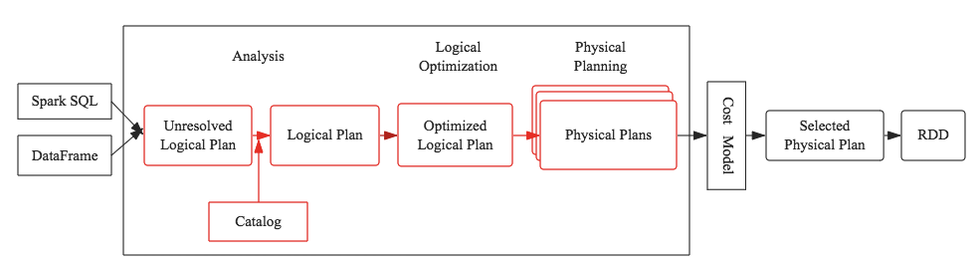
Optimizer in SQL - Catalyst Optimizer in Spark SQL

SELECT sum(v)
FROM (
SELECT score.id, 100+80+score.math_score+ score.english_score AS v
FROM people JOIN score
WHERE people.id = score.id
AND people.age > 10
) tmp
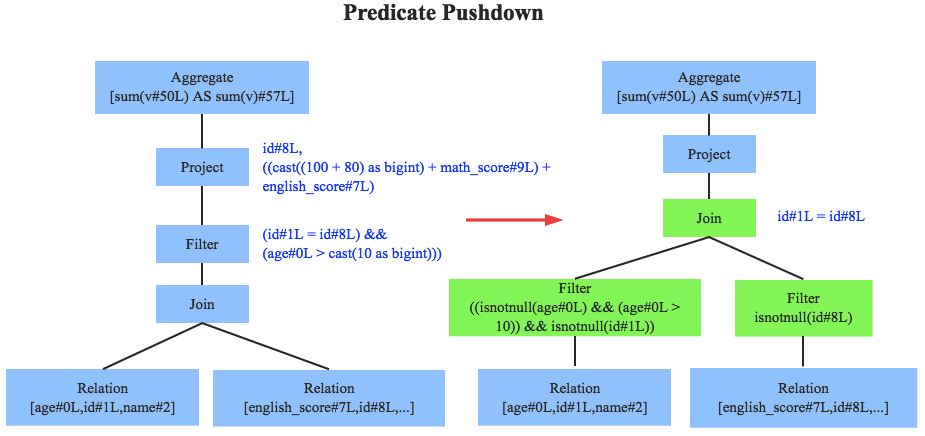
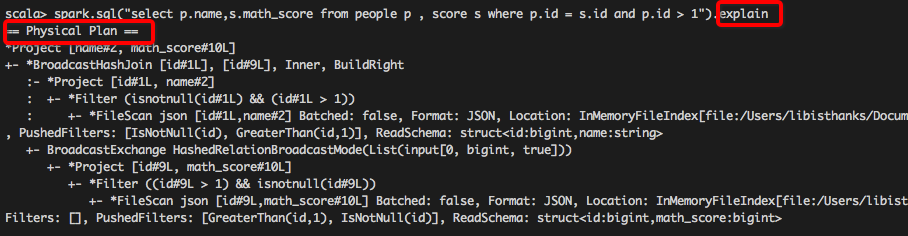
谓词下推(Predicate Pushdown)
【join前对待join的表通过列值条件进行行过滤,减少之后join时表行数】
系统在扫描数据的时候就对数据进行了过滤,参与join的数据量将会得到显著的减少,join耗时必然也会降低
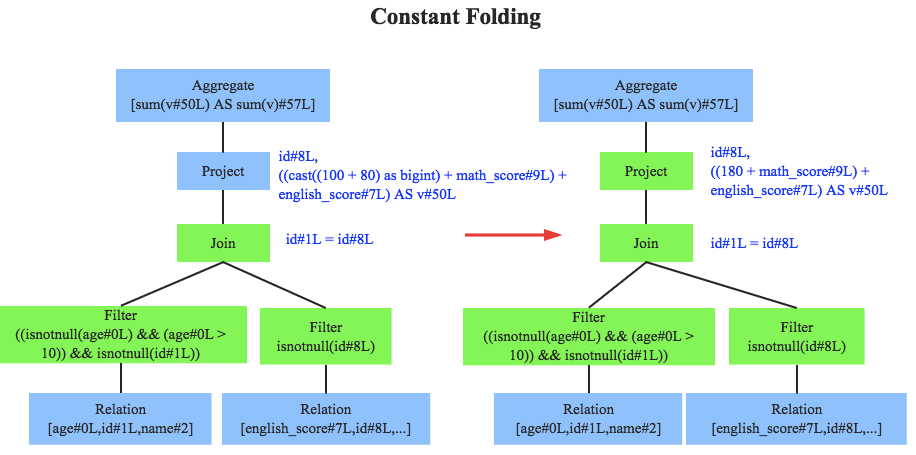
常量累加(Constant Folding)
【计算一次,再参与后续计算】
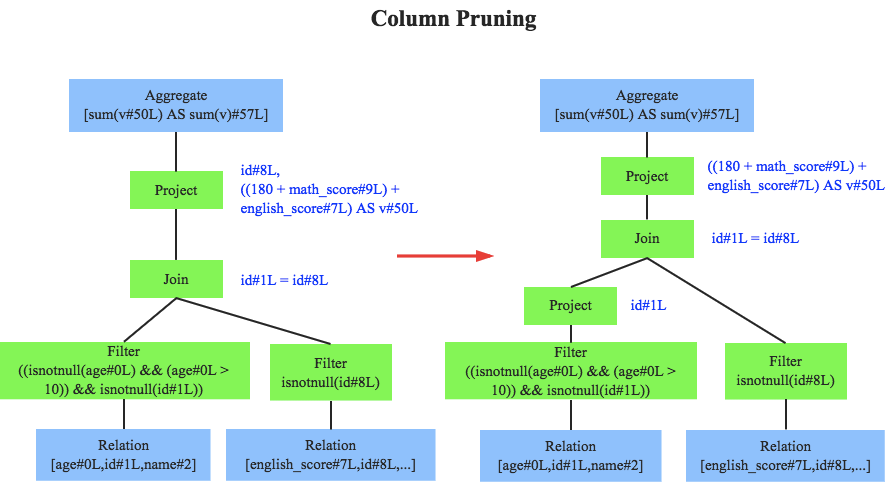
列值裁剪(Column Pruning)
【阶段有用的列,使用后,不再参与后续计算,及时抛弃】
people.age age Column 列对于之后的计算没有贡献,参与后续计算的仅有people.id id Column 列
http://www.waitingforcode.com/apache-spark-sql/catalyst-optimizer-in-spark-sql/read
http://blog.csdn.net/lw_ghy/article/details/60778157
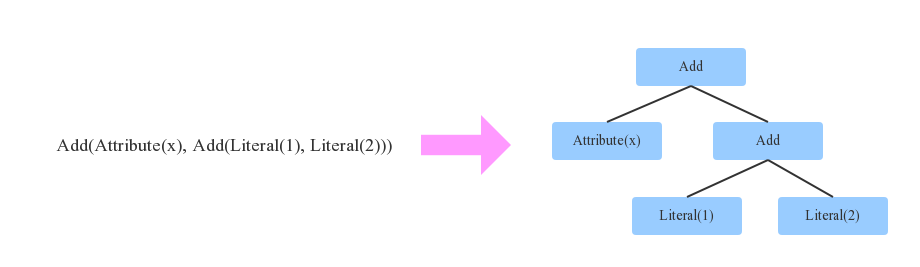
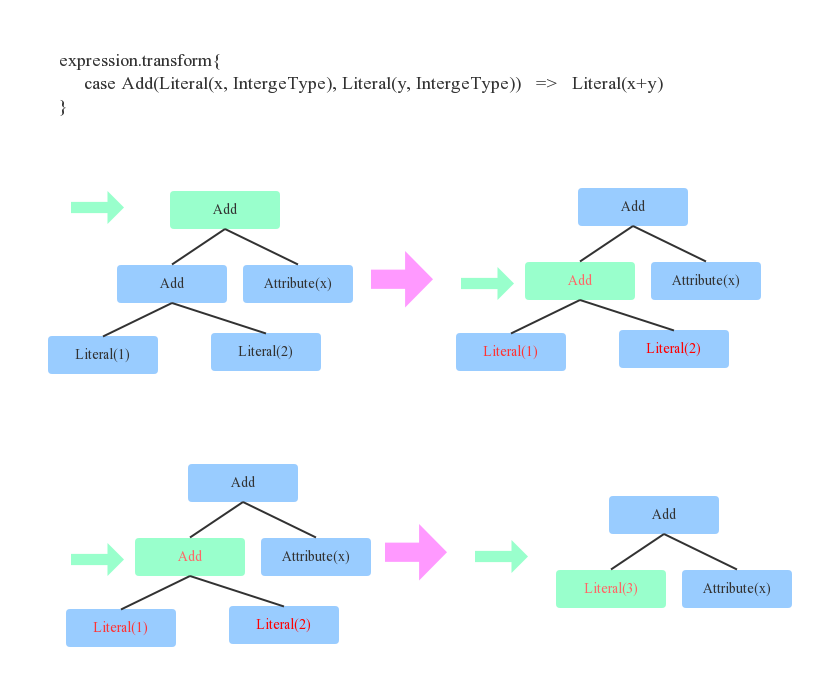
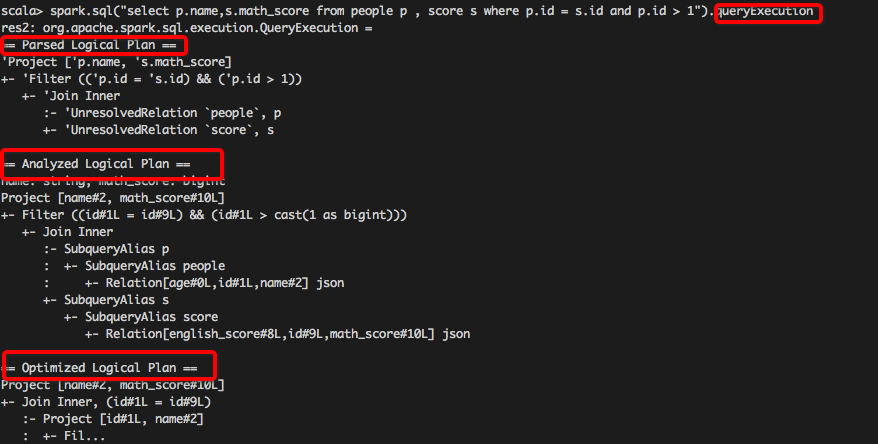
【生成引用ID】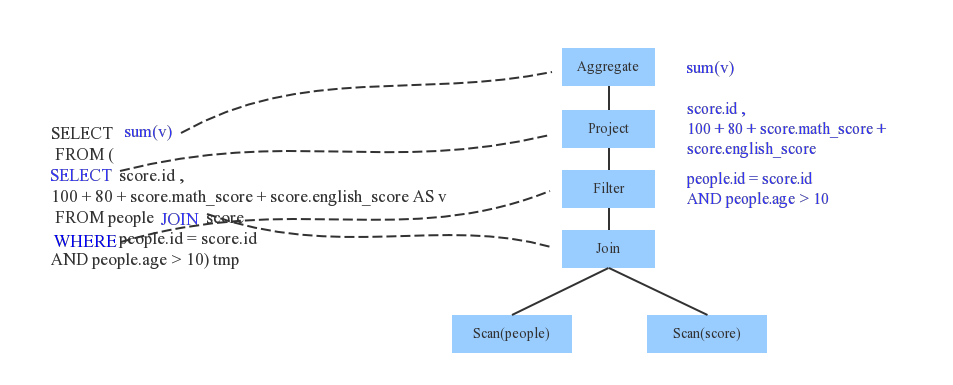
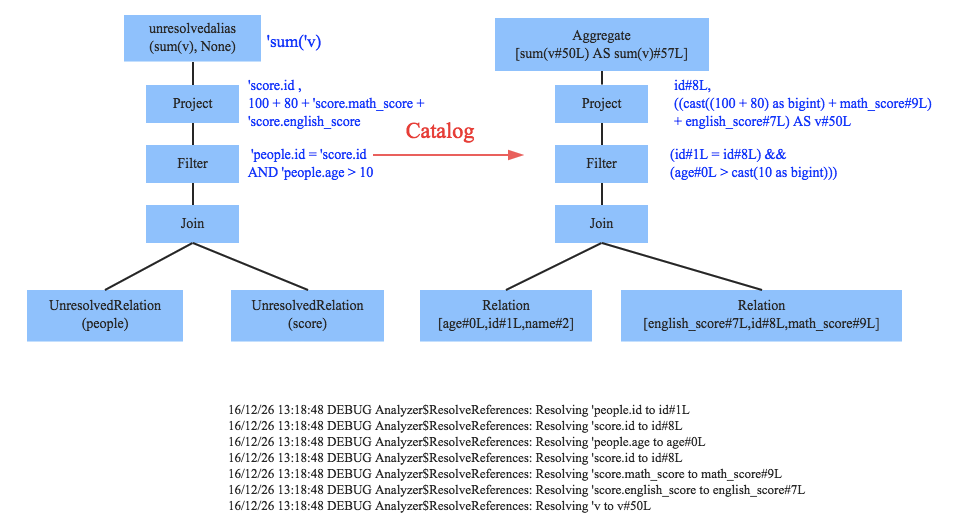
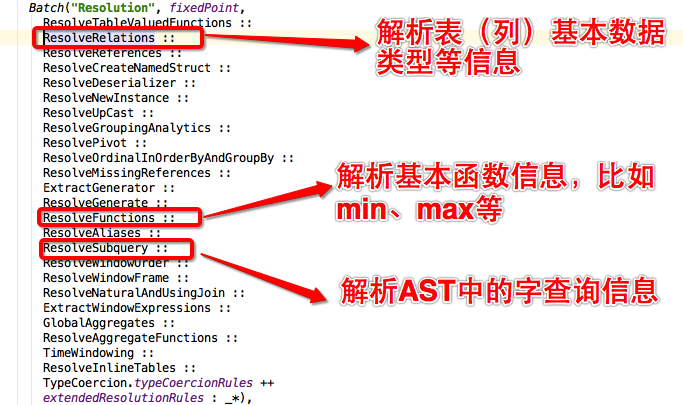
【先单表扫描过滤,之后表连接】




 浙公网安备 33010602011771号
浙公网安备 33010602011771号