执行函数调用,且能传递一个参数,请大家完成阅读理解 (对完成实验有巨大帮助):
static inline void stack_switch_call(void *sp, void *entry, uintptr_t arg) {
asm volatile (
#if __x86_64__
"movq %0, %%rsp; movq %2, %%rdi; jmp *%1"
: : "b"((uintptr_t)sp), "d"(entry), "a"(arg) : "memory"
#else
"movl %0, %%esp; movl %2, 4(%0); jmp *%1"
: : "b"((uintptr_t)sp - 8), "d"(entry), "a"(arg) : "memory"
#endif
);
}
理解上述函数你需要的文档:GCC-Inline-Assembly-HOWTO。当然,这个文档有些过时,如果还有不明白的地方,gcc 的官方手册是最佳的阅读材料。
警告:堆栈对齐
x86-64 要求堆栈按照 16 字节对齐 (x86-64 的堆栈以 8 字节为一个单元),这是为了确保 SSE 指令集中 XMM 寄存器变量的对齐。如果你的程序遇到了神秘的 Segmentation Fault (可能在某个 libc 的函数中),如果你用 gdb 确定到 Segmentation Fault 的位置,而它恰好是一条 SSE 指令,例如
movaps %xmm0,0x50(%rsp) movaps %xmm1,0x60(%rsp) ...那很可能就是你的堆栈没有正确对齐。我们故意没有说的是,System V ABI (x86-64) 对堆栈对齐的要求,是在 “何时” 做出的——在
call指令之前按 16 字节对齐,在call指令之后就不对齐了。一方面你可以暴力地尝试一下;如果你想更深入地理解这个问题,就需要读懂stack_switch_call,以及 STFW 关于 ABI 对对齐的要求,或是查看编译出的汇编代码。
每当 co_yield() 发生时,我们都会选择一个协程继续执行,此时必定为以下两种情况之一 (思考为什么):
- 选择的协程是新创建的,此时该协程还没有执行过任何代码,我们需要首先执行
stack_switch_call切换堆栈,然后开始执行协程的代码; - 选择的协程是调用
yield()切换出来的,此时该协程已经调用过setjmp保存寄存器现场,我们直接longjmp恢复寄存器现场即可。
当然,上述过程描述相当的抽象;你可能会花一点时间,若干次试错,才能实现第一次切换到另一个协程执行——当然,这会让你感到非常的兴奋。之后,你还会面对一些挑战,例如如何处理 co_wait,但把这些难关一一排除以后,你会发现你对计算机系统 (以及 “程序是个状态机”) 的理解更深刻了。
⚠️ 用好 gdb
gdb 是这个实验的好帮手,无论如何都要逼自己熟练掌握。例如,你可以试着调试一小段 setjmp/longjmp 的代码,来观察 setjmp/longjmp 是如何处理寄存器和堆栈的,例如是否只保存了 volatile registers 的值?如何实现堆栈的切换?堆栈式如何对齐的?
int main() { int n = 0; jmp_buf buf; setjmp(buf); printf("Hello %d\n", n); longjmp(buf, n++); }无论你觉得你理解得多么 “清楚”,亲手调试过代码后的感觉仍是很不一样的。
4.6. 实现协程
非常难理解?坚持住!
没错,的确很难理解。如果你没有完成《计算机系统基础》中的
setjmp/longjmp实验,你需要多读一读setjmp/longjmp的文档和例子——这是很多高端面试职位的必备题目。如果你能解释得非常完美,就说明你对 C 语言有了脱胎换骨的理解。setjmp/longjmp的 “寄存器快照” 机制还被用来做很多有趣的 hacking,例如实现事务内存、在并发 bug 发生以后的线程本地轻量级 recovery 等等。
setjmp/longjmp类似于保存寄存器现场/恢复寄存器现场的行为,其实模拟了操作系统中的上下文切换。因此如果你彻底理解了这个例子,你们一定会觉得操作系统也不过如此——我们在操作系统的进程之上又实现了一个迷你的 “操作系统”。类似的实现还有 AbstractMachine 的native,它是通过ucontext.h实现的,有兴趣的同学也可以尝试阅读 AbstractMachine 的代码。
在参考实现中,我们维护了 “当前运行的协程” 的指针 (这段代码非常类似于操作系统中,为每一个 CPU 维护一个 “当前运行的进程”):
struct co *current;
这样,在 co_yield 时,我们就知道要将寄存器现场保存到哪里。我们使用的代码是
void co_yield() {
int val = setjmp(current->context);
if (val == 0) {
// ?
} else {
// ?
}
}
在上面的代码中,setjmp 会返回两次:
- 在
co_yield()被调用时,setjmp保存寄存器现场后会立即返回0,此时我们需要选择下一个待运行的协程 (相当于修改current),并切换到这个协程运行。 setjmp是由另一个longjmp返回的,此时一定是因为某个协程调用co_yield(),此时代表了寄存器现场的恢复,因此不必做任何操作,直接返回即可。
最后,框架代码里有一行奇怪的 CFLAGS += -U_FORTIFY_SOURCE,用来防止 __longjmp_chk 代码检查到堆栈切换以后报错 (当成是 stack smashing)。Google 的 sanitizer 也遇到了相同的问题。
4.7. 资源初始化、管理和释放
需要初始化?
如果你希望在程序运行前完成一系列的初始化工作 (例如分配一些内存),可以定义
__attribute__((constructor))属性的函数,它们会在main执行前被运行。我们在课堂上已经讲解过。
这个实验最后的麻烦是管理 co_start 时分配的 struct co 结构体资源。很多时候,我们的库函数都涉及到资源的管理,在面向 OJ 编程时,大家养成了很糟糕的习惯:只管申请、不管释放,依赖操作系统在进程结束后自动释放资源。但如果是长期运行的程序,这些没有释放但又不会被使用的泄露资源就成了很大但问题,例如在 Windows XP 时代,桌面 Windows 是没有办法做到开机一星期的,一周之后机器就一定会变得巨卡无比。
管理内存说起来轻巧——一次分配对应一次回收即可,但协程库中的资源管理有些微妙 (但并不复杂),因为 co_wait 执行的时候,有两种不同的可能性:
- 此时协程已经结束 (
func返回),这是完全可能的。此时,co_wait应该直接回收资源。 - 此时协程尚未结束,因此
co_wait不能继续执行,必须调用co_yield切换到其他协程执行,直到协程结束后唤醒。
希望大家仔细考虑好每一种可能的情况,保证你的程序不会在任何一种情况下 crash 或造成资源泄漏。然后你会发现,假设每个协程都会被 co_wait 一次,且在 co_wait 返回时释放内存是一个几乎不可避免的设计:如果允许在任意时刻、任意多次等待任意协程,那么协程创建时分配的资源就无法做到自动回收了——即便一个协程结束,我们也无法预知未来是否还会执行对它的 co_wait,而对已经回收的 (非法) 指针的 co_wait 将导致 undefined behavior。C 语言中另一种常见 style 是让用户管理资源的分配和释放,显式地提供 co_free 函数,在用户确认今后不会使用时释放资源。
资源管理一直是计算机系统世界的难题,至今很多系统还受到资源泄漏、use-after-free 的困扰。例如,顺着刚才资源释放的例子,你可能会感觉 pthread 线程库似乎有点麻烦:pthread_create() 会修改一个 pthread_t 的值,线程返回以后资源似乎应该会被释放。那么:
- 如果
pthread_join发生在结束后不久,资源还未被回收,函数会立即返回。 - 如果
pthread_join发生在结束以后一段时间,可能会得到ESRCH(no such thread) 错误。 - 如果
pthread_join发生在之后很久很久很久很久,资源被释放又被再次复用 (pthread_t是一个的确可能被复用的整数),我不就 join 了另一个线程了吗?这恐怕要出大问题。
实际上,pthread 线程默认是 “joinable” 的。joinable 的线程只要没有 join 过,资源就一直不会释放。特别地,文档里写明: Failure to join with a thread that is joinable (i.e., one that is not detached), produces a "zombie thread". Avoid doing this, since each zombie thread consumes some system resources, and when enough zombie threads have accumulated, it will no longer be possible to create new threads (or processes).
这就是实际系统中各种各样的 “坑”。在《操作系统》这门课程中,我们尽量不涉及这些复杂的行为,而是力图用最少的代码把必要的原理解释清楚。当大家对基本原理有深入的理解后,随着经验的增长,就会慢慢考虑到更周全的系统设计。
https://en.wikipedia.org/wiki/Subroutine
In computer programming, a subroutine is a sequence of program instructions that perform a specific task, packaged as a unit. This unit can then be used in programs wherever that particular task should be performed.
Subprograms may be defined within programs, or separately in libraries that can be used by multiple programs. In different programming languages, a subroutine may be called a procedure, a function, a routine, a method, or a subprogram. The generic term callable unit is sometimes used.[1]
Subroutines are special cases of ... coroutines.
https://en.wikipedia.org/wiki/Coroutine
Coroutines are computer-program components that generalize subroutines for non-preemptive multitasking, by allowing multiple entry points for suspending and resuming execution at certain locations. Coroutines are well-suited for implementing familiar program components such as cooperative tasks, exceptions, event loops, iterators, infinite lists and pipes.
According to Donald Knuth, Melvin Conway coined the term coroutine in 1958 when he applied it to construction of an assembly program.[1] The first published explanation of the coroutine appeared later, in 1963.[2]
Comparison with subroutines[edit]
Subroutines are special cases of coroutines.[3] When subroutines are invoked, execution begins at the start, and once a subroutine exits, it is finished; an instance of a subroutine only returns once, and does not hold state between invocations. By contrast, coroutines can exit by calling other coroutines, which may later return to the point where they were invoked in the original coroutine; from the coroutine's point of view, it is not exiting but calling another coroutine.[3] Thus, a coroutine instance holds state, and varies between invocations; there can be multiple instances of a given coroutine at once. The difference between calling another coroutine by means of "yielding" to it and simply calling another routine (which then, also, would return to the original point), is that the relationship between two coroutines which yield to each other is not that of caller-callee, but instead symmetric.
Any subroutine can be translated to a coroutine which does not call yield.[4]
Here is a simple example of how coroutines can be useful. Suppose you have a consumer-producer relationship where one routine creates items and adds them to a queue and another removes items from the queue and uses them. For reasons of efficiency, you want to add and remove several items at once. The code might look like this:
var q := new queue
coroutine produce
loop
while q is not full
create some new items
add the items to q
yield to consume
coroutine consume
loop
while q is not empty
remove some items from q
use the items
yield to produce
The queue is then completely filled or emptied before yielding control to the other coroutine using the yield command. The further coroutines calls are starting right after the yield, in the outer coroutine loop.
Although this example is often used as an introduction to multithreading, two threads are not needed for this: the yield statement can be implemented by a jump directly from one routine into the other.
Comparison with threads[edit]
Coroutines are very similar to threads. However, coroutines are cooperatively multitasked, whereas threads are typically preemptively multitasked. This means that coroutines provide concurrency but not parallelism. The advantages of coroutines over threads are that they may be used in a hard-realtime context (switching between coroutines need not involve any system calls or any blocking calls whatsoever), there is no need for synchronisation primitives such as mutexes, semaphores, etc. in order to guard critical sections, and there is no need for support from the operating system.
It is possible to implement coroutines using preemptively-scheduled threads, in a way that will be transparent to the calling code, but some of the advantages (particularly the suitability for hard-realtime operation and relative cheapness of switching between them) will be lost.
Comparison with generators[edit]
Generators, also known as semicoroutines,[5] are a subset of coroutines. Specifically, while both can yield multiple times, suspending their execution and allowing re-entry at multiple entry points, they differ in coroutines' ability to control where execution continues immediately after they yield, while generators cannot, instead transferring control back to the generator's caller.[6] That is, since generators are primarily used to simplify the writing of iterators, the yield statement in a generator does not specify a coroutine to jump to, but rather passes a value back to a parent routine.
However, it is still possible to implement coroutines on top of a generator facility, with the aid of a top-level dispatcher routine (a trampoline, essentially) that passes control explicitly to child generators identified by tokens passed back from the generators:
var q := new queue
generator produce
loop
while q is not full
create some new items
add the items to q
yield consume
generator consume
loop
while q is not empty
remove some items from q
use the items
yield produce
subroutine dispatcher
var d := new dictionary(generator → iterator)
d[produce] := start produce
d[consume] := start consume
var current := produce
loop
current := next d[current]
A number of implementations of coroutines for languages with generator support but no native coroutines (e.g. Python[7] before 2.5) use this or a similar model.
Comparison with mutual recursion[edit]
Using coroutines for state machines or concurrency is similar to using mutual recursion with tail calls, as in both cases the control changes to a different one of a set of routines. However, coroutines are more flexible and generally more efficient. Since coroutines yield rather than return, and then resume execution rather than restarting from the beginning, they are able to hold state, both variables (as in a closure) and execution point, and yields are not limited to being in tail position; mutually recursive subroutines must either use shared variables or pass state as parameters. Further, each mutually recursive call of a subroutine requires a new stack frame (unless tail call elimination is implemented), while passing control between coroutines uses the existing contexts and can be implemented simply by a jump.
Common uses
Coroutines are useful to implement the following:
- State machines within a single subroutine, where the state is determined by the current entry/exit point of the procedure; this can result in more readable code compared to use of goto, and may also be implemented via mutual recursion with tail calls.
- Actor model of concurrency, for instance in video games. Each actor has its own procedures (this again logically separates the code), but they voluntarily give up control to central scheduler, which executes them sequentially (this is a form of cooperative multitasking).
- Generators, and these are useful for streams – particularly input/output – and for generic traversal of data structures.
- Communicating sequential processes where each sub-process is a coroutine. Channel inputs/outputs and blocking operations yield coroutines and a scheduler unblocks them on completion events. Alternatively, each sub-process may be the parent of the one following it in the data pipeline (or preceding it, in which case the pattern can be expressed as nested generators).
- Reverse communication, commonly used in mathematical software, wherein a procedure such as a solver, integral evaluator, ... needs the using process to make a computation, such as evaluating an equation or integrand.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号