三次握手 四次握手 原因分析 TCP 半连接队列 全连接队列
小结
1、
三次握手的原因:保证双方收和发消息功能正常;

连接建立(3)
C-->S
-->SYN c
<--ACK c+1;SYN s
-->ACK s+1
连接断开(4)
C ---> S
-->FIN c
<--ACK c+1 [S close wait]
<-- FIN s [C time wait]
--->ACK s+1
深入理解 Linux 的 TCP 三次握手 https://mp.weixin.qq.com/s/G2LuRZjQE15F6fSU-Bv_jw
【生活模型】
"请问能听见吗""我能听见你的声音,你能听见我的声音吗"
【原理】
A先对B:你在么?我在的,我发一个消息看你能不能收到,我发J;
B收到后,回答:我收到了你发的J,你的发送和我的接收功能正常,回你J+1;并且,我给你发个消息K,看我的发送和你的接收是否正常?
A收到后,回答:我收到了你发的J+1和K,我回你K+1,告诉你的发送和我的接收正常;
通过前2次,表明:起点的发送和终点的接收,功能正常;
通过后2次,表明:终点的发送和起点的接收,功能正常;
由此保证:双方可以发送和接收对方的信息。
【术语】
客户端的协议栈向服务器端发送了 SYN 包,并告诉服务器端当前发送序列号 j,客户端进入 SYNC_SENT 状态;
服务器端的协议栈收到这个包之后,和客户端进行 ACK 应答,应答的值为 j+1,表示对 SYN 包 j 的确认,同时服务器也发送一个 SYN 包,告诉客户端当前我的发送序列号为 k,服务器端进入 SYNC_RCVD 状态;
客户端协议栈收到 ACK 之后,使得应用程序从 connect 调用返回,表示客户端到服务器端的单向连接建立成功,客户端的状态为 ESTABLISHED,同时客户端协议栈也会对服务器端的 SYN 包进行应答,应答数据为 k+1;
应答包到达服务器端后,服务器端协议栈使得 accept 阻塞调用返回,这个时候服务器端到客户端的单向连接也建立成功,服务器端也进入 ESTABLISHED 状态。
【本质】
这个问题的本质是, 信道不可靠, 但是通信双发需要就某个问题达成一致. 而要解决这个问题, 无论你在消息中包含什么信息, 三次通信是理论上的最小值. 所以三次握手不是TCP本身的要求, 而是为了满足"在不可靠信道上可靠地传输信息"这一需求所导致的。
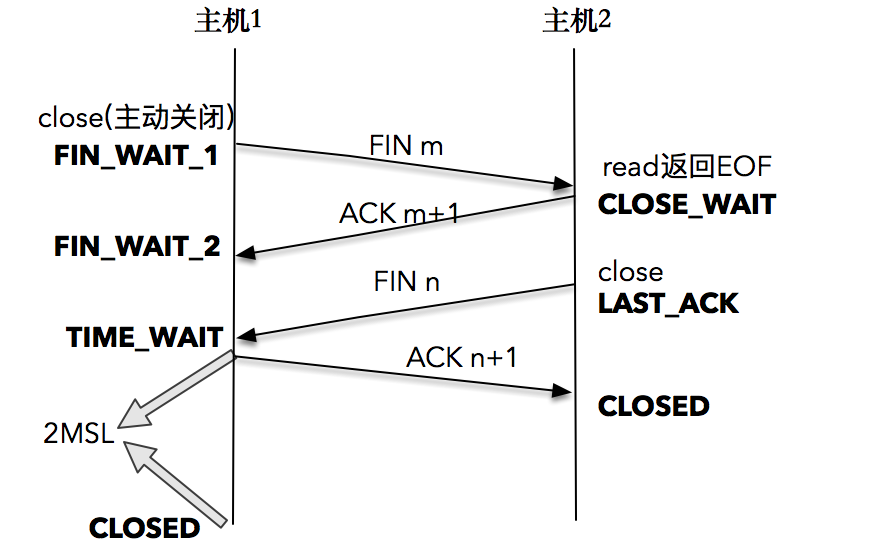
【生活模型】
C想对D挂电话
C->D:我要挂电话了,我发X;
D->C:我知道你要挂电话了,我发X+1;但是我还有话要说;
C:我收到了你发的X+1;我知道你知道我要挂电话了;
D->C:我最后对你说一句话,我发Y;
C->D:我收到你的最后一句话了,我发Y+1;
D:我收到Y+1就挂电话;
C:我发Y+1之后,再等一段时间就挂电话;
【总结】
TIME_WAIT的作用:
1) 确保对方能够正确收到最后的ACK,帮助其关闭;
2) 防迷走报文对程序带来的影响。
TIME_WAIT的危害:
1) 占用内存;
2) 占用端口。
关于TCP 半连接队列和全连接队列-云栖社区-阿里云 https://yq.aliyun.com/articles/79972
关于TCP 半连接队列和全连接队列
最近碰到一个client端连接异常问题,然后定位分析并查阅各种资料文章,对TCP连接队列有个深入的理解
查资料过程中发现没有文章把这两个队列以及怎么观察他们的指标说清楚,希望通过这篇文章能把他们说清楚一点
问题描述
JAVA的client和server,使用socket通信。server使用NIO。
1.间歇性的出现client向server建立连接三次握手已经完成,但server的selector没有响应到这连接。
2.出问题的时间点,会同时有很多连接出现这个问题。
3.selector没有销毁重建,一直用的都是一个。
4.程序刚启动的时候必会出现一些,之后会间歇性出现。
分析问题
正常TCP建连接三次握手过程:

- 第一步:client 发送 syn 到server 发起握手;
- 第二步:server 收到 syn后回复syn+ack给client;
- 第三步:client 收到syn+ack后,回复server一个ack表示收到了server的syn+ack(此时client的56911端口的连接已经是established)
从问题的描述来看,有点像TCP建连接的时候全连接队列(accept队列)满了,尤其是症状2、4. 为了证明是这个原因,马上通过 ss -s 去看队列的溢出统计数据:
667399 times the listen queue of a socket overflowed
反复看了几次之后发现这个overflowed 一直在增加,那么可以明确的是server上全连接队列一定溢出了
接着查看溢出后,OS怎么处理:
# cat /proc/sys/net/ipv4/tcp_abort_on_overflow
0
tcp_abort_on_overflow 为0表示如果三次握手第三步的时候全连接队列满了那么server扔掉client 发过来的ack(在server端认为连接还没建立起来)
为了证明客户端应用代码的异常跟全连接队列满有关系,我先把tcp_abort_on_overflow修改成 1,1表示第三步的时候如果全连接队列满了,server发送一个reset包给client,表示废掉这个握手过程和这个连接(本来在server端这个连接就还没建立起来)。
接着测试然后在客户端异常中可以看到很多connection reset by peer的错误,到此证明客户端错误是这个原因导致的。
于是开发同学翻看java 源代码发现socket 默认的backlog(这个值控制全连接队列的大小,后面再详述)是50,于是改大重新跑,经过12个小时以上的压测,这个错误一次都没出现过,同时 overflowed 也不再增加了。
到此问题解决,简单来说TCP三次握手后有个accept队列,进到这个队列才能从Listen变成accept,默认backlog 值是50,很容易就满了。满了之后握手第三步的时候server就忽略了client发过来的ack包(隔一段时间server重发握手第二步的syn+ack包给client),如果这个连接一直排不上队就异常了。
深入理解TCP握手过程中建连接的流程和队列
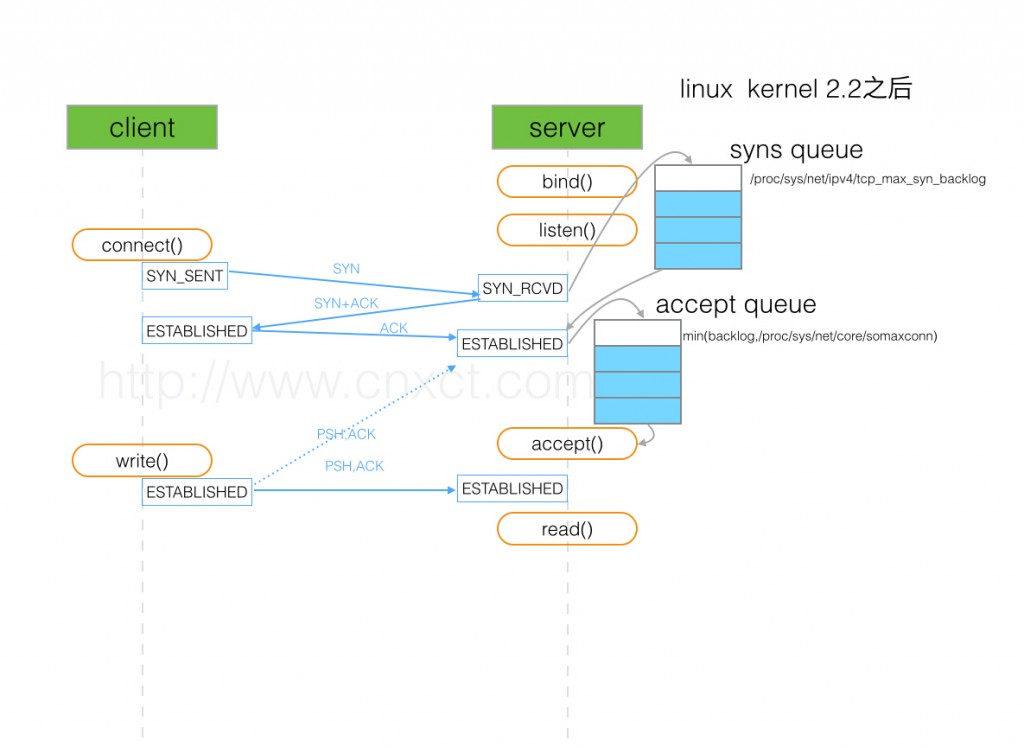
(图片来源:http://www.cnxct.com/something-about-phpfpm-s-backlog/)
如上图所示,这里有两个队列:syns queue(半连接队列);accept queue(全连接队列)
三次握手中,在第一步server收到client的syn后,把相关信息放到半连接队列中,同时回复syn+ack给client(第二步);
比如syn floods 攻击就是针对半连接队列的,攻击方不停地建连接,但是建连接的时候只做第一步,第二步中攻击方收到server的syn+ack后故意扔掉什么也不做,导致server上这个队列满其它正常请求无法进来
第三步的时候server收到client的ack,如果这时全连接队列没满,那么从半连接队列拿出相关信息放入到全连接队列中,否则按tcp_abort_on_overflow指示的执行。
这时如果全连接队列满了并且tcp_abort_on_overflow是0的话,server过一段时间再次发送syn+ack给client(也就是重新走握手的第二步),如果client超时等待比较短,就很容易异常了。
在我们的os中retry 第二步的默认次数是2(centos默认是5次):
net.ipv4.tcp_synack_retries = 2
如果TCP连接队列溢出,有哪些指标可以看呢?
上述解决过程有点绕,那么下次再出现类似问题有什么更快更明确的手段来确认这个问题呢?
netstat -s
[root@server ~]# netstat -s | egrep "listen|LISTEN"
667399 times the listen queue of a socket overflowed
667399 SYNs to LISTEN sockets ignored
比如上面看到的 667399 times ,表示全连接队列溢出的次数,隔几秒钟执行下,如果这个数字一直在增加的话肯定全连接队列偶尔满了。
ss 命令
[root@server ~]# ss -lnt
Recv-Q Send-Q Local Address:Port Peer Address:Port
0 50 *:3306 *:*
上面看到的第二列Send-Q 表示第三列的listen端口上的全连接队列最大为50,第一列Recv-Q为全连接队列当前使用了多少
全连接队列的大小取决于:min(backlog, somaxconn) . backlog是在socket创建的时候传入的,somaxconn是一个os级别的系统参数
半连接队列的大小取决于:max(64, /proc/sys/net/ipv4/tcp_max_syn_backlog)。 不同版本的os会有些差异
实践验证下上面的理解
把java中backlog改成10(越小越容易溢出),继续跑压力,这个时候client又开始报异常了,然后在server上通过 ss 命令观察到:
Fri May 5 13:50:23 CST 2017
Recv-Q Send-QLocal Address:Port Peer Address:Port
11 10 *:3306 *:*
按照前面的理解,这个时候我们能看到3306这个端口上的服务全连接队列最大是10,但是现在有11个在队列中和等待进队列的,肯定有一个连接进不去队列要overflow掉
进一步思考
如果client走完第三步在client看来连接已经建立好了,但是server上的对应连接实际没有准备好,这个时候如果client发数据给server,server会怎么处理呢?(有同学说会reset,还是实践看看)
先来看一个例子:
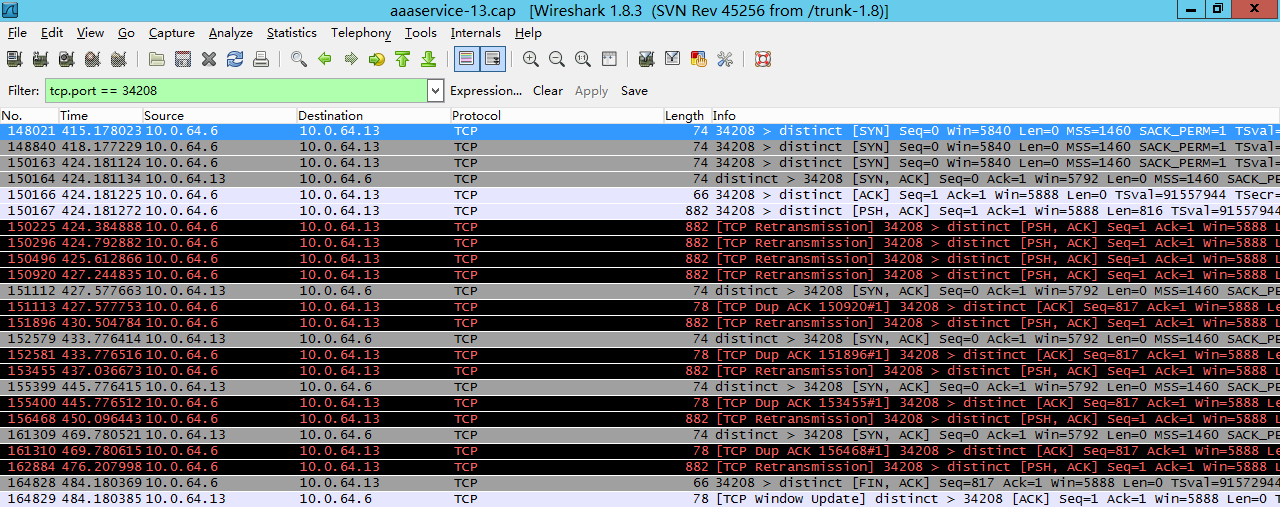
(图片来自:http://blog.chinaunix.net/uid-20662820-id-4154399.html)
如上图,150166号包是三次握手中的第三步client发送ack给server,然后150167号包中client发送了一个长度为816的包给server,因为在这个时候client认为连接建立成功,但是server上这个连接实际没有ready,所以server没有回复,一段时间后client认为丢包了然后重传这816个字节的包,一直到超时,client主动发fin包断开该连接。
这个问题也叫client fooling,可以看这里:https://github.com/torvalds/linux/commit/5ea8ea2cb7f1d0db15762c9b0bb9e7330425a071 (感谢 @刘欢(浅奕(16:00后答疑) 的提示)
**从上面的实际抓包来看不是reset,而是server忽略这些包,然后client重传,一定次数后client认为异常,然后断开连接。
**
过程中发现的一个奇怪问题
[root@server ~]# date; netstat -s | egrep "listen|LISTEN"
Fri May 5 15:39:58 CST 2017
1641685 times the listen queue of a socket overflowed
1641685 SYNs to LISTEN sockets ignored
[root@server ~]# date; netstat -s | egrep "listen|LISTEN"
Fri May 5 15:39:59 CST 2017
1641906 times the listen queue of a socket overflowed
1641906 SYNs to LISTEN sockets ignored
如上所示:
overflowed和ignored居然总是一样多,并且都是同步增加,overflowed表示全连接队列溢出次数,socket ignored表示半连接队列溢出次数,没这么巧吧。
翻看内核源代码(http://elixir.free-electrons.com/linux/v3.18/source/net/ipv4/tcp_ipv4.c):
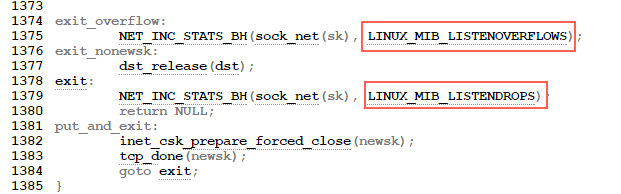
可以看到overflow的时候一定会drop++(socket ignored),也就是drop一定大于等于overflow。
同时我也查看了另外几台server的这两个值来证明drop一定大于等于overflow:
server1
150 SYNs to LISTEN sockets dropped
server2
193 SYNs to LISTEN sockets dropped
server3
16329 times the listen queue of a socket overflowed
16422 SYNs to LISTEN sockets dropped
server4
20 times the listen queue of a socket overflowed
51 SYNs to LISTEN sockets dropped
server5
984932 times the listen queue of a socket overflowed
988003 SYNs to LISTEN sockets dropped
那么全连接队列满了会影响半连接队列吗?
来看三次握手第一步的源代码(http://elixir.free-electrons.com/linux/v2.6.33/source/net/ipv4/tcp_ipv4.c#L1249):
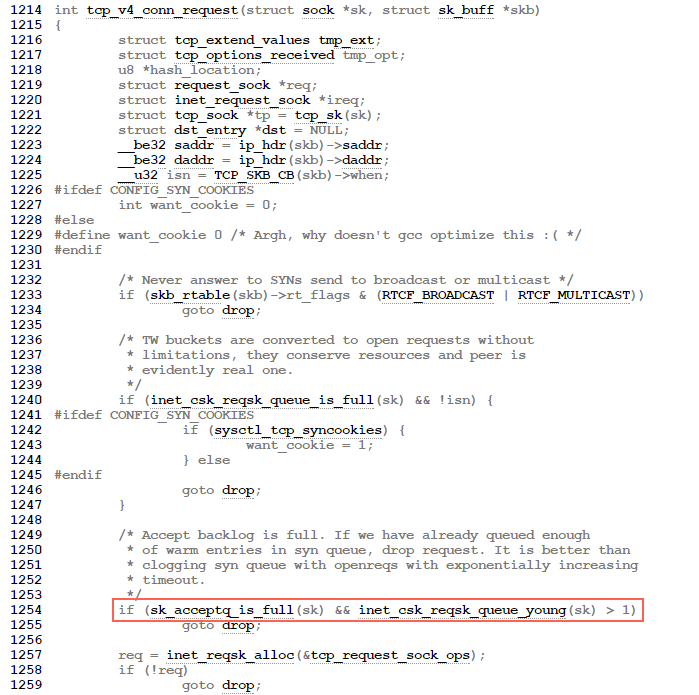
TCP三次握手第一步的时候如果全连接队列满了会影响第一步drop 半连接的发生。大概流程的如下:
tcp_v4_do_rcv->tcp_rcv_state_process->tcp_v4_conn_request
//如果accept backlog队列已满,且未超时的request socket的数量大于1,则丢弃当前请求
if(sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_yong(sk)>1)
goto drop;
总结
全连接队列、半连接队列溢出这种问题很容易被忽视,但是又很关键,特别是对于一些短连接应用(比如Nginx、PHP,当然他们也是支持长连接的)更容易爆发。 一旦溢出,从cpu、线程状态看起来都比较正常,但是压力上不去,在client看来rt也比较高(rt=网络+排队+真正服务时间),但是从server日志记录的真正服务时间来看rt又很短。
另外就是jdk、netty等一些框架默认backlog比较小,可能有些情况下导致性能上不去,比如 @毕玄 碰到的这个 《netty新建连接并发数很小的case》
都是类似原因
希望通过本文能够帮大家理解TCP连接过程中的半连接队列和全连接队列的概念、原理和作用,更关键的是有哪些指标可以明确看到这些问题。
另外每个具体问题都是最好学习的机会,光看书理解肯定是不够深刻的,请珍惜每个具体问题,碰到后能够把来龙去脉弄清楚。
我的其他几篇跟网络问题相关的文章,也很有趣,借着案例来理解好概念和原理,希望对大家也有点帮助
https://www.atatech.org/articles/76138
https://www.atatech.org/articles/60633
https://www.atatech.org/articles/73174
https://www.atatech.org/articles/73289
最后感谢 @梦实 在这个过程中提供的帮助

 浙公网安备 33010602011771号
浙公网安备 33010602011771号