flink_action 多级别的抽象 同时处理无界限(流)和有界限(批处理)数据集
CREATE TEMPORARY TABLE `nocache_table_test` (
`device_id` STRING
)
WITH (
'connector' = 'rds',
'username' = 'acforflink',
'password' = 'pwd',
'tableName' = 'table_test',
'url' = 'jdbc:mysql://pc-id.rwlb.rds.aliyuncs.com:3306/test_db?rewriteBatchedStatements=true&serverTimezone=GMT%2B8',
'cache' = 'None'
);
IPROERT INTO PROsink_noise(
data_version,
fireware_version,
proctime,
device_id,
pubtime,
latitude,
longitude,
MN,
LpA,
LpC,
LpZ,
Lp16,
Lp20,
Lp16000,
Lp20000,
Laf,
Las,
Lzi,
SDCal,
Delta,
Mode,
wind_speed,
wind_direction,
wind_temperature,
wind_humidity,
wind_illumination,
NoiseA
)
SELECT
data_version,
fireware_version,
proctime,
tb.device_id,
CSTFun( CAST(to_timestamp(pubtime) as timestamp(3)) ) as pubtime,
123.12,
34.12,
IntFun( CAST( NULLIF( MN, -999 ) AS INT) ),
DoubleFun( CAST( NULLIF( LpA, -999.0 ) AS DECIMAL(6,2)) ),
DoubleFun( CAST( NULLIF( LpC, -999.0 ) AS DECIMAL(6,2)) ),
DoubleFun( CAST( NULLIF( LpZ, -999.0 ) AS DECIMAL(6,2)) ),
DoubleFun( CAST( NULLIF( Lp16, -999.0 ) AS DECIMAL(6,2)) ),
DoubleFun( CAST( NULLIF( Lp20, -999.0 ) AS DECIMAL(6,2)) ),
DoubleFun( CAST( NULLIF( Delta, -999.0 ) AS DECIMAL(6,2)) ),
Mode,
DoubleFun( CAST( NULLIF( wind_speed, -999.0 ) AS DECIMAL(16,4)) ),
DoubleFun( CAST( NULLIF( wind_rainfall_intePROity, -999.0 ) AS DECIMAL(16,4)) ),
NoiseV1013Fun( DoubleFun( CAST( NULLIF( LpA, -999.0 ) AS DECIMAL(6,2)) ), DoubleFun( CAST( NULLIF( Delta, -999.0 ) AS DECIMAL(6,2))), DoubleFun( CAST( NULLIF( wind_temperature, -999.0 ) AS DECIMAL(16,4)) ),0,0,0 )
FROM PROsource_noise ta
LEFT JOIN nocache_table_test FOR SYSTEM_TIME AS OF ta.proctime AS tb ON ta.device_id=tb.device_id
where tb.device_id IS NOT NULL
;
通过识别原始数据,实现数据分流
同一个消息队列的topic,第一个字段为场景值,不同场景值字段个数、值不同,实现过滤、分流。
/*
print_table
CREATE TABLE print_table (
a1 varchar,
a2 varchar,
a3 varchar,
a4 varchar,
`proctime` TIMESTAMP(3)
) WITH (
'connector'='print',
'logger'='true'
);
CREATE TABLE table_one_topic_1_source(
`a1` STRING ,
`a2` VARCHAR(50) ,
`a3` VARCHAR(50) ,
`a4` VARCHAR(50) ,
proctime as PROCTIME()
) with (
'connector'='mq',
'instanceID'='MQ_INST_test',
'topic'='rmq_juya_dev',
'endpoint'='http://MQ_INST_test.cn-shenzhen.mq-internal.aliyuncs.com:8080',
'accessId'='aid',
'accessKey'='ak',
'pullIntervalMs'='100',
'consumerGroup'='GID_rmq_juya_dev_1',
'fieldDelimiter' = '#'
);
CREATE TABLE table_one_topic_2_source(
`a1` STRING ,
`a2` VARCHAR(50) ,
`a3` VARCHAR(50) ,
`a4` VARCHAR(50) ,
`b1` VARCHAR(50) ,
`b2` VARCHAR(50) ,
`b3` VARCHAR(50) ,
proctime as PROCTIME()
) with (
'connector'='mq',
'instanceID'='MQ_INST_test',
'topic'='rmq_juya_dev',
'endpoint'='http://MQ_INST_test.cn-shenzhen.mq-internal.aliyuncs.com:8080',
'accessId'='aid',
'accessKey'='ak',
'pullIntervalMs'='100',
'consumerGroup'='GID_rmq_juya_dev_2',
'fieldDelimiter' = '#'
);
CREATE TABLE `vvp`.`default`.`mqtt_one_topic_1_dev` (
`a1` STRING ,
`a2` VARCHAR(50) ,
`a3` VARCHAR(50) ,
`a4` VARCHAR(50) ,
`proctime` TIMESTAMP(3)
) COMMENT '<your comment here>'
WITH (
'connector' = 'rds',
'url' = 'jdbc:mysql://pc-test.rwlb.rds.aliyuncs.com:3306/dev_db?rewriteBatchedStatements=true&serverTimezone=GMT%2B8',
'userName' = 'acforflink',
'password' = 'pwd',
'tableName' = 'mqtt_one_topic_1_dev'
);
CREATE TABLE `vvp`.`default`.`mqtt_one_topic_2_dev` (
`a1` STRING ,
`a2` VARCHAR(50) ,
`a3` VARCHAR(50) ,
`a4` VARCHAR(50) ,
`b1` VARCHAR(50) ,
`b2` VARCHAR(50) ,
`b3` VARCHAR(50) ,
`proctime` TIMESTAMP(3)
) COMMENT '<your comment here>'
WITH (
'connector' = 'rds',
'url' = 'jdbc:mysql://pc-test.rwlb.rds.aliyuncs.com:3306/dev_db?rewriteBatchedStatements=true&serverTimezone=GMT%2B8',
'userName' = 'acforflink',
'password' = 'pwd',
'tableName' = 'mqtt_one_topic_2_dev'
);
CREATE TABLE print_sink (
a1 varchar,
a2 varchar,
a3 varchar,
a4 varchar,
`proctime` TIMESTAMP(3)
) WITH (
'connector'='print',
'logger'='true'
);
INSERT INTO print_sink SELECT * from table_source;
INSERT INTO mqtt_one_topic_1_dev SELECT * from table_one_topic_1_source where a1='1';
INSERT INTO mqtt_one_topic_2_dev SELECT * from table_one_topic_2_source where a1='2';
*/
INSERT INTO mqtt_one_topic_2_dev SELECT * from table_one_topic_2_source where a1='2';
什么是 Apache Flink?- Apache Flink 简介 - AWS https://aws.amazon.com/what-is/apache-flink/
同时处理无界限(流)和有界限(批处理)数据集
Apache Flink 既可以处理无界限数据集,也可以处理有界限数据集,即流和批处理数据。无界限流具有起点,但实际上是无限的,永远不会结束。从理论上讲,处理永远不会停止。
有界限数据(如表)是有限的,可以在有限的时间内从头到尾进行处理。
Apache Flink 提供的算法和数据结构支持通过同一个编程接口进行有界限处理和无界限处理。处理无界限数据的应用程序会持续运行。处理有界限数据的应用程序将在到达输入数据集的末尾时结束其执行。
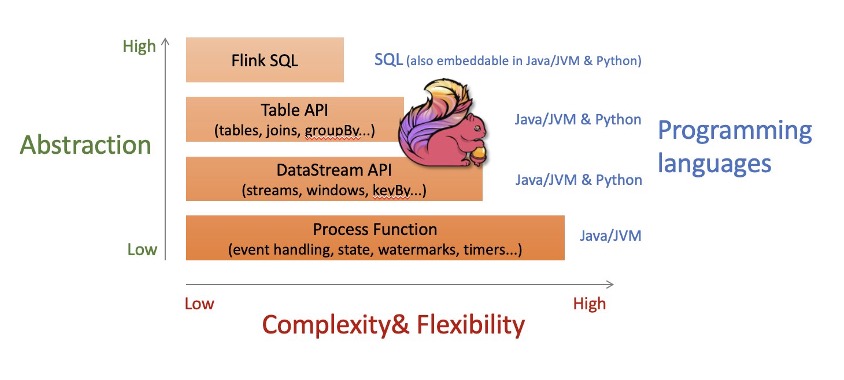
多级别的抽象
Apache Flink 为编程接口提供多级别的抽象。在较高级别的流式传输 SQL 和 Table API 中,使用熟悉的抽象,例如表、联接和分组。DataStream API 提供较低级别的抽象,但同时赋予更多的控制,包括流、窗口化和映射的语义。最后,ProcessFunction API 提供对每条消息处理的精细控制和状态的直接控制。所有编程接口均可与无界限(流)和有界限(表)日期集无缝协作。可以在同一个应用程序中使用不同级别的抽象,将其作为解决每个问题的正确工具。
flink SQL开发
INSERT INTO test_sink(
字段1类型a,
字段2类型b
)
SELECT
消息队列中的1条消息解析后相应字段1的值x--类型转换为a,
消息队列中的1条消息解析后相应字段1的值y--类型转换为b,
FROM 消息队列;
test_sink和数据库mysql中的相应表test_table对应
执行模式(流/批) #
DataStream API 支持不同的运行时执行模式,你可以根据你的用例需要和作业特点进行选择。
DataStream API 有一种”经典“的执行行为,我们称之为流(STREAMING)执行模式。这种模式适用于需要连续增量处理,而且预计无限期保持在线的无边界作业。
此外,还有一种批式执行模式,我们称之为批(BATCH)执行模式。这种执行作业的方式更容易让人联想到批处理框架,比如 MapReduce。这种执行模式适用于有一个已知的固定输入,而且不会连续运行的有边界作业。
Apache Flink 对流处理和批处理统一方法,意味着无论配置何种执行模式,在有界输入上执行的 DataStream 应用都会产生相同的最终 结果。重要的是要注意最终 在这里是什么意思:一个在流模式执行的作业可能会产生增量更新(想想数据库中的插入(upsert)操作),而批作业只在最后产生一个最终结果。尽管计算方法不同,只要呈现方式得当,最终结果会是相同的。
通过启用批执行,我们允许 Flink 应用只有在我们知道输入是有边界的时侯才会使用到的额外的优化。例如,可以使用不同的关联(join)/ 聚合(aggregation)策略,允许实现更高效的任务调度和故障恢复行为的不同 shuffle。下面我们将介绍一些执行行为的细节。
什么时候可以/应该使用批执行模式? #
批执行模式只能用于 有边界 的作业/Flink 程序。边界是数据源的一个属性,告诉我们在执行前,来自该数据源的所有输入是否都是已知的,或者是否会有新的数据出现,可能是无限的。而对一个作业来说,如果它的所有源都是有边界的,则它就是有边界的,否则就是无边界的。
而流执行模式,既可用于有边界任务,也可用于无边界任务。
一般来说,在你的程序是有边界的时候,你应该使用批执行模式,因为这样做会更高效。当你的程序是无边界的时候,你必须使用流执行模式,因为只有这种模式足够通用,能够处理连续的数据流。
一个明显的例外是当你想使用一个有边界作业去自展一些作业状态,并将状态使用在之后的无边界作业的时候。例如,通过流模式运行一个有边界作业,取一个 savepoint,然后在一个无边界作业上恢复这个 savepoint。这是一个非常特殊的用例,当我们允许将 savepoint 作为批执行作业的附加输出时,这个用例可能很快就会过时。
另一个你可能会使用流模式运行有边界作业的情况是当你为最终会在无边界数据源写测试代码的时候。对于测试来说,在这些情况下使用有边界数据源可能更自然。
配置批执行模式 #
执行模式可以通过 execute.runtime-mode 设置来配置。有三种可选的值:
STREAMING: 经典 DataStream 执行模式(默认)BATCH: 在 DataStream API 上进行批量式执行AUTOMATIC: 让系统根据数据源的边界性来决定
这可以通过 bin/flink run ... 的命令行参数进行配置,或者在创建/配置 StreamExecutionEnvironment 时写进程序。
下面是如何通过命令行配置执行模式:
$ bin/flink run -Dexecution.runtime-mode=BATCH <jarFile>
这个例子展示了如何在代码中配置执行模式:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
我们不建议用户在程序中设置运行模式,而是在提交应用程序时使用命令行进行设置。保持应用程序代码的免配置可以让程序更加灵活,因为同一个应用程序可能在任何执行模式下执行。
执行行为 #
本节概述了批执行模式的执行行为,并与流执行模式进行了对比。详细内容请参考介绍该功能的 FLIP-134 和 FLIP-140.
任务调度与网络 Shuffle #
Flink 作业由不同的操作组成,这些操作在数据流图中连接在一起。系统决定如何在不同的进程/机器(TaskManager)上调度这些操作的执行,以及如何在它们之间 shuffle (发送)数据。
将多个操作/算子链接在一起的功能称为链。Flink 称一个调度单位的一组或多个(链接在一起的)算子为一个 任务。通常,子任务 用来指代在多个 TaskManager 上并行运行的单个任务实例,但我们在这里只使用 任务(task)一词。
任务调度和网络 shuffle 对于批和流执行模式的执行方式不同。这主要是由于在批执行模式中,当知道输入数据是有边界的时候,Flink可以使用更高效的数据结构和算法。
我们将用这个例子来解释任务调度和网络传输的差异。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = env.fromElements(...);
source.name("source")
.map(...).name("map1")
.map(...).name("map2")
.rebalance()
.map(...).name("map3")
.map(...).name("map4")
.keyBy((value) -> value)
.map(...).name("map5")
.map(...).name("map6")
.sinkTo(...).name("sink");
包含 1-to-1 连接模式的操作,比如 map()、 flatMap() 或 filter(),可以直接将数据转发到下一个操作,这使得这些操作可以被链接在一起。这意味着 Flink 一般不会在他们之间插入网络 shuffle。
而像 keyBy() 或者 rebalance() 这样需要在不同的任务并行实例之间进行数据 shuffle 的操作,就会引起网络 shuffle。
对于上面的例子,Flink 会将操作分组为这些任务:
- 任务1:
source、map1和map2 - 任务2:
map3和map4 - 任务3:
map5、map6和sink
我们在任务1到任务2、任务2到任务3之间各有一次网络 shuffle。这是该作业的可视化表示:

流执行模式 #
在流执行模式下,所有任务需要一直在线/运行。这使得 Flink可以通过整个管道立即处理新的记录,以达到我们需要的连续和低延迟的流处理。这同样意味着分配给某个作业的 TaskManagers 需要有足够的资源来同时运行所有的任务。
网络 shuffle 是 流水线 式的,这意味着记录会立即发送给下游任务,在网络层上进行一些缓冲。同样,这也是必须的,因为当处理连续的数据流时,在任务(或任务管道)之间没有可以实体化的自然数据点(时间点)。这与批执行模式形成了鲜明的对比,在批执行模式下,中间的结果可以被实体化,如下所述。
批执行模式 #
在批执行模式下,一个作业的任务可以被分离成可以一个接一个执行的阶段。我们之所以能做到这一点,是因为输入是有边界的,因此 Flink 可以在进入下一个阶段之前完全处理管道中的一个阶段。在上面的例子中,工作会有三个阶段,对应着被 shuffle 界线分开的三个任务。
不同于上文所介绍的流模式立即向下游任务发送记录,分阶段处理要求 Flink 将任务的中间结果实体化到一些非永久存储中,让下游任务在上游任务已经下线后再读取。这将增加处理的延迟,但也会带来其他有趣的特性。其一,这允许 Flink 在故障发生时回溯到最新的可用结果,而不是重新启动整个任务。其二,批作业可以在更少的资源上执行(就 TaskManagers 的可用槽而言),因为系统可以一个接一个地顺序执行任务。
TaskManagers 将至少在下游任务开始消费它们前保留中间结果(从技术上讲,它们将被保留到消费的流水线区域产生它们的输出为止)。在这之后,只要空间允许,它们就会被保留,以便在失败的情况下,可以回溯到前面涉及的结果。
State Backends / State #
在流模式下,Flink 使用 StateBackend 来控制状态的存储方式和检查点的工作方式。
在批模式下,配置的 state backend 被忽略。取而代之的是,keyed 操作的输入按键分组(使用排序),然后我们依次处理一个键的所有记录。这样就可以在同一时间只保留一个键的状态。当进行到下一个键时,一个给定键的状态将被丢弃。
关于这方面的背景信息,请参见 FLIP-140。
处理顺序 #
在批执行和流执行中,算子或用户自定义函数(UDFs)处理记录的顺序可能不同。
在流模式下,用户自定义函数不应该对传入记录的顺序做任何假设。数据一到达就被处理。
在批执行模式下,Flink 通过一些操作确保顺序。排序可以是特定调度任务、网络 shuffle、上文提到的 state backend 或是系统有意识选择的副作用。
我们可以将常见输入类型分为三类:
- 广播输入(broadcast input): 从广播流输入(参见 广播状态(Broadcast State))
- 常规输入(regular input): 从广播或 keyed 输入
- keyed 输入(keyed input): 从
KeyedStream输入
消费多种类型输入的函数或是算子可以使用以下顺序处理:
- 广播输入第一个处理
- 常规输入第二个处理
- keyed 输入最后处理
对于从多个常规或广播输入进行消费的函数 — 比如 CoProcessFunction — Flink 有权从任一输入以任意顺序处理数据。
对于从多个keyed输入进行消费的函数 — 比如 KeyedCoProcessFunction — Flink 先处理单一键中的所有记录再处理下一个。
事件时间/水印 #
在支持事件时间方面,Flink 的流运行时间建立在一个事件可能是乱序到来的悲观假设上的,即一个时间戳 t 的事件可能会在一个时间戳 t+1 的事件之后出现。因为如此,系统永远无法确定在给定的时间戳 T 下,未来不会再有时间戳 t < T 的元素出现。为了摊平这种失序性对最终结果的影响,同时使系统实用,在流模式下,Flink 使用了一种名为 Watermarks 的启发式方法。一个带有时间戳 T 的水印标志着再没有时间戳 t < T 的元素跟进。
在批模式下,输入的数据集是事先已知的,不需要这样的启发式方法,因为至少可以按照时间戳对元素进行排序,从而按照时间顺序进行处理。对于熟悉流的读者来说,在批中,我们可以假设”完美的 Watermark“。
综上所述,在批模式下,我们只需要在输入的末尾有一个与每个键相关的 MAX_WATERMARK,如果输入流没有键,则在输入的末尾需要一个 MAX_WATERMARK。基于这个方案,所有注册的定时器都会在时间结束时触发,用户定义的 WatermarkAssigners 或 WatermarkStrategies 会被忽略。但细化一个 WatermarkStrategy 仍然是重要的,因为它的 TimestampAssigner 仍然会被用来给记录分配时间戳。
处理时间 #
处理时间是指在处理记录的具体实例上,处理记录的机器上的挂钟时间。根据这个定义,我们知道基于处理时间的计算结果是不可重复的。因为同一条记录被处理两次,会有两个不同的时间戳。
尽管如此,在流模式下处理时间还是很有用的。原因在于因为流式管道从 真实时间 摄取无边界输入,所以事件时间和处理时间之间存在相关性。此外,由于上述原因,在流模式下事件时间的1小时也往往可以几乎是处理时间,或者叫挂钟时间的1小时。所以使用处理时间可以用于早期(不完全)触发,给出预期结果的提示。
在批处理世界中,这种相关性并不存在,因为在批处理世界中,输入的数据集是静态的,是预先知道的。鉴于此,在批模式中,我们允许用户请求当前的处理时间,并注册处理时间计时器,但与事件时间的情况一样,所有的计时器都要在输入结束时触发。
在概念上,我们可以想象,在作业执行过程中,处理时间不会提前,当整个输入处理完毕后,我们会快进到时间结束。
故障恢复 #
在流执行模式下,Flink 使用 checkpoints 进行故障恢复。请参看 checkpointing 文档,了解关于如何实践和配置它。关于通过状态快照进行容错,也有一个比较入门的章节,从更高的层面解释了这些概念。
Checkpointing 用于故障恢复的特点之一是,在发生故障时,Flink 会从 checkpoint 重新启动所有正在运行的任务。这可能比我们在批模式下所要做的事情代价更高(如下文所解释),这也是如果你的任务允许的话应该使用批执行模式的原因之一。
在批执行模式下,Flink 会尝试并回溯到之前的中间结果仍可获取的处理阶段。只有失败的任务(或它们在图中的前辈)才可能需要重新启动。这与从 checkpoint 重新启动所有任务相比,可以提高作业的处理效率和整体处理时间。
重要的考虑因素 #
与经典的流执行模式相比,在批模式下,有些东西可能无法按照预期工作。一些功能的工作方式会略有不同,而其他功能会不支持。
批模式下的行为变化:
- “滚动"操作,如 reduce() 或 sum(),会对
流模式下每一条新记录发出增量更新。在批模式下,这些操作不是"滚动”。它们只发出最终结果。
批模式下不支持的:
- Checkpointing 和任何依赖于 checkpointing 的操作都不支持。
- 迭代(Iterations)
自定义算子应谨慎执行,否则可能会有不恰当的行为。更多细节请参见下面的补充说明。
Checkpointing #
如上文所述,批处理程序的故障恢复不使用检查点。
重要的是要记住,因为没有 checkpoints,某些功能如 ( CheckpointListener ),以及因此,Kafka 的 精确一次(EXACTLY_ONCE) 模式或 File Sink 的 OnCheckpointRollingPolicy 将无法工作。 如果你需要一个在批模式下工作的事务型 sink,请确保它使用 FLIP-143 中提出的统一 Sink API。
你仍然可以使用所有的 状态原语(state primitives),只是用于故障恢复的机制会有所不同。
编写自定义算子 #
注意: 自定义算子是 Apache Flink 的一种高级使用模式。对于大多数的使用情况,可以考虑使用(keyed-)处理函数来代替。
在编写自定义算子时,记住批执行模式的假设是很重要的。否则,一个在流模式下运行良好的操作符可能会在批模式下产生错误的结果。算子永远不会被限定在一个特定的键上,这意味着他们看到了 Flink 试图利用的批处理的一些属性。
首先你不应该在一个算子内缓存最后看到的 Watermark。在批模式下,我们会逐个键处理记录。因此,Watermark 会在每个键之间从 MAX_VALUE 切换到 MIN_VALUE。你不应该认为 Watermark 在一个算子中总是递增的。出于同样的原因,定时器将首先按键的顺序触发,然后按每个键内的时间戳顺序触发。此外,不支持手动更改键的操作。
Flink’s Table API & SQL programs can be connected to other external systems for reading and writing both batch and streaming tables. A table source provides access to data which is stored in external systems (such as a database, key-value store, message queue, or file system). A table sink emits a table to an external storage system. Depending on the type of source and sink, they support different formats such as CSV, Avro, Parquet, or ORC.
This page describes how to register table sources and table sinks in Flink using the natively supported connectors. After a source or sink has been registered, it can be accessed by Table API & SQL statements.
If you want to implement your own custom table source or sink, have a look at the user-defined sources & sinks page.
-- 原始,未处理源表
create table tab(
data_version STRING COMMENT '数据格式版本',
latitude STRING COMMENT 'GPS信息-纬度',
longitude STRING COMMENT 'GPS信息-经度',
proctime as PROCTIME()
) with (
'connector'='mq',
'instanceID'='1',
'topic'='1',
'endpoint'='http://1.mq-internal.aliyuncs.com:8080',
'accessId'='1',
'accessKey'='1',
'pullIntervalMs'='100',
'consumerGroup'='GID_1',
'fieldDelimiter' = '#'
);
drop table tab
mqtt其中设备投入的消息为 a#b#c#

 浙公网安备 33010602011771号
浙公网安备 33010602011771号