栈 堆 stack heap 堆内存 栈内存 内存分配中的堆和栈 掌握堆内存的权柄就是返回的指针 栈是面向线程的而堆是面向进程的。 new/delete and malloc/ free 指针与内存模型
小结:
1、栈内存 为什么快?
- Due to this nature, the process of storing and retrieving data from the stack is very fast as there is no lookup required, you just store and retrieve data from the topmost block on it.
堆内存 慢于栈内存 ,但存储空间动态,使用指针访问
Heap is used for dynamic memory allocation and unlike stack, the program needs to look up the data in heap using pointers (Think of it as a big multi-level library).
- It is slower than stack as the process of looking up data is more involved but it can store more data than the stack.
- This means data with dynamic size can be stored here.
2、每个线程有一个栈
- Multi-threaded applications can have a stack per thread.
3、讨论内存管理指的是堆内存的管理
4、染色标记
Mark & Sweep GC: Also known as Tracing GC. Its generally a two-phase algorithm that first marks objects that are still being referenced as “alive” and in the next phase frees the memory of objects that are not alive.
第一阶段仍被引用,标记为alive,第二阶段释放标记为“not alive”的内存
5、为什么我们需要指针?直接用变量名不行吗?
5.2
既然指针的本质都是变量的内存首地址,即一个 int 类型的整数。
那为什么还要有各种类型呢?
———5———》
https://mp.weixin.qq.com/s/d1ng1-AFFdPGLWDXVKPJZg
为什么指针被誉为 C 语言灵魂?
是的,这一篇的文章主题是「指针与内存模型」
说到指针,就不可能脱离开内存,学会指针的人分为两种,一种是不了解内存模型,另外一种则是了解。
不了解的对指针的理解就停留在“指针就是变量的地址”这句话,会比较害怕使用指针,特别是各种高级操作。
而了解内存模型的则可以把指针用得炉火纯青,各种 byte 随意操作,让人直呼 666。
这篇看完,相信你会对指针有一个新的认识,坐等打脸😂
一、内存本质
编程的本质其实就是操控数据,数据存放在内存中。
因此,如果能更好地理解内存的模型,以及 C 如何管理内存,就能对程序的工作原理洞若观火,从而使编程能力更上一层楼。
大家真的别认为这是空话,我大一整年都不敢用 C 写上千行的程序也很抗拒写 C。
因为一旦上千行,经常出现各种莫名其妙的内存错误,一不小心就发生了 coredump...... 而且还无从排查,分析不出原因。
相比之下,那时候最喜欢 Java,在 Java 里随便怎么写都不会发生类似的异常,顶多偶尔来个 NullPointerException,也是比较好排查的。
直到后来对内存和指针有了更加深刻的认识,才慢慢会用 C 写上千行的项目,也很少会再有内存问题了。(过于自信
「指针存储的是变量的内存地址」这句话应该任何讲 C 语言的书都会提到吧。
所以,要想彻底理解指针,首先要理解 C 语言中变量的存储本质,也就是内存。
1.1 内存编址
计算机的内存是一块用于存储数据的空间,由一系列连续的存储单元组成,就像下面这样,
每一个单元格都表示 1 个 Bit,一个 bit 在 EE 专业的同学看来就是高低电位,而在 CS 同学看来就是 0、1 两种状态。
由于 1 个 bit 只能表示两个状态,所以大佬们规定 8个 bit 为一组,命名为 byte。
并且将 byte 作为内存寻址的最小单元,也就是给每个 byte 一个编号,这个编号就叫内存的地址。
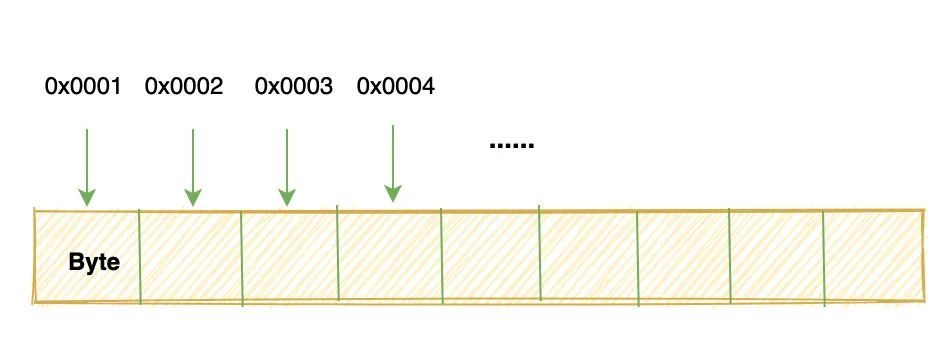
这就相当于,我们给小区里的每个单元、每个住户都分配一个门牌号: 301、302、403、404、501......
在生活中,我们需要保证门牌号唯一,这样就能通过门牌号很精准的定位到一家人。
同样,在计算机中,我们也要保证给每一个 byte 的编号都是唯一的,这样才能够保证每个编号都能访问到唯一确定的 byte。
1.2 内存地址空间
上面我们说给内存中每个 byte 唯一的编号,那么这个编号的范围就决定了计算机可寻址内存的范围。
所有编号连起来就叫做内存的地址空间,这和大家平时常说的电脑是 32 位还是 64 位有关。
早期 Intel 8086、8088 的 CPU 就是只支持 16 位地址空间,寄存器和地址总线都是 16 位,这意味着最多对 2^16 = 64 Kb 的内存编号寻址。
这点内存空间显然不够用,后来,80286 在 8086 的基础上将地址总线和地址寄存器扩展到了20 位,也被叫做 A20 地址总线。
当时在写 mini os 的时候,还需要通过 BIOS 中断去启动 A20 地址总线的开关。
但是,现在的计算机一般都是 32 位起步了,32 位意味着可寻址的内存范围是 2^32 byte = 4GB。
所以,如果你的电脑是 32 位的,那么你装超过 4G 的内存条也是无法充分利用起来的。
好了,这就是内存和内存编址。
1.3 变量的本质
有了内存,接下来我们需要考虑,int、double 这些变量是如何存储在 0、1 单元格的。
在 C 语言中我们会这样定义变量:
int a = 999;
char c = 'c';
当你写下一个变量定义的时候,实际上是向内存申请了一块空间来存放你的变量。
我们都知道 int 类型占 4 个字节,并且在计算机中数字都是用补码(不了解补码的记得去百度)表示的。
999 换算成补码就是:0000 0011 1110 0111
这里有 4 个byte,所以需要四个单元格来存储:
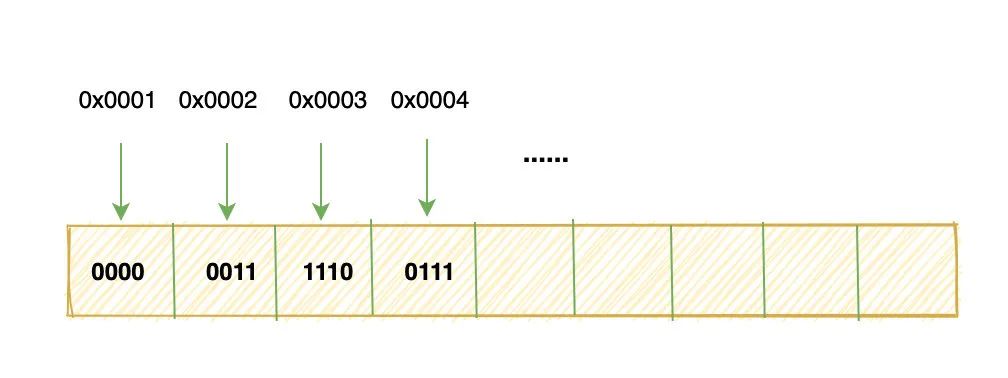
有没有注意到,我们把高位的字节放在了低地址的地方。
那能不能反过来呢?
当然,这就引出了大端和小端。
像上面这种将高位字节放在内存低地址的方式叫做大端
反之,将低位字节放在内存低地址的方式就叫做小端:
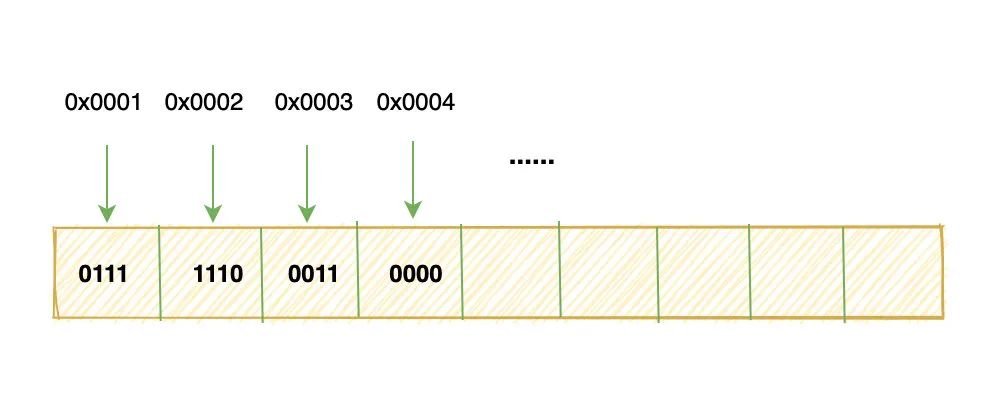
上面只说明了 int 型的变量如何存储在内存,而 float、char 等类型实际上也是一样的,都需要先转换为补码。
对于多字节的变量类型,还需要按照大端或者小端的格式,依次将字节写入到内存单元。
记住上面这两张图,这就是编程语言中所有变量的在内存中的样子,不管是 int、char、指针、数组、结构体、对象... 都是这样放在内存的。
二、指针是什么东西?
2.1 变量放在哪?
上面我说,定义一个变量实际就是向计算机申请了一块内存来存放。
那如果我们要想知道变量到底放在哪了呢?
可以通过运算符&来取得变量实际的地址,这个值就是变量所占内存块的起始地址。
(PS: 实际上这个地址是虚拟地址,并不是真正物理内存上的地址
我们可以把这个地址打印出来:
printf("%x", &a);
大概会是像这样的一串数字:0x7ffcad3b8f3c
2.2 指针本质
上面说,我们可以通过&符号获取变量的内存地址,那获取之后如何来表示这是一个地址,而不是一个普通的值呢?
也就是在 C 语言中如何表示地址这个概念呢?
对,就是指针,你可以这样:
int *pa = &a;
pa 中存储的就是变量 a 的地址,也叫做指向 a 的指针。
在这里我想谈几个看起来有点无聊的话题:
为什么我们需要指针?直接用变量名不行吗?
当然可以,但是变量名是有局限的。
变量名的本质是什么?
是变量地址的符号化,变量是为了让我们编程时更加方便,对人友好,可计算机可不认识什么变量 a,它只知道地址和指令。
所以当你去查看 C 语言编译后的汇编代码,就会发现变量名消失了,取而代之的是一串串抽象的地址。
你可以认为,编译器会自动维护一个映射,将我们程序中的变量名转换为变量所对应的地址,然后再对这个地址去进行读写。
也就是有这样一个映射表存在,将变量名自动转化为地址:
a | 0x7ffcad3b8f3c
c | 0x7ffcad3b8f2c
h | 0x7ffcad3b8f4c
....
说的好!
可是我还是不知道指针存在的必要性,那么问题来了,看下面代码:
int func(...) {
...
};
int main() {
int a;
func(...);
};
假设我有一个需求:
要求在
func函数里要能够修改main函数里的变量a,这下咋整,在main函数里可以直接通过变量名去读写a所在内存。但是在
func函数里是看不见a的呀。
你说可以通过&取地址符号,将 a 的地址传递进去:
int func(int address) {
....
};
int main() {
int a;
func(&a);
};
这样在func 里就能获取到 a 的地址,进行读写了。
理论上这是完全没有问题的,但是问题在于:
编译器该如何区分一个 int 里你存的到底是 int 类型的值,还是另外一个变量的地址(即指针)。
这如果完全靠我们编程人员去人脑记忆了,会引入复杂性,并且无法通过编译器检测一些语法错误。
而通过int * 去定义一个指针变量,会非常明确:这就是另外一个 int 型变量的地址。
编译器也可以通过类型检查来排除一些编译错误。
这就是指针存在的必要性。
实际上任何语言都有这个需求,只不过很多语言为了安全性,给指针戴上了一层枷锁,将指针包装成了引用。
可能大家学习的时候都是自然而然的接受指针这个东西,但是还是希望这段啰嗦的解释对你有一定启发。
同时,在这里提点小问题:
既然指针的本质都是变量的内存首地址,即一个 int 类型的整数。
那为什么还要有各种类型呢?
比如 int 指针,float 指针,这个类型影响了指针本身存储的信息吗?
这个类型会在什么时候发挥作用?
2.3 解引用
上面的问题,就是为了引出指针解引用的。
pa中存储的是a变量的内存地址,那如何通过地址去获取a的值呢?
这个操作就叫做解引用,在 C 语言中通过运算符 *就可以拿到一个指针所指地址的内容了。
比如*pa就能获得a的值。
我们说指针存储的是变量内存的首地址,那编译器怎么知道该从首地址开始取多少个字节呢?
这就是指针类型发挥作用的时候,编译器会根据指针的所指元素的类型去判断应该取多少个字节。
如果是 int 型的指针,那么编译器就会产生提取四个字节的指令,char 则只提取一个字节,以此类推。
下面是指针内存示意图:
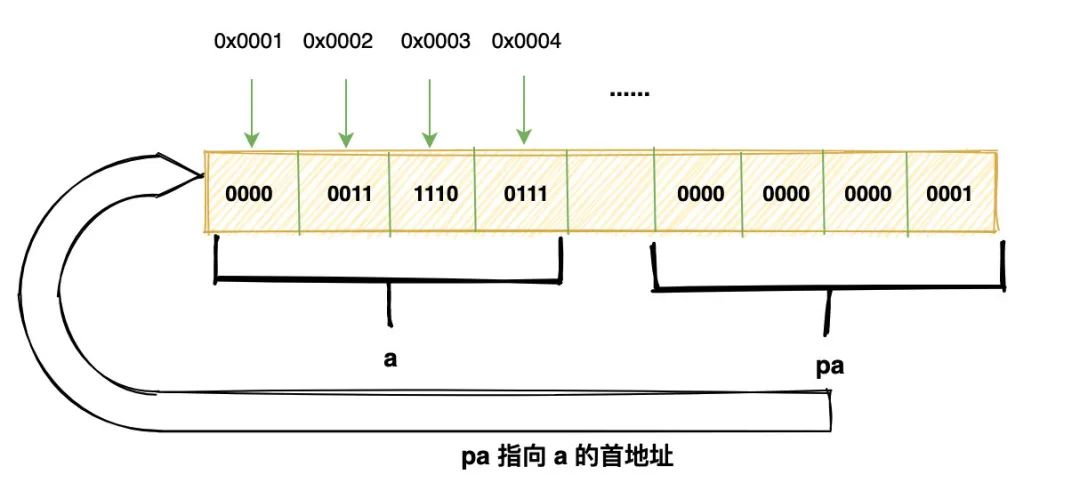
pa 指针首先是一个变量,它本身也占据一块内存,这块内存里存放的就是 a 变量的首地址。
当解引用的时候,就会从这个首地址连续划出 4 个 byte,然后按照 int 类型的编码方式解释。
2.4 活学活用
别看这个地方很简单,但却是深刻理解指针的关键。
举两个例子来详细说明:
比如:
float f = 1.0;
short c = *(short*)&f;
你能解释清楚上面过程,对于 f 变量,在内存层面发生了什么变化吗?
或者 c 的值是多少?1 ?
实际上,从内存层面来说,f 什么都没变。
如图:
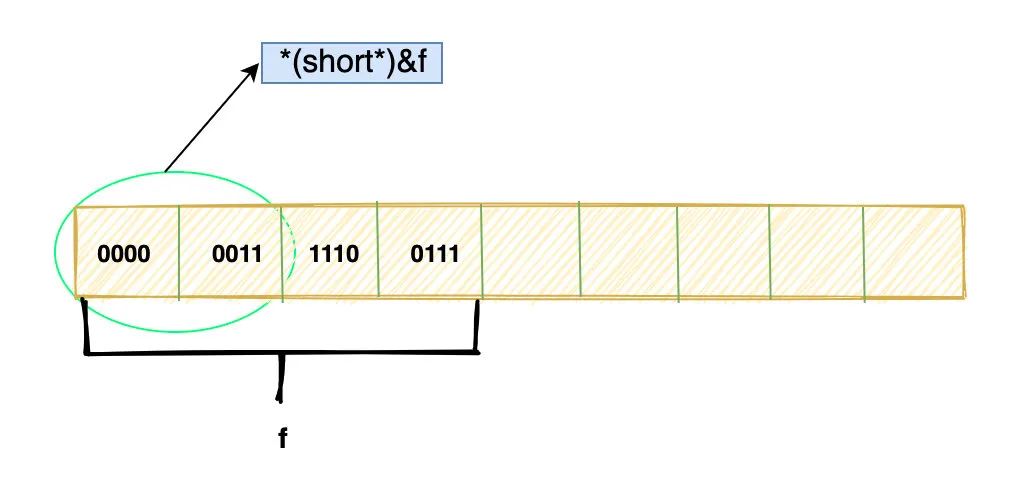
假设这是f 在内存中的位模式,这个过程实际上就是把 f 的前两个 byte 取出来然后按照 short 的方式解释,然后赋值给 c。
详细过程如下:
&f取得f的首地址(short*)&f
上面第二步什么都没做,这个表达式只是说 :
“噢,我认为f这个地址放的是一个 short 类型的变量”
最后当去解引用的时候*(short*)&f时,编译器会取出前面两个字节,并且按照 short 的编码方式去解释,并将解释出的值赋给 c 变量。
这个过程 f的位模式没有发生任何改变,变的只是解释这些位的方式。
当然,这里最后的值肯定不是 1,至于是什么,大家可以去真正算一下。
那反过来,这样呢?
short c = 1;
float f = *(float*)&c;
如图:
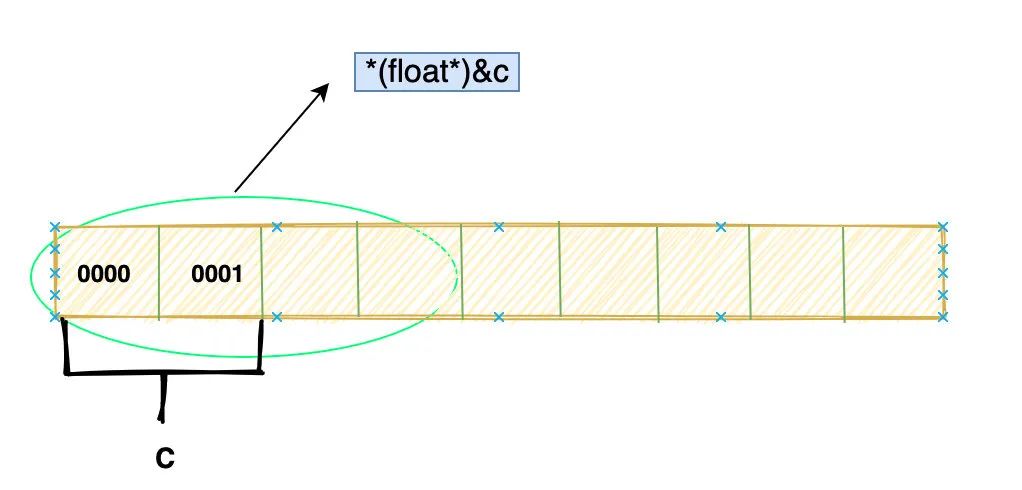
具体过程和上述一样,但上面肯定不会报错,这里却不一定。
为什么?
(float*)&c会让我们从c 的首地址开始取四个字节,然后按照 float 的编码方式去解释。
但是c是 short 类型只占两个字节,那肯定会访问到相邻后面两个字节,这时候就发生了内存访问越界。
当然,如果只是读,大概率是没问题的。
但是,有时候需要向这个区域写入新的值,比如:
*(float*)&c = 1.0;
那么就可能发生 coredump,也就是访存失败。
另外,就算是不会 coredump,这种也会破坏这块内存原有的值,因为很可能这是是其它变量的内存空间,而我们去覆盖了人家的内容,肯定会导致隐藏的 bug。
如果你理解了上面这些内容,那么使用指针一定会更加的自如。
2.6 看个小问题
讲到这里,我们来看一个问题,这是一位群友问的,这是他的需求:

这是他写的代码:
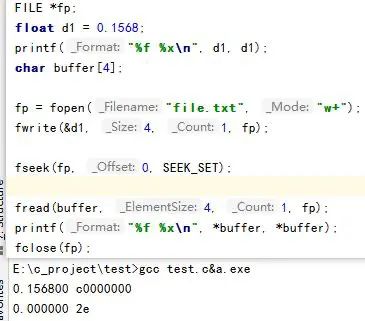
他把 double 写进文件再读出来,然后发现打印的值对不上。
而关键的地方就在于这里:
char buffer[4];
...
printf("%f %x\n", *buffer, *buffer);
他可能认为 buffer 是一个指针(准确说是数组),对指针解引用就该拿到里面的值,而里面的值他认为是从文件读出来的 4 个byte,也就是之前的 float 变量。
注意,这一切都是他认为的,实际上编译器会认为:
“哦,buffer 是 char类型的指针,那我取第一个字节出来就好了”。
然后把第一个字节的值传递给了 printf 函数,printf 函数会发现,%f 要求接收的是一个 float 浮点数,那就会自动把第一个字节的值转换为一个浮点数打印出来。
这就是整个过程。
错误关键就是,这个同学误认为,任何指针解引用都是拿到里面“我们认为的那个值”,实际上编译器并不知道,编译器只会傻傻的按照指针的类型去解释。
所以这里改成:
printf("%f %x\n", *(float*)buffer, *(float*)buffer);
相当于明确的告诉编译器:
“buffer指向的这个地方,我放的是一个 float,你给我按照 float 去解释”
三、 结构体和指针
结构体内包含多个成员,这些成员之间在内存中是如何存放的呢?
比如:
struct fraction {
int num; // 整数部分
int denom; // 小数部分
};
struct fraction fp;
fp.num = 10;
fp.denom = 2;
这是一个定点小数结构体,它在内存占 8 个字节(这里不考虑内存对齐),两个成员域是这样存储的:
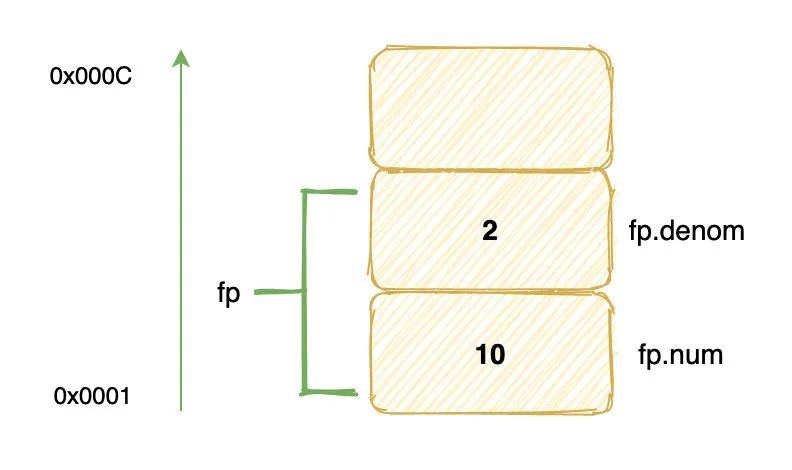 image-20201030214416842
image-20201030214416842
我们把 10 放在了结构体中基地址偏移为 0 的域,2 放在了偏移为 4 的域。
接下来我们做一个正常人永远不会做的操作:
((fraction*)(&fp.denom))->num = 5;
((fraction*)(&fp.denom))->denom = 12;
printf("%d\n", fp.denom); // 输出多少?
上面这个究竟会输出多少呢?自己先思考下噢~
接下来我分析下这个过程发生了什么:
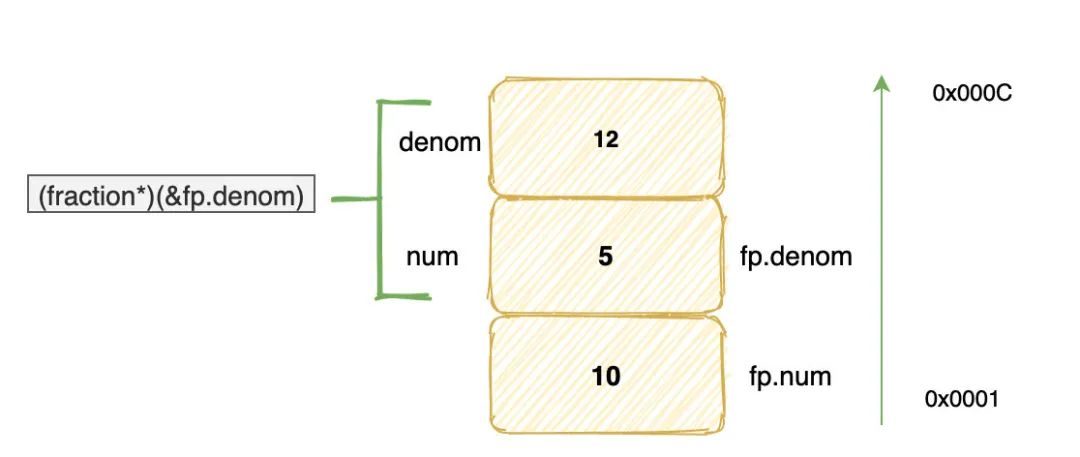
首先,&fp.denom表示取结构体 fp 中 denom 域的首地址,然后以这个地址为起始地址取 8 个字节,并且将它们看做一个 fraction 结构体。
在这个新结构体中,最上面四个字节变成了 denom 域,而 fp 的 denom 域相当于新结构体的 num 域。
因此:
((fraction*)(&fp.denom))->num = 5
实际上改变的是 fp.denom,而
((fraction*)(&fp.denom))->denom = 12
则是将最上面四个字节赋值为 12。
当然,往那四字节内存写入值,结果是无法预测的,可能会造成程序崩溃,因为也许那里恰好存储着函数调用栈帧的关键信息,也可能那里没有写入权限。
大家初学 C 语言的很多 coredump 错误都是类似原因造成的。
所以最后输出的是 5。
为什么要讲这种看起来莫名其妙的代码?
就是为了说明结构体的本质其实就是一堆的变量打包放在一起,而访问结构体中的域,就是通过结构体的起始地址,也叫基地址,然后加上域的偏移。
其实,C++、Java 中的对象也是这样存储的,无非是他们为了实现某些面向对象的特性,会在数据成员以外,添加一些 Head 信息,比如C++ 的虚函数表。
实际上,我们是完全可以用 C 语言去模仿的。
这就是为什么一直说 C 语言是基础,你真正懂了 C 指针和内存,对于其它语言你也会很快的理解其对象模型以及内存布局。
四、多级指针
说起多级指针这个东西,我以前大一,最多理解到 2 级,再多真的会把我绕晕,经常也会写错代码。
你要是给我写个这个:int ******p 能把我搞崩溃,我估计很多同学现在就是这种情况🤣
其实,多级指针也没那么复杂,就是指针的指针的指针的指针......非常简单。
今天就带大家认识一下多级指针的本质。
首先,我要说一句话,没有多级指针这种东西,指针就是指针,多级指针只是为了我们方便表达而取的逻辑概念。
首先看下生活中的快递柜:

这种大家都用过吧,丰巢或者超市储物柜都是这样,每个格子都有一个编号,我们只需要拿到编号,然后就能找到对应的格子,取出里面的东西。
这里的格子就是内存单元,编号就是地址,格子里放的东西就对应存储在内存中的内容。
假设我把一本书,放在了 03 号格子,然后把 03 这个编号告诉你,你就可以根据 03 去取到里面的书。
那如果我把书放在 05 号格子,然后在 03 号格子只放一个小纸条,上面写着:「书放在 05 号」。
你会怎么做?
当然是打开 03 号格子,然后取出了纸条,根据上面内容去打开 05 号格子得到书。
这里的 03 号格子就叫指针,因为它里面放的是指向其它格子的小纸条(地址)而不是具体的书。
明白了吗?
那我如果把书放在 07 号格子,然后在 05 号格子 放一个纸条:「书放在 07号」,同时在03号格子放一个纸条「书放在 05号」
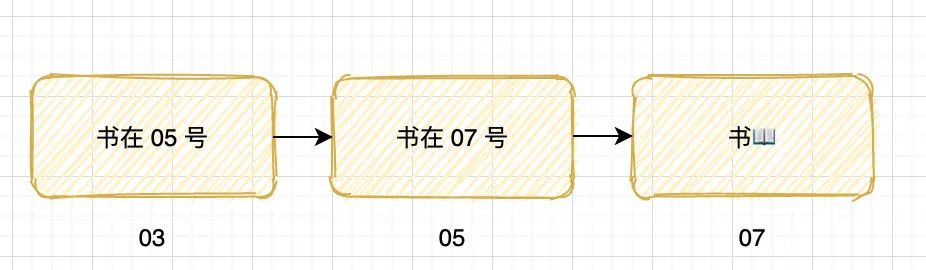
这里的 03 号格子就叫二级指针,05 号格子就叫指针,而 07 号就是我们平常用的变量。
依次,可类推出 N 级指针。
所以你明白了吗?同样的一块内存,如果存放的是别的变量的地址,那么就叫指针,存放的是实际内容,就叫变量。
int a;
int *pa = &a;
int **ppa = &pa;
int ***pppa = &ppa;
上面这段代码,pa就叫一级指针,也就是平时常说的指针,ppa 就是二级指针。
内存示意图如下:
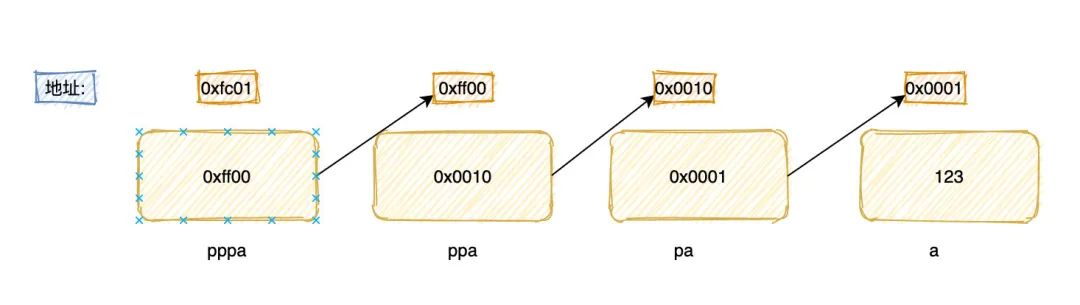
不管几级指针有两个最核心的东西:
- 指针本身也是一个变量,需要内存去存储,指针也有自己的地址
- 指针内存存储的是它所指向变量的地址
这就是我为什么多级指针是逻辑上的概念,实际上一块内存要么放实际内容,要么放其它变量地址,就这么简单。
怎么去解读int **a这种表达呢?
int ** a 可以把它分为两部分看,即int* 和 *a,后面 *a 中的*表示 a 是一个指针变量,前面的 int* 表示指针变量a
只能存放 int* 型变量的地址。
对于二级指针甚至多级指针,我们都可以把它拆成两部分。
首先不管是多少级的指针变量,它首先是一个指针变量,指针变量就是一个*,其余的*表示的是这个指针变量只能存放什么类型变量的地址。
比如int****a表示指针变量 a 只能存放int*** 型变量的地址。
五、指针与数组
5.1 一维数组
数组是 C 自带的基本数据结构,彻底理解数组及其用法是开发高效应用程序的基础。
数组和指针表示法紧密关联,在合适的上下文中可以互换。
如下:
int array[10] = {10, 9, 8, 7};
printf("%d\n", *array); // 输出 10
printf("%d\n", array[0]); // 输出 10
printf("%d\n", array[1]); // 输出 9
printf("%d\n", *(array+1)); // 输出 9
int *pa = array;
printf("%d\n", *pa); // 输出 10
printf("%d\n", pa[0]); // 输出 10
printf("%d\n", pa[1]); // 输出 9
printf("%d\n", *(pa+1)); // 输出 9
在内存中,数组是一块连续的内存空间:
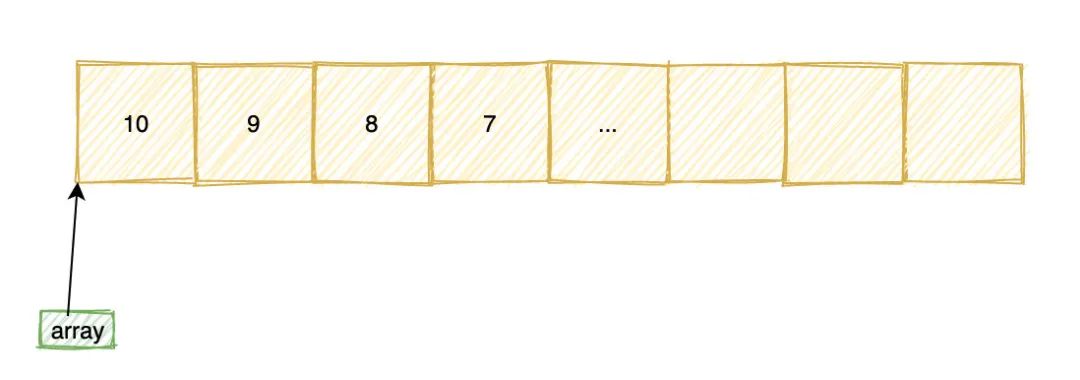
第 0 个元素的地址称为数组的首地址,数组名实际就是指向数组首地址,当我们通过array[1]或者*(array + 1) 去访问数组元素的时候。
实际上可以看做 address[offset],address 为起始地址,offset 为偏移量,但是注意这里的偏移量offset 不是直接和 address相加,而是要乘以数组类型所占字节数,也就是: address + sizeof(int) * offset。
学过汇编的同学,一定对这种方式不陌生,这是汇编中寻址方式的一种:基址变址寻址。
看完上面的代码,很多同学可能会认为指针和数组完全一致,可以互换,这是完全错误的。
尽管数组名字有时候可以当做指针来用,但数组的名字不是指针。
最典型的地方就是在 sizeof:
printf("%u", sizeof(array));
printf("%u", sizeof(pa));
第一个将会输出 40,因为 array包含有 10 个int类型的元素,而第二个在 32 位机器上将会输出 4,也就是指针的长度。
为什么会这样呢?
站在编译器的角度讲,变量名、数组名都是一种符号,它们都是有类型的,它们最终都要和数据绑定起来。
变量名用来指代一份数据,数组名用来指代一组数据(数据集合),它们都是有类型的,以便推断出所指代的数据的长度。
对,数组也有类型,我们可以将 int、float、char 等理解为基本类型,将数组理解为由基本类型派生得到的稍微复杂一些的类型,
数组的类型由元素的类型和数组的长度共同构成。而 sizeof 就是根据变量的类型来计算长度的,并且计算的过程是在编译期,而不会在程序运行时。
编译器在编译过程中会创建一张专门的表格用来保存变量名及其对应的数据类型、地址、作用域等信息。
sizeof 是一个操作符,不是函数,使用 sizeof 时可以从这张表格中查询到符号的长度。
所以,这里对数组名使用sizeof可以查询到数组实际的长度。
pa 仅仅是一个指向 int 类型的指针,编译器根本不知道它指向的是一个整数,还是一堆整数。
虽然在这里它指向的是一个数组,但数组也只是一块连续的内存,没有开始和结束标志,也没有额外的信息来记录数组到底多长。
所以对 pa 使用 sizeof 只能求得的是指针变量本身的长度。
也就是说,编译器并没有把 pa 和数组关联起来,pa 仅仅是一个指针变量,不管它指向哪里,sizeof求得的永远是它本身所占用的字节数。
5.2 二维数组
大家不要认为二维数组在内存中就是按行、列这样二维存储的,实际上,不管二维、三维数组... 都是编译器的语法糖。
存储上和一维数组没有本质区别,举个例子:
int array[3][3] = {{1, 2,3}, {4, 5,6},{7, 8, 9}};
array[1][1] = 5;
或许你以为在内存中 array 数组会像一个二维矩阵:
1 2 3
4 5 6
7 8 9
可实际上它是这样的:
1 2 3 4 5 6 7 8 9
和一维数组没有什么区别,都是一维线性排列。
当我们像 array[1][1]这样去访问的时候,编译器会怎么去计算我们真正所访问元素的地址呢?
为了更加通用化,假设数组定义是这样的:
int array[n][m]
访问: array[a][b]
那么被访问元素地址的计算方式就是: array + (m * a + b)
这个就是二维数组在内存中的本质,其实和一维数组是一样的,只是语法糖包装成一个二维的样子。
六、神奇的 void 指针
想必大家一定看到过 void 的这些用法:
void func();
int func1(void);
在这些情况下,void 表达的意思就是没有返回值或者参数为空。
但是对于 void 型指针却表示通用指针,可以用来存放任何数据类型的引用。
下面的例子就 是一个 void 指针:
void *ptr;
void 指针最大的用处就是在 C 语言中实现泛型编程,因为任何指针都可以被赋给 void 指针,void 指针也可以被转换回原来的指针类型, 并且这个过程指针实际所指向的地址并不会发生变化。
比如:
int num;
int *pi = #
printf("address of pi: %p\n", pi);
void* pv = pi;
pi = (int*) pv;
printf("address of pi: %p\n", pi);
这两次输出的值都会是一样:

平常可能很少会这样去转换,但是当你用 C 写大型软件或者写一些通用库的时候,一定离不开 void 指针,这是 C 泛型的基石,比如 std 库里的 sort 函数申明是这样的:
void qsort(void *base,int nelem,int width,int (*fcmp)(const void *,const void *));
所有关于具体元素类型的地方全部用 void 代替。
void 还可以用来实现 C 语言中的多态,这是一个挺好玩的东西。
不过也有需要注意的:
- 不能对 void 指针解引用
比如:
int num;
void *pv = (void*)#
*pv = 4; // 错误
为什么?
因为解引用的本质就是编译器根据指针所指的类型,然后从指针所指向的内存连续取 N 个字节,然后将这 N 个字节按照指针的类型去解释。
比如 int *型指针,那么这里 N 就是 4,然后按照 int 的编码方式去解释数字。
但是 void,编译器是不知道它到底指向的是 int、double、或者是一个结构体,所以编译器没法对 void 型指针解引用。
七、花式秀技
很多同学认为 C 就只能面向过程编程,实际上利用指针和结构体,我们一样可以在 C 中模拟出对象、继承、多态等东西。
也可以利用 void 指针实现泛型编程,也就是 Java、C++ 中的模板。
大家如果对 C 实现面向对象、模板、继承这些感兴趣的话,可以积极一点,点赞,留言~ 呼声高的话,我就再写一篇。
实际上也是很有趣的东西,当你知道了如何用 C 去实现这些东西,那你对 C++ 中的对象、Java 中的对象也会理解得更加透彻。
比如为啥有 this 指针,或者 Python 中的 self 究竟是个啥?
关于指针想写的内容还有很多,这其实也只算是开了个头,限于篇幅,以后有机会补齐以下内容:
- 二维数组和二维指针
- 数组指针和指针数组
- 指针运算
- 函数指针
- 动态内存分配: malloc 和 free
- 堆、栈
- 函数参数传递方式
- 内存泄露
- 数组退化成指针
- const 修饰指针
- ...
絮叨
我其实挺想写一个系列,大概就是关于内存、指针、引用、函数调用、堆栈、面向对象实现机制等等这样的底层一点的东西。
不知道大家有兴趣没有,有兴趣的话,那就给我点个赞或者在看,数量够多,我就会写下去。
《———5———
https://baike.baidu.com/item/堆内存
堆内存和栈内存
- 中文名
- 堆内存
- 外文名
- heap
- 区 别
- 于栈区
- 类 型
- 软件
- 获得堆内存
- malloc()
- 5 典型示例
堆内存和栈内存的区别可以用如下的比喻来看出:使用堆内存就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度大。使用栈内存就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但是自由度小。操作系统中所说的堆内存和栈内存,在操作上有上述的特点,这里的堆内存实际上指的就是(满足堆内存性质的)优先队列的一种数据结构,第1个元素有最高的优先权;栈内存实际上就是满足先进后出的性质的数学或数据结构。
动态分配堆内存
在标准C语言上,使用malloc等内存分配函数获取内存即是从堆中分配内存,而在一个函数体中例如定义一个数组之类的操作是从栈中分配内存。从堆中分配的内存需要程序员手动释放,如果不释放,而系统内存管理器又不自动回收这些堆内存的话(实现这一项功能的系统很少),那就一直被占用。如果一直申请堆内存,而不释放,内存会越来越少,很明显的结果是系统变慢或者申请不到新的堆内存。而过度的申请堆内存(可以试试在函数中申请一个1G的数组!),会导致堆被压爆,结果是灾难性的。
我们掌握堆内存的权柄就是返回的指针,一旦丢掉了指针,便无法在我们视野内释放它。这便是内存泄露。而如果在函数中申请一个数组,在函数体外调用使用这块堆内存,结果将无法预测。 我们知道在c/c++ 中定义的数组大小必需要事先定义好,他们通常是分配在静态内存空间或者是在栈内存空间内的,但是在实际工作中,我们有时候却需要动态的为数组分配大小,这时就要用到堆内存分配的概念。在堆内存分配时首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。堆内存是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆内存的大小受限于计算机系统中有效的虚拟内存。由此可见,堆内存获得的空间比较灵活,也比较大。堆内存是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.另外,在WINDOWS下,最好的方式是用VirtualAlloc分配内存,它直接在进程的地址空间中保留一快内存,虽然用起来最不方便。但是速度快,也最灵活。
内存方式
malloc函数
|
1
2
|
int *p;p = (int*)malloc(sizeof(int)); |
new运算符
|
1
2
3
4
|
int *p,*q;p = new int;//申请分配一个int型内存空间p = new int(10);//申请一个int型空间存放10q = new int[10];//申请分配10个int型的内存空间 |
}
https://baike.baidu.com/item/栈内存
栈内存在函数中定义的一些基本类型的变量和对象的引用变量都在函数的栈内存中分配。当在一段代码块定义一个变量时,Java就在栈中为这个变量分配内存空间,当超过变量的作用域后,Java会自动释放掉为该变量所分配的内存空间,该内存空间可以立即被另作他用。
堆和栈的理解和区别,C语言堆和栈完全攻略 http://c.biancheng.net/c/stack/
内存分配中的堆和栈
在 C 语言中,内存分配方式不外乎有如下三种形式:
- 从静态存储区域分配:它是由编译器自动分配和释放的,即内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在,直到整个程序运行结束时才被释放,如全局变量与 static 变量。
- 在栈上分配:它同样也是由编译器自动分配和释放的,即在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元将被自动释放。需要注意的是,栈内存分配运算内置于处理器的指令集中,它的运行效率一般很高,但是分配的内存容量有限。
- 从堆上分配:也被称为动态内存分配,它是由程序员手动完成申请和释放的。即程序在运行的时候由程序员使用内存分配函数(如 malloc 函数)来申请任意多少的内存,使用完之后再由程序员自己负责使用内存释放函数(如 free 函数)来释放内存。也就是说,动态内存的整个生存期是由程序员自己决定的,使用非常灵活。需要注意的是,如果在堆上分配了内存空间,就必须及时释放它,否则将会导致运行的程序出现内存泄漏等错误。
堆和栈的理解和区别,C语言堆和栈完全攻略 http://c.biancheng.net/c/stack/
Stack and Heap 堆和栈的区别 - Grandyang - 博客园 https://www.cnblogs.com/grandyang/p/4933011.html
在和计算机内存打交道时,我们一定会碰到堆和栈,这两个东西很容易搞混,那么现在就来梳理一下二者的关系。
栈是用来静态分配内存的而堆是动态分配内存的,它们都是存在于计算机内存之中。
栈的分配是在程序编译的时候完成的,直接存储在内存中,接触内存很快。栈是后进先出的顺序,最后被申请的块最先被释放,这样就很容易跟踪到栈,释放栈的过程简单到仅仅是移动下指针就能完成。
堆的分配是在程序运行时完成的,分配速度较为缓慢,但是堆的可用空间非常的大。堆中的元素相互之间没有关联,各自都可以被任何时候随机访问。我们可以任何时候申请和释放一块内存,这样会使得我们很难随时随地追踪到堆中某块位置被分配了还是被释放了。
当你知道在编译前需要分配多少数据时且数据量不是很大时可以使用栈。如果不知道在运行时需要多少数据那么就该使用堆。
在多线程的程序里,每个线程都有其自己独立的栈,它们都共享一个堆。栈是面向线程的而堆是面向进程的。
#include <stdio.h>
#include <malloc.h>
int main(void) {
/*在栈上分配*/
int i1=0;
int i2=0;
int i3=0;
int i4=0;
printf("栈:向下\n");
printf("i1=0x%08x\n",&i1);
printf("i2=0x%08x\n",&i2);
printf("i3=0x%08x\n",&i3);
printf("i4=0x%08x\n\n",&i4);
printf("--------------------\n\n");
/*在堆上分配*/
char *p1 = (char *)malloc(4);
char *p2 = (char *)malloc(4);
char *p3 = (char *)malloc(4);
char *p4 = (char *)malloc(4);
printf("p1=0x%08x\n",p1);
printf("p2=0x%08x\n",p2);
printf("p3=0x%08x\n",p3);
printf("p4=0x%08x\n",p4);
printf("堆:向上\n\n");
/*释放堆内存*/
free(p1);
p1=NULL;
free(p2);
p2=NULL;
free(p3);
p3=NULL;
free(p4);
p4=NULL;
/*
栈:向下
i1=0x0022fe2c
i2=0x0022fe28
i3=0x0022fe24
i4=0x0022fe20
--------------------
p1=0x004bfe40
p2=0x004bfe60
p3=0x004bfe80
p4=0x004bfea0
堆:向上
*/
return 0;
}
从运行结果中不难发现,内存中的栈区主要用于分配局部变量空间,处于相对较高的地址,其栈地址是向下增长的;而堆区则主要用于分配程序员申请的内存空间,堆地址是向上增长的。
内存分配中的栈与堆主要存在如下区别。
1) 分配与释放方式
栈内存是由编译器自动分配与释放的,它有两种分配方式:静态分配和动态分配。
- 静态分配是由编译器自动完成的,如局部变量的分配(即在一个函数中声明一个 int 类型的变量i时,编译器就会自动开辟一块内存以存放变量 i)。与此同时,其生存周期也只在函数的运行过程中,在运行后就释放,并不可以再次访问。
- 动态分配由 alloca 函数进行分配,但是栈的动态分配与堆是不同的,它的动态分配是由编译器进行释放,无需任何手工实现。值得注意的是,虽然用 alloca 函数可以实现栈内存的动态分配,但 alloca 函数的可移植性很差,而且在没有传统堆栈的机器上很难实现。因此,不宜使用于广泛移植的程序中。当然,完全可以使用 C99 中的变长数组来替代 alloca 函数。
而堆内存则不相同,它完全是由程序员手动申请与释放的,程序在运行的时候由程序员使用内存分配函数(如 malloc 函数)来申请任意多少的内存,使用完再由程序员自己负责使用内存释放函数(如 free 函数)释放内存,如下面的代码所示:
/*分配堆内存*/ char *p1 = (char *)malloc(4); … … /*释放堆内存*/ free(p1); p1=NULL;
对栈内存的自动释放而言,虽然堆上的数据只要程序员不释放空间就可以一直访问,但是,如果一旦忘记了释放堆内存,那么将会造成内存泄漏,导致程序出现致命的潜在错误。
【去除free】
top命令可以查看,该进程占用的内存不断增大。
2) 分配的碎片问题
对堆来说,频繁分配和释放(malloc / free)不同大小的堆空间势必会造成内存空间的不连续,从而造成大量碎片,导致程序效率降低;而对栈来讲,则不会存在这个问题。
3) 分配的效率
大家都知道,栈是机器系统提供的数据结构,计算机会在底层对栈提供支持,例如,分配专门的寄存器存放栈的地址,压栈出栈都有专门的执行指令,这就决定了栈的效率比较高。一般而言,只要栈的剩余空间大于所申请空间,系统就将为程序提供内存,否则将报异常提示栈溢出。
而堆则不同,它是由 C/C++ 函数库提供的,它的机制也相当复杂。例如,为了分配一块堆内存,首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆节点,然后将该节点从空闲节点链表中删除,并将该节点的空间分配给程序。而对于大多数系统,会在这块内存空间的首地址处记录本次分配的大小,这样,代码中的 delete 语句才能正确释放本内存空间。另外,由于找到的堆节点的大小不一定正好等于申请的大小,系统会自动将多余的那部分重新放入空闲链表中。很显然,堆的分配效率比栈要低得多。
4) 申请的大小限制
由于操作系统是用链表来存储空闲内存地址(内存区域不连续)的,同时链表的遍历方向是由低地址向高地址进行的。因此,堆内存的申请大小受限于计算机系统中有效的虚拟内存。
而栈则不同,它是一块连续的内存区域,其地址的增长方向是向下进行的,向内存地址减小的方向增长。由此可见,栈顶的地址和栈的最大容量一般都是由系统预先规定好的,如果申请的空间超过栈的剩余空间时,将会提示溢出错误。由此可见,相对于堆,能够从栈中获得的空间相对较小。
5) 存储的内容
对栈而言,一般用于存放函数的参数与局部变量等。例如,在函数调用时,第一个进栈的是(主函数中的)调用处的下一条指令(即函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数 C 编译器中,参数是由右往左入栈的,最后是函数中的局部变量(注意 static 变量是不入栈的)。
当本次函数调用结束后,遵循“先进后出”(或者称为“后进先出”)的规则,局部变量先出栈,然后是参数,最后栈顶指针指向最开始保存的地址,也就是主函数中的下一条指令,程序由该点继续运行。下面的示例代码可以清晰反映这种入栈顺序:
void f(int i) {
printf("%d,%d,%d,%d\n", i, i++, i++, i++);
}
int main(void) {
int i = 1;
f(i);
return 0;
}
/*
4,3,2,1
*/
由于栈的“先进后出”规则,所以程序最后的输出结果是“4,3,2,1”。
对堆而言,具体存储内容由程序员根据需要决定存储数据。
最后介绍一下 C 语言中各类型变量的存储位置和作用域。
- 全局变量。从静态存储区域分配,其作用域是全局作用域,也就是整个程序的生命周期内都可以使用。与此同时,如果程序是由多个源文件构成的,那么全局变量只要在一个文件中定义,就可以在其他所有的文件中使用,但必须在其他文件中通过使用extern关键字来声明该全局变量。
- 全局静态变量。从静态存储区域分配,其生命周期也是与整个程序同在的,从程序开始到结束一直起作用。但是与全局变量不同的是,全局静态变量作用域只在定义它的一个源文件内,其他源文件不能使用。
- 局部变量。从栈上分配,其作用域只是在局部函数内,在定义该变量的函数内,只要出了该函数,该局部变量就不再起作用,该变量的生命周期也只是和该函数同在。
- 局部静态变量。从静态存储区域分配,其在第一次初始化后就一直存在直到程序结束,该变量的特点是其作用域只在定义它的函数内可见,出了该函数就不可见了。
面试题思考:Stack和Heap的区别 - CSDN博客 https://blog.csdn.net/u014306011/article/details/51044091
堆栈的概念:
堆栈是两种数据结构。堆栈都是一种数据项按序排列的数据结构,只能在一端(称为栈顶(top))对数据项进行插入和删除。在单片机应用中,堆栈是个特殊的存储区,主要功能是暂时存放数据和地址,通常用来保护断点和现场。要点:堆,队列优先,先进先出(FIFO—first in first out)。栈,先进后出(FILO—First-In/Last-Out)。
堆和栈的区别:
一、堆栈空间分配区别:
1、栈(操作系统):由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈;
2、堆(操作系统): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收,分配方式倒是类似于链表。
二、堆栈缓存方式区别:
1、栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放;
2、堆是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些。
三、堆栈数据结构区别:
堆(数据结构):堆可以被看成是一棵树,如:堆排序;
栈(数据结构):一种先进后出的数据结构。
Java中栈和堆的区别:
栈(stack)与堆(heap)都是Java用来在Ram中存放数据的地方。与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆。
在函数中定义的一些基本类型的变量和对象的引用变量都在函数的栈内存中分配。当在一段代码块定义一个变量时,Java就在栈中为这个变量分配内存空间,当超过变量的作用域后,Java会自动释放掉为该变量所分配的内存空间,该内存空间可以立即被另作他用。
堆内存用来存放由new创建的对象和数组,在堆中分配的内存,由Java虚拟机的自动垃圾回收器来管理。在堆中产生了一个数组或对象后,还可以在栈中定义一个特殊的变量,让栈中这个变量的取值等于数组或对象在堆内存中的首地址,栈中的这个变量就成了数组或对象的引用变量。引用变量就相当于是为数组或对象起的一个名称,以后就可以在程序中使用栈中的引用变量来访问堆中的数组或对象。
Java中变量在内存中的分配:
1、类变量(static修饰的变量):在程序加载时系统就为它在堆中开辟了内存,堆中的内存地址存放于栈以便于高速访问。静态变量的生命周期–一直持续到整个”系统”关闭。
2、实例变量:当你使用java关键字new的时候,系统在堆中开辟并不一定是连续的空间分配给变量(比如说类实例),然后根据零散的堆内存地址,通过哈希算法换算为一长串数字以表征这个变量在堆中的”物理位置”。 实例变量的生命周期–当实例变量的引用丢失后,将被GC(垃圾回收器)列入可回收“名单”中,但并不是马上就释放堆中内存。
3、局部变量:局部变量,由声明在某方法,或某代码段里(比如for循环),执行到它的时候在栈中开辟内存,当局部变量一但脱离作用域,内存立即释放。
这里要涉及到Java内存问题,可以参考:Java的内存机制
Java中堆内存和栈内存详解 - 蛊惑Into - 博客园 https://www.cnblogs.com/whgw/archive/2011/09/29/2194997.html
Java把内存分成两种,一种叫做栈内存,一种叫做堆内存
在函数中定义的一些基本类型的变量和对象的引用变量都是在函数的栈内存中分配。当在一段代码块中定义一个变量时,java就在栈中为这个变量分配内存空间,当超过变量的作用域后,java会自动释放掉为该变量分配的内存空间,该内存空间可以立刻被另作他用。
堆内存用于存放由new创建的对象和数组。在堆中分配的内存,由java虚拟机自动垃圾回收器来管理。在堆中产生了一个数组或者对象后,还可以在栈中定义一个特殊的变量,这个变量的取值等于数组或者对象在堆内存中的首地址,在栈中的这个特殊的变量就变成了数组或者对象的引用变量,以后就可以在程序中使用栈内存中的引用变量来访问堆中的数组或者对象,引用变量相当于为数组或者对象起的一个别名,或者代号。
引用变量是普通变量,定义时在栈中分配内存,引用变量在程序运行到作用域外释放。而数组&对象本身在堆中分配,即使程序运行到使用new产生数组和对象的语句所在地代码块之外,数组和对象本身占用的堆内存也不会被释放,数组和对象在没有引用变量指向它的时候,才变成垃圾,不能再被使用,但是仍然占着内存,在随后的一个不确定的时间被垃圾回收器释放掉。这个也是java比较占内存的主要原因,实际上,栈中的变量指向堆内存中的变量,这就是 Java 中的指针!
java中内存分配策略及堆和栈的比较
1 内存分配策略
按照编译原理的观点,程序运行时的内存分配有三种策略,分别是静态的,栈式的,和堆式的.
静态存储分配是指在编译时就能确定每个数据目标在运行时刻的存储空间需求,因而在编译时就可以给他们分配固定的内存空间.这种分配策略要求程序代码中不允许有可变数据结构(比如可变数组)的存在,也不允许有嵌套或者递归的结构出现,因为它们都会导致编译程序无法计算准确的存储空间需求.
栈式存储分配也可称为动态存储分配,是由一个类似于堆栈的运行栈来实现的.和静态存储分配相反,在栈式存储方案中,程序对数据区的需求在编译时是完全未知的,只有到运行的时候才能够知道,但是规定在运行中进入一个程序模块时,必须知道该程序模块所需的数据区大小才能够为其分配内存.和我们在数据结构所熟知的栈一样,栈式存储分配按照先进后出的原则进行分配。
静态存储分配要求在编译时能知道所有变量的存储要求,栈式存储分配要求在过程的入口处必须知道所有的存储要求,而堆式存储分配则专门负责在编译时或运行时模块入口处都无法确定存储要求的数据结构的内存分配,比如可变长度串和对象实例.堆由大片的可利用块或空闲块组成,堆中的内存可以按照任意顺序分配和释放.
2 堆和栈的比较
上面的定义从编译原理的教材中总结而来,除静态存储分配之外,都显得很呆板和难以理解,下面撇开静态存储分配,集中比较堆和栈:
从堆和栈的功能和作用来通俗的比较,堆主要用来存放对象的,栈主要是用来执行程序的.而这种不同又主要是由于堆和栈的特点决定的:
在编程中,例如C/C++中,所有的方法调用都是通过栈来进行的,所有的局部变量,形式参数都是从栈中分配内存空间的。实际上也不是什么分配,只是从栈顶向上用就行,就好像工厂中的传送带(conveyor belt)一样,Stack Pointer会自动指引你到放东西的位置,你所要做的只是把东西放下来就行.退出函数的时候,修改栈指针就可以把栈中的内容销毁.这样的模式速度最快, 当然要用来运行程序了.需要注意的是,在分配的时候,比如为一个即将要调用的程序模块分配数据区时,应事先知道这个数据区的大小,也就说是虽然分配是在程序运行时进行的,但是分配的大小多少是确定的,不变的,而这个"大小多少"是在编译时确定的,不是在运行时.
堆是应用程序在运行的时候请求操作系统分配给自己内存,由于从操作系统管理的内存分配,所以在分配和销毁时都要占用时间,因此用堆的效率非常低.但是堆的优点在于,编译器不必知道要从堆里分配多少存储空间,也不必知道存储的数据要在堆里停留多长的时间,因此,用堆保存数据时会得到更大的灵活性。事实上,面向对象的多态性,堆内存分配是必不可少的,因为多态变量所需的存储空间只有在运行时创建了对象之后才能确定.在C++中,要求创建一个对象时,只需用 new命令编制相关的代码即可。执行这些代码时,会在堆里自动进行数据的保存.当然,为达到这种灵活性,必然会付出一定的代价:在堆里分配存储空间时会花掉更长的时间!这也正是导致我们刚才所说的效率低的原因,看来列宁同志说的好,人的优点往往也是人的缺点,人的缺点往往也是人的优点(晕~).
3 JVM中的堆和栈
JVM是基于堆栈的虚拟机.JVM为每个新创建的线程都分配一个堆栈.也就是说,对于一个Java程序来说,它的运行就是通过对堆栈的操作来完成的。堆栈以帧为单位保存线程的状态。JVM对堆栈只进行两种操作:以帧为单位的压栈和出栈操作。
我们知道,某个线程正在执行的方法称为此线程的当前方法.我们可能不知道,当前方法使用的帧称为当前帧。当线程激活一个Java方法,JVM就会在线程的 Java堆栈里新压入一个帧。这个帧自然成为了当前帧.在此方法执行期间,这个帧将用来保存参数,局部变量,中间计算过程和其他数据.这个帧在这里和编译原理中的活动纪录的概念是差不多的.
从Java的这种分配机制来看,堆栈又可以这样理解:堆栈(Stack)是操作系统在建立某个进程时或者线程(在支持多线程的操作系统中是线程)为这个线程建立的存储区域,该区域具有先进后出的特性。
每一个Java应用都唯一对应一个JVM实例,每一个实例唯一对应一个堆。应用程序在运行中所创建的所有类实例或数组都放在这个堆中,并由应用所有的线程共享.跟C/C++不同,Java中分配堆内存是自动初始化的。Java中所有对象的存储空间都是在堆中分配的,但是这个对象的引用却是在堆栈中分配,也就是说在建立一个对象时从两个地方都分配内存,在堆中分配的内存实际建立这个对象,而在堆栈中分配的内存只是一个指向这个堆对象的指针(引用)而已。
Java 中的堆和栈
Java把内存划分成两种:一种是栈内存,一种是堆内存。
在函数中定义的一些基本类型的变量和对象的引用变量都在函数的栈内存中分配。
当在一段代码块定义一个变量时,Java就在栈中为这个变量分配内存空间,当超过变量的作用域后,Java会自动释放掉为该变量所分配的内存空间,该内存空间可以立即被另作他用。
堆内存用来存放由new创建的对象和数组。
在堆中分配的内存,由Java虚拟机的自动垃圾回收器来管理。
在堆中产生了一个数组或对象后,还可以在栈中定义一个特殊的变量,让栈中这个变量的取值等于数组或对象在堆内存中的首地址,栈中的这个变量就成了数组或对象的引用变量。
引用变量就相当于是为数组或对象起的一个名称,以后就可以在程序中使用栈中的引用变量来访问堆中的数组或对象。
具体的说:
栈与堆都是Java用来在Ram中存放数据的地方。与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆。
Java的堆是一个运行时数据区,类的(对象从中分配空间。这些对象通过new、newarray、anewarray和multianewarray等指令建立,它们不需要程序代码来显式的释放。堆是由垃圾回收来负责的,堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,因为它是在运行时动态分配内存的,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
栈的优势是,存取速度比堆要快,仅次于寄存器,栈数据可以共享。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。栈中主要存放一些基本类型的变量(,int, short, long, byte, float, double, boolean, char)和对象句柄。
栈有一个很重要的特殊性,就是存在栈中的数据可以共享。假设我们同时定义:
int a = 3;
int b = 3;
编译器先处理int a = 3;首先它会在栈中创建一个变量为a的引用,然后查找栈中是否有3这个值,如果没找到,就将3存放进来,然后将a指向3。接着处理int b = 3;在创建完b的引用变量后,因为在栈中已经有3这个值,便将b直接指向3。这样,就出现了a与b同时均指向3的情况。这时,如果再令a=4;那么编译器会重新搜索栈中是否有4值,如果没有,则将4存放进来,并令a指向4;如果已经有了,则直接将a指向这个地址。因此a值的改变不会影响到b的值。要注意这种数据的共享与两个对象的引用同时指向一个对象的这种共享是不同的,因为这种情况a的修改并不会影响到b, 它是由编译器完成的,它有利于节省空间。而一个对象引用变量修改了这个对象的内部状态,会影响到另一个对象引用变量
http://www.cplusplus.com/reference/cstdlib/malloc/
malloc
void* malloc (size_t size);
Allocates a block of size bytes of memory, returning a pointer to the beginning of the block.
The content of the newly allocated block of memory is not initialized, remaining with indeterminate values.
If size is zero, the return value depends on the particular library implementation (it may or may not be a null pointer), but the returned pointer shall not be dereferenced.
Parameters
- size
- Size of the memory block, in bytes.
size_t is an unsigned integral type.
Return Value
On success, a pointer to the memory block allocated by the function.
The type of this pointer is always void*, which can be cast to the desired type of data pointer in order to be dereferenceable.
If the function failed to allocate the requested block of memory, a null pointer is returned.
Example
|
|
This program generates a string of the length specified by the user and fills it with alphabetic characters. The possible length of this string is only limited by the amount of memory available to malloc
Data races
Only the storage referenced by the returned pointer is modified. No other storage locations are accessed by the call.
If the function reuses the same unit of storage released by a deallocation function (such as free or realloc), the functions are synchronized in such a way that the deallocation happens entirely before the next allocation.
Exceptions (C++)
No-throw guarantee: this function never throws exceptions.
http://www.cplusplus.com/reference/new/operator%20new%5b%5d/
The default allocation and deallocation functions are special components of the standard library; They have the following unique properties:
- Global: All three versions of
operator neware declared in the global namespace, not within the std namespace. - Implicit: The allocating versions ((1) and (2)) are implicitly declared in every translation unit of a C++ program, no matter whether header
<new>is included or not. - Replaceable: The allocating versions ((1) and (2)) are also replaceable: A program may provide its own definition that replaces the one provided by default to produce the result described above, or can overload it for specific types.
If set_new_handler has been used to define a new_handler function, this new-handler function is called by the default definitions of the allocating versions ((1) and (2)) if they fail to allocate the requested storage.operator new[] can be called explicitly as a regular function, but in C++, new[] is an operator with a very specific behavior: An expression with the new operator on an array type, first calls function operator new (i.e., this function) with the size of its array type specifier as first argument (plus any array overhead storage to keep track of the size, if any), and if this is successful, it then automatically initializes or constructs every object in the array (if needed). Finally, the expression evaluates as a pointer to the appropriate type pointing to the first element of the array.
What is the difference between new/delete and malloc/ free in C/ C++? https://www.tutorialspoint.com/what-is-the-difference-between-new-delete-and-malloc-free-in-c-cplusplus
https://www.tutorialspoint.com/malloc-vs-new-in-c-cplusplus
new()
The new operator requests for the memory allocation in heap. If the sufficient memory is available, it initializes the memory to the pointer variable and returns its address.
Here is the syntax of new operator in C++ language,
pointer_variable = new datatype;
Here is the syntax to initialize the memory,
pointer_variable = new datatype(value);
Here is the syntax to allocate a block of memory,
pointer_variable = new datatype[size];
Here is an example of new operator in C++ language,
【The new operator requests for the memory allocation in heap. new申请堆内存】
new/ delete
The new operator requests for the memory allocation in heap. If the sufficient memory is available, it initializes the memory to the pointer variable and returns its address.
The delete operator is used to deallocate the memory. User has the privilege to deallocate the created pointer variable by this delete operator.
Here is an example of new/delete operator in C++ language,
new/ delete
The new operator requests for the memory allocation in heap. If the sufficient memory is available, it initializes the memory to the pointer variable and returns its address.
The delete operator is used to deallocate the memory. User has the privilege to deallocate the created pointer variable by this delete operator.
Here is an example of new/delete operator in C++ language,
Example
#include <iostream>
using namespace std;
int main () {
int *ptr1 = NULL;
ptr1 = new int;
float *ptr2 = new float(299.121);
int *ptr3 = new int[28];
*ptr1 = 28;
cout << "Value of pointer variable 1 : " << *ptr1 << endl;
cout << "Value of pointer variable 2 : " << *ptr2 << endl;
if (!ptr3)
cout << "Allocation of memory failed\n";
else {
for (int i = 10; i < 15; i++)
ptr3[i] = i+1;
cout << "Value of store in block of memory: ";
for (int i = 10; i < 15; i++)
cout << ptr3[i] << " ";
}
delete ptr1;
delete ptr2;
delete[] ptr3;
return 0;
}
Here is the output
Value of pointer variable 1 : 28 Value of pointer variable 2 : 299.121 Value of store in block of memory: 11 12 13 14 15
malloc/ free
The function malloc() is used to allocate the requested size of bytes and it returns a pointer to the first byte of allocated memory. It returns null pointer, if fails.
The function free() is used to deallocate the allocated memory by malloc(). It does not change the value of pointer which means it still points the same memory location.
Here is an example of malloc/free in C language,
Example
#include <stdio.h>
#include <stdlib.h>
int main() {
int n = 4, i, *p, s = 0;
p = (int*) malloc(n * sizeof(int));
if(p == NULL) {
printf("\nError! memory not allocated.");
exit(0);
}
printf("\nEnter elements of array : ");
for(i = 0; i < n; ++i) {
scanf("%d", p + i);
s += *(p + i);
}
printf("\nSum : %d", s);
free(p);
return 0;
}
Here is the output:
Enter elements of array : 32 23 21 8 Sum : 84
🚀 Demystifying memory management in modern programming languages | Technorage https://deepu.tech/memory-management-in-programming/
In this multi-part series, I aim to demystify the concepts behind memory management and take a deeper look at memory management in some of the modern programming languages. I hope the series would give you some insights into what is happening under the hood of these languages in terms of memory management. Learning about memory management will also help us to write more performant code as the way we write code also has an impact on memory management regardless of the automatic memory management technique used by the language.
Part 1: Introduction to Memory management
Memory management is the process of controlling and coordinating the way a software application access computer memory. It is a serious topic in software engineering and its a topic that confuses some people and is a black box for some.
What is it?
When a software runs on a target Operating system on a computer it needs access to the computers RAM(Random-access memory) to:
- load its own bytecode that needs to be executed
- store the data values and data structures used by the program that is executed
- load any run-time systems that are required for the program to execute
When a software program uses memory there are two regions of memory they use, apart from the space used to load the bytecode, Stack and Heap memory.
Stack
The stack is used for static memory allocation and as the name suggests it is a last in first out(LIFO) stack (Think of it as a stack of boxes).
- Due to this nature, the process of storing and retrieving data from the stack is very fast as there is no lookup required, you just store and retrieve data from the topmost block on it.
- But this means any data that is stored on the stack has to be finite and static(The size of the data is known at compile-time).
- This is where the execution data of the functions are stored as stack frames(So, this is the actual execution stack). Each frame is a block of space where the data required for that function is stored. For example, every time a function declares a new variable, it is “pushed” onto the topmost block in the stack. Then every time a function exits, the topmost block is cleared, thus all of the variables pushed onto the stack by that function, are cleared. These can be determined at compile time due to the static nature of the data stored here.
- Multi-threaded applications can have a stack per thread.
- Memory management of the stack is simple and straightforward and is done by the OS.
- Typical data that are stored on stack are local variables(value types or primitives, primitive constants), pointers and function frames.
- This is where you would encounter stack overflow errors as the size of the stack is limited compared to the Heap.
- There is a limit on the size of value that can be stored on the Stack for most languages.
 Stack used in JavaScript, objects are stored in Heap and referenced when needed. Here is a video of the same.
Stack used in JavaScript, objects are stored in Heap and referenced when needed. Here is a video of the same.
Heap
Heap is used for dynamic memory allocation and unlike stack, the program needs to look up the data in heap using pointers (Think of it as a big multi-level library).
- It is slower than stack as the process of looking up data is more involved but it can store more data than the stack.
- This means data with dynamic size can be stored here.
- Heap is shared among threads of an application.
- Due to its dynamic nature heap is trickier to manage and this is where most of the memory management issues arise from and this is where the automatic memory management solutions from the language kick in.
- Typical data that are stored on the heap are global variables, reference types like objects, strings, maps, and other complex data structures.
- This is where you would encounter out of memory errors if your application tries to use more memory than the allocated heap(Though there are many other factors at play here like GC, compacting).
- Generally, there is no limit on the size of the value that can be stored on the heap. Of course, there is the upper limit of how much memory is allocated to the application.
Why is it important?
Unlike Hard disk drives, RAM is not infinite. If a program keeps on consuming memory without freeing it, ultimately it will run out of memory and crash itself or even worse crash the operating system. Hence software programs can’t just keep using RAM as they like as it will cause other programs and processes to run out of memory. So instead of letting the software developer figure this out, most programming languages provide ways to do automatic memory management. And when we talk about memory management we are mostly talking about managing the Heap memory.
Different approaches?
Since modern programming languages don’t want to burden(more like trust 👅) the end developer to manage the memory of his/her application most of them have devised a way to do automatic memory management. Some older languages still require manual memory handling but many do provide neat ways to do that. Some languages use multiple approaches to memory management and some even let the developer choose what is best for him/her(C++ is a good example). The approaches can be categorized as below
Manual memory management
The language doesn’t manage memory for you by default, it’s up to you to allocate and free memory for the objects you create. For example, C and C++. They provide the malloc, realloc, calloc, and freemethods to manage memory and it’s up to the developer to allocate and free heap memory in the program and make use of pointers efficiently to manage memory. Let’s just say that it’s not for everyone 😉.
Garbage collection(GC)
Automatic management of heap memory by freeing unused memory allocations. GC is one of the most common memory management in modern languages and the process often runs at certain intervals and thus might cause a minor overhead called pause times. JVM(Java/Scala/Groovy/Kotlin), JavaScript, C#, Golang, OCaml, and Ruby are some of the languages that use Garbage collection for memory management by default.

- Mark & Sweep GC: Also known as Tracing GC. Its generally a two-phase algorithm that first marks objects that are still being referenced as “alive” and in the next phase frees the memory of objects that are not alive. JVM, C#, Ruby, JavaScript, and Golang employ this approach for example. In JVM there are different GC algorithms to choose from while JavaScript engines like V8 use a Mark & Sweep GC along with Reference counting GC to complement it. This kind of GC is also available for C & C++ as an external library.
- Reference counting GC: In this approach, every object gets a reference count which is incremented or decremented as references to it change and garbage collection is done when the count becomes zero. It’s not very preferred as it cannot handle cyclic references. PHP, Perl, and Python, for example, uses this type of GC with workarounds to overcome cyclic references. This type of GC can be enabled for C++ as well.
Resource Acquisition is Initialization (RAII)
In this type of memory management, an object’s memory allocation is tied to its lifetime, which is from construction until destruction. It was introduced in C++ and is also used by Ada and Rust.
Automatic Reference Counting(ARC)
It’s similar to Reference counting GC but instead of running a runtime process at a specific interval the retain and release instructions are inserted to the compiled code at compile-time and when an object reference becomes zero its cleared automatically as part of execution without any program pause. It also cannot handle cyclic references and relies on the developer to handle that by using certain keywords. Its a feature of the Clang compiler and provides ARC for Objective C & Swift.
Ownership
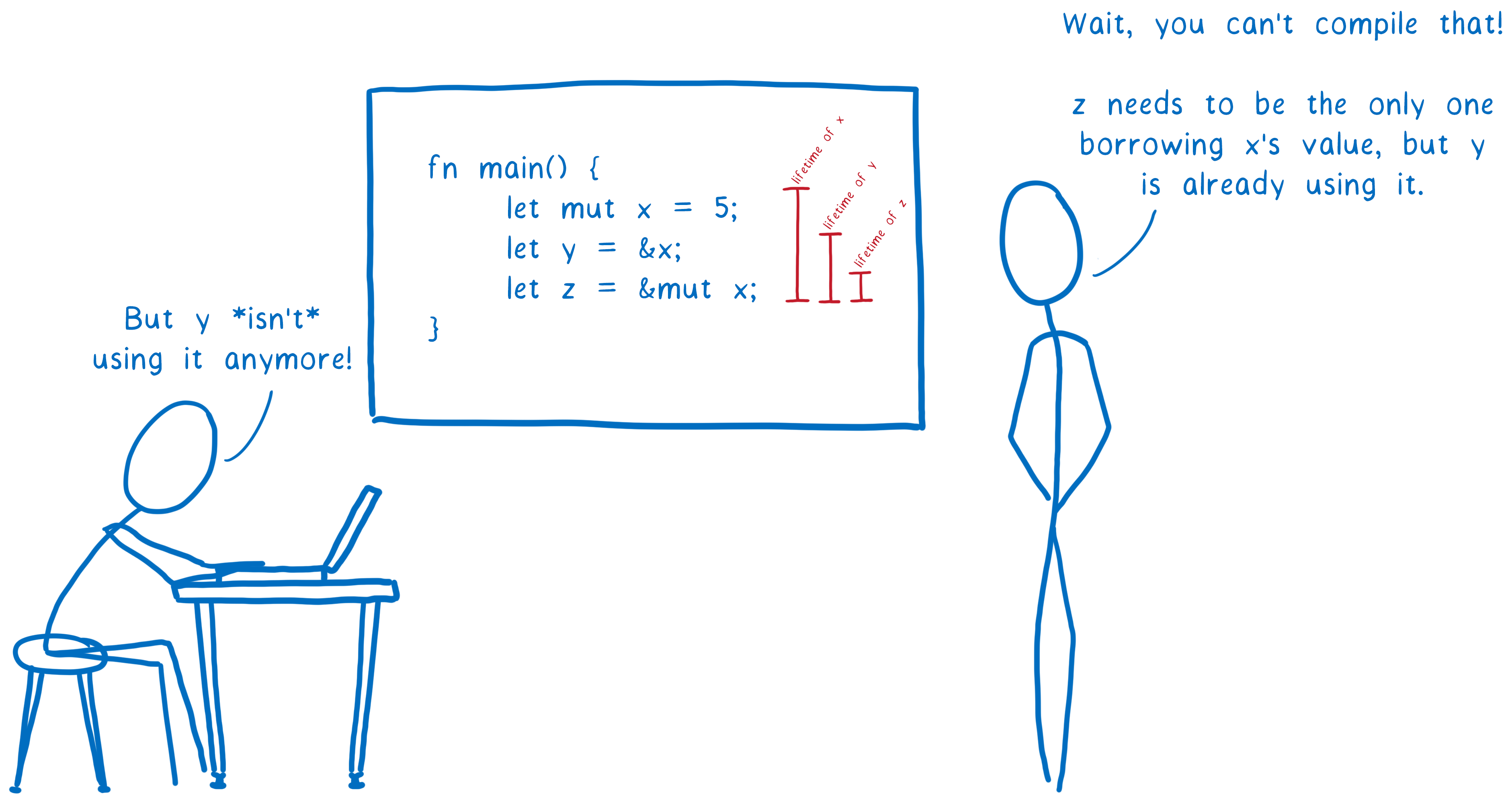
It combines RAII with an ownership model, any value must have a variable as its owner(and only one owner at a time) when the owner goes out of scope the value will be dropped freeing the memory regardless of it being in stack or heap memory. It is kind of like Compile-time reference counting. It is used by Rust, in my research I couldn’t find any other language using this exact mechanism.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号